 Transformer
Transformer
Transformer

Transformer中的Self-Attention
Self-Attention in Detail
计算自注意力的第一步就是从每个编码器的输入向量(每个单词的词向量)中生成三个向量。也就是说对于每个单词,我们创造一个查询向量、一个键向量和一个值向量。这三个向量是通过词嵌入与三个权重矩阵后相乘创建的。
可以发现这些新向量在维度上比词嵌入向量更低。他们的维度是64,而词嵌入和编码器的输入/输出向量的维度是512. 但实际上不强求维度更小,这只是一种基于架构上的选择,它可以使多头注意力(multiheaded attention)的大部分计算保持不变。

计算自注意力的第二步是计算得分。假设我们在为这个例子中的第一个词“Thinking”计算自注意力向量,我们需要拿输入句子中的每个单词对“Thinking”打分。这些分数决定了在编码单词“Thinking”的过程中有多重视句子的其它部分。
这些分数是通过打分单词(所有输入句子的单词)的键向量与“Thinking”的查询向量相点积来计算的。所以如果我们是处理位置最靠前的词的自注意力的话,第一个分数是

第三步和第四步是将分数除以8(8是论文中使用的键向量的维数64的平方根,这会让梯度更稳定。这里也可以使用其它值,8只是默认值),然后通过softmax传递结果。softmax的作用是使所有单词的分数归一化,得到的分数都是正值且和为1。

这个softmax分数决定了每个单词对编码当下位置(“Thinking”)的贡献。显然,已经在这个位置上的单词将获得最高的softmax分数,但有时关注另一个与当前单词相关的单词也会有帮助。
第五步是将每个值向量乘以softmax分数(这是为了准备之后将它们求和)。这里的直觉是希望关注语义上相关的单词,并弱化不相关的单词(例如,让它们乘以0.001这样的小数)。
第六步是对加权值向量求和(译注:自注意力的另一种解释就是在编码某个单词时,就是将所有单词的表示(值向量)进行加权求和,而权重是通过该词的表示(键向量)与被编码词表示(查询向量)的点积并通过softmax得到。),然后即得到自注意力层在该位置的输出(在我们的例子中是对于第一个单词)。

这样自注意力的计算就完成了。得到的向量就可以传给前馈神经网络。然而实际中,这些计算是以矩阵形式完成的,以便算得更快。那我们接下来就看看如何用矩阵实现的。
Matrix Calculation of Self-Attention
第一步是计算查询矩阵、键矩阵和值矩阵。为此,我们将将输入句子的词嵌入装进矩阵X中,将其乘以我们训练的权重矩阵(


除以
过程就是Scale过程:如果 大,将导致在经过sofrmax操作后产生非常小的梯度,不利于网络的训练。
最后,由于我们处理的是矩阵,我们可以将步骤2到步骤6合并为一个公式来计算自注意力层的输出。这种通过 query 和 key 的相似性程度来确定 value 的权重分布的方法被称为scaled dot-product attention。其实scaled dot-Product attention就是我们常用的使用点积进行相似度计算的attention,只是多除了一个(为K的维度)起到调节作用,使得内积不至于太大。


Many Heads
通过增加一种叫做“多头”注意力(“multi-headed” attention)的机制,论文进一步完善了自注意力层,并在两方面提高了注意力层的性能:
1.它扩展了模型专注于不同位置的能力。在上面的例子中,虽然每个编码都在
2.它给出了注意力层的多个“表示子空间”(representation subspaces)。接下来我们将看到,对于“多头”注意机制,我们有多个查询/键/值权重矩阵集(Transformer使用八个注意力头,因此我们对于每个编码器/解码器有八个矩阵集合)。这些集合中的每一个都是随机初始化的,在训练之后,每个集合都被用来将输入词嵌入(或来自较低编码器/解码器的向量)投影到不同的表示子空间中。

在“多头”注意机制下,我们为每个头保持独立的查询/键/值权重矩阵,从而产生不同的查询/键/值矩阵。和之前一样,我们拿
如果我们做与上述相同的自注意力计算,只需八次不同的权重矩阵运算,我们就会得到八个不同的

