 ViT_four secrets
ViT_four secrets
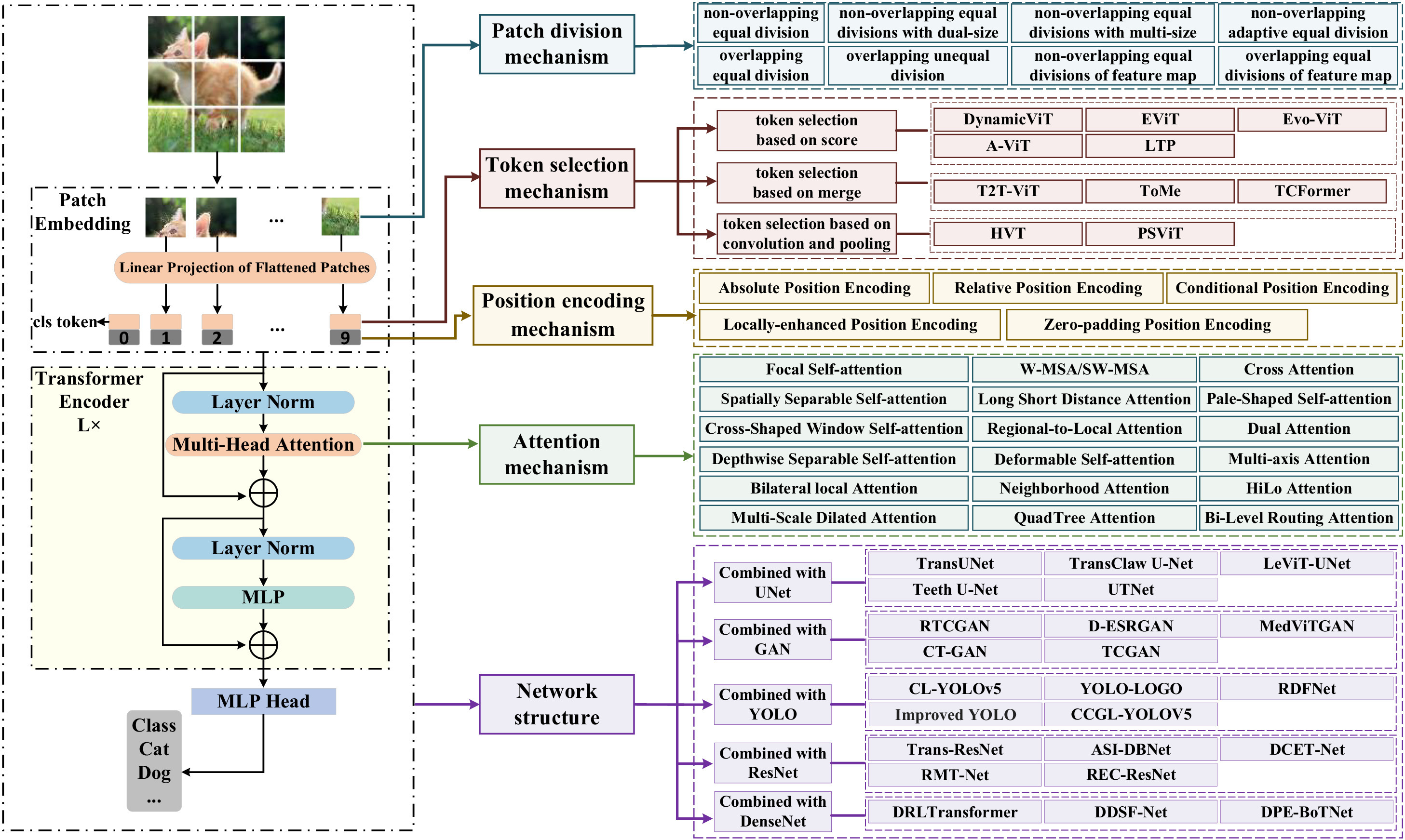
Vision transformer: To discover the “four secrets” of image patches (opens new window)
0. 摘要
视觉Transformer(ViT)在计算机视觉领域被广泛使用,在 ViT 中,有四个主要步骤,即“四个秘密”,如图像块划分、标记选择、位置编码添加和注意力计算,现有的关于计算机视觉中Transformer的研究主要集中在上述四个步骤上。因此,“如何划分图像块?”、“如何选择标记?”、“如何添加位置编码?”和“如何计算注意力?”对于提高 ViT 性能至关重要。但到目前为止,大多数综述文献都是从应用的角度进行总结的,没有相应的文献从技术角度全面总结这四个步骤,这在一定程度上限制了 ViT 的进一步发展。为了解决上述问题,本文总结了 ViT 的 4 个主要机制和 5 个应用,主要创新工作如下:首先,阐述了 ViT 的基本原理和模型结构;其次,针对“如何划分图像块?”,总结了图像块划分机制的 5 项关键技术:从单一尺寸划分到多尺寸划分,从固定数量划分到自适应数量划分,从非重叠划分到重叠划分,从语义分割划分到语义聚合划分,以及从原始图像划分到特征图划分;第三,针对“如何选择标记?”,总结了标记选择机制的 3 项关键技术:基于分数的标记选择、基于合并的标记选择以及基于卷积和池化的标记选择;第四,针对“如何添加位置编码?”,总结了位置编码机制的 5 项关键技术:绝对位置编码、相对位置编码、条件位置编码、局部增强位置编码和零填充位置编码;第五,针对“如何计算注意力?”,基于时间线总结了 18 种注意力机制;第六,讨论了 ViT 在医学图像处理领域的广泛应用,通过与 U-Net、GAN、YOLO、ResNet 和 DenseNet 的结合进行了探讨;最后,围绕本文提出的这四个问题,我们展望了前沿技术的未来发展方向,如图像块划分机制、标记选择机制、位置编码机制和注意力机制等,这些在 ViT 的进一步发展中扮演着重要角色。
1. 引言
Transformer是一种基于自注意力机制的编码器 - 解码器架构模型,最初应用于自然语言处理(NLP)领域。它不仅可以对输入序列元素之间的长期依赖性进行建模,而且在训练和推理过程中支持并行计算,并在语言建模和机器翻译任务中表现出色。Devlin 等人提出了基于Transformer的掩蔽双向编码结构 BERT 模型,该模型通过大规模无监督训练学习丰富的语言表示。此外,许多基于Transformer的语言模型,如 GPTv1、GPTv2、GPTv3、Ro-BERTa、T5 等,在多种语言任务中被广泛使用。随着Transformer在 NLP 领域的快速发展,越来越多的研究者被吸引到计算机视觉(CV)领域。CV 任务通常涉及图像或视频数据。卷积神经网络(CNN)中存在归纳偏差,例如平移不变性和局部敏感性,这些可以捕获图像的细粒度特征和局部特征。然而,基于 CNN 的方法存在有限的感受野问题,这使得它难以对输入信息的全局特征和长距离相关性进行建模。