 Self-Attention通过线性变换计算Q K V的原理
Self-Attention通过线性变换计算Q K V的原理
文章来源:为什么Self-Attention要通过线性变换计算Q K V,背后的原理或直观解释是什么? (opens new window)
“线性变换”是机器学习中针对数据常用的变换方式,通过线性变换可以将数据进行降维、解耦、筛选精炼等操作。而 Transformer 中的“线性变换”有着十分独特且重要的意义,它是导致 Multi-Head Attention 机制得以成功运行的根基。
但是要彻底了解 Transformer 中独特的“线性变换”机制,你首先要彻底理解 Q、K、V 三矩阵与生成它们的三个线性变换矩阵
1. Q、K、V三者之间的运算关系
先举个不是100%贴切,但容易让我们理解的例子。
Attention 此时就是将你想要查询的
所以,你也可以理解 Attention 为一个数据库查表的过程:
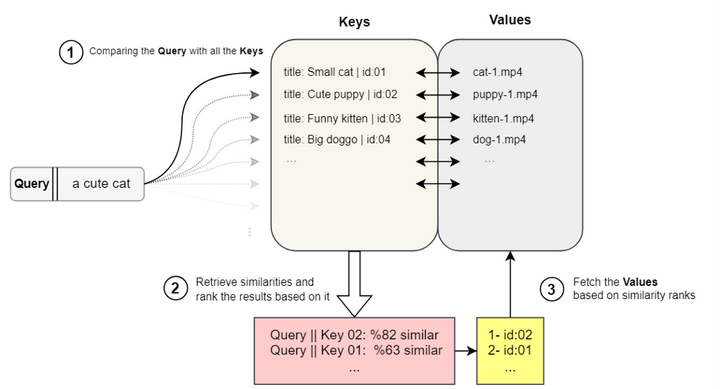
在 YouTube 上搜索“a cute cat”相关的视频,系统运作的大体流程
当然,以上只是一个对
(实际上不是单词,而是 token。token 本质上与“单词”概念是有区别的,token 为词元,即最小语义单位。为了更精准地解释,下面我们将用正规的描述 “token” 来进行讲解。)
既然一个输入序列中,每一个 token 都只有一个 Embedding 向量来表达,那么,我们要如何获得针对这每一个 Embedding 向量进行上面所描述的
2. Q、K、V是如何产生的?与 Multi-Head Attention 有何关系?
在 Attention 机制中,从广义上来说
比如:输入给 Attention 一句话:How are you?。此时系统会首先把这个输入序列转化为四个token(“How”、“are”、“you”、“?”),然后找出这四个 token 互相之间的语义关联度,即 Attention 过程,即“How”与其余三个 token:“are”、“you”、“?”之间的的语义关联度,“are”与其余三个 token:“How”、“you”、“?”之间的的语义关联度,以此类推。
是不是很无聊?四个token之间不用机器,肉眼一看就能懂。
而一本10万字的书呢,机器是怎么通过 Attention 机制几秒钟的时间,一下子就读懂10万字之间的语义关系呢,最终又是怎样了解其中的语义逻辑呢?很明显,无论你输入给机器是四个 token 的一句话,还是10万字的一本书,它都在执行这同一套运算!Attention 都要把输入的序列中的每一个 token,转化成 Embedding 向量,然后再把 Embedding 向量“拆成”或者说是“分解成”、“变幻成”三个矩阵