这给我们带来了一点挑战。前馈层不需要8个矩阵,它只需要一个矩阵(由每一个单词的表示向量组成)。所以我们需要一种方法把这八个矩阵压缩成一个矩阵。那该怎么做?其实可以直接把这些矩阵拼接在一起,然后用一个附加的权重矩阵

这几乎就是多头自注意力的全部。这确实有好多矩阵,我们试着把它们集中在一个图片中,这样可以一眼看清。

那么在整个模型中,是如何使用attention的呢?如下图,首先在编码器到解码器的地方使用了多头attention进行连接,K,V,Q分别是编码器的层输出(这里K=V)和解码器中多头attention的输入。其实就和主流的机器翻译模型中的attention一样,利用解码器和编码器attention来进行翻译对齐。然后在编码器和解码器中都使用了多头自注意力self-attention来学习文本的表示。Self-attention即K=V=Q,例如输入一个句子,那么里面的每个词都要和该句子中的所有词进行attention计算。目的是学习句子内部的词依赖关系,捕获句子的内部结构。


对于使用自注意力机制的原因,论文中提到主要从三个方面考虑(每一层的复杂度,是否可以并行,长距离依赖学习),并给出了和RNN,CNN计算复杂度的比较。可以看到,如果输入序列n小于表示维度d的话,每一层的时间复杂度self-attention是比较有优势的。当n比较大时,作者也给出了一种解决方案self-attention(restricted)即每个词不是和所有词计算attention,而是只与限制的r个词去计算attention。在并行方面,多头attention和CNN一样不依赖于前一时刻的计算,可以很好的并行,优于RNN。在长距离依赖上,由于self-attention是每个词和所有词都要计算attention,所以不管他们中间有多长距离,最大的路径长度也都只是1。可以捕获长距离依赖关系。

既然我们已经摸到了注意力机制的这么多“头”,那么让我们重温之前的例子,看看我们在例句中编码“it”一词时,不同的注意力“头”集中在哪里:

当我们编码“it”一词时,一个注意力头集中在“animal”上,而另一个则集中在“tired”上,从某种意义上说,模型对“it”一词的表达在某种程度上是“animal”和“tired”的代表。
然而,如果我们把所有的attention都加到图示里,事情就更难解释了:

Positional Encoding
根据自注意力机制原理的介绍我们知道,自注意力机制在实际运算过程中不过就是几个矩阵来回相乘进行线性变换而已。因此,这就导致即使是打乱各个词的顺序,那么最终计算得到的结果本质上却没有发生任何变换,换句话说仅仅只使用自注意力机制会丢失文本原有的序列信息。

如上图所示,在经过词嵌入表示后,序列“我 在 看 书”经过了一次线性变换。现在,我们将序列变成“书 在 看 我”,然后同样以中间这个权重矩阵来进行线性变换,过程如下图所示。
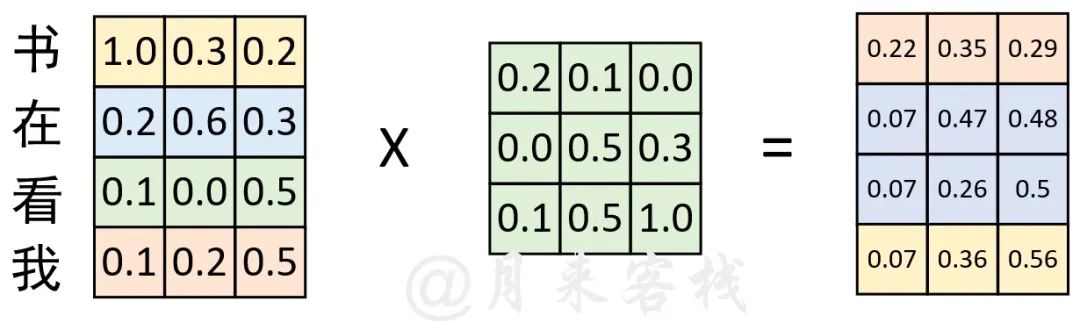
根据上图的计算结果来看,序列在交换位置前和交换位置后计算得到的结果在本质上并没有任何区别,仅仅只是交换了对应的位置。因此,基于这样的原因,Transformer在原始输入文本进行Token Embedding后,又额外的加入了一个Positional Embedding来刻画数据在时序上的特征。
首先通过一幅图直观看看经过Positional Embedding处理后到底产生了什么样的变化。