Transformer通过注意力机制获得全局表示,可以对输入信息的全局特征和长距离相关性进行建模。因此,Transformer逐渐在 CV 领域得到应用。ViT 依靠其建模能力,在一些基准数据集上取得了优异的性能,如 ImageNet、COCO 和 ADE20k。在过去的几年中,提出了数百种基于Transformer的模型,用于 CV 领域的各种任务,如分类、检测、分割、跟踪、生成和增强等。ViT 在深度学习领域取得了突破性进展。目前,有许多文献回顾了 ViT 技术的应用进展;Han 等人根据不同任务(即骨干网络、高级视觉、中级视觉、低级视觉和视频处理)回顾了视觉Transformer模型;Liu 等人根据三个基本的 CV 任务(即分类、检测和分割)和数据流类型(即图像、点云、多流数据)回顾了视觉Transformer模型;Khan 等人根据流行的识别任务(如图像分类、目标检测、动作识别和分割)、生成建模、多模态任务(如视觉问题回答、视觉推理和视觉接地)、视频处理(如活动识别、视频预测)、低级视觉(如图像超分辨率、图像增强和着色)和 3D 分析(如点云分类和分割)回顾了视觉Transformer模型。在 ViT 中,有四个主要步骤,即“四个秘密”,如图像块划分、标记选择、位置编码添加和注意力计算,现有的关于计算机视觉中Transformer的研究主要集中在上述四个步骤上。因此,“如何划分图像块?”、“如何选择标记?”、“如何添加位置编码?”和“如何计算注意力?”对于提高 ViT 性能至关重要。但到目前为止,大多数综述文献都是从应用的角度进行总结的,没有相应的文献从技术角度全面总结这四个步骤,这在一定程度上限制了 ViT 的进一步发展。因此,针对上述问题,本文全面总结了 ViT 的 4 个机制和 5 个应用。首先,总结了 ViT 的基本原理和模型结构;其次,针对“如何划分图像块?”,总结了 5 项关键技术:(1)从单一尺寸划分到多尺寸划分,(2)从固定数量划分到自适应数量划分,(3)从非重叠划分到重叠划分,(4)从语义分割划分到语义聚合划分,(5)从原始图像划分到特征图划分;第三,针对“如何选择标记?”,总结了 3 项关键技术:(1)基于分数的标记选择,(2)基于合并的标记选择,(3)基于卷积和池化的标记选择;第四,针对“如何添加位置编码?”,总结了 5 项关键技术:(1)绝对位置编码,(2)相对位置编码,(3)条件位置编码,(4)局部增强位置编码,(5)零填充位置编码;第五,针对“如何计算注意力?”,基于时间线总结了 18 种注意力机制;第六,讨论了 ViT 在医学图像处理领域的广泛应用,通过与 U-Net、GAN、YOLO、ResNet 和 DenseNet 的结合进行了探讨;最后,围绕本文提出的这四个问题,我们展望了前沿技术的未来发展方向,如图像块划分机制、标记选择机制、位置编码机制、注意力机制、构建多任务的统一框架、降低高维数据计算、实现小样本学习、ViT 可解释性等,在 ViT 的进一步发展中扮演着重要角色。
2. ViT 的基本原理
