模型构建
模型构建
模型构建
网络模型的内容如下,包括模型创建和权值初始化,这些内容都在nn.Module中有实现。

创建模型有 2 个要素**:构建子模块和拼接子模块**。如 LeNet 里包含很多卷积层、池化层、全连接层,当我们构建好所有的子模块之后,按照一定的顺序拼接起来。
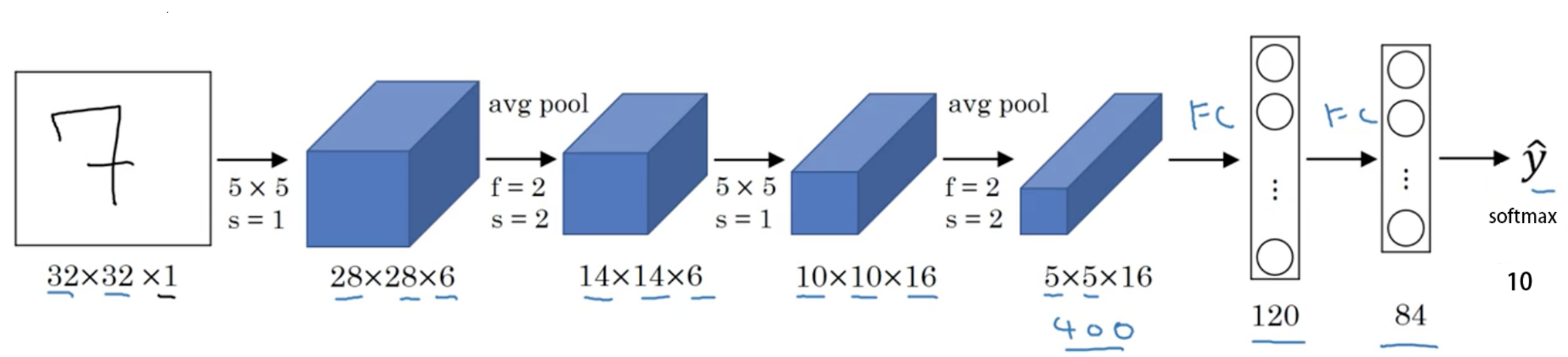
以 lenet.py的 LeNet 为例,继承nn.Module,必须实现__init__()方法和forward()方法。其中__init__()方法里创建子模块,在forward()方法里拼接子模块。
class LeNet(nn.Module):
# 子模块创建
def __init__(self, classes):
super(LeNet, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16*5*5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, classes)
# 子模块拼接
def forward(self, x):
out = F.relu(self.conv1(x))
out = F.max_pool2d(out, 2)
out = F.relu(self.conv2(out))
out = F.max_pool2d(out, 2)
out = out.view(out.size(0), -1)
out = F.relu(self.fc1(out))
out = F.relu(self.fc2(out))
out = self.fc3(out)
return out
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
当我们调用net = LeNet(classes=2)创建模型时,会调用__init__()方法创建模型的子模块。
当我们在训练时调用outputs = net(inputs)时,会进入module.py的call()函数中:
def __call__(self, *input, **kwargs):
for hook in self._forward_pre_hooks.values():
result = hook(self, input)
if result is not None:
if not isinstance(result, tuple):
result = (result,)
input = result
if torch._C._get_tracing_state():
result = self._slow_forward(*input, **kwargs)
else:
result = self.forward(*input, **kwargs)
...
...
...
2
3
4
5
6
7
8
9
10
11
12
13
14
最终会调用result = self.forward(*input, **kwargs)函数,该函数会进入模型的forward()函数中,进行前向传播。
在 torch.nn中包含 4 个模块,如下图所示。

其中所有网络模型都是继承于nn.Module的,下面重点分析nn.Module模块。
nn.Module (opens new window)
nn.Module 是 PyTorch 中神经网络模块的基类。当你在 PyTorch 中定义自己的神经网络模型时,通常会继承这个基类,并实现自己的 __init__ 和 forward 方法。
nn.Module 主要有以下几个重要的参数和方法:
__init__(self): 初始化方法。当你继承nn.Module并创建自己的模型时,需要实现这个方法。在这里,你可以定义模型的层、参数等。forward(self, x): 前向传播方法。这个方法定义了模型如何处理输入数据x并返回输出。你必须实现这个方法。parameters(self): 返回一个生成器,包含模型的所有参数(权重和偏置)。cuda(self, device=None)和to(self, *args, **kwargs): 将模型及其参数移动到指定的设备(如 GPU)。train(self, mode=True): 设置模型为训练模式。当模型在训练模式下时,某些层(如nn.Dropout和nn.BatchNorm2d)的行为会发生变化。eval(self): 设置模型为评估模式。这是训练模式的反操作。state_dict(self): 返回一个字典,包含模型的所有参数。这通常用于保存和加载模型。load_state_dict(self, state_dict): 使用给定的状态字典加载模型的参数。
在 LeNet 的__init__()方法中会调用父类nn.Module的__init__()方法,创建这 8 个属性。
在 LeNet 的__init__()中创建了 5 个子模块,nn.Conv2d()和nn.Linear()都是继承于nn.module,也就是说一个 module 都是包含多个子 module 的。
class LeNet(nn.Module):
# 子模块创建
def __init__(self, classes):
super(LeNet, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16*5*5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, classes)
...