如上图所示,横坐标表示输入序列中的每一个Token,每一条曲线或者直线表示对应Token在每个维度上对应的位置信息。在左图中,每个维度所对应的位置信息都是一个不变的常数;而在右图中,每个维度所对应的位置信息都是基于某种公式变换所得到。换句话说就是,左图中任意两个Token上的向量都可以进行位置交换而模型却不能捕捉到这一差异,但是加入右图这样的位置信息模型却能够感知到。例如位置20这一处的向量,在左图中无论你将它换到哪个位置,都和原来一模一样;但在右图中,你却再也找不到与位置20处位置信息相同的位置。

如上图所示,原始输入在经过Token Embedding后,又加入了一个常数位置信息的的Positional Embedding。在经过一次线性变换后便得到了图右边所示的结果。接下来,我们再交换序列的位置,并同时进行Positional Embedding观察其结果。

如上图所示,在交换序列位置后,采用同样的Positional Embedding进行处理,并且进行线性变换。可以发现,其计算结果同上图(我在看书)中的计算结果本质上也没有发生变换。因此,这就再次证明,如果Positional Embedding中位置信息是以常数形式进行变换,那么这样的Positional Embedding是无效的。
在Transformer中,作者采用了如公式所示的规则来生成各个维度的位置信息:
$PE_{pos,2i}=sin(pos/10000^{2i/d_{model}}) $
$PE_{pos,2i+1}=cos(pos/10000^{2i/d_{model}}) $
其中

最终,在融入这种非常数的Positional Embedding位置信息后,便可以得到如下图所示的对比结果。

The Residuals
在继续进行下去之前,我们需要提到一个编码器架构中的细节:在每个编码器中的每个子层(自注意力、前馈网络)的周围都有一个残差连接,并且都跟随着一个“层-归一化”步骤。
层-归一化步骤:https://arxiv.org/abs/1607.06450

如果我们去可视化这些向量以及这个和自注意力相关联的层-归一化操作,那么看起来就像下面这张图描述一样:

解码器的子层也是这样样的。如果我们想象一个2 层编码-解码结构的transformer,它看起来会像下面这张图一样:

Encoder

在transformer的Encoder里面,会分成很多的block

每一个block都是输入一排向量,输出一排向量,你输入一排向量,第一个block输出另外一排向量,再输给另外一个block,到最后一个block,会输出最终的vector sequence,每一个block 其实,并不是neural network的一层,每一个block里面做的事情,是好几个layer在做的事情,在transformer的Encoder里面,每一个block做的事情,大概是这样子的

- input一排vector以后,做self-attention,考虑整个sequence的资讯,Output另外一排vector.
- 接下来这一排vector,会再丢到fully connected的feed forward network里面,再output另外一排vector,这一排vector就是block的输出
事实上在原来的transformer里面,它做的事情是更复杂的
在transformer里面,它加入了一个设计,我们不只是输出这个vector,我们还要把这个vector加上它的input,它要把input拉过来,直接加给输出,得到新的output 。也就是说,这边假设这个vector叫做
得到residual的结果以后,再把它做一件事情叫做normalization,这边用的不是batch normalization,这边用的叫做layer normalization

layer normalization做的事情,比bacth normalization更简单一点
输入一个向量,输出另外一个向量,不需要考虑batch,它会把输入的这个向量,计算它的mean跟standard deviation
但是要注意一下,batch normalization是对不同example,不同feature的同一个dimension,去计算mean跟standard deviation(batch的每个特征归一化)
但layer normalization,它是对同一个feature,同一个example里面,不同的dimension,去计算mean跟standard deviation(每个example归一化)
计算出mean和standard deviation以后,就可以做一个normalize,我们把input 这个vector里面每一个,dimension减掉mean,再除以standard deviation以后得到
得到layer normalization的输出以后,它的这个输出才是FC network的输入。

而FC network这边,也有residual的架构,所以我们会把FC network的input,跟它的output加起来做一下residual,得到新的输出。这个FC network做完residual以后,还不是结束,你要把residual的结果,再做一次layer normalization,得到的输出,才是residual network里面,一个block的输出,所以这个是挺复杂的。

