 LoRA&MoE综述
LoRA&MoE综述
TODO: 未整理
LoRA遇上MoE,大模型再也不会健忘了
Author: [CastellanZhang]
Link: [https://zhuanlan.zhihu.com/p/685580458]
最近组里同学在尝试实现LoRAMoE,意在解决大模型微调后遗忘世界知识的问题。参考的是复旦23年年底的这篇论文:"LoRAMoE: Revolutionizing Mixture of Experts for Maintaining World Knowledge in Language Model Alignment"[1],将LoRA和MoE方法做了组合,有效解决了上述问题,本文详细讲解一下这篇论文。
1. 背景
大模型经过大量语料的无监督预训练后,得到所谓的基座模型,这时候通常还不能很好地完成下游任务,需要经过有监督的微调(SFT)后才能和人类指令对齐,释放其全部潜力。
一般来说,SFT的训练数据不需要太多,但当下游任务增多或者需要强化特定任务的性能时,增加SFT训练数据还是有必要的。如下图的左侧部分,当SFT数据从100K提升到3M时,大部分任务的性能显著增强。
但随着SFT数据的大规模增加,新的问题出现了:如下图的右侧部分所示,在某些评测数据集上性能显著下降,与之相伴的是大模型的参数变化量剧增(见红色线段)。这些数据集属于闭卷问答任务(Closed-Book Question Answering,简称CBQA),即只给大模型输入问题,大模型主要依靠在预训练过程中习得的世界知识来给出答案。
这里补充一下:像TriviaQA、Natural Questions这类数据其实是包含问题相关上下文的,也就是说如果用作开卷问答任务,则输入不仅包括问题还包括上下文,大模型可以从上下文中总结出答案;但如果用作闭卷问答任务,则输入中不提供上下文。论文[2]中6.1节有提到。
我们有理由怀疑CBQA的性能下降与大模型世界知识的崩溃有关,下面将通过实验证明这一点。首先验证CBQA的推理依赖大模型的世界知识,其次证明CBQA数据集上性能的大幅下降归因于大规模微调会显着改变模型参数,导致世界知识的破坏,即发生知识遗忘。
2. 大规模微调导致世界知识破坏
下面详细介绍一下实验过程,即做实验证明大规模SFT导致大模型的世界知识严重受损,引起知识遗忘。
2.1 实验设计
数据集
准备了7种任务的数据集,分别是CBQA(闭卷问答)、coreference resolution(指代消解)、NLI(自然语言推理)、summarization(文本摘要)、multi-lingual translation(多语言翻译)、reading comprehension(阅读理解)、text classification(文本分类)。具体数据集见下图:
基座模型
采用LLaMA-2-7B作为基座模型,属于在学术界非常流行的LLM之一。
评估
将任务分为两类:CBQA数据集用于评估模型的世界知识,前人工作发现CBQA数据集中有train-test重叠,因此做了过滤,只用未重叠的test集,命名为Filtered TriviaQA和Filtered NQ这种;其他的下游任务用opencompass[3]框架来评测。
2.2 实验结果