ViT 模型使用经典的Transformer编码器结构来实现图像分类任务,这是视觉Transformer模型的开始。模型结构如图 1(左图)所示。首先,输入图像被划分为固定大小的不重叠图像块;其次,图像块在通道维度上展平为一维向量,并通过对线性映射获得相应的标记;第三,向图像标记集合中添加一个额外的类别标记,类别标记负责聚合全局图像特征和最终分类;第四,向标记中添加位置嵌入以保留位置信息;最后,将向量序列输入到多个串联的Transformer编码器中以计算注意力和提取特征。
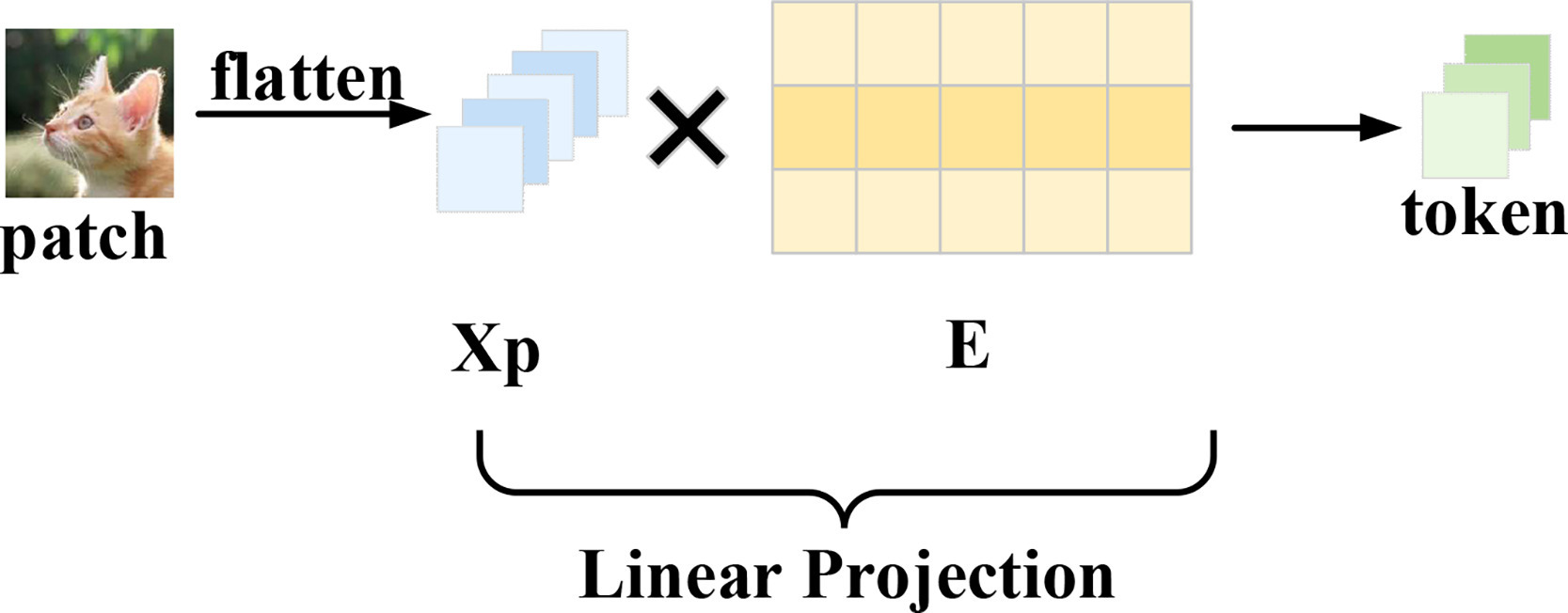
2.1. 图像块嵌入
将图像转换为Transformer编码器的输入序列:步骤 1:2D 图像
2.2. Transformer编码器
Transformer编码器由
其中,公式(1)是输入向量通过 LN、MHSA 和残差连接进行处理;公式(2)是前一步的输出通过 LN、MLP 和残差连接进行处理。
2.3. 多头自注意力
多头自注意力是Transformer编码器的核心部分,其主要操作是自注意力机制。如图 3 所示。自注意力机制减少了对外部信息的依赖,并能更好地捕获数据内部的相关性。首先,使用三个线性变换矩阵
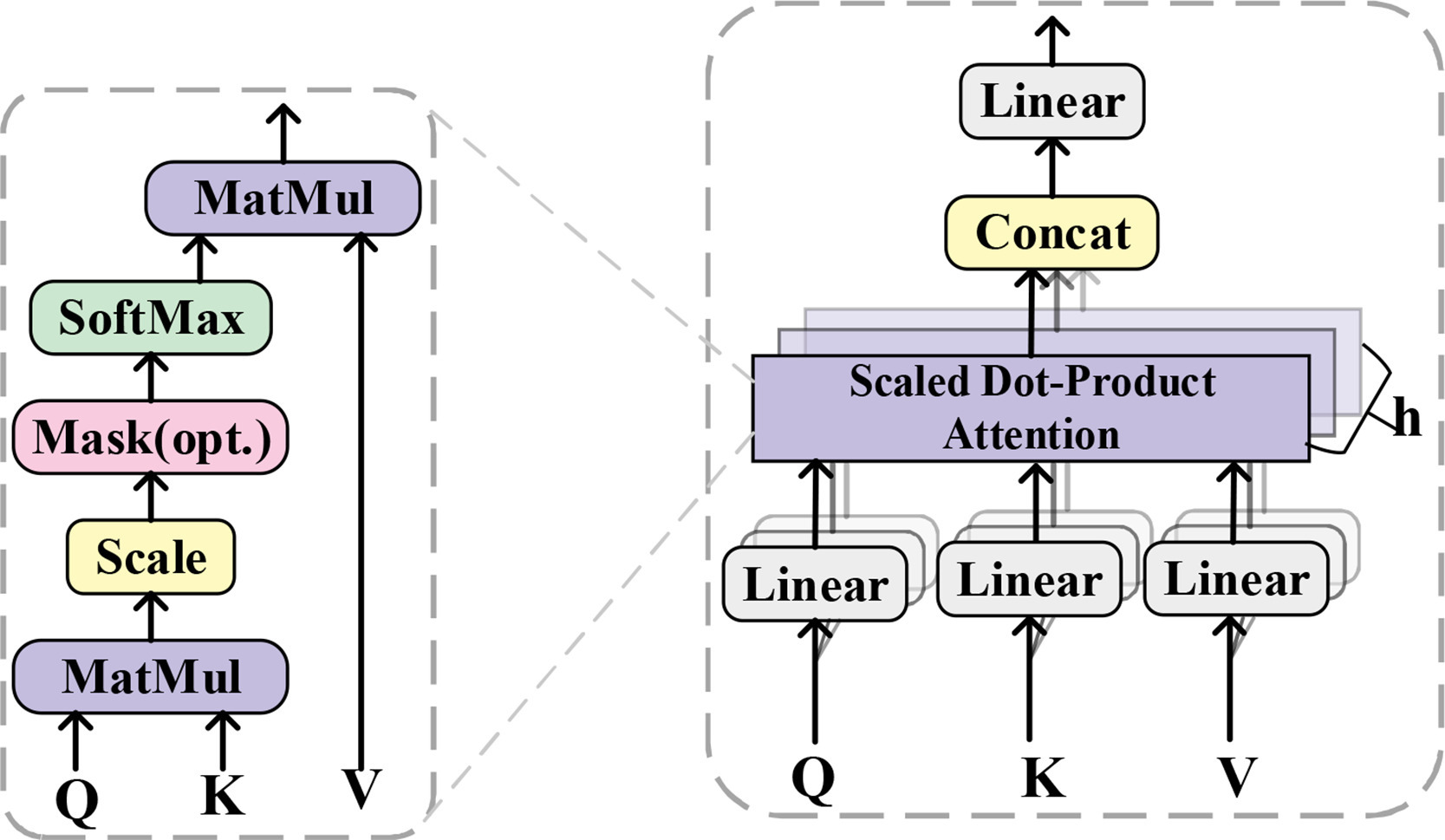
多头自注意力可以看作是自注意力的扩展形式。通过引入多个独立的注意力头,它可以更好地捕获输入序列中的关联信息,并提供更丰富的上下文表示。首先,输入向量与多组参数矩阵
3. 视觉Transformer改进机制
ViT 模型是一种深度神经网络,将输入图像划分为固定大小的一系列不重叠图像块,其中每个图像块被视为一个独立的特征向量,然后通过多头自注意力对不同图像块之间的上下文关系进行建模。总结了图像块划分机制的 5 项关键技术如下:从单一尺寸划分到多尺寸划分,从固定数量划分到自适应数量划分,从非重叠划分到重叠划分,从语义分割划分到语义聚合划分,以及从原始图像划分到特征图划分;总结了标记选择机制的 3 项关键技术如下:基于分数的标记选择、基于合并的标记选择以及基于卷积和池化的标记选择;总结了位置编码机制的 5 项关键技术如下:绝对位置编码、相对位置编码、条件位置编码、局部增强位置编码和零填充位置编码;基于时间线总结了 18 种注意力机制;通过与 U-Net、GAN、YOLO、ResNet 和 DenseNet 的结合,讨论了 ViT 在医学图像处理领域的广泛应用。
3.1. 图像块划分机制
图像块划分机制是将图像划分为多个图像块进行处理。通过将图像划分为多个图像块,可以更好地提取图像中的局部特征,从而提高图像处理的效率和准确性。传统的划分方法是将原始输入图像划分为一系列固定大小的不重叠图像块,如图 4(A) 所示。这种方法简单直接,但它在一定程度上破坏了图像的局部连续性,也限制了 ViT 在视觉任务中的性能。为了解决这个问题,有许多关于图像块划分机制的研究,包括 5 个方面:从单一尺寸划分到多尺寸划分,从固定数量划分到自适应数量划分,从非重叠划分到重叠划分,从语义分割划分到语义聚合划分,以及从原始图像划分到特征图划分。
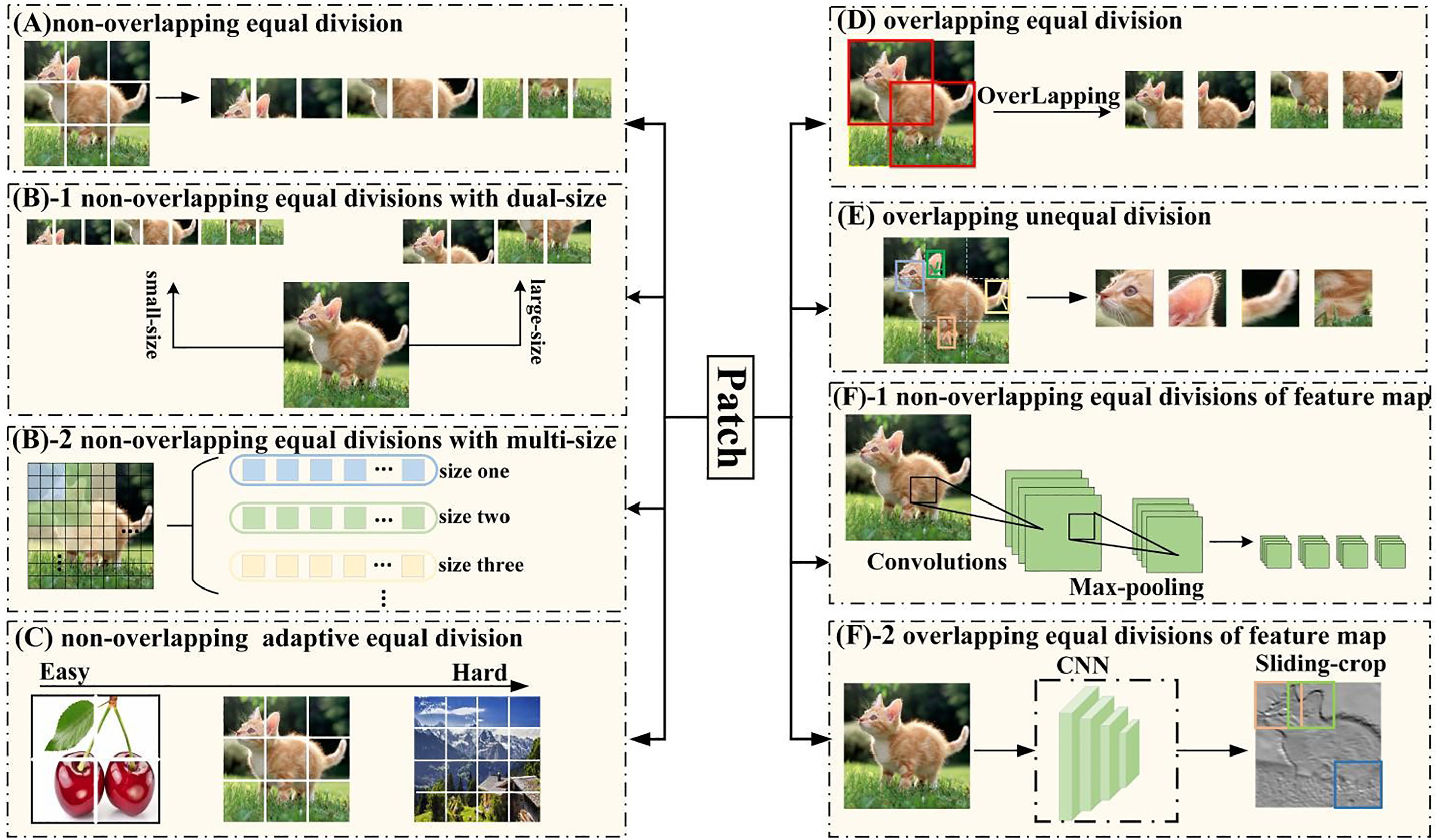
3.1.1. 从单一尺寸划分到多尺寸划分