- 首先 你有self-attention,其实在input的地方,还有加上positional encoding,我们之前已经有讲过,如果你只用self-attention,你没有位置的资讯,所以你需要加上positional的information,然后在这个图上,有特别画出positional的information。
- Multi-Head Attention,这个就是self-attention的block,这边有特别强调说,它是Multi-Head的self-attention。
- Add&norm,就是residual加layer normalization,我们刚才有说self-attention,有加上residual的connection,加下来还要过layer normalization,这边这个图上的Add&norm,就是residual加layer norm的意思。
- 接下来,要过feed forward network。
- fc的feed forward network以后再做一次Add&norm,再做一次residual加layer norm,才是一个block的输出。
- 然后这个block会重复n次,这个复杂的block,其实在之后会讲到的,一个非常重要的模型BERT里面,会再用到 ,它其实就是transformer的encoder。
Decoder
Decoder – Autoregressive (AT)
Decoder 要做的事情就是产生输出,也就是产生语音辨识的结果, Decoder 怎么产生这个语音辨识的结果

首先,你要先给它一个特殊的符号,这个特殊的符号代表开始,在助教的投影片里面,是写 Begin Of Sentence,缩写是 BOS

就是 Begin 的意思,这个是一个 Special 的 Token,代表了开始这个事情。在这个机器学习里面,假设你要处理 NLP 的问题,每一个 Token,你都可以把它用一个 One-Hot 的 Vector 来表示,One-Hot Vector 就其中一维是 1,其他都是 0,所以 BEGIN 也是用 One-Hot Vector 来表示,其中一维是 1,其他是 0
接下来Decoder 会吐出一个向量,这个 Vector 的长度很长,跟你的 Vocabulary 的 Size 是一样的

每一个中文的字,都会对应到一个数值,因为在产生这个向量之前,你通常会先跑一个 Softmax,就跟做分类一样,所以这一个向量里面的分数,它是一个 Distribution,也就是它这个向量里面的值全部加起来总和会是 1。

分数最高的一个中文字,它就是最终的输出。在这个例子里面,机的分数最高,所以机,就当做是这个 Decoder 第一个输出。
然后接下来,你把“机”当做是 Decoder 新的 Input,原来 Decoder 的 Input,只有 BEGIN 这个特别的符号,现在它**除了 BEGIN 以外,它还有“机”**作为它的 Input。

所以 Decoder 现在它有两个输入
- 一个是 BEGIN 这个符号
- 一个是“机”
根据这两个输入,它输出一个蓝色的向量,根据这个蓝色的向量里面,给每一个中文的字的分数,我们会决定第二个输出,哪一个字的分数最高,它就是输出,假设"器"的分数最高,"器"就是输出。
然后现在 Decoder
- 看到了 BEGIN
- 看到了"机"
- 看到了"器"
它接下来,还要再决定接下来要输出什么,它可能,就输出"学",这一个过程就反覆的持续下去
所以现在 Decoder
看到了 BEGIN
看到了"机"
看到了"器"
还有"学"
Encoder 这边其实也有输入,等一下再讲 Encoder 的输入,Decoder 是怎么处理的。
所以 Decoder 看到 Encoder 这边的输入,看到"机" ,看到"器" ,看到"学",决定接下来输出一个向量,这个向量里面,"习"这个中文字的分数最高的,所以它就输出"习"。

然后这个 Process ,就反覆持续下去,这边有一个关键的地方,我们特别用红色的虚线把它标出来

也就是说 Decoder 看到的输入,其实是它在前一个时间点,自己的输出,Decoder 会把自己的输出,当做接下来的输入。
我们来看一下这个 Decoder内部的结构长什么样子?