...
...
2
3
4
5
6
7
8
9
10
11
12
当调用net = LeNet(classes=2)创建模型后,net对象的 modules 属性就包含了这 5 个子网络模块。
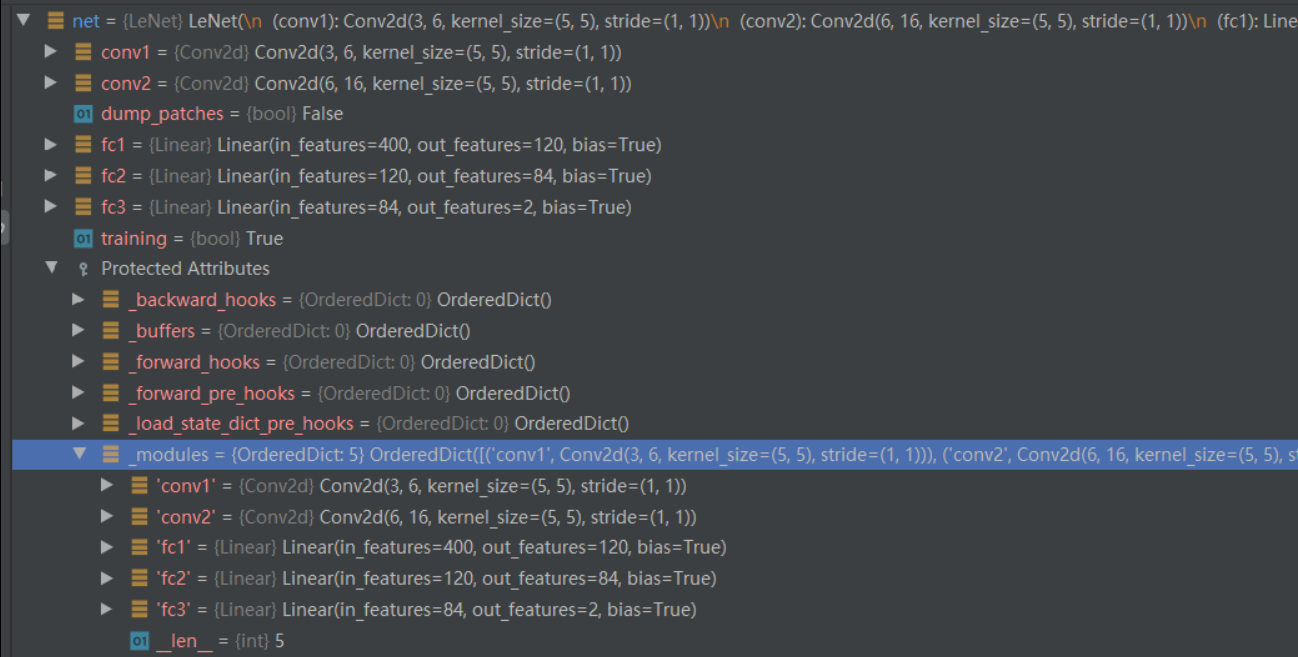
下面看下每个子模块是如何添加到 LeNet 的_modules属性中的。以self.conv1 = nn.Conv2d(3, 6, 5)为例,当我们运行到这一行时,首先 Step Into 进入 Conv2d的构造,然后 Step Out。右键Evaluate Expression查看nn.Conv2d(3, 6, 5)的属性。
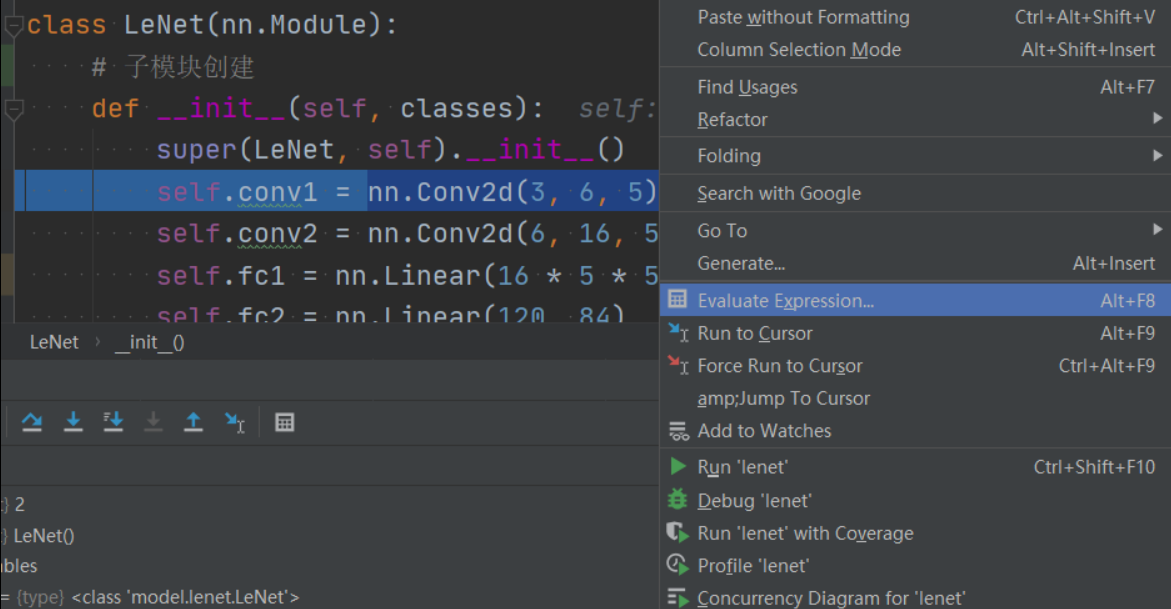
上面说了Conv2d也是一个 module,里面的_modules属性为空,_parameters属性里包含了该卷积层的可学习参数,这些参数的类型是 Parameter,继承自 Tensor。
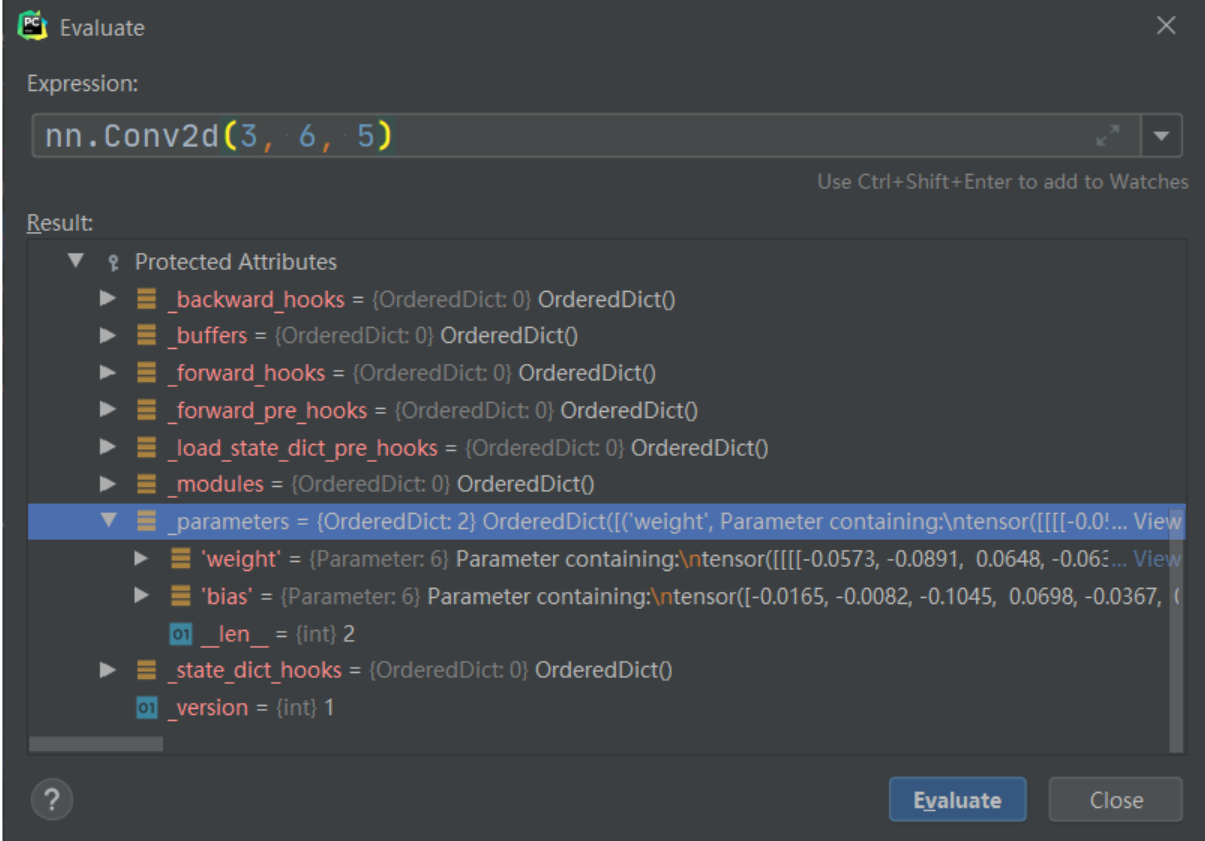
此时只是完成了nn.Conv2d(3, 6, 5)module 的创建。还没有赋值给self.conv1。在nn.Module
里有一个机制,会拦截所有的类属性赋值操作(self.conv1是类属性),进入到__setattr__()函数中。我们再次 Step Into 就可以进入__setattr__()。
def __setattr__(self, name, value):
def remove_from(*dicts):
for d in dicts:
if name in d:
del d[name]
params = self.__dict__.get('_parameters')
if isinstance(value, Parameter):
if params is None:
raise AttributeError(
"cannot assign parameters before Module.__init__() call")
remove_from(self.__dict__, self._buffers, self._modules)
self.register_parameter(name, value)
elif params is not None and name in params:
if value is not None:
raise TypeError("cannot assign '{}' as parameter '{}' "
"(torch.nn.Parameter or None expected)"
.format(torch.typename(value), name))
self.register_parameter(name, value)
else:
modules = self.__dict__.get('_modules')
if isinstance(value, Module):
if modules is None:
raise AttributeError(
"cannot assign module before Module.__init__() call")
remove_from(self.__dict__, self._parameters, self._buffers)
modules[name] = value
elif modules is not None and name in modules:
if value is not None:
raise TypeError("cannot assign '{}' as child module '{}' "
"(torch.nn.Module or None expected)"
.format(torch.typename(value), name))
modules[name] = value
...