2.1 W_Q,W_K,W_V 三个权重矩阵的引入与作用
实际上,我们把每个 token 的 Embedding 向量分别做三次线性投影(或称为线性变换),也就是说它与三个具有不同权重的矩阵
而
很多人会在这里感觉很迷惑,
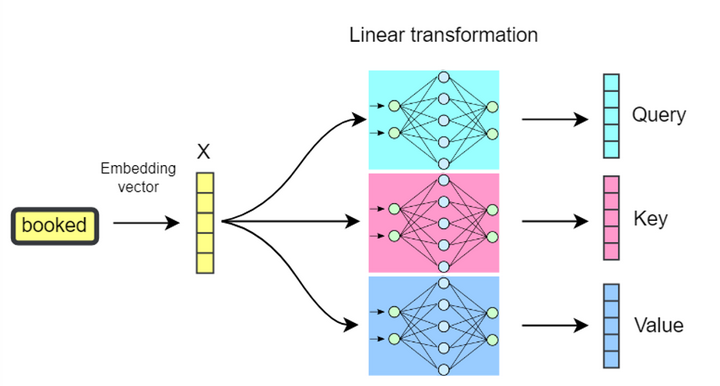
每个 token 的 Embedding 向量分别做三次线性变换获得 Q、K、V 矩阵。
注意,这里因为是把全句子(输入的全序列)拆成具体的 token 来讲解,所以为了理解起来方便,暂用向量来表达。其实,在实际的运算过程中是以矩阵的方式来运行的,以提高运行效率,即整个序列中所有 token 的 Embedding 向量都放在一起组成一个矩阵同时进行运算。所以,该矩阵的维度由输入序列的 token 数
2.2 Multi-head Attention 多头注意力机制的引入
实际上,权重矩阵
512 与 64 差了8倍,也就是说把一个完整的进程分解为了 8 个并列的并行的进程来实施。这个进程被原论文称为“头”,即 head。这 8 个“头”之间互不干扰,各自运算各自的 Attention 机制。8 个头中的每一个头都只采用初始 Embedding 的向量长度 512 的 8 分之一来运行,即通过把 Embedding 向量与
当然,每次 Embedding 向量乘的
所以,这相当于把 Embedding 向量作线性变换的同时,顺便把它“切”成了 8 份来运行。当然,这样的“切”并不是直接在一个长度为 512 的向量上等分 8 份,而是通过与
2.3 Embedding 空间中语义结构的多样性与 Multi-Head 多头之间的关系
这里我们再继续往下深挖,将挖出 Embedding 才是多头背后的真正内在成因。
我之前的文章讲过,在 Embedding 的空间中,一个词的语义逻辑、语法逻辑、上下文逻辑、在全句中位置逻辑、分类逻辑等等,有很多种,如下两图中的几种 word embedding 逻辑。
在 Embedding 的二维空间中 dog、cat、rabbit 三个向量的坐标点位排布,可以看到三个绿色的点距离很近,是因为他们三个相对于其他词汇来说语义上更接近。tree 和 flower 则离它们较远,但是 cat 会因为在很多语言的文章中都会有“爬树”的词汇出现在同一句话中,所以导致 cat 会与 tree 离得较近一些。同时 dog、rabbit 与 tree 的关系就较远。
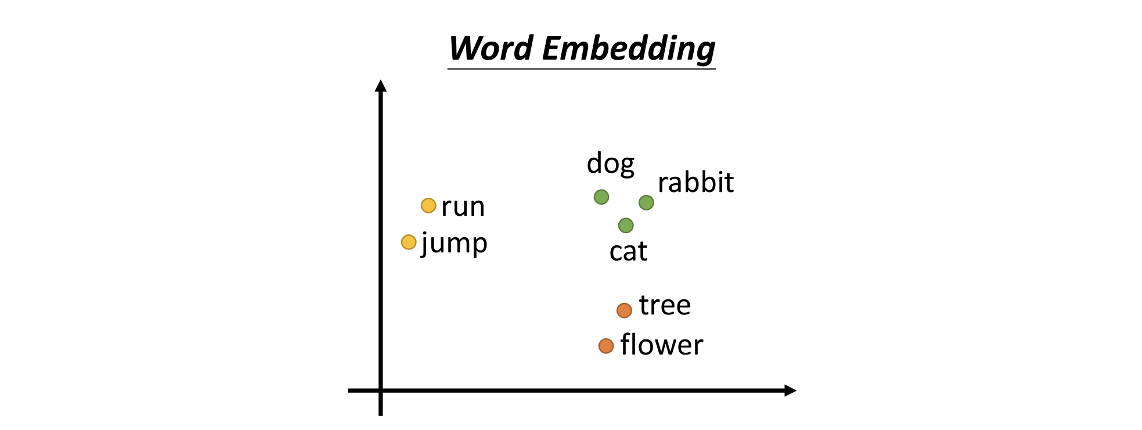
Word Embedding中词语的含义逻辑被自然地聚类