这里先把 Encoder 的部分先暂时省略掉,那在 Transformer 里面,Decoder 的结构,长得是这个样子的,看起来有点复杂,比 Encoder 还稍微复杂一点,
那我们现在先把 Encoder 跟 Decoder 放在一起

稍微比较一下它们之间的差异,那你会发现说,如果我们把 Decoder 中间这一块盖起来,其实 Encoder 跟 Decoder,并没有那么大的差别。

在 Decoder 这边,Multi-Head Attention 这一个 Block 上面,还加了一个 Masked,这个 Masked 的意思是这样子的,这是我们原来的 Self-Attention

Input 一排 Vector,Output 另外一排 Vector,这一排 Vector 每一个输出,都要看过完整的 Input 以后,才做决定,所以输出
当我们把 Self-Attention,转成 Masked Attention 的时候,它的不同点是,现在我们不能再看右边的部分,也就是产生

产生

产生

产生
讲得更具体一点,你做的事情是,当我们要产生

我们这样子不去管这个
那为什么会这样,为什么需要加 Masked?

这件事情其实非常地直觉:我们一开始 Decoder 的运作方式,它是一个一个输出,所以是先有
这跟原来的 Self-Attention 不一样,原来的 Self-Attention,
所以这就是为什么,在那个 Decoder 的那个图上面,Transformer 原始的 Paper 特别跟你强调说,那不是一个一般的 Attention,这是一个 Masked 的 Self-Attention,意思只是想要告诉你说,Decoder 它的 Token,它输出的东西是一个一个产生的,所以它只能考虑它左边的东西,它没有办法考虑它右边的东西。
讲了 Decoder 的运作方式,但是这边,还有一个非常关键的问题,Decoder 必须自己决定输出的 Sequence 的长度。
所以我们要让 Decoder 做的事情,也是一样,要让它可以输出一个断,所以你要特别准备一个特别的符号,这个符号,就叫做断,我们这边用 END 来表示这个特殊的符号。

BEGIN 只会在输入的时候出现,断只会在输出的时候出现,所以在助教的程式里面,如果你仔细研究一下的话,会发现说 END 跟 BEGIN,用的其实是同一个符号,但你用不同的符号,也是完全可以的,也完全没有问题。
这个就是 Autoregressive Decoder ,它运作的方式。
在真实预测时解码器需要将上一个时刻的输出作为下一个时刻解码的输入,然后一个时刻一个时刻的进行解码操作。显然,如果训练时也采用同样的方法那将是十分费时的。因此,在训练过程中,解码器也同编码器一样,一次接收解码时所有时刻的输入进行计算。这样做的好处,一是通过多样本并行计算能够加快网络的训练速度;二是在训练过程中直接喂入解码器正确的结果而不是上一时刻的预测值(因为训练时上一时刻的预测值可能是错误的)能够更好的训练网络。
例如在用平行语料"我 是 谁"<==>"who am i"对网络进行训练时,编码器的输入便是"我 是 谁",而解码器的输入则是"<s> who am i",对应的正确标签则是"who am i <e>"。
假设现在解码器的输入"<s> who am i"在分别乘上一个矩阵进行线性变换后得到了