...
...
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
在这里判断 value 的类型是Parameter还是Module,存储到对应的有序字典中。
这里nn.Conv2d(3, 6, 5)的类型是Module,因此会执行modules[name] = value,key 是类属性的名字conv1,value 就是nn.Conv2d(3, 6, 5)。
小结
- 一个 module 里可包含多个子 module。比如 LeNet 是一个 Module,里面包括多个卷积层、池化层、全连接层等子 module
- 一个 module 相当于一个运算,必须实现 forward() 函数
- 每个 module 都有 8 个字典管理自己的属性
卷积层
1D/2D/3D 卷积
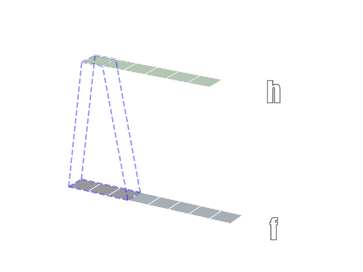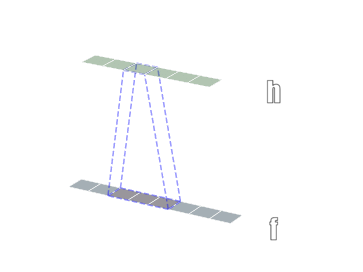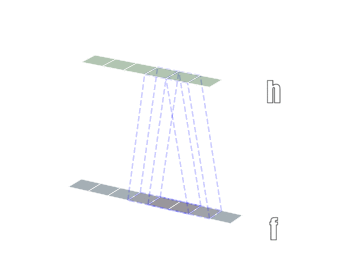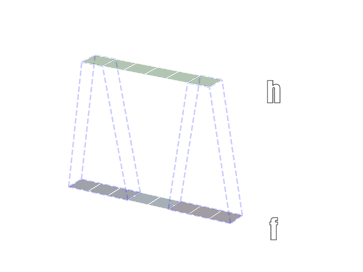