想象一下全世界的所有语言文字里,是不是大体上都是这样,在如此众多的语言文字的资料里,描述“狗”的句子、段落、书籍里,提到“树”的次数,是不是要比描述“猫”的句子、段落、书籍里,提到“树”的次数要少,“兔子”与“树”共同出现就就更少了?这背后透露出了这个世界中的各种事物间的逻辑规律,是 AI 往 AGI 方向发展的内在核心。
这就是 Embedding 最有意思的地方,也是 Embedding 的核心了。我会单独写一篇文章来详细介绍 Embedding 的!这里为了介绍 Multi-Head Attention ,先简要介绍一些 Embedding 的知识点。
我们可以把在 Embedding 想象成一个多维的空间。在这个空间中,词与词之间的关系不仅仅限于像上面所举到的猫、狗与树之间仅仅是因为在海量训练语料中结伴出现的频次所导致了在 Embedding 空间中定位的远近亲疏。一个词所代表的事物与其他词所代表的事物之间能产生内在联系的因素往往有成百上千上万种之多。
比如 man 和 woman,他们之间的关系还会映射出 king 和 queen 之间的关系。同时,语法也会带来一定的联系,比如在 Embedding 空间中,由 walking 到 walked 的距离与斜率竟然与 swimming 到 swam 的距离与斜率一致(即向量的长度与斜率一致),且距离几乎相等,见下图。因为这背后是两组动作单词的现在分词形式和过去分词形式的变化关系。我们可以尽情地想象,凡是事物或概念有逻辑联系的,甚至是逻辑与逻辑之间的联系的,在 Embedding 向量空间中都可以得到远近亲疏的空间表达。
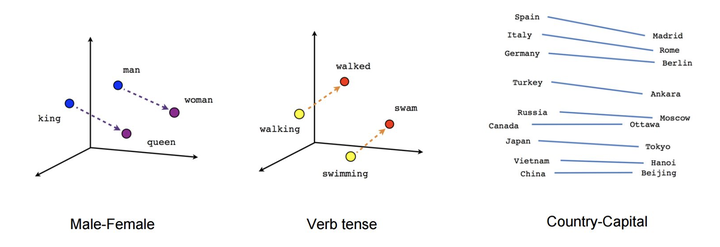
Word Embedding中词语的语法逻辑被自然地表征出来,词语的嵌套逻辑也自然地被表征出来
(注:为了文章中表达方便,我们仅用二维或三维空间来表达,实际上 Embedding 空间的维度很高,至少要在 512 维之上!一维二维三维的空间大家容易在脑中想象出来对应的画面,但是四维以上以至于 512 维就难以图形化的想象了。所以,这里做了简化,以方便大家理解。)
于是,通过把 Embedding 向量线性变幻成 8 个 1/8 的向量再分别去做 Attention 机制运算,这其实在本质上并不会耽误每个 token 的语义表达,而只是细分出了不同的语义子空间,即不同类型的细分语义逻辑而已,Attention 机制运算起来将更细腻精准、更有针对性。
2.4 被 Multi-Head 分解的“语义逻辑子空间”的重要意义
知道了多头的真正内因是 Embedding,那么让我们再看看这个 Embedding 中的语义逻辑子空间:
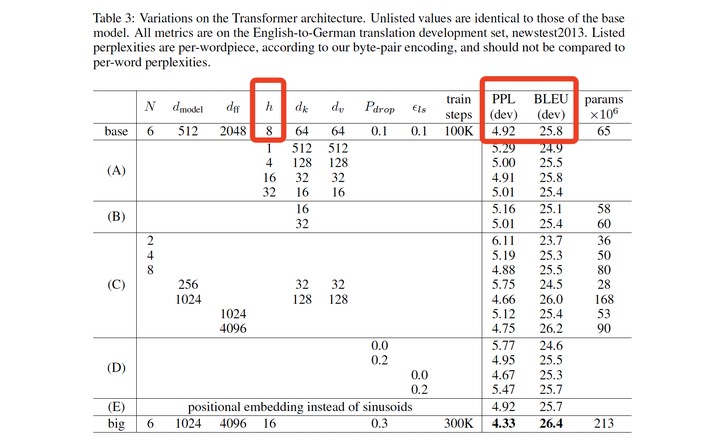