从上图可以看出,此时已经计算得到了注意力权重矩阵。由第1行的权重向量可知,在解码第1个时刻时应该将20%(严格来说应该是经过softmax后的值)的注意力放到"<s>"上,30%的注意力放到"who"上等等。不过此时有一个问题就是,模型在实际的预测过程中只是将当前时刻之前(包括当前时刻)的所有时刻作为输入来预测下一个时刻,也就是说模型在预测时是看不到当前时刻之后的信息。因此,Transformer中的Decoder通过加入注意力掩码机制来解决了这一问题。
self-attention layers in the decoder allow each position in the decoder to attend to all positions in the decoder up to and including that position. We need to prevent leftward information flow in the decoder to preserve the auto-regressive property. We implement this inside of scaled dot-product attention by masking out (setting to −∞) all values in the input of the softmax which correspond to illegal connections.
如下图所示,左边依旧是通过
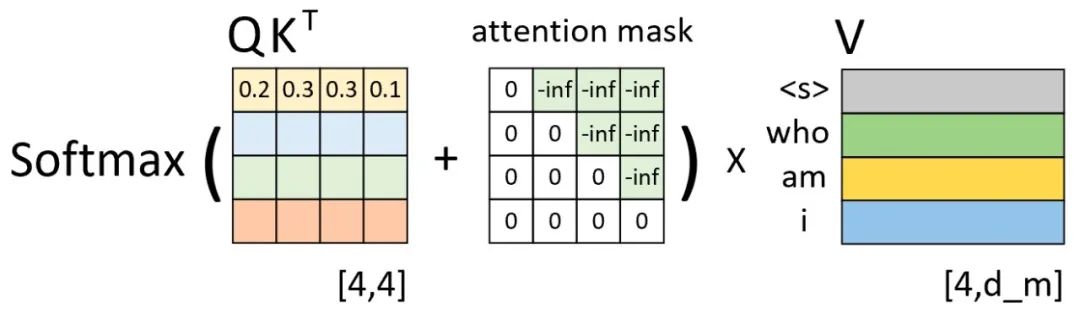
那为什么注意力权重矩阵加上这个注意力掩码矩阵就能够达到这样的效果呢?以上图第1行权重为例,当解码器对第1个时刻进行解码时其对应的输入只有"<s>",因此这就意味着此时应该将所有的注意力放在第1个位置上(尽管在训练时解码器一次喂入了所有的输入),换句话说也就是第1个位置上的权重应该是1,而其它位置则是0。从上上图可以看出,第1行注意力向量在加上第1行注意力掩码,再经过softmax操作后便得到了一个类似的向量。那么,通过这个向量就能够保证在解码第1个时刻时只能将注意力放在第1个位置上的特性。同理,在解码后续的时刻也是类似的过程。
Decoder – Non-autoregressive (NAT)
用两页投影片,非常简短地讲一下,Non-Autoregressive 的 Model

Non-Autoregressive ,通常缩写成 NAT,所以有时候 Autoregressive 的 Model,也缩写成 AT,Non-Autoregressive 的 Model 是怎么运作的
AT v.s. NAT
这个 Autoregressive 的 Model 是

先输入 BEGIN,然后出现 w1,然后再**把 w1 当做输入,再输出 w2,直到输出 END 为止
那 NAT 是这样,它不是依次产生

就假设我们现在产生是中文的句子,它不是依次产生一个字,它是一次把整个句子都产生出来
NAT 的 Decoder可能吃的是一整排的 BEGIN 的 Token,你就把一堆一排 BEGIN 的 Token 都丢给它,让它一次产生一排 Token 就结束了
举例来说,如果你丢给它 4 个 BEGIN 的 Token,它就产生 4 个中文的字,变成一个句子,就结束了,所以它只要一个步骤,就可以完成句子的生成。
这边你可能会问一个问题:刚才不是说不知道输出的长度应该是多少吗,那我们这边怎么知道 BEGIN 要放多少个,当做 NAT Decoder 的输入?

没错 这件事没有办法很自然的知道,没有办法很直接的知道,所以有几个做法
- 一个做法是,你另外learn一个 Classifier,这个 Classifier ,它吃 Encoder 的 Input,然后输出是一个数字,这个数字代表 Decoder 应该要输出的长度,这是一种可能的做法
- 另一种可能做法就是,你就不管三七二十一,给它一堆 BEGIN 的 Token,你就假设说,你现在输出的句子的长度,绝对不会超过 300 个字,你就假设一个句子长度的上限,然后 BEGIN ,你就给它 300 个 BEGIN,然后就会输出 300 个字嘛,然后,你再看看什么地方输出 END,输出 END 右边的,就当做它没有输出,就结束了,这是另外一种处理 NAT 的这个 Decoder,它应该输出的长度的方法
那 NAT 的 Decoder,它有什么样的好处,