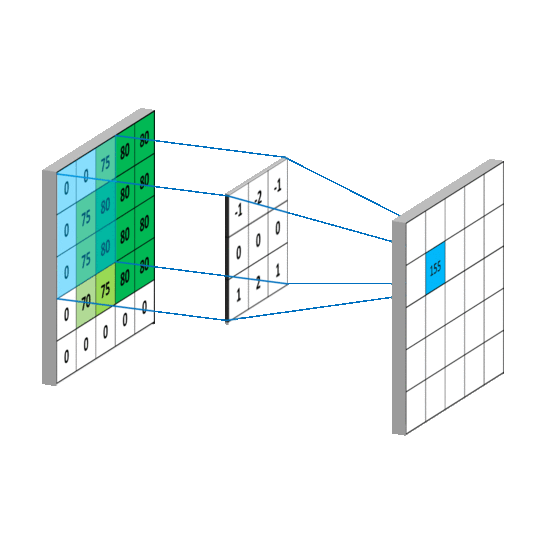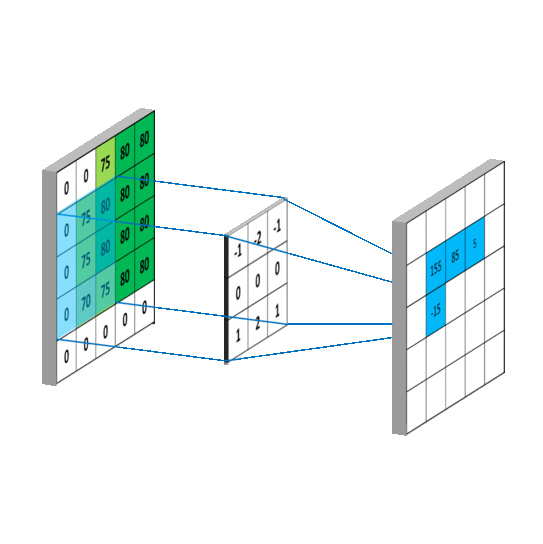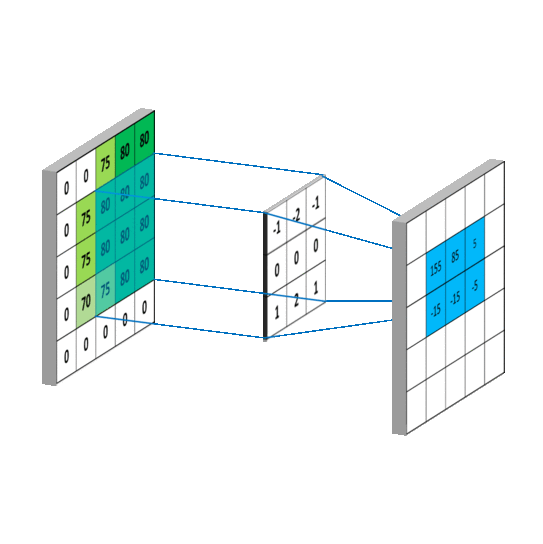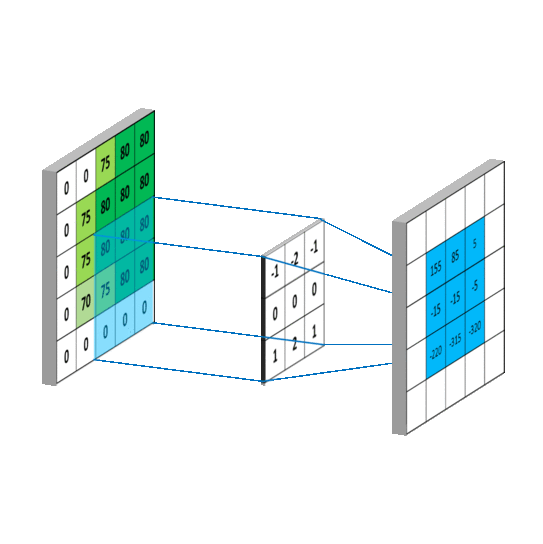
卷积有一维卷积、二维卷积、三维卷积。一般情况下,卷积核在几个维度上滑动,就是几维卷积。比如在图片上的卷积就是二维卷积。
- 一维卷积
- 二维卷积
- 三维卷积
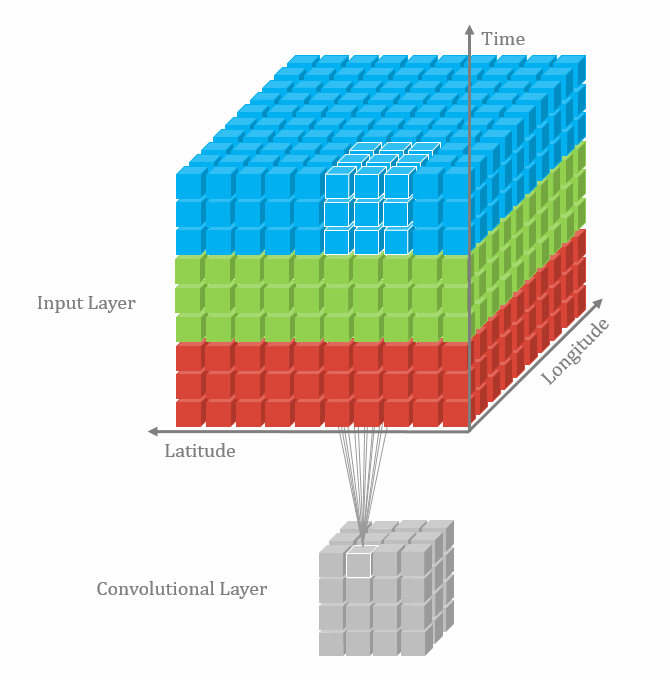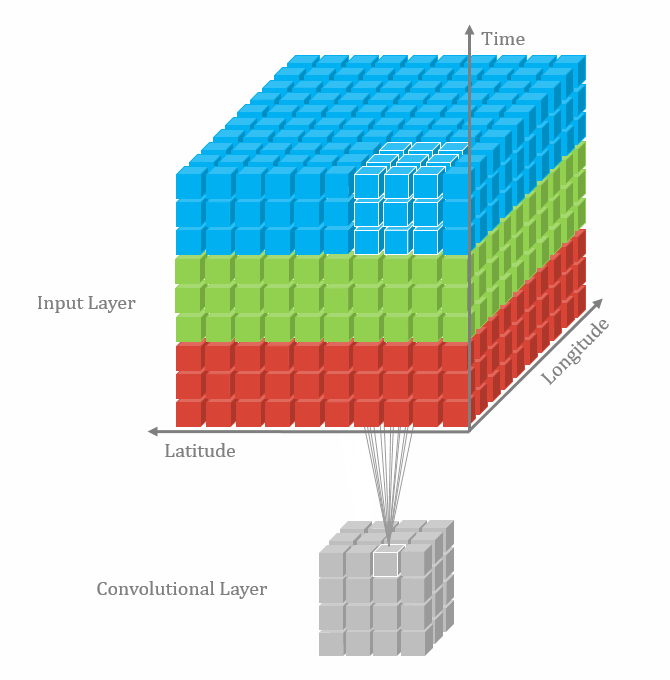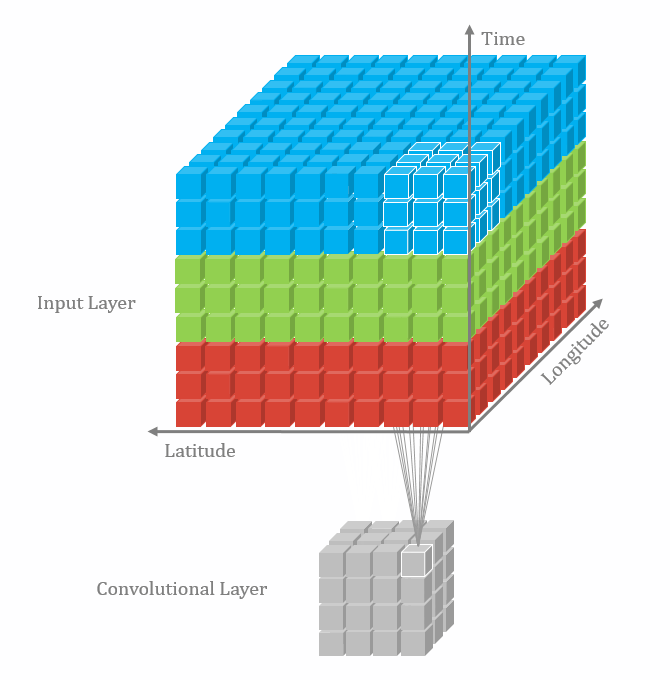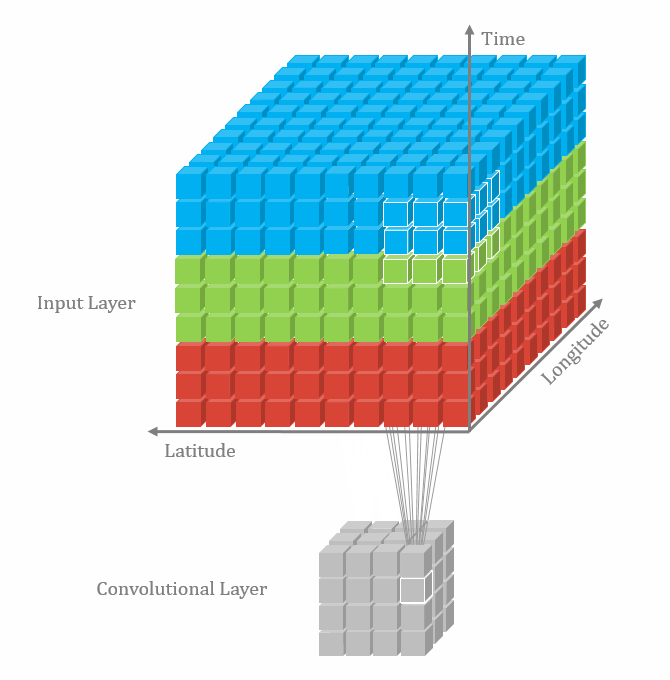
nn.Conv2d() (opens new window)
nn.Conv2d(self, in_channels, out_channels, kernel_size, stride=1,
padding=0, dilation=1, groups=1,
bias=True, padding_mode='zeros')
2
3
这个函数的功能是对多个二维信号进行二维卷积,主要参数如下:
in_channels: 输入数据的通道数。对于彩色 RGB 图像,这个值通常是 3;对于灰度图像,这个值是 1。它代表了输入特征图的深度。