从单一尺寸划分到多尺寸划分是指根据多个尺寸而不是单一尺寸对图像进行划分。计算机视觉任务,如检测和分类,需要有效的多尺寸特征表示。因此,通过将图像划分为多个尺寸来获得多尺寸特征表示。在非重叠等分的情况下,有双尺寸非重叠等分和多尺寸非重叠等分的图像块划分。双尺寸非重叠等分是通过两个独立分支提取粗粒度大尺寸图像块和细粒度小尺寸图像块。这个想法是由 Chen 等人提出的,在该想法中,通过结合不同尺寸的图像块产生更强的图像特征,如图 4(B)-1 所示。多尺寸非重叠等分是通过多个独立分支获得不同尺寸的图像块。这个想法是由 Lee 等人提出的,在该想法中,通过独立输入不同尺寸的图像块到Transformer编码器中,实现在同一特征级别上的多尺寸特征表示,如图 4(B)-2 所示。
3.1.2. 从固定数量划分到自适应数量划分
从固定数量划分到自适应数量划分是指图像被划分为自适应数量的图像块而不是固定数量。通常,这些问题是通过更多的图像块产生的,例如更高的预测精度和更多的计算复杂性。因此,为了实现预测精度和计算复杂性之间的权衡,自适应数量的图像块对于图像块划分机制非常重要。这个想法是由 Wang 等人提出的,在该想法中,级联了多个Transformer,它们具有递增数量的图像块,在测试期间,从较少的图像块开始顺序激活模型,一旦产生足够有信心的预测,就立即终止推理,如图 4(C) 所示。对于“简单”图像,只有 2×2 图像块就足以进行准确预测,而对于“困难”图像,需要细粒度表示以减少信息丢失并提高计算效率。
3.1.3. 从非重叠划分到重叠划分
从非重叠划分到重叠划分是指将图像块划分机制从非重叠划分改为重叠划分。非重叠划分在一定程度上破坏了图像的局部连续性。因此,图像的重叠划分可以增强相邻图像块之间的语义相关性,并有效解决非重叠划分破坏特征局部连续性的问题。这个想法是由 Wang 等人提出的,在该想法中,图像通过重叠等分进行序列化,使得相邻图像块重叠一半的区域。通过这种方式,包含了更多的图像特征局部连续性。如图 4(D) 所示。
3.1.4. 从语义分割划分到语义聚合划分
从语义分割划分到语义聚合划分是指在图像块中聚合语义相关的目标局部结构。由于通过常规图像块捕获目标对象的完整局部结构总是困难的,因此自适应地将图像划分为不同位置和尺寸的图像块可以有效捕获目标对象的完整局部结构。这个想法是由 Chen 等人提出的,在该想法中,根据输入视觉特征学习每个图像块的偏移和尺寸,以可变形的方式将图像划分为不同位置和尺寸的图像块,这保留了每个图像块中的语义信息,并减少了图像分割引起的语义破坏,如图 4(E) 所示。
3.1.5. 从原始图像划分到特征图划分
从原始图像划分到特征图划分是指将生成的特征图划分为图像块,而不是原始图像,以便每个获得的图像块包含更多的语义信息。特征图的划分包括特征图的非重叠等分和特征图的重叠等分。特征图的非重叠等分是采用卷积层和最大池化层获得原始图像的特征图,然后将特征图划分为非重叠图像块。这个想法是由 Yuan 等人提出的,在该想法中,利用 CNN 在提取低级特征方面的优势,并通过减小图像块大小来降低嵌入的训练难度,如图 4(F)-1 所示。特征图的重叠等分是采用预训练的 CNN 从原始图像中提取中间卷积特征图,然后通过滑动窗口将中间特征图划分为重叠图像块。这个想法是由 Liu 等人提出的,在该想法中,一个