原论文中表格3:BLEU主要考量单词翻译精确度,越高越好。PPL主要考量困惑度,越低越好
虽然从 Embedding 向量的角度看是从 512 维降到了每一个头的 64 维,缩小了,但实际上每一个头 head 同样可以在某个子空间中表达某些细分的语义逻辑。
考虑一下这样的句子“The animal didn't cross the street because it was too tired.”。我们先模拟出两个“头head”来看看它们各自都是把语义逻辑做怎样的细分。下图总共 8 个头之中只启用 2 个头(橙黄色、绿色),可以看出橙黄色的头把 it 关注的细分语义逻辑重点放在了“The”、“animal”上,而绿色的头把 it 关注的细分语义逻辑重点放在了“tired”身上。
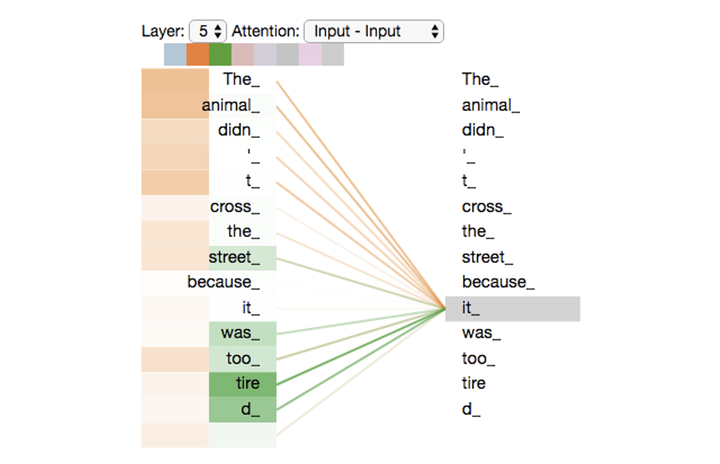
总共8个头中启用2个头的语义逻辑关注点
如果 8 个头全部启用,每个头的语义逻辑关注点则更细腻、更有针对性。这样的细腻性来源于 Embedding 空间的独特表达方式,之所以用 512 维的向量来表达一个 token,说明这个世界上任何一个单词(token)它背后的语义逻辑可以挖掘的点实在是很多很多,别以为 512 太多了(因为有的 Embedding 维度甚至为 1024 呢~),甚至从理论上来说是趋向于无限高维的。在我稍后单独写的一篇有关 Embedding 的文章中会详细解读。当然,你可以用 1024 维来表达,不过一般 512 维的向量就足够丰富了,人间足够用了。再多就带来了运算成本陡然提升的问题了,而效果未必带来长足的提升。
加个题外话,中文语言的 Embedding 语义逻辑子空间的细腻和变化程度,应该比英文高。中文字符为二维的文字,如果把一个汉字转化为 token,其内涵,语义逻辑空间,势必要比靠一维字母组合的语言文字复杂一个数量级。这也导致我们以中文为母语的人类个体思维比较复杂,单位时间内考虑信息量偏多。而西方人比较直线条思维。是高一维度好呢还是低一维度好呢?可以说各有利弊吧…,先到为止,这里就不展开了。

总共8个头全部启用,每个头的语义逻辑关注点
一个头分成8个头,战斗完毕了,还要在变回来,总不能一直是8个头的状态。于是,在 Multi-head Attention 多头注意力机制运算结束后,系统会通过 Concat 方式把 8 个子进程的结果串联起来,并通过另一个线性变换的方式恢复为原 Embedding 的 512 维的向量长度。
如何从 8 头再线性变换回来,稍后再讲解,我们先看看分成8个头后,在每个头中是如何具体运算的。
3. Multi-Head Attention 多头注意力机制的运算方式
3.1 先看看单头的“Attention 注意力机制”的运算方式