用前面说的7种任务的混合数据集微调大模型,数据规模逐渐增加,然后看不同下游任务的性能表现。如下图所示,像左侧的摘要、NLI、机器翻译这类任务,随着SFT训练数据的增加,性能显著提升;但是右侧的CBQA任务,却出现断崖式下跌。
我们已经高度怀疑CBQA的性能下降是由于大模型的世界知识崩坏引起的,为了更加确信,接下来我们仔细实验一下CBQA和大模型的世界知识到底有什么关系,具体做法是单独拿CBQA的25万条样本训练大模型,然后看大模型在未重叠的测试集上的表现。
如下图所示,在训练一开始大约1000样本的时候,性能已经快速提升到了很高的点,后续再增加更多的训练样本其实提升很有限。说明少量样本微调就帮助大模型完成了人类指令的对齐,大模型完成CBQA指标评测的能力主要依靠的是内在的世界知识,而不是微调过程中训练样本灌输的。因此我们更加确性CBQA指标高度依赖大模型在预训练过程中学到的世界知识,上图中CBQA的性能下降的原因就是世界知识的破坏。
再进一步实验,证明是大规模的微调导致了世界知识受损。具体做法如下表:第三列仅用CBQA训练数据微调,是可以CBQA测试集上打败Baseline的;而第四列是分两阶段,先用300万不包换CBQA的数据微调,然后再用和第三列同样的CBQA数据继续微调,结果在CBQA测试集上的表现比Baseline都差很远。
对比一下第三列和第四列,差别只在后者多了一个第一阶段300万数据的微调,说明它正是大模型世界知识崩塌的罪魁祸首,第二阶段即便加上CBQA训练数据,也无法弥补回来。同时发现大模型的参数发生了巨大变化,正好和前面结论相互佐证。
3. LoRAMoE方法
前面的实验表明,有些下游任务需要SFT的训练数据越多越好,即LLM的参数改变越大越好,而有些下游任务需要尽可能保留世界知识,即参数变化越小越好。这种冲突对于一般的全参微调或者LoRA微调都是搞不定的。论文[1]引入了MoE的思想来解决,实现LoRA微调的自适应。题外话,MoE在搜广推领域早就烂大街,这里又用到了LLM微调领域,说明技术都是相通的。
下面先分别介绍一下MoE和LoRA,然后看如何结合。
3.1 MoE简介
MoE全称Mixture of Experts,意味着有多个专家网络投票共同输出结果,只不过每个专家根据输入不同,分配不同的权重。我们可以想象成不同的专家具备不同领域的能力,然后根据输入的特征,给更匹配的专家分配更高的权重,从而动态组合专家输出。
MoE本身是一种思想,需要结合具体模型设计。对于transformer形式的网络,MoE可以将每个block中的前馈网改造成N个结构相同的前馈网
其中,
3.2 LoRA简介
如果大家对推荐系统中的SVD算法了解的话,LoRA的原理就非常简单了,无非用两个低秩矩阵相乘来拟合一个高秩矩阵,只不过这里拟合的不是模型的参数矩阵
其中
按照LoRA的原始论文[4],
$ h=W_0x+\Delta Wx=W_0x+\frac{\alpha}{r}BAx\$
训练过程中,固定
论文[4]中对缩放系数的作用只是很简略的说了一段,令人摸不着头脑。对此我自己做了推导和调研,发现原生的缩放因子并未最佳选择,因和本文主旨无关,后续单独作文述之。
3.3 LoRA+MoE
我们结合LoRA和MoE的优点,将二者组合起来,便是LoRAMoE,看下图所示:
具体做法就是冻结已经预训练好的LLM,然后在FFN层中的每个线性层增加了一组LoRA适配器作为专家网络组,并通过门控网络(路由器机制)分配权重,公式为:
$ o=W_0x+\frac{\alpha}{r}\sum_{i=1}^NG(x)_iB_iA_ix\$
其中,
对照公式我们再回看上面的图4,只能说图中的LoRAMoE部分是个示意图,意会即可。
3.4 专家平衡约束
如果不加任何约束微调MoE,经常会出现门控函数收敛到一种状态,即少数专家掌握了话语权,其他专家权重非常小,失去了平衡。
LoRAMoE人为地将专家分为两组,一组专注于学习下游任务,另一组专注于将世界知识和人类指令对齐。
形式上,我们先给每个LoRAMoE层定义一个重要性矩阵
$ Q_{nm}=\frac{\exp(\omega_n^m/\tau)}{\sum_{k=1}^N\exp(\omega_k^m/\tau)}\$
其中,
然后再给
$ I_{nm}=\begin{cases} 1+\delta,\quad \text{Type}_e(n)=\text{Type}_s(m)\ 1-\delta,\quad \text{Type}_e(n)\ne\text{Type}_s(m) \end{cases}\$
其中,
我们真正使用的是加权版的重要性矩阵
$ \mathcal L_{lbc}=\frac{\sigma^2(Z)}{\mu(Z)}\$
分子分母分别为方差和均值。通过这个损失函数就能够抑制专家强者恒强的现象。
整体损失函数为LLM的损失
3.5 实验
实验参数:
LoRAMoE层只替换LLM中FFN的线性层,且每个LoRAMoE层的专家数为6,其中3个用于下游任务,另外3个用于对齐世界知识。
超参
300万的训练样本,在32张A100上训练。
实验结果:
可以看到,相比于全量微调或者传统的LoRA,本文的方法都取得明显提升,世界知识的遗忘问题也不再发生。详细结论不再细表,总之,LoRA结合上MoE的路由功能,让LoRA的参数增量不再是静态的死板一块,而是可以根据不同任务的输入来动态生成,有效解决了SFT大量训练数据和世界知识遗忘的冲突。
4. 参考文献
[1] LoRAMoE: Revolutionizing Mixture of Experts for Maintaining World Knowledge in Language Model Alignment, 2023
[2] Palm: Scaling language modeling with pathways, 2022
[3] https://opencompass.org.cn/ (opens new window)
[4] Lora: Low-rank adaptation of large language models, 2021https://zhuanlan.zhihu.com/p/677511164)
知识的稀疏性
这种技术出现的原因有三个主要方面:
神经网络的稀疏性: 在特定层中,神经网络可能会变得非常稀疏,即某些神经元的激活频率远低于其他神经元。换句话说,很多神经元并非每次都会被使用到,这和人类大脑中的神经元是类似的。
神经元的多语义性: 神经元的设计使其具有多语义性,这意味着它们可以同时处理多个主题或概念。比如,一个神经元可能对"苹果"、"香蕉"和"橙子"都有反应,这些词代表着不同的实体。
计算资源的有限性:模型规模是提升模型性能的关键因素之一。而不管在什么阶段,资源一定是有限的,在有限的计算资源预算下,用更少的训练步数训练一个更大的模型,往往比用更多的步数训练一个较小的模型效果更佳。