out_channels: 输出数据的通道数,即卷积核的数量。每个卷积核会对输入数据进行卷积操作并生成一个输出特征图,因此
out_channels决定了输出特征图的深度。kernel_size: 卷积核的大小。它可以是一个整数,表示卷积核是正方形的,且其边长为该整数;也可以是一个二元组,如
(height, width),表示卷积核的高度和宽度。stride: 卷积操作的步长。和
kernel_size类似,它也可以是一个整数或二元组。步长决定了卷积核在输入数据上滑动的距离。padding: 输入数据周围的填充大小。填充通常用于控制输出特征图的空间尺寸。它可以是一个整数或二元组。填充不会增加特征图的通道数,只是在外围增加了额外的像素值(通常是 0)。
dilation: 卷积核的扩张率。这个参数允许你控制卷积核中元素之间的间距。通过设置
dilation大于 1,你可以增加卷积核的感受野(即卷积核可以看到的输入区域的大小),而不增加卷积核的参数数量。groups: 控制输入和输出之间的连接。
groups参数决定了输入和输出通道如何被分成不同的组,每个组内的通道使用独立的卷积核。如果groups=1,则进行标准卷积;如果groups=in_channels,则每个输入通道与对应的输出通道进行独立卷积,这被称为深度可分离卷积。bias: 一个布尔值,表示是否给卷积层的输出添加偏置项。默认为
