 DDP
DDP
Distributed Data Parallel,DDP
使用

不过通过 DP 进行分布式多卡训练的方式容易造成负载不均衡,有可能第一块 GPU 显存占用更多,因为输出默认都会被 gather 到第一块 GPU 上。为此 Pytorch 也提供了torch.nn.parallel.DistributedDataParallel(DDP)方法来解决这个问题。
针对每个 GPU,启动一个进程,然后这些进程在最开始的时候会保持一致(模型的初始化参数也一致,每个进程拥有自己的优化器),同时在更新模型的时候,梯度传播也是完全一致的,这样就可以保证任何一个 GPU 上面的模型参数就是完全一致的,所以这样就不会出现DataParallel那样显存不均衡的问题。
进程组的相关概念
- GROUP:进程组,默认情况下,只有一个组,一个 job 即为一个组,也即一个 world。(当需要进行更加精细的通信时,可以通过 new_group 接口,使用 world 的子集,创建新组,用于集体通信等。)
- WORLD_SIZE:表示全局进程个数。如果是多机多卡就表示机器数量,如果是单机多卡就表示 GPU 数量。
- RANK:表示进程序号,用于进程间通讯,表征进程优先级。rank = 0 的主机为 master 节点。 如果是多机多卡就表示对应第几台机器,如果是单机多卡,由于一个进程内就只有一个 GPU,所以 rank 也就表示第几块 GPU。
- LOCAL_RANK:表示进程内,GPU 编号,非显式参数,由 torch.distributed.launch 内部指定。例如,多机多卡中 rank = 3,local_rank = 0 表示第 3 个进程内的第 1 块 GPU。
在 单机多卡 场景下,如果使用 PyTorch 提供的
torchrun(或原先的torch.distributed.launch)来做分布式训练,通常不需要手动设置group、WORLD_SIZE、RANK等环境变量。torchrun会在后台自动为每个进程设置好,脚本只需要在代码中使用dist.init_process_group(...)即可。
DDP 的基本用法 (代码编写流程)
- 在使用
distributed包的任何其他函数之前,需要使用init_process_group初始化进程组,同时初始化distributed包。 - 使用
torch.nn.parallel.DistributedDataParallel创建 分布式模型DDP(model, device_ids=device_ids) - 使用
torch.utils.data.distributed.DistributedSampler创建 DataLoader - 使用启动工具
torch.distributed.launch在每个主机上执行一次脚本,开始训练
首先是对代码进行修改,添加参数 --local_rank
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("--local_rank", type=int) # 这个参数很重要
args = parser.parse_args()
2
3
4
这里的 local_rank 参数,可以理解为torch.distributed.launch在给一个 GPU 创建进程的时候,给这个进程提供的 GPU 号,这个是程序自动给的,不需要手动在命令行中指定这个参数。
local_rank = int(os.environ["LOCAL_RANK"]) #也可以自动获取
然后在所有和 GPU 相关代码的前面添加如下代码,如果不写这句代码,所有的进程都默认在你使用CUDA_VISIBLE_DEVICES参数设定的 0 号 GPU 上面启动
torch.cuda.set_device(args.local_rank) # 调整计算的位置
接下来我们得初始化backend,也就是俗称的后端,pytorch 介绍了以下后端:

可以看到,提供了gloo,nccl,mpi,那么如何进行选择呢,官网中也给了以下建议
经验之谈
- 如果是使用
cpu的分布式计算, 建议使用gloo,因为表中可以看到gloo对cpu的支持是最好的 - 如果使用
gpu进行分布式计算, 建议使用nccl。
- 如果是使用
GPU 主机
- InfiniBand 连接,建议使用
nccl,因为它是目前唯一支持 InfiniBand 和 GPUDirect 的后端。 - Ethernet 连接,建议使用
nccl,因为它的分布式 GPU 训练性能目前是最好的,特别是对于多进程单节点或多节点分布式训练。 如果在使用nccl时遇到任何问题,可以使用gloo作为后备选项。 (不过注意,对于 GPU,gloo目前的运行速度比nccl慢。)
- InfiniBand 连接,建议使用
CPU 主机
- InfiniBand 连接,如果启用了 IP over IB,那就使用
gloo,否则使用mpi - Ethernet 连接,建议使用
gloo,除非有不得已的理由使用mpi。
- InfiniBand 连接,如果启用了 IP over IB,那就使用
当后端选择好了之后, 我们需要设置一下网络接口, 因为多个主机之间肯定是使用网络进行交换, 那肯定就涉及到 IP 之类的, 对于nccl和gloo一般会自己寻找网络接口,不过有时候如果网卡比较多的时候,就需要自己设置,可以利用以下代码
import os
# 以下二选一, 第一个是使用gloo后端需要设置的, 第二个是使用nccl需要设置的
os.environ['GLOO_SOCKET_IFNAME'] = 'eth0'
os.environ['NCCL_SOCKET_IFNAME'] = 'eth0'
2
3
4
可以通过以下操作知道自己的网络接口,输入
ifconfig, 然后找到自己 IP 地址的就是, 一般就是em0,eth0,esp2s0之类的,
从以上介绍我们可以看出, 当使用 GPU 的时候, nccl的效率是高于gloo的,我们一般还是会选择nccl后端,设置 GPU 之间通信使用的后端和端口:
# ps 检查nccl是否可用
# torch.distributed.is_nccl_available ()
torch.distributed.init_process_group(backend='nccl') # 选择nccl后端,初始化进程组
2
3
之后,使用 DistributedSampler 对数据集进行划分。它能帮助我们将每个 batch 划分成几个 partition,在当前进程中只需要获取和 rank 对应的那个 partition 进行训练:
# 创建Dataloader
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=16, sampler=train_sampler)
2
3
注意: testset 不用 sampler
然后使用torch.nn.parallel.DistributedDataParallel包装模型:
# DDP进行训练
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.local_rank])
2
主要代码
import argparse
import torch
from torch.nn.parallel import DistributedDataParallel as DDP
parser = argparse.ArgumentParser()
parser.add_argument("--save_dir", default='')
parser.add_argument("--local_rank", default=-1)
parser.add_argument("--world_size", default=1)
args = parser.parse_args()
# 初始化后端
# world_size 指的是总的并行进程数目
# 比如16张卡单卡单进程 就是 16
# 但是如果是8卡单进程 就是 1
# 等到连接的进程数等于world_size,程序才会继续运行
torch.distributed.init_process_group(backend='nccl',
world_size=ws,
init_method='env://')
torch.cuda.set_device(args.local_rank)
device = torch.device(f'cuda:{args.local_rank}')
model = nn.Linear(2,3).to(device)
# train dataset
# train_sampler
# train_loader
# 初始化 DDP,这里我们通过规定 device_id 用了单卡单进程
# 实际上根据我们前面对 parallel_apply 的解读,DDP 也支持一个进程控制多个线程利用多卡
model = DDP(model,
device_ids=[args.local_rank],
output_device=args.local_rank).to(device)
# 保存模型
if torch.distributed.get_rank() == 0:
torch.save(model.module.state_dict(),
'results/%s/model.pth' % args.save_dir)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
在 ImageNet 上的完整训练代码,请点击Github (opens new window)。
启动
- torch.distributed.launch 启动器
- PyTorch 从 1.10 版本开始推荐使用
torchrun来启动分布式训练
原理
与DP区别
- 多进程 和 DP 不同, DDP 采用多进程,最推荐的做法是每张卡一个进程从而避免单进程带来的影响。 DP 和 DDP 共用一个 parallel_apply 函数,所以 DDP 同样支持单进程多线程多卡操作,自然也支持多进程多线程,不过需要注意一下 world_size。
- 通信效率 DP 的通信成本随着 GPU 数量线性增长,而 DDP 支持 Ring AllReduce,其通信成本是恒定的,与 GPU 数量无关。
- 同步参数 DP 通过收集梯度到 device[0],在device[0] 更新参数,然后其他设备复制 device[0] 的参数实现各个模型同步; DDP 通过保证初始状态相同并且改变量也相同(指同步梯度) ,保证模型同步。
Ring AllReduce
假设我们有
首先我们将要传输的梯度等分成
举个例子,假设现有 5 个 GPU,那么就将梯度分为 5 份,如下图,分别是
Scatter Reduce 流程,从 diagonal 的位置开始传,每次传输时 GPU 之间只有一个块在传输,比如