针对每一个 token,单头的 Attention 机制运算如下:
- 我们将一个输入序列中其中一个 token 的 Embedding 向量线性变换出来的
向量(下图图例中为 )与同一序列中其他所有 token 的 Embedding 向量线性变换出来的 向量进行比较,计算两者之间的语义关联度得分(即原始论文中所说的点积相似度); - 将这些语义关联度得分转换为权重值,权重数值的大小在 0~1 之间,数值接近 1 代表权重高,即语义逻辑很紧密,比如猫和树。数值接近 0 代表权重低,比如兔子和树。所有权重数值的总和为 1,即 Softmax 归一化;
- 然后,把 Softmax 后的权重值与每个 token 的 Embedding 向量线性变换出来的
做加权和,最终生成结果 (图例中为 )。
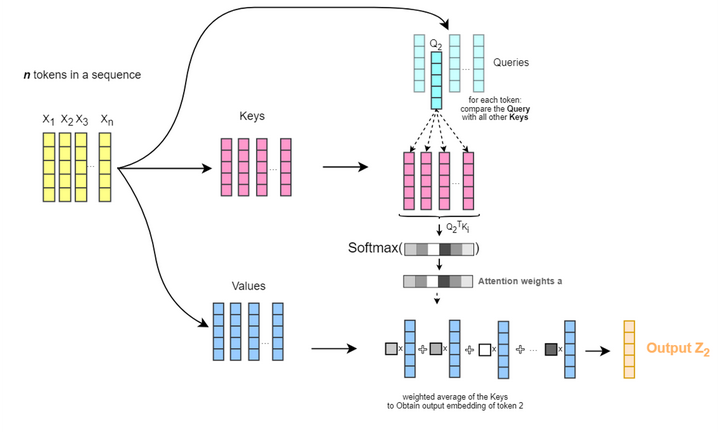
Attention 机制的实际运算架构
如图,在
(注:
下面,用一个具体的例子来解释。
比如这样一句话:“He booked a room at a hotel.”。我们对其中“booked”这个单词(实际上是 token)做 Attention 机制。“booked”会对“He booked a room at a hotel.”这句话中所有的 token ,包括“booked”自己,都做一遍点乘,然后做 Softmax 。再然后,Softmax 后的结果与“He booked a room at a hotel.”转换成的
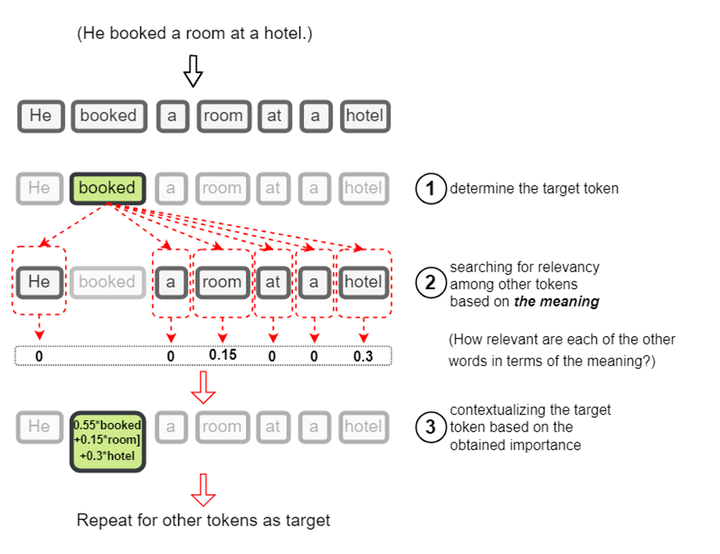
booked 在 Attention 机制处理后诞生了 booked的变体“0.55*booked+0.15*room+0.3*hotel”
从中可以看出“booked”在全句中与“hotel”关联度最大,其次是“room”。所以“booked”这个单词也可以理解为“hotel-room-booked”。这便把“booked”在这句话中的本质通过“变形”给体现出来了。“booked”本身并没有变,而是通过“变形”展示出了另外一种变体状态“hotel-room-booked”。灵魂没变,外在变了。想想哪吒的法身与肉身…
我的上一篇文章中用变形金刚大黄蜂作比喻,说它的灵魂没有变,但是形状变了,由车变成人形机器人了,所以此时的功能也就变了,这也便是 “Transformer”这个词的来源,Google的技术团队就是利用了变形金刚这个词的梗,来直接命名这个技术术语。对此,如果想加深理解,请参看这篇文章:《https://zhuanlan.zhihu.com/p/666206302 (opens new window)》,这是一篇特别有意思的解读!