3.2. 标记选择机制
在通道维度上进行线性映射后展平操作获得的一维向量称为标记。标记选择机制是在模型的前向传播过程中动态识别冗余标记并选择更重要的标记。考虑到使用Transformer解决视觉任务时,ViT 的计算量随着标记数量的增加而呈指数级增长,而 ViT 的最终预测结果通常由一些包含大量信息的标记决定,大多数标记是冗余的。因此,如果能够根据输入图像和标记动态识别冗余标记,并在前向传播过程中选择包含重要信息的标记,可以大大提高 ViT 模型的推理速度。关于标记选择机制的研究包括 3 个方面:第一种 是基于分数的标记选择机制,如图 5(A) 所示,典型模型有 DynamicViT、EViT、Evo-ViT、A-ViT 和 LTP;第二种是基于合并的标记选择机制,如图 5(B) 所示,典型模型有 T2T-ViT、ToMe 和 TCFormer;第三种是基于卷积和池化的标记选择,如图 5(C) 所示,典型模型有 HVT 和 PSViT。同时,从 5 个方面比较了不同标记选择机制的性能:参数量、浮点运算次数、吞吐量、数据集和 Top-1 准确率,如表 1 所示。
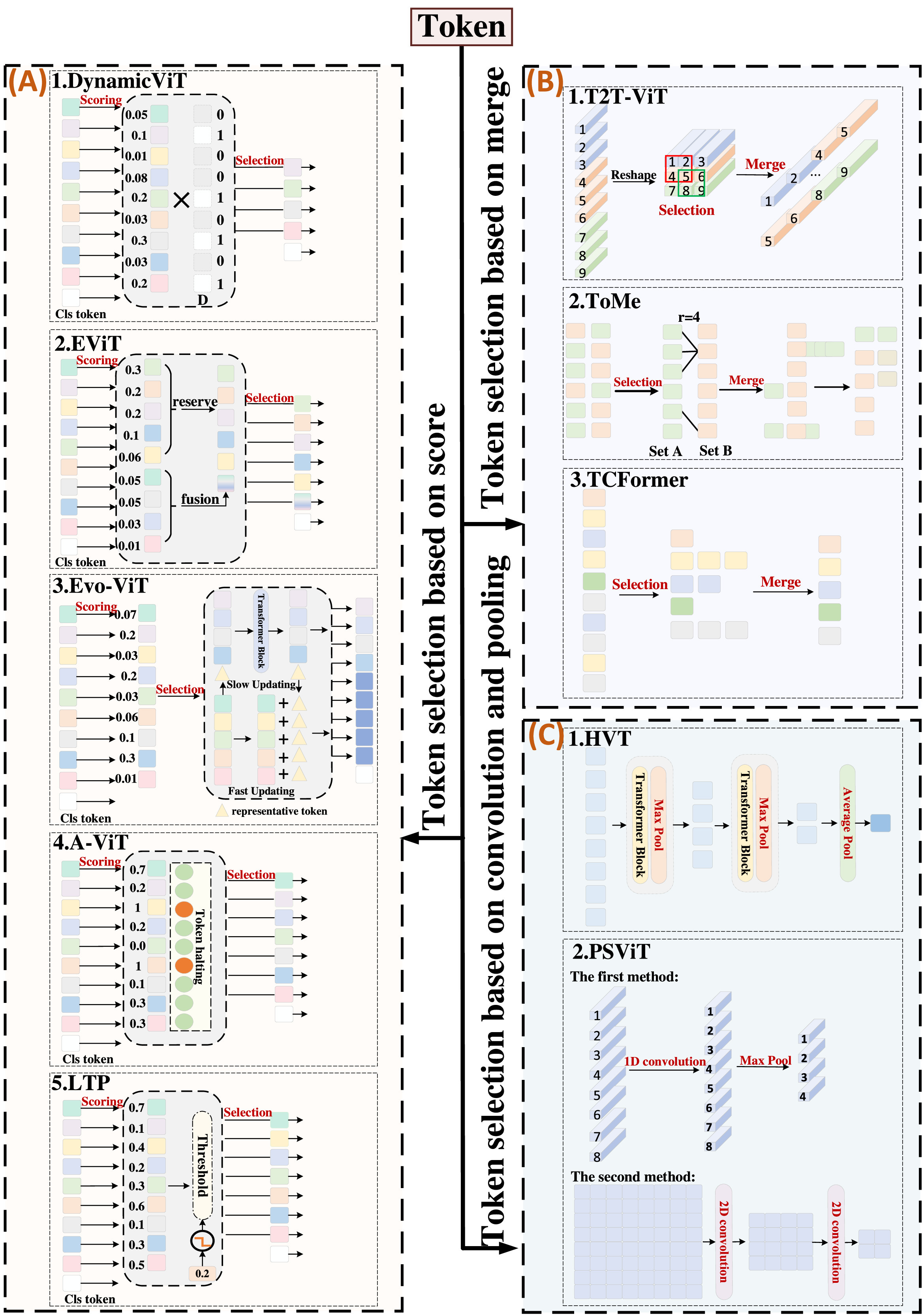
3.2.1. 基于分数的标记选择
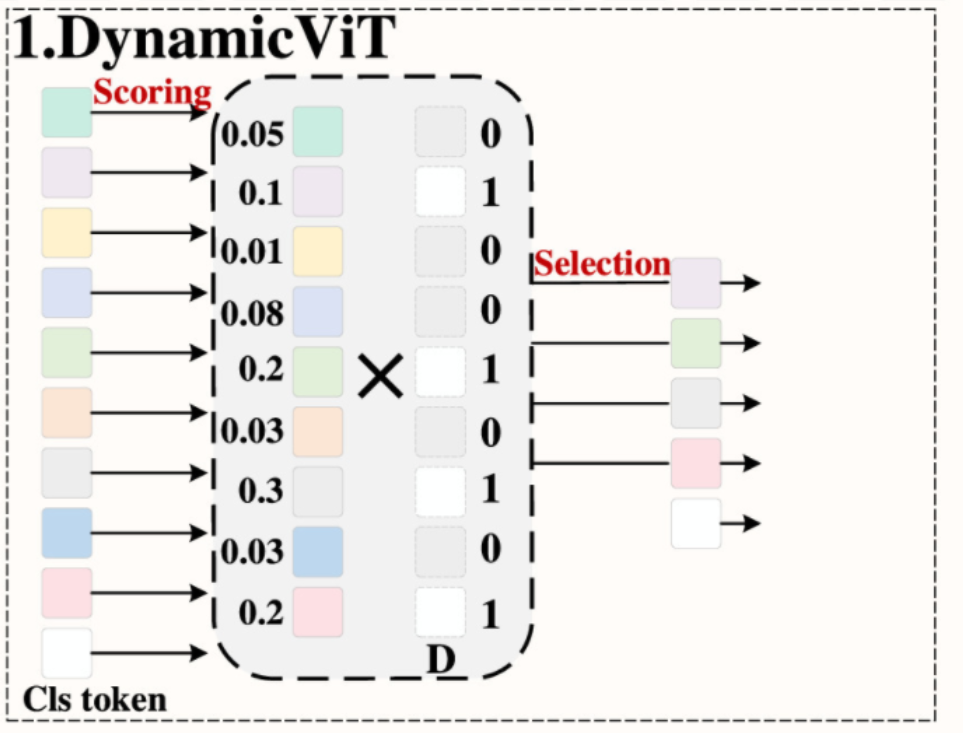
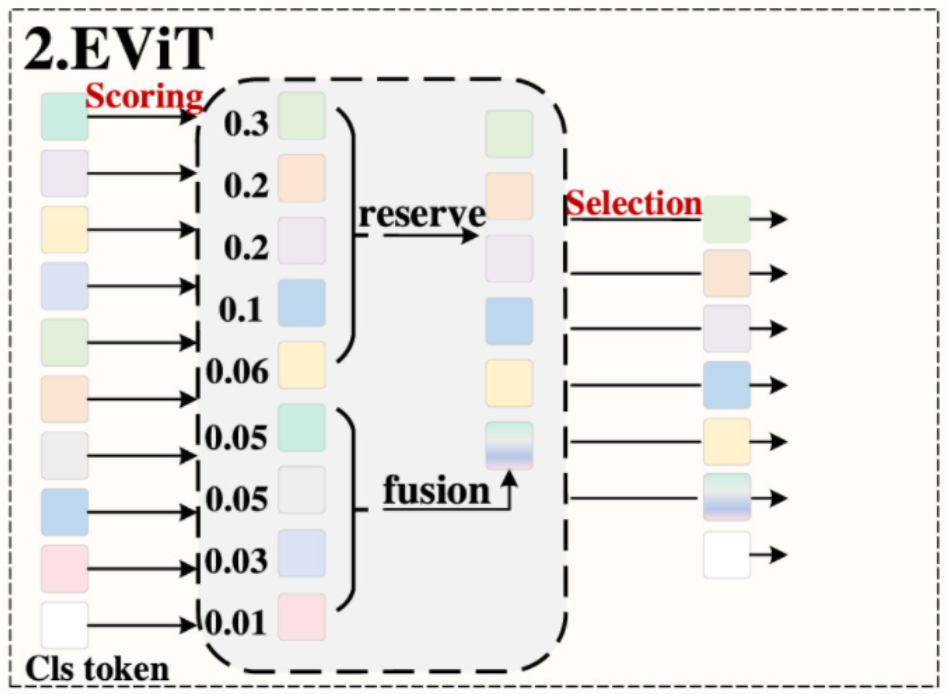
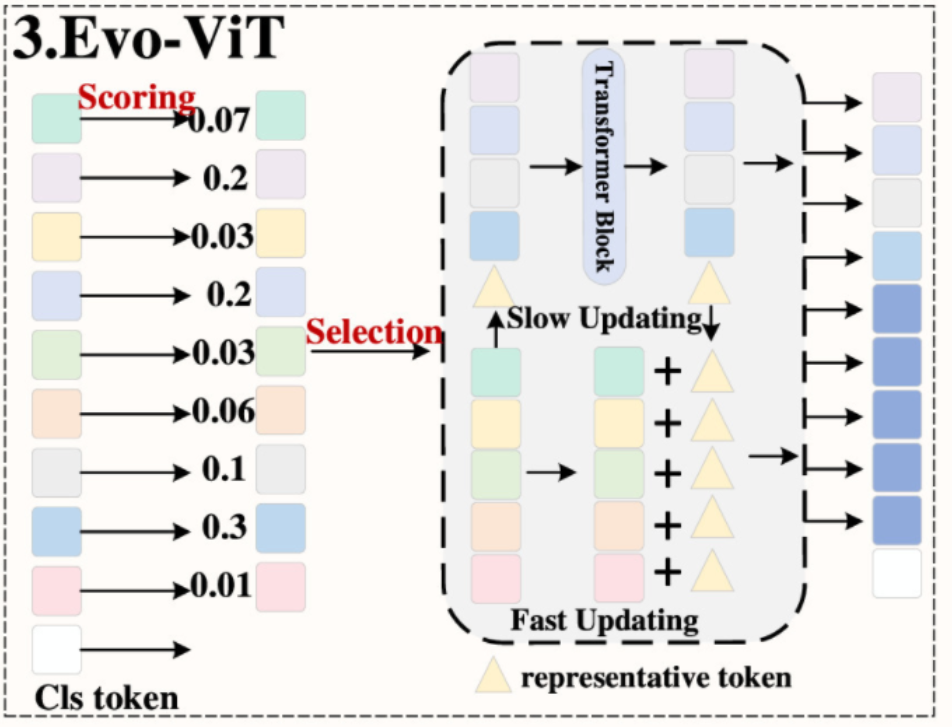
基于分数的标记选择机制是通过评分函数对标记的重要性进行评分,通过剪枝操作保留高分标记,删除低分标记,以减少计算量并提高模型的计算效率。目前,这种方法中有 5 种主要的评分策略和选择策略:DynamicViT 策略、EViT 策略、Evo-ViT 策略、A-ViT 策略和 LTP 策略。
- DynamicViT 策略。这种策略是由 Rao 等人提出的,如图 5(A)-1 所示,通过在 66% 的输入标记上进行层剪枝来提高性能,例如模型中的浮点运算次数减少了 31-37%,运行速度提高了 40% 以上。在评分策略部分:首先,初始化一个二进制决策掩码
,并将所有元素值设置为 1;其次,使用 MLP 对标记进行投影以获得局部特征,如公式 7 所示;第三,使用 Agg 函数聚合所有现有标记的信息以计算全局特征,如公式 8 所示;最后,将局部特征和全局特征在通道维度上连接并输入另一个 MLP 以预测保留/丢弃标记的概率,如公式 9 所示,结果 是每个标记的重要性分数;在选择策略部分:根据每个标记的重要性分数更新二进制掩码 以选择标记,在掩码 中,如果 中元素的值为 0,则删除其对应的标记;如果 中元素的值为 1,则保留其对应的标记。
- EViT 策略。这种策略是由 Liang 等人提出的,如图 5(A)-2 所示,这种策略应用于 DeiT-S,在 ImageNet 上将 DeiT-S 的推理速度提高了 50%,而识别精度仅下降了 0.3%。在评分策略部分:通过执行注意力机制获得类别标记与其他标记之间的注意力值