True。padding_mode: 填充的模式。它决定了如何使用填充值。默认为
'zeros',表示使用 0 进行填充。其他可能的值包括'reflect'、'replicate'等。
卷积尺寸计算
简化版卷积尺寸计算
这里不考虑空洞卷积,假设输入图片大小为
下面例子的输入图片大小为
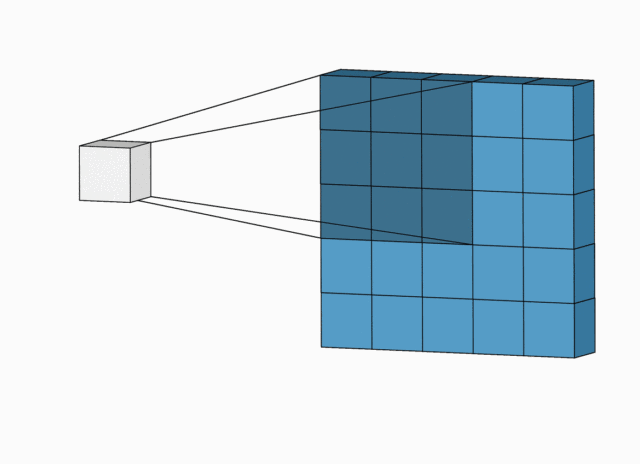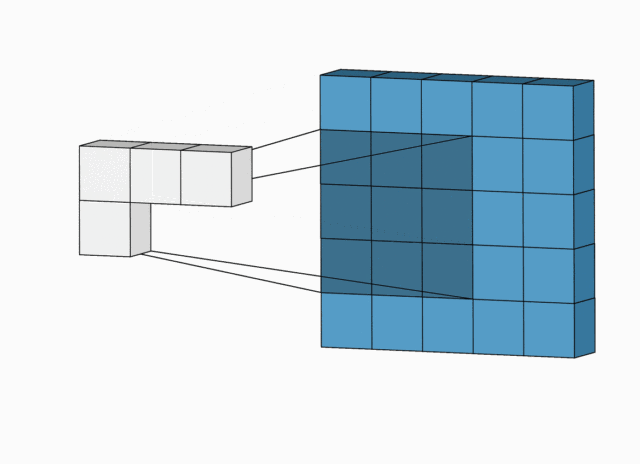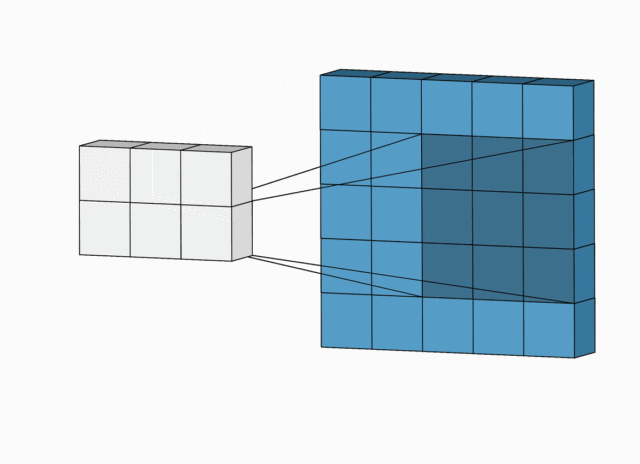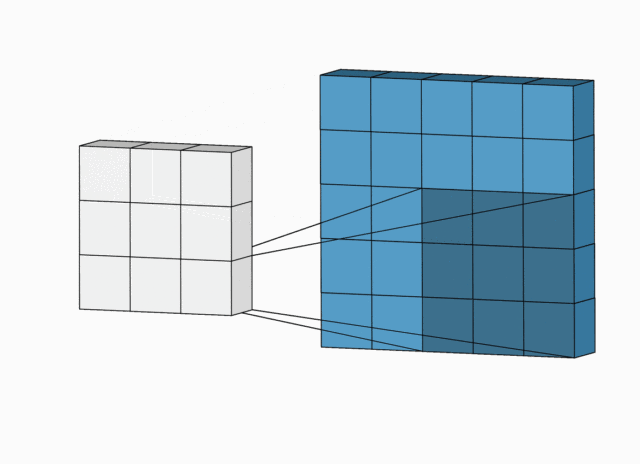
完整版卷积尺寸计算
完整版卷积尺寸计算考虑了空洞卷积,假设输入图片大小为
池化层
池化的作用则体现在降采样:保留显著特征、降低特征维度,增大 kernel 的感受野。 另外一点值得注意:pooling 也可以提供一些旋转不变性。 池化层可对提取到的特征信息进行降维,一方面使特征图变小,简化网络计算复杂度并在一定程度上避免过拟合的出现;一方面进行特征压缩,提取主要特征。