3.2 “Multi-Head Attention 多头注意力机制”的运算方式
如之前所讲,这样的 Attention 机制(下图中左侧部分为 Attention 机制的架构图)实际上是被分配到了 8 个头 head 之中去分别运行了。每一个头在各自运行之后,再通过 Concat 把得到的结果链接起来,然后再做一次线性变换,变回初始的形状。
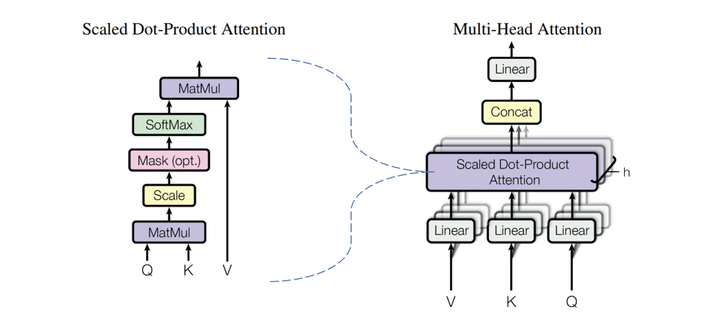
h 个 Scale Dot-Product Attention(左)并行为 Multi-Head Attention(右),在 Transformer 模型中默认 h=8
一个完整的 Embedding 被有机分割成 8 个子语义逻辑的“小Embedding”后进行运算,在运算完之后,便需要把 8 个被 Attention 变换后的“小Embedding”再有机组合成完整的 Embedding。于是就需要把 8 个头中每个头的 Attention 运算结果
3.3W^{O}矩阵的引入和作用
首先我们要知道 Concat 后的矩阵实际上并不是有机地融合 8 个“小Embedding”,而只是简单地做了矩阵的前后链接。而早在当初,分出 8个头 head 时,并非直接在物理层面上八等分切割 512 长度的 Embedding 到 64 长度,而是通过线性变换得来的 8 个具有独立语义逻辑的子空间“小Embedding”。所以在 Multi-Head 运行结束后,在 Concat 后,我们需要通过
这个
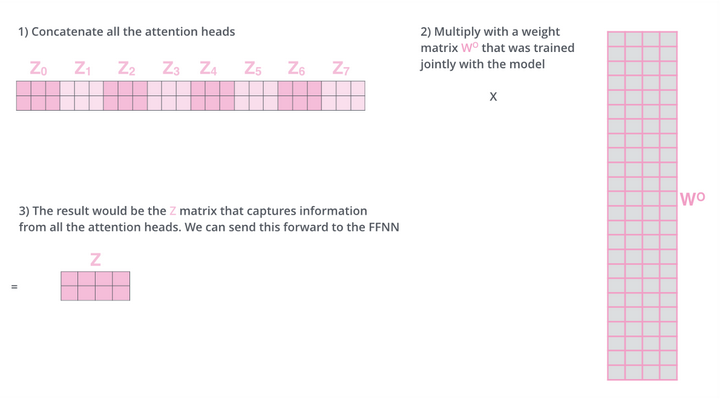
以上,就是对
下面再看看 Multi-Head Attention 的公式表达。
用原论文公式表示为:
where(
注1:
注2:以上公式有一处需要解释一下,针对
上面这些公式,看起来挺唬人,其实当你把 Attention 和 Multi-Head Attention 都搞明白后,再看这些就显得简单多了。
让我们举一个例子,假设一个输入的句子只有两个 token,那么 Attention 和 Multi-Head Attention 是这样运算的:
- 首先,明确几个参数,
=512。设 为默认值 8。 = = = 64。设 =100( 可以等于 、 ,也可以不等于,这里设置 100 并无实际意义,只是为了举例子时方便快速口算)。输入序列为2个 token 转化为 2 个 Embedding 向量,每个向量是 512 维度,即 512 个数值组成的向量,2 个这样的向量就组成了一个形状为 2×512 的矩阵,命名为 矩阵; - 训练好的权重矩阵
和 是形状为 512×64( × )的矩阵。它们把 分别线性转化为 2×64 的 矩阵和 矩阵(在这里,线性转化是通过矩阵乘法执行的,即 × 与 × ); - 然后
与 ( 的转秩矩阵)做矩阵乘法(或者此处可以理解为把 与 拆分为向量做点积,与论文中提到的“ the dot products of the query with all keys”一致,见下图),得到 2×2 矩阵,然后做 运算,产生的结果依旧是 2×2 形状的矩阵,命名为 ;

原论文中《Attention Is All You Need》3.2.1节对“Scaled Dot-Product Attention”以及“compute the matrix”的描述
- 预训练好的权重矩阵
是形状为 512×100( × )的矩阵。它把 线性变化为 2×100 的 矩阵; - 然后,用
的 2×2 矩阵与 的 2×100 矩阵做矩阵乘法,即做 Attention 运算 得到结果 矩阵,形状为 2×100; - 以上的进程做 8 次,即
=1~8。并把每次 Attention 的结果 2×100 的 矩阵 Concat 到一起,得到一个 2×800 的矩阵 ; - 最后,训练好的权重矩阵
是形状为 800×512( × )的矩阵。它把 线性变化成一个 2×512 的新矩阵 。 与初始输入的矩阵 具有完全一样的形状,即 2×512。此时 可以理解为 做过一次 Multi-Head Attention 机制后产生的变体,此变体即为 Transformer 一词的由来。
这就是 Transformer 的核心灵魂,Attention 和 Multi-Head Attention !