,注意力值表示每个标记的重要性分数,如图 10 所示,其中 别代表类别标记的查询向量、键矩阵和 量的维度, 图像标记的数量;在选择策略部分:选择分数最高的前 标记,其他标记通过加权平均操作合并成一个新的标记,并将新标记添加到前 标记中并发送到后续层。
- Evo-ViT 策略。这种策略是由 Xu 等人提出的,如图 5(A)-3 所示,这种策略应用于 DeiT-S,在 ImageNet 上将 DeiT-S 的吞吐量提高了 60%,而识别精度仅下降了 0.4%。在评分策略部分:类别标记与图像标记之间的相似性表示为类别注意力
,如图 11 所示,其中 别代表类别标记的查询向量、键矩阵和 量的维度, 每个标记的重要性分数;在选择策略部分:低分标记聚合成一个代表性标记,前 高分标记和代表性标记通过Transformer块更新,同时,低分标记与更新后的代表性标记分别加权,加权后的低分标记添加到前 标记中并发送到后续层。
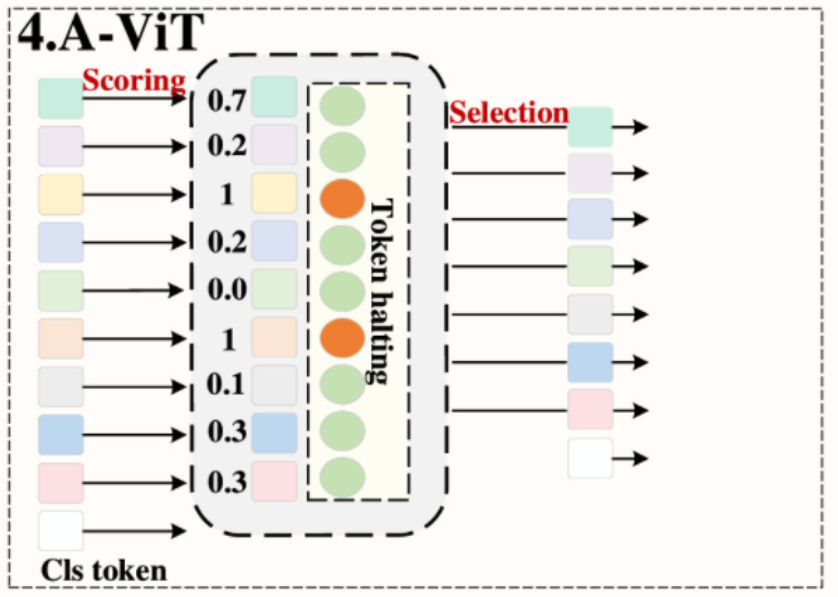
- A-ViT 策略。这种策略是由 Yin 等人提出的,如图 5(A)-4 所示,这种策略应用于 DeiT-Tiny 和 DeiT-Small,DeiT-Tiny 和 DeiT-Small 的速度分别提高了 62% 和 38%,而精度仅下降了 0.3%。在评分策略部分:为每个标记
层 入了停止概率 ,如图 12 所示,其中 停止模块, 范围是 ;在选择策略部分:进入更深层时,根据停止模块的输出使用累积停止概率,当累积停止分数超过 1 时,停止标记的计算。
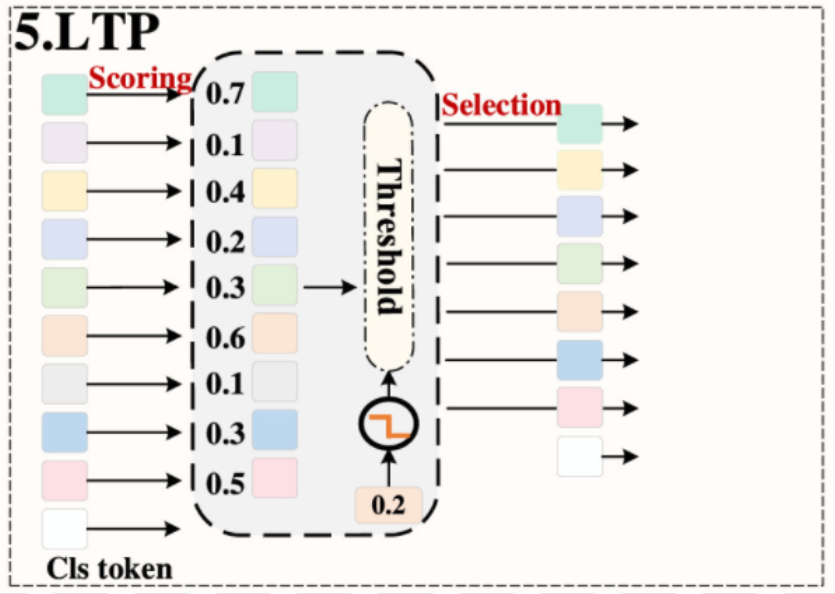
- LTP 策略。这种策略是由 Kim 等人提出的,如图 5(A)-5 所示。在评分策略部分:首先,获得头
间标记 标记 注意力概率 ,然后计算标记 层 重要性分数,如图 13 所示,其中 头的数量, 标记的数量;在选择策略部分:分数低于可学习阈值的标记在每层被剪枝。
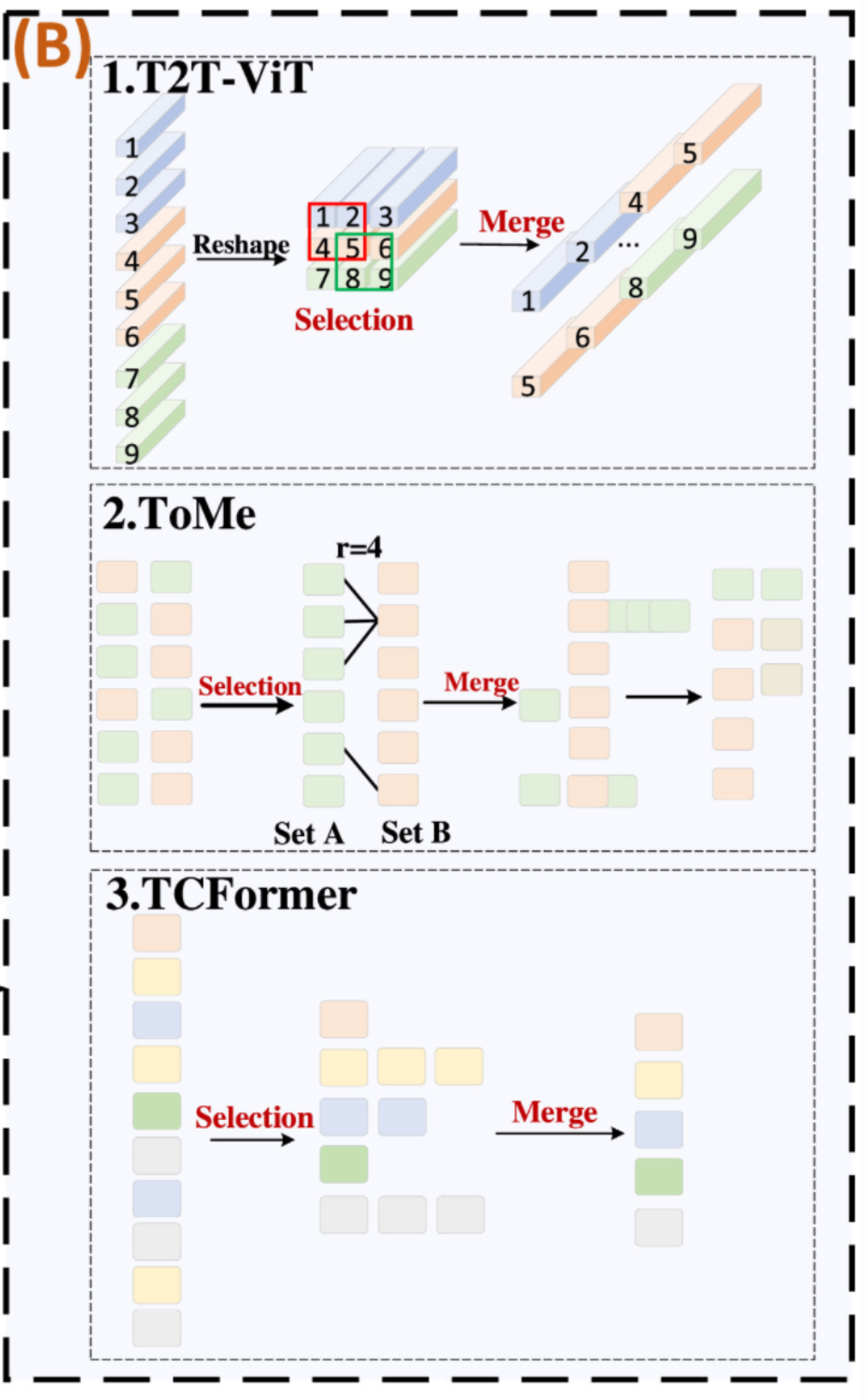
3.2.2. 基于合并的标记选择
基于合并的标记选择机制是通过匹配算法选择并合并相似标记,以减少信息丢失并提高训练速度。这种方法中的关键操作是选择策略和合并策略。目前,有 3 种主要的选择策略和合并策略:T2T-ViT 策略、ToMe 策略和 TCFormer 策略。 1. T2T-ViT 策略。这种策略是由 Yuan 等人提出的,如图 5(B)-1 所示。在这种策略中,相邻标记递归地聚合为一个标记,以便对相邻标记的局部结构进行建模,并减少标记长度。在选择策略部分:所有标记被重塑为空间维度上的图像,然后分割为重叠的图像块;在合并策略部分:每个分割图像块中的标记被连接为一个新的标记。 2. ToMe 策略。这种策略是由 Bolya 等人提出的,如图 5(B)-2 所示。在这种策略中,大量冗余标记被合并,大大改善了模型的训练和推理速度。在选择策略部分:标记被分为两组 A 和 B,这两组大致相等大小,然后使用点积相似性从 B 集中选择与 A 集最相似的
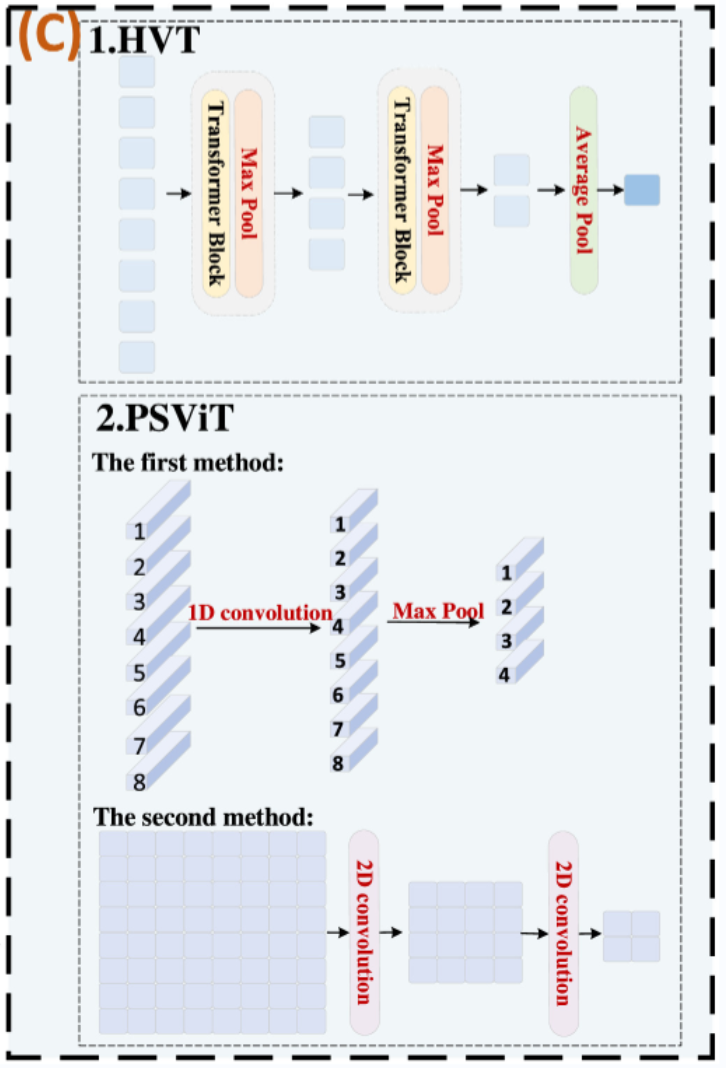
3.2.3. 基于卷积和池化的标记选择