条件计算
References
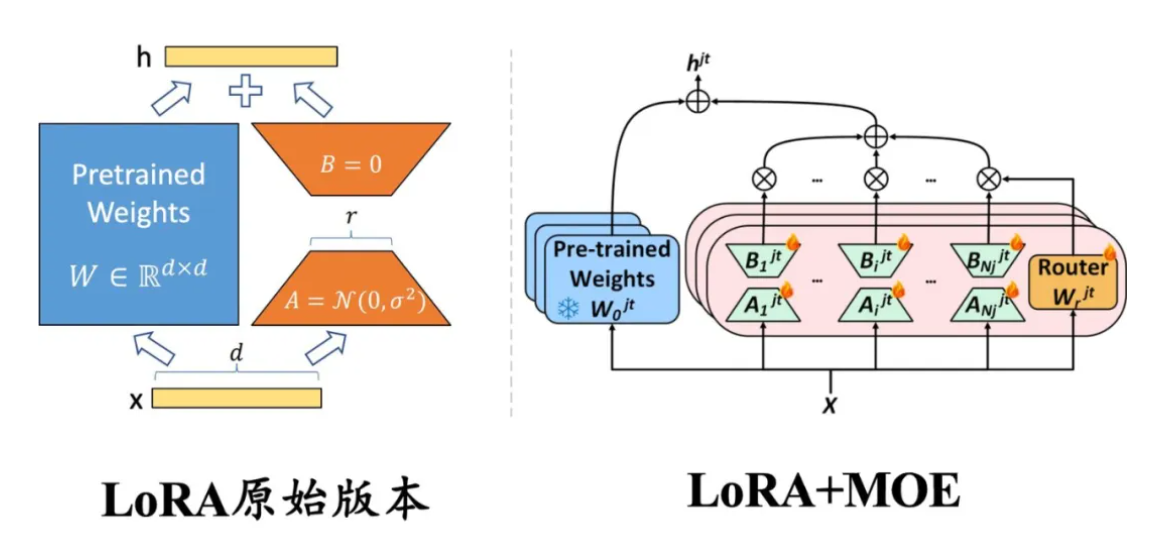
左侧:原始版本的 LoRA,权重是稠密的,每个样本都会激活所有参数;右侧:与混合专家(MoE)框架结合的 LoRA,每一层插入多个并行的 LoRA 权重(即 MoE 中的多个专家模型),路由模块(Router)输出每个专家的激活概率,以决定激活哪些 LoRA 模块。
由于大模型全量微调时的显存占用过大,LoRA、Adapter、
传统上,LoRA 这类适配模块的参数和主干参数一样是稠密的,每个样本上的推理过程都需要用到所有的参数。近来,大模型研究者们为了克服稠密模型的参数效率瓶颈,开始关注以 Mistral、DeepSeek MoE 为代表的混合专家(Mixure of Experts,简称 MoE)模型框架。在该框架下,模型的某个模块(如 Transformer 的某个 FFN 层)会存在多组形状相同的权重(称为专家),另外有一个路由模块(Router)接受原始输入、输出各专家的激活权重,最终的输出为:
- 如果是软路由(soft routing),输出各专家输出的加权求和;
- 如果是离散路由(discrete routing ),即 Mistral、DeepDeek MoE 采用的稀疏混合专家(Sparse MoE)架构,则将 Top-K(K 为固定的 超参数,即每次激活的专家个数,如 1 或 2)之外的权重置零,再加权求和。
在 MoE 架构中,每个专家参数的激活程度取决于数据决定的路由权重,使得各专家的参数能各自关注其所擅长的数据类型。在离散路由的情况下,路由权重在 TopK 之外的专家甚至不用计算,在保证总参数容量的前提下极大降低了推理的计算代价。
Pushing mixture of experts to the limit: Extremely parameter efficient moe for instruction tuning
论文链接:https://arxiv.org/abs/2309.05444
MoV 和 MoLORA:提出于 2023 年 9 月,首个结合 PEFT 和 MoE 的工作,MoV 和 MoLORA 分别是
回顾下
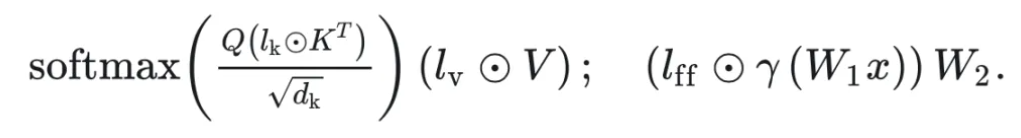
那么,MOV 就是将这些可训练向量各自复制
Revolutionizing mixture of experts for maintaining world knowledge in language model alignment
论文链接:https://arxiv.org/abs/2312.09979
LoRAMOE:提出于 2023 年 12 月,在 MoLORA 的基础上,为解决微调大模型时的灾难遗忘问题,将同一位置的 LoRA 专家分为两组,分别负责保存预训练权重中的世界知识和微调时学习的新任务,并为此目标设计了新的负载均衡 loss。
背景
大模型经过大量语料的无监督预训练后,得到所谓的基座模型,这时候通常还不能很好地完成下游任务,需要经过有监督的微调(SFT)后才能和人类指令对齐,释放其全部潜力。
一般来说,SFT 的训练数据不需要太多,但当下游任务增多或者需要强化特定任务的性能时,增加 SFT 训练数据还是有必要的。如下图的左侧部分,当 SFT 数据从 100K 提升到 3M 时,大部分任务的性能显著增强。