它第一个好处是,并行化,这个 AT 的 Decoder,它在输出它的句子的时候,是一个一个一个字产生的,所以你有你的,假设要输出长度一百个字的句子,那你就需要做一百次的 Decode
但是 NAT 的 Decoder 不是这样,不管句子的长度如何,都是一个步骤就产生出完整的句子,所以在速度上,NAT 的 Decoder 它会跑得比,AT 的 Decoder 要快,那你可以想像说,这个 NAT Decoder 的想法显然是在,由这个 Transformer 以后,有这种 Self-Attention 的 Decoder 以后才有的
因为以前如果你是用那个 LSTM ,用 RNN 的话,那你就算给它一排 BEGIN,它也没有办法同时产生全部的输出,它的输出还是一个一个产生的,所以在没有这个 Self-Attention 之前,只有 RNN,只有 LSTM 的时候,根本就不会有人想要做什么 NAT 的 Decoder,不过自从有了 Self-Attention 以后,那 NAT 的 Decoder,现在就算是一个热门的研究的主题了
那 NAT 的 Decoder 还有另外一个好处就是,你比较能够控制它输出的长度,举语音合成为例,其实在语音合成里面,NAT 的 Decoder 算是非常常用的,它并不是一个什么罕见的招数。
比如说有,所以语音合成今天你都可以用,Sequence To Sequence 的模型来做,那最知名的,是一个叫做 Tacotron 的模型,那它是 AT 的 Decoder
那有另外一个模型叫 FastSpeech ,那它是 NAT 的 Decoder,那 NAT 的 Decoder 有一个好处,就是你可以控制你输出的长度,那我们刚才说怎么决定,NAT 的 Decoder 输出多长
你可能有一个 Classifier,决定 NAT 的 Decoder 应该输出的长度,那如果在做语音合成的时候,假设你现在突然想要让你的系统讲快一点,加速,那你就把那个 Classifier 的 Output 除以二,它讲话速度就变两倍快,然后如果你想要这个讲话放慢速度,那你就把那个 Classifier 输出的那个长度,它 Predict 出来的长度乘两倍,那你的这个 Decoder ,说话的速度就变两倍慢
所以你可以如果有这种 NAT 的 Decoder,那你有 Explicit 去 Model,Output 长度应该是多少的话,你就比较有机会去控制,你的 Decoder 输出的长度应该是多少,你就可以做种种的变化
NAT 的 Decoder,最近它之所以是一个热门研究主题,就是它虽然表面上看起来有种种的厉害之处,尤其是平行化是它最大的优势,但是 NAT 的 Decoder ,它的 Performance,往往都不如 AT 的 Decoder

所以发现有很多很多的研究试图让,NAT 的 Decoder 的 Performance 越来越好,试图去逼近 AT 的 Decoder,不过今天你要让 NAT 的 Decoder,跟 AT 的 Decoder Performance 一样好,你必须要用非常多的 Trick 才能够办到,就 AT 的 Decoder 随便 Train 一下,NAT 的 Decoder 你要花很多力气,才有可能跟 AT 的 Performance 差不多
Encoder-Decoder
接下来就要讲Encoder 跟 Decoder它们中间是怎么传递资讯的了,也就是我们要讲,刚才我们刻意把它遮起来的那一块

这块叫做 Cross Attention ,它是连接 Encoder 跟 Decoder 之间的桥樑,那这一块里面啊,会发现有两个输入来自于 Encoder,Encoder 提供两个箭头,然后 Decoder 提供了一个箭头,所以从左边这两个箭头,Decoder 可以读到 Encoder 的输出。
Encoder输入一排向量,输出一排向量,我们叫它

Decoder 会先吃 BEGIN ,那 BEGIN 这个 Special 的 Token 读进来以后,可能会经过 Self-Attention,这个 Self-Attention 是有做 Mask 的,然后得到一个向量,然后接下来把这个向量乘上一个矩阵做一个 Transform,得到一个 Query 叫做

然后这边的
接下来再把

那这一个
所以 Decoder 就是凭借着产生一个
现在假设产生第二个,第一个这个中文的字产生一个“机”,接下来的运作也是一模一样的。

输入 BEGIN 输入“机”,产生一个向量,这个向量一样乘上一个 Linear 的 Transform,得到
Decoder预测解码过程如下图所示

Decoder在对当前时刻进行解码输出时,都会将当前时刻之前所有的预测结果作为输入来对下一个时刻的输出进行预测
Training
已经清楚说 Input 一个 Sequence,是怎么得到最终的输出,那接下来就进入训练的部分。

假设是做语音辨识,那你要有训练资料,你要收集一大堆的声音讯号,每一句声音讯号都要有工读生来听打一下,打出说它的这个对应的词汇是什么

工读生听这段是机器学习,他就把机器学习四个字打出来,所以就知道说你的这个 Transformer,应该要学到听到这段声音讯号,它的输出就是机器学习这四个中文字。
我们已经知道说输入这段声音讯号,第一个应该要输出的中文字是“机”,所以今天当我们把 BEGIN丢给这个 Encoder 的时候,它第一个输出应该要跟“机”越接近越好