基于卷积和池化的标记选择机制是通过卷积和池化操作缩短标记序列长度,类似于 CNN 中的特征图下采样,以减少冗余信息和计算成本。这种方法中的关键操作是卷积策略和池化策略。目前,有 2 种主要的卷积策略和池化策略:HVT 策略和 PSViT 策略。 1.HVT 策略。这种策略是由 Pan 等人提出的,如图 5(C)-1 所示。在这种策略中,通过层次池化缩短标记序列长度。在池化策略部分:首先,将 ViT 块分为几个阶段;其次,在每个阶段之后,在Transformer块后插入最大池化层进行下采样;最后,在最后阶段的标记上执行平均池化以进行最终结果预测。 2.PSViT 策略。这种策略是由 Chen 等人提出的,如图 5(C)-2 所示。在这种策略中,有两种方法减少标记数量以消除空间冗余。第一种方法,使用小核尺寸的 1D 卷积改变每个标记的维度,然后使用 1D 最大池化减少标记数量;第二种方法,采用步长为 2 的 2D 卷积层进行标记下采样,这在许多卷积网络中被广泛应用。
3.3. 位置编码机制
由于自注意力计算过程中不考虑位置信息,而数据之间的关系受到位置信息的影响,为了使模型能够接受输入图像的位置信息,引入了位置编码机制。位置编码机制是将位置信息整合到输入序列中。通过捕获输入序列的位置信息并保持这些序列之间的空间位置关系,可以有效地表达图像中的位置信息,从而提高模型的性能。编码位置信息的序列可以并行输入,大大提高了计算效率。有 5 种典型的位置编码机制:绝对位置编码、相对位置编码、条件位置编码、局部增强位置编码和零填充位置编码。同时,对不同位置编码机制进行了比较,如表 2 所示。 首先,绝对位置编码,绝对位置编码是由预定义函数生成或通过训练学习得到的。其维度与输入序列相同,通过加法操作将位置信息添加到输入序列中。在 ViT 中,编码方法是通过不同频率的正弦和余弦函数生成的,如公式 15 和公式 16 所示,其中
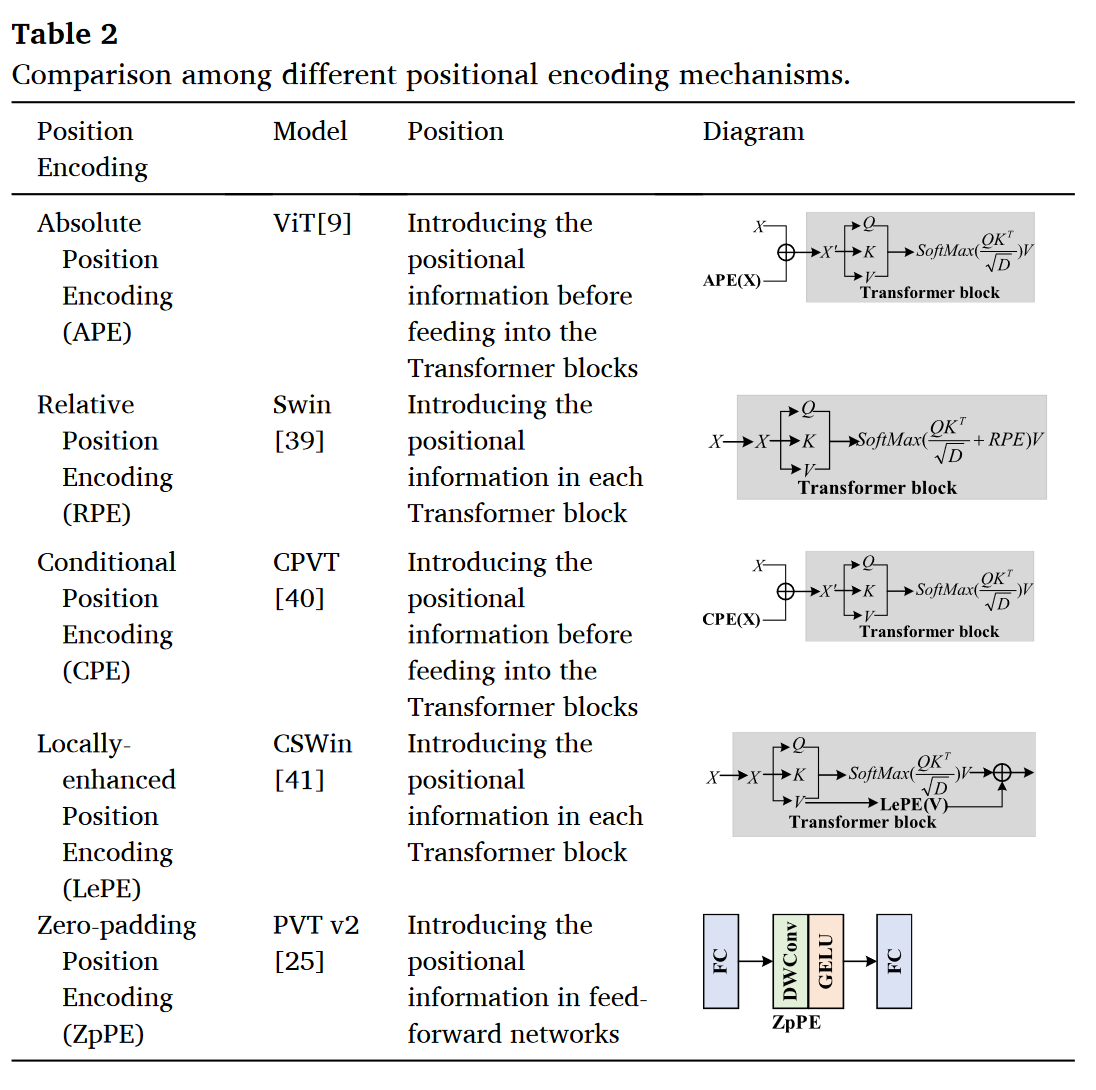
其次,相对位置编码,与绝对位置编码直接将位置信息添加到输入标记序列不同,相对位置编码考虑当前位置与被关注位置之间的相对距离。计算并编码元素对之间的相对位置,并将其作为模型输入的一部分,可以学习不同元素之间的空间关系。在 Swin 中,将相对位置偏置
第三,条件位置编码,与固定或可学习的位置编码不同,条件位置编码是由一个简单的位置编码生成器(PEG)基于输入的局部邻域预定义并动态生成的。为了将局部邻域作为条件,将展平的输入标记序列
第五,零填充位置编码,研究表明,位置信息可以从 CNN 中的零填充隐式学习,零填充位置编码是在前馈神经网络中的第一个全连接层和 GELU 激活函数之间添加一个核尺寸为
3.4. 注意力机制