但随着 SFT 数据的大规模增加,新的问题出现了:如下图的右侧部分所示,在某些评测数据集上性能显著下降,与之相伴的是大模型的参数变化量剧增(见红色线段)。这些数据集属于闭卷问答任务(Closed-Book Question Answering,简称 CBQA),即只给大模型输入问题,大模型主要依靠在预训练过程中习得的世界知识来给出答案。
这里补充一下:像 TriviaQA、Natural Questions 这类数据其实是包含问题相关上下文的,也就是说如果用作开卷问答任务,则输入不仅包括问题还包括上下文,大模型可以从上下文中总结出答案;但如果用作闭卷问答任务,则输入中不提供上下文。
SFT 训练会导致模型参数大幅度偏离预训练参数,预训练阶段学习到的世界知识(world knowledge)逐渐被遗忘,虽然模型的指令跟随能力增强、在常见的测试集上性能增长,但需要这些世界知识的 QA 任务性能大幅度下降,作者通过实验也验证了这一点。

作者提出的解决方案是:
数据部分:加入 world knowledge 的代表性数据集 CBQA,减缓模型对世界知识的遗忘;
模型部分:以(1)减少模型参数变化、(2)隔离处理世界知识和新任务知识的参数为指导思想,在 MoLORA 思想上设计了 LoRAMoE 方法,将 LoRA 专家们划分为两组,一组用于保留预训练参数就可以处理好的(和世界知识相关的)任务,一组用于学习 SFT 过程中见到的新任务,如下图所示:
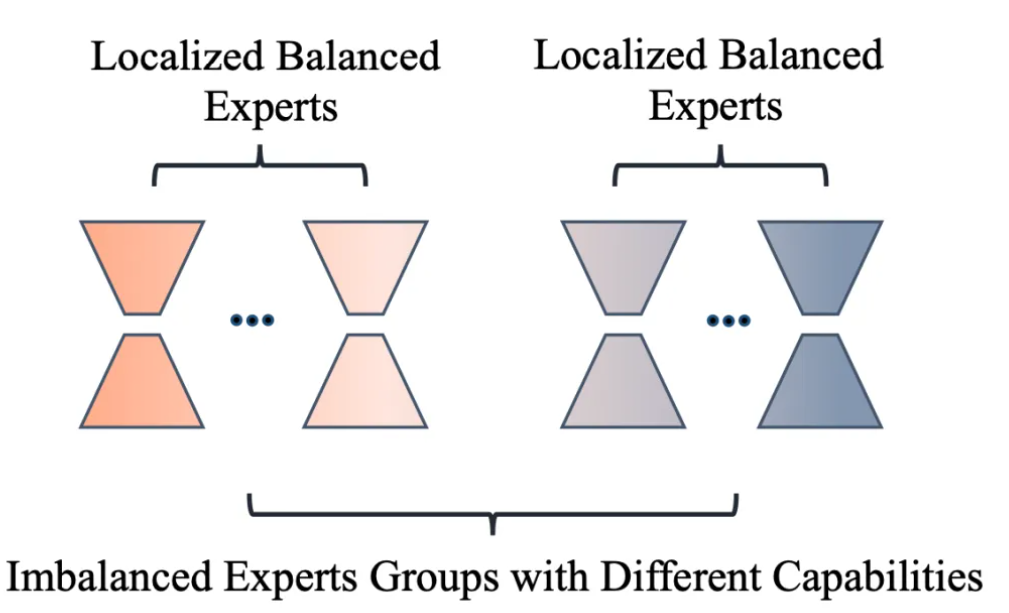
为了训练好这样的分组专家,让两组专家在组间各司其职(分别处理两类任务)、在组内均衡负载,作者设计了一种名为 localized balancing contraint 的负载均衡约束机制。具体地,假设
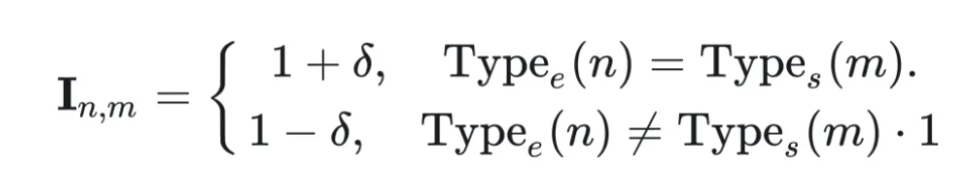
其中
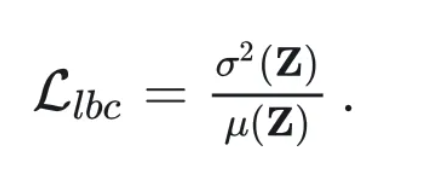
这样设计 loss 的用意是,对任意一种训练样本,两组 LoRA 专家组内的
这种“强者愈强”的极化现象是 MoE 领域的经典问题,可以参见经典的 sMoE 论文 The Sparsely-Gated Mixture-of-Experts Layer 对该问题的阐述。
这样一来,即使推理阶段没有数据类型 的信息,A 对这种数据的路由值 也会显著大于 B 的相应值,这就实现了两组专家各司其职的目标。
实验
LoRAMoE 层只替换 LLM 中 FFN 的线性层,且每个 LoRAMoE 层的专家数为 6,其中 3 个用于下游任务,另外 3 个用于对齐世界知识。
Higher Layers Need More LoRA Experts
https://arxiv.org/abs/2402.08562
MOLA:提出于 2024 年 2 月,使用离散路由(每次只激活路由权重 top-2 的专家),并发现在每一层设置同样的专家个数不是最优的,增加高层专家数目、降低底层专家数目,能在可训练参数量不变的前提下,明显提升 LLaMa-2 微调的效果。
该工作受到 MoE 领域先前工作发现的专家个数过多容易导致性能下降的现象之启发,提出了两个问题:
- 现有 PEFT+MoE 的微调方法是否存在专家冗余的问题?
- 如何在不同中间层之间分配专家个数?