“机”这个字会被表示成一个 One-Hot 的 Vector,在这个 Vector 里面,只有机对应的那个维度是 1,其他都是 0,这是正确答案,那我们的 Decoder,它的输出是一个 Distribution,是一个机率的分布,我们会希望这一个机率的分布,跟这个 One-Hot 的 Vector 越接近越好。
所以你会去计算这个 Ground Truth,跟这个 Distribution 它们之间的 Cross Entropy,然后我们希望这个 Cross Entropy 的值,越小越好。

它就跟分类很像,每一次 Decoder 在产生一个中文字的时候,其实就是做了一次分类的问题,中文字假设有四千个,那就是做有四千个类别的分类的问题。
所以实际上训练的时候这个样子,我们已经知道输出应该是“机器学习”这四个字,就告诉你的 Decoder ,现在你第一次的输出 第二次的输出,第三次的输出 第四次输出,应该分别就是“机” “器” “学”跟“习”,这四个中文字的 One-Hot Vector,我们希望我们的输出,跟这四个字的 One-Hot Vector 越接近越好

在训练的时候,每一个输出都会有一个 Cross Entropy,每一个输出跟 One-Hot Vector,跟它对应的正确答案都有一个 Cross Entropy,我们要希望所有的 Cross Entropy 的总和最小,越小越好
所以这边做了四次分类的问题,我们希望这些分类的问题,它总合起来的 Cross Entropy 越小越好,还有 END 这个符号。

那这个就是 Decoder 的训练**:把 Ground Truth ,正确答案给它,希望 Decoder 的输出跟正确答案越接近越好**
那这边有一件值得我们注意的事情,在训练的时候我们会给 Decoder 看正确答案,也就是我们会告诉它说
- 在已经有 "BEGIN",在有"机"的情况下你就要输出"器"
- 有 "BEGIN" 有"机" 有"器"的情况下输出"学"
- 有 "BEGIN" 有"机" 有"器" 有"学"的情况下输出"习"
- 有 "BEGIN" 有"机" 有"器" 有"学" 有"习"的情况下,你就要输出"断"
在 Decoder 训练的时候,我们会在输入的时候给它正确的答案,那这件事情叫做 Teacher Forcing
那这个时候你马上就会有一个问题了
- 训练的时候,Decoder 有偷看到正确答案了
- 但是测试的时候,显然没有正确答案可以给 Decoder 看
刚才也有强调说在真正使用这个模型,在 Inference 的时候,Decoder 看到的是自己的输入,这**中间显然有一个 Mismatch **,那等一下我们会有一页投影片的说明,有什么样可能的解决方式
Answer
1、为什么除以
除以
2、为什么多头
- 模型在对当前位置的信息进行编码时,会过度的将注意力集中于自身的位置
- 使用多头注意力机制还能够给予注意力层的输出包含有不同子空间中的编码表示信息,从而增强模型的表达能力
3、原始Q、K、V来源
根据Transformer结构图可知,在整个Transformer中涉及到自注意力机制的一共有3个部分:Encoder中的Multi-Head Attention;Decoder中的Masked Multi-Head Attention;Encoder和Decoder交互部分的Multi-Head Attention。

- 对于Encoder中的Multi-Head Attention来说,其原始
是Encoder的Token输入经过Embedding后的结果。 别经过一次线性变换(各自乘以一个权重矩阵)后得到了 ,然后再进行自注意力运算得到Encoder部分的输出结果Memory。 - 对于Decoder中的Masked Multi-Head Attention来说,其原始
是Decoder的Token输入经过Embedding后的结果。 别经过一次线性变换后得到了 ,然后再进行自注意力运算得到Masked Multi-Head Attention部分的输出结果,即待解码向量。 - 对于Encoder和Decoder交互部分的Multi-Head Attention,其原始
别是上面的带解码向量和Memory。 别经过一次线性变换后得到了 ,然后再进行自注意力运算得到Decoder部分的输出结果。之所以这样设计也是在模仿传统Encoder-Decoder网络模型的解码过程。