 随机变量的数字特征
随机变量的数字特征
三、随机变量的数字特征
3.1 数学期望(均值)与中位数
数学期望
定义:设随机变量
取有限个可能值 ,其概率分布为 .则 数学期望记作 ,定义为 .数学期望也常称为”均值“,即指以概率为权的加权平均。 离散型变量的数学期望:
(当级数绝对收敛,即 ) 连续型变量的数学期望:
.(当 ) 常见分布的数学期望:
泊松分布:
. 二项分布:
. 均匀分布:
. 指数分布:
. 正态分布:
. 卡方分布:
. 布: . 布: .
性质:
- 若干个随机变量之和的期望等于各变量的期望值和,即
- 若干个独立随机变量之积的期望等于各变量的期望之积,即
- 设随机变量
离散型,有分布 ;或者为连续型,有概率密度函数 .则
- 若
常数,则 .
条件数学期望
- 定义:随机变量 Y 的条件期望就是它在给定的某种附加条件下的数学期望。
.它反映了随着 值 变化 平均变化的情况如何。在统计上,常把条件期望 为 函数,称为 回归函数。 - 性质:
. .
- 定义:随机变量 Y 的条件期望就是它在给定的某种附加条件下的数学期望。
中位数
- 定义:设连续型随机变量
分布函数为 ,则满足条件 数 为 分布 中位数。即 个点把 分布从概率上一切两半。 - 性质:
- 与期望值相比,中位数受特大值或特小值影响很小,而期望不然。
- 中位数可能不唯一,且在某些离散型情况下,中位数不能达到一分两半的效果。
- 定义:设连续型随机变量
3.2 方差与矩
方差与标准差
- 定义:设
随机变量,分布为 ,则 为 (或分布 )的方差,其平方根 (取正值)称为 (或分布 )的标准差。 - 常见分布的方差:
- 泊松分布:
. - 二项分布:
. - 正态分布:
. - 指数分布:
. - 均匀分布:
. - 卡方分布:
. 布: . 布: .
- 泊松分布:
- 性质:
. - 常数的方差为 0,即
. - 若
常数,则 . - 若
常数,则 . - 独立随机变量和的方差等于各变量方差和,即
.
- 定义:设
矩
定义:设
随机变量, 常数, 正整数。则量 为 于 的 矩。特别地,有两种重要的情况: (1)
.这时 为 原点矩。 (2)
.这时 为 中心矩。 一阶原点矩就是期望,一阶中心距
,二阶中心距 是 方差 . 两种重要应用:
- 偏度系数:
.衡量概率分布函数 否关于均值对称。如果 ,则称分布为正偏或右偏;如果 ,则称分布为负偏或左偏;如果 ,则对称。(注: 标准差的三次方,可将 放到一次因次) - 峰度系数:
.衡量概率分布函数 均值附近的陡峭程度。若 正态分布 ,则 .(注: 标准差的四次方,将 放到一次因次。为了迁就正态分布,也常定义 峰度系数,以使正态分布的峰度系数为 0)
- 偏度系数:
3.3 协方差与相关系数
两者都反映了随机变量之间的关系。
协方差(Covariance)
- 定义:称
, 协方差,并记为 . - 性质:
次序无关,即 . . . - 若
立,则 . .等号当且仅当 间有严格线性关系( )时成立。
注:协方差的结果受随机变量量纲影响。
- 定义:称
相关系数(Correlation coefficient)
- 定义:称
相关系数,并记为 . - 性质:
- 若
立,则 . ,或 ,等号当且仅当 严格线性关系时达到。当 ,推出 线性相关。
- 若
注:相关系数常称为“线性相关系数”,实际上相关系数并不是刻画了
间消除量纲后“一般”关系的程度,而只是“线性关系的程度”。即使 某种严格的函数关系但非线性关系, 仅不必为 1,还可以为 0. 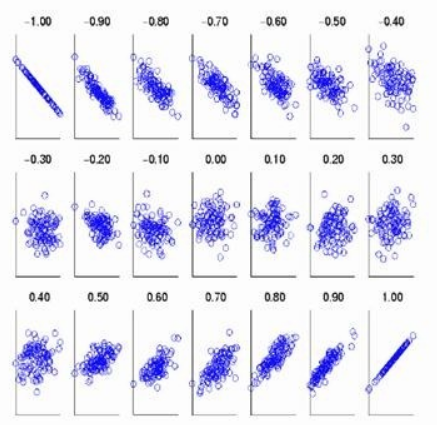
- 定义:称
3.4 大数定理和中心极限定理
大数定理
“大数”的意思,就是指涉及大量数目的观察值
,它表明这种定理中指出的现象只有在大量次数的试验和观察之下才能成立。 - 定义:设
独立同分布的随机变量,记它们的公共均值为 .又设它们的方差存在并记为 .则对任意给定的 ,有 .(该式表明,当 大时, 近 )
- 定义:设
中心极限定理
即和的分布收敛于正态分布。
定义:设
独立同分布的随机变量, .则对任何实数 ,有 .( 标准正态分布 分布函数) 特例:设
立同分布, 布是 , .则对任何实数 ,有 . 注:如果
两个正整数, .则当 当大时,近似地有
其中
若把
正为 在应用上式,则一般可提高精度。
上次更新: 2025/06/25, 11:25:50