为了解答问题 1,作者训练了每层专家个数均为 5 的 LoRA+MoE(基座模型为 32 层的 LLaMa-2 7B),路由机制采用 Top-2 离散路由,计算了每层 self-attention 的 Q、K、V、O 各组专家权重内两两之间求差的 Frobenius 范数的平均值,可视化如下:

可以看出,层数越高(约接近输出端),专家之间的差异程度越大,而低层的专家之间差异程度非常小,大模型底层的 LoRA 专家权重存在冗余。该观察自然导出了对问题 2 答案的猜想:高层需要更多专家,在各层的专家个数之和固定的预算约束下,应该把底层的一部分专家挪到高层,用原文标题来说就是:Higher Layers Need More Experts
为了验证该猜想,作者提出了四个版本的专家个数划分方式分别严重性能,它们统称为 MoLA(MoE-LoRA with Layer-wise Expert Allocation),分别是:
MoLA-△:正三角形,底层专家个数多,高层专家个数少; MoLA-▽:倒三角形,底层少,高层多; MoLA-▷◁: 沙漏型,两头多、中间少; MoLA-□:正方形,即默认的均匀分配。

具体实现中,作者将 LLaMA 的 32 层从低到高分为 4 组,分别是 1-8、9-16、17-24、25 到 32 层,以上四种划分方式总的专家个数相等,具体划分分别为:
MoLA-△:8-6-4-2 MoLA-▽:2-4-6-8; MoLA-▷◁: 8-2-2-8; MoLA-□:5-5-5-5。
路由机制为 token 级别的 Top-2 路由,训练时加入了负载均衡损失。MoLA 的 LoRA rank=8,基线方法中 LoRA 的秩为 64(可训练参数量略大于上述四种 MoLA,与 MOLA-□ 的 8-8-8-8 版本相同)评测数据集为 MPRC、RTE、COLA、ScienceQA、CommenseQA 和 OenBookQA,在两种设定下训练模型:
- 设定 1:直接在各数据集的训练集上分别微调模型;
- 设定 2:先在 OpenOrac 指令跟随数据集上进行 SFT,再在各数据集的训练集上分别微调模型。
从以下实验结果可以看出,在设定 1 下,MoLA-▽ 都在大多数数据集上都取得了 PEFT 类型方法的最佳性能,远超可训练参数量更大的原始版本 LoRA 和 LLaMA-Adapter,相当接近全量微调的结果。

在设定 2 下,也是倒三角形的专家个数分配方式 MoLA-▽ 最优,验证了“高层需要更多专家”的猜想。

笔者点评:从直觉来看,模型的高层编码更 high-level 的信息,也和目标任务的训练信号更接近,和编码基础语言属性的底层参数相比需要更多调整,和此文的发现相符,也和迁移学习中常见的 layer-wise 学习率设定方式(顶层设定较高学习率,底层设定较低学习率)的思想不谋而合,未来可以探索二者的结合是否能带来进一步的提升。
MoCLE-Mixture of Cluster-conditional LoRA Experts for Vision-language Instruction Tuning
- Cluster-conditional MoE(句向量聚类路由 MoE): 按 instruction(整个句子)在预训练 embedding 模型的向量空间中的聚类中心当作 MoE gate 的输入,而不是采用 token 级别的 routing(每个 token embedding 作为 MoE gate 的输入);
- Universal Expert:每个样本都会用到一个 universal expert,和之前工作中的 universal expert 的主要区别是,它的权重由激活值最大的专家决定(
)

MoV 和 MoLORA:提出于 2023 年 9 月,首个结合 PEFT 和 MoE 的工作,MoV 和 MoLORA 分别是
Multi-Task Dense Prediction via Mixture of Low-Rank Experts
文章提出的 MLoRE 是一种利用低秩(Low-Rank)结构和对专家支路的重新设计的多任务密集预测算法。如图 2 所示,文章所设计的 MLoRE 模块以不同任务的任务特定特征为输入,然后将每个任务特定特征根据路由网络计算出的路由值送入不同的低秩专家网络,低秩专家依靠低秩结构可以拥有更低的参数量。同时,为了保证建模全局任务联系,所有的特征都将通过一个同样的任务通用路径,最后,将来自任务通用路径,任务共享低秩专家网络和任务特定专家网络的特征相加,在建模任务间关系的同时也能生成有区分度的任务特定特征。此外,模块去除了所有路径中的激活函数,实现了重新参数化以减少推理时的计算成本。通过这一设计,MLoRE 模块能够显著提高多任务密集预测的性能,并有效解决了全局任务关系建模和参数计算成本增加的问题。