池化层每次对输入数据的一个固定形状窗口(⼜称池化窗口)中的元素计算输出。不同于卷积层里计算输⼊和核的互相关性,池化层直接计算池化窗口内元素的属性(均值、最大值等)。常见的池化包括最大池化或平均池化。在二维最⼤池化中,池化窗口从输入数组的最左上方开始,按从左往右、从上往下的顺序,依次在输⼊数组上滑动。当池化窗口滑动到某⼀位置时,窗口中的输入子数组的最大值即输出数组中相应位置的元素。
最大池化:nn.MaxPool2d()
nn.MaxPool2d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False)
这个函数的功能是进行 2 维的最大池化,主要参数如下:
- kernel_size:池化核尺寸
- stride:步长,通常与 kernel_size 一致
- padding:填充宽度,主要是为了调整输出的特征图大小,一般把 padding 设置合适的值后,保持输入和输出的图像尺寸不变。
- dilation:池化间隔大小,默认为 1。常用于图像分割任务中,主要是为了提升感受野
- ceil_mode:默认为 False,尺寸向下取整。为 True 时,尺寸向上取整
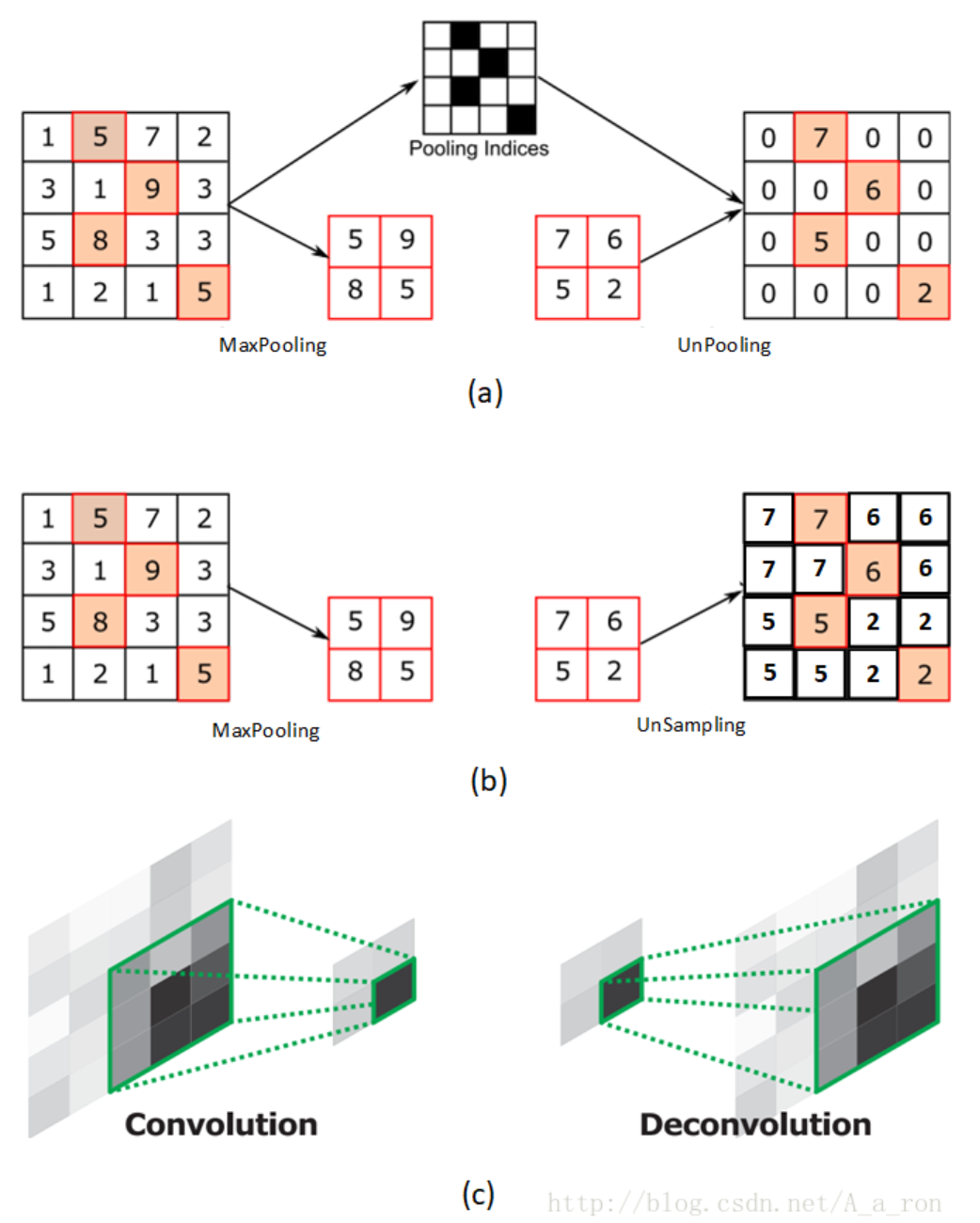
- return_indices:为 True 时,返回最大池化所使用的像素的索引,这些记录的索引通常在反最大池化时使用,把小的特征图反池化到大的特征图时,每一个像素放在哪个位置。
下图 (a) 表示反池化,(b) 表示上采样,(c) 表示反卷积。