图 5: Scatter Reduce 流程图
All Gather 的过程也类似,只是将收集到的完整梯度通过通信传播给所有参与的 GPU。
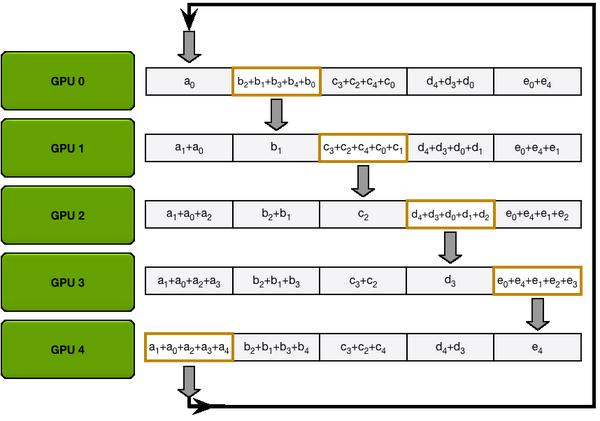
图 6: All Gather 流程图
这样,通信开销就只有
- DDP
DDP 也是数据并行,所以每张卡都有模型和输入。我们以多进程多线程为例,每起一个进程,该进程的 device[0] 都会从本地复制模型,如果该进程仍有多线程,就像 DP,模型会从 device[0] 复制到其他设备。
DDP 通过 Reducer 来管理梯度同步。为了提高通讯效率, Reducer 会将梯度归到不同的桶里(按照模型参数的 reverse order, 因为反向传播需要符合这样的顺序),一次归约一个桶。其中桶的大小为参数 bucket_cap_mb 默认为 25,可根据需要调整。下图即为一个例子。
可以看到每个进程里,模型参数都按照倒序放在桶里,每次归约一个桶。

图 7: Gradient Bucketing 示意图
DDP 通过在构建时注册 autograd hook 进行梯度同步。反向传播时,当一个梯度计算好后,相应的 hook 会告诉 DDP 可以用来归约。当一个桶里的梯度都可以了,Reducer 就会启动异步 allreduce 去计算所有进程的平均值。allreduce 异步启动使得 DDP 可以边计算边通信,提高效率。当所有桶都可以了,Reducer 会等所有 allreduce 完成,然后将得到的梯度写到 param.grad。
实现
DDP 主要基于下图所示结构。至于 backend,NCCL 已经最优化了,建议直接用 NCCL,不过 NCCL 只支持 GPU Tensor 间通信。

- 伪代码

图 9: DDP 伪代码,原图见 [11]
从 DDP 的伪代码我们可以看出,DDP 最重要的包括三部分:
- constructor
- 负责在构建的时候将 rank 0 的 state_dict() 广播 ➜ 保证所有网络初始状态相同;
- 初始化 buckets 并尽可能按逆序将 parameters 分配进 buckets ➜ 按桶通信提高效率;
- 为每个 parameter 加上 grad_accumulator 以及在 autograd_graph 注册 autograd_hook ➜ 在 backward 时负责梯度同步。
- forward
- 正常的 forward 操作;
- 如果 self.find_unused_parameters 设置为 True,DDP 会在 forward 结束时 traverse autograd graph 找到所有没用过的parameters 并标记为 ready ➜ 虽说这一步开销很大,但是有时计算动态图会改变,所以很必要。
- autograd_hook
- 这个 hook 是挂在 autograd graph 在 backward 时负责梯度同步的。当一个梯度计算好后,相应的 hook 会告诉 DDP 可以用来归约。当一个桶里的梯度都可以了,Reducer 就会启动异步 allreduce 去计算所有进程的平均值。当所有桶都可以了,Reducer 会等所有 allreduce 完成,然后将得到的梯度写到 param.grad。
好的,但现在为止我们应该对 DDP 有了大致了解了,接下来就一起看一下代码是怎么实现的!
- 通信
因为 DDP 依赖 c10d 的 ProcessGroup 进行通信,所以开始前我们先要有个 ProcessGroup 实例。这步可以通过 torch.distributed.init_process_group 实现。
除了正常的前向传播,DDP 还允许在 subgraph 进行反向传播,只需将 self.find_unused_parameters 设置为 True。或许有朋友会问,如果 find_unused_parameters 设置为 True,那每次都要 traverse 计算图,明明开销很大,为什么有时候我们还要将 self.find_unused_parameters 设置为 True? 这是因为训练时有可能某次迭代只用到整个模型的一个 subgraph, 并且这个 subgraph 迭代时可能会改变,就是说某些参数可能会在训练时被跳过。但因为所有parameters 在一开始就被分好桶了,而我们的 hook 又规定了只有整个桶 ready 了(pending==0)才会通信,如果我们不将 unused parameter 标记为 ready,整个过程会没法进行。我们在这节结束的部分附上一个小实验验证一下。
DDP 通过在构建时注册 autograd hook 进行梯度同步。当一个梯度计算好后,相应的 hook 会告诉 DDP 可以用来归约。当一个桶里的梯度都可以了,Reducer 就会启动异步 allreduce 去计算所有进程的平均值。当所有桶都可以了,Reducer 会等所有 allreduce 完成,然后将得到的梯度写到 param.grad。
- optimizer step 独立于 DDP,所有进程的模型能够同步是因为初始状态相同并且改变量也相同。
- no_sync