整体框架:文章所提出的 MLoRE 是基于解码器的多任务密集预测方法。它使用一个训练好的 ViT(Vision Transformer)作为所有任务的编码器。然后在不同的层上提取特征,这些特征通过一个轻量的任务特定卷积层得到该层的任务特定的特征。这些特征被输入到 MLoRE 模块中,从而在建立不同任务之间的联系的同时建立更加具有区分度的特征。经过 MLoRE 处理后,来自不同层的特征最后被连接到一起,通过任务特定的预测头获得不同任务的密集预测。
专家混合模型:在多任务密集预测里,一个专家混合模型通常包含
图片
此外,在有些方法[8]中,会通过稀疏激活的方式减少推理时的计算量,同时让不同的专家学到不同的知识。具体来说,每个任务只会激活对应的路由值在前 k 的专家,其余的专家的知识都和最终结果无关。
低秩专家混合模型:如图 2 所示,文章所提出的低秩混合专家模型主要包含三个支路。其中第一个支路是任务共享通用支路,它包含一个 3x3 的卷积层。来自所有任务的任务特定特征都会通过这一个支路,这一支路也因此会接受来自所有任务的梯度,所以可以建模所有的任务之间的联系。同时,为了防止来自不同的任务的梯度会影响整个模型的优化,这个支路向后传递的梯度被停止,而梯度只会经由其它两个支路进行向后传递。这一支路的设计虽然并不复杂,但是在实验中体现出了对性能的显著的提升,体现了建模所有任务之间的联系对多任务学习的重要性。
第二个支路是任务共享低秩专家支路,这一支路包含
第三个支路是任务特定的低秩专家支路。这一支路为每个任务设定了一个单独的低秩专家,设计这一专家的目的是让 MLoRE 模块能够建模任务之间联系的同时也能提升建模的特征的区分度。
来自三个支路的输出被线性加和到一起,得到最终的任务特定特征,其中第 t 个任务的任务特定特征可以被表示如下:
其中
路由网络的设计:如图 2 所示,每个低秩混合专家支路在每个任务上都由一个路由网络来控制专家的分配,关于路由网络的设计,参照之前的工作Strip pooling: Rethinking spatial pooling for scene parsing (opens new window),文章认为路由中的全局信息也十分重要,所以设计了两条支路,一条支路从通道的角度进行处理,另一条支路从全局的特征角度进行处理,两者结合就可以实现全局的感受野,从而实现更加准确的专家分配,更好地挖掘任务与任务之间的关系。
重参数化:在推理时,为了减少激活大量专家带来的计算量增长,我们把专家和所有支路中的激活函数去除,从而实现全线性的专家网络(可参考Diverse branch block: Building a convolution as an inception-like unit (opens new window))。具体而言,我们首先把所有的低秩专家转化为一个 3x3 的卷积核,然后在推理时,通过对不同的样本和任务计算出不同的路由值之后,对其权重进行加权求和。在Diverse branch block: Building a convolution as an inception-like unit (opens new window)中证明了这样可以得到和正常推理相同的结果,但是因为多个专家网络被转化为单个卷积核,因此能够令计算量不会随着专家数量的增长而增长,同时不损害其学到的任务间关系。
Mixture-of-LoRAs: An Efficient Multitask Tuning for Large Language Models
摘要:首先在每个域上训练一个单独的 LoRA Module,然后训练一个路由器,选择最优的 module 融合到 LLM 的每个 trasnformer 层中。路由器的训练数据是从每个域任务中均匀采样得到。

Routing Strategy
- 采用序列级(sequence-level)的路由策略,训练阶段根据数据标签选择相应的域专家
- Model 的训练和路由的训练分开完成
MoA Architecture
: LLM attention + feed-forward 的权重,训练过程中固定不变 : 路由参数,每层一个,实现方式为两层 MLP : transformer 每层定义的 LoRA
实验结果
MTLoRA: A Low-Rank Adaptation Approach for Efficient Multi-Task Learning
https://arxiv.org/pdf/2403.20320.pdf