至此,我们可以清晰地搞明白,
原论文中表格3:BLEU主要考量单词翻译精确度,越高越好。PPL主要考量困惑度,越低越好
当然,形状的恢复只是
最后,用一图流来把整个 Multi-Head Attention 的四个
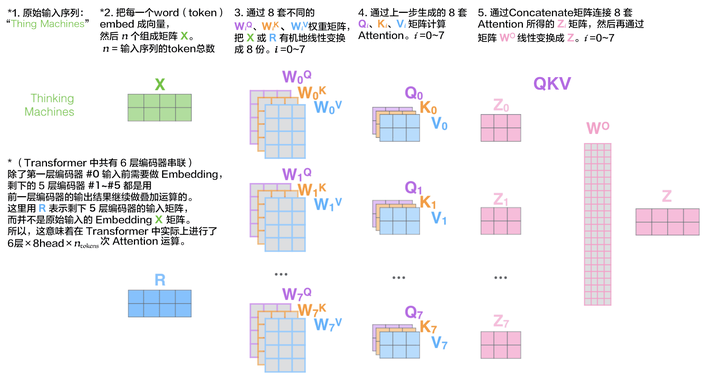
Multi-Head Attention中各要素间关系
4. 对“Multi-Head Attention 多头注意力机制”最通俗易懂的比喻
以上,虽然我已尽量减少用公式来解读,但是对比我一直坚持的“比喻解读”的方式则还是显得有点晦涩难懂。那么让我们看看用纯比喻的描述会是怎样的。
在上一篇文章中(https://zhuanlan.zhihu.com/p/667905865 (opens new window))我用一个公司中新进的一个员工来比喻“Self-Attention 自注意力机制”,这个新员工需要迅速地在全部成员之间做一遍工作岗位关联重要度的“Attention 注意力机制“的审查,以便自己能快速定位出自己在团队中的位置,找准自己的位置,接下来的业务与工作进展自然也会很流畅。
其实,找准个人在团队中的定位,除了在业务流程上的考量外,还有很多其他的维度需要考量,比如职位的权重、性格匹配度、男女比例关系、前辈与新兵、人际关系。等等等等。如果在这些不同的维度领域,都来一套“Attention 注意力机制”,这就叫“Multi-head Attention 多头注意力机制”了。如果说“Self-Attention 自注意力机制”是一个团队成功的基本必要条件,那么“Multi-head Attention 多头注意力机制”就是确保全团队最优协作的充分条件了。
相信任何一个长时间在一起磨合的团队,都会有意无意地走完这个“Multi-head Attention 多头注意力机制”的过程。这个过程可能会很漫长,并伴随着公司中各种大大小小数不尽的事情,但每每经历过一些磨合之后,团队的协作能力就会进一步提高。而且这种磨合的重头戏往往不是只集中在业务流程上,而是在职位、性格、性别、前辈与新兵、人际关系等等方面的磨合上。因为业务流程是团队存在的必须的基础,而其他方面才是团队的升华。
这也好比一个代驾司机,驾驶汽车的刹车油门方向盘的配合,以及交通法规的遵守,那只是作为一个好司机必须的基础,是业务的最底层。但是,服务好客户不能仅靠这些,更需要靠热情的服务态度、整洁的车内外卫生环境、贴心的便利化设施等等周到考量,这便是”Multi-head“的作用和意义!