注意力的概念最初是由 Mnih 等人在 2014 年在图像识别领域提出的,这是一种模拟人脑注意力机制的模型。作为 ViT 的核心组件,自注意力是捕获长距离依赖关系的强大工具。然而,原始 ViT 模型中的全局注意力计算了所有图像块在空间位置中所有对的全局信息交互,如图 6-1 所示,因此导致了高时间复杂度和空间复杂度,特别是在高分辨率视觉任务中。有一系列工作旨在改进注意力性能并降低计算和存储成本。本文基于时间线总结了 18 种注意力机制,如图 6 所示。主要的注意力机制包括:Focal Self-attention、W-MSA 和 SW-MSA、Cross-Attention、Spatially Separable Self-Attention、Long Short Distance Attention、Pale-Shaped Self-attention、Cross-Shaped Window Self-Attention、Regional-to-Local Attention、Dual Attention、Depthwise Separable Self-attention、Deformable Attention、Multi-axis Attention、Bilateral Local Attention、Neighborhood Attention、HiLo Attention、Multi-Scale Dilated Attention、QuadTree Attention 和 Bi-Level Routing。同时,从 5 个方面比较了 18 种注意力机制的性能:参数量、浮点运算次数、吞吐量、数据集和 Top-1 准确率,如表 3 所示。 首先,Focal Self-attention (FSA),FSA 是一种注意力机制,它结合了细粒度的局部特征和粗粒度的全局特征,每个标记在细粒度上关注其周围的最近标记,在粗粒度上关注长距离标记,如图 6-2 所示。Yang 等人认为,邻近区域之间的视觉依赖通常比非邻近区域之间的视觉依赖更强,并提出了 FSA 以模拟高分辨率预测任务中的局部和全局交互,有效地捕获短距离和长距离之间的视觉依赖。其次,W-MSA 和 SW-MSA,W-MSA 代表 Windows 多头自注意力,在层

3.5. 网络结构
由于其出色的性能,Transformer在医学影像领域被广泛应用,并在肺癌、乳腺癌、皮肤病、心血管疾病和脑血管疾病的计算机辅助诊断中取得了良好效果。由于单一网络的性能有限,越来越多的研究发现,将Transformer与其他网络模型结合是一个重要的发展方向。在医学影像领域,Transformer有 5 个应用领域,如将Transformer与 U-Net 结合用于医学图像分割,将Transformer与 GAN 结合用于融合,将Transformer与 YOLO 结合用于检测,将Transformer与 ResNet 和 DenseNet 结合用于分类和识别,这些工作可以为Transformer的应用提供帮助。
3.5.1. Transformer与 U-Net 结合
医学图像分割是指从医学图像中分割出所需的病变区域,如器官、组织等,通过数字图像处理技术将分割后的病变可视化,并通过图形处理技术指导操作。精确的病灶分割对医学图像分类具有很好的指导作用。在2020年之前,主流的医学图像分割方法大多是基于U-Net模型进行改进的。U-Net虽然实现了较好的分割效果,但由于卷积操作的局部性,缺乏长距离关系建模,难以学习全局语义信息。Transformer可以通过注意力机制捕获全局信息,建立长距离依赖关系,提取更多的特征信息。近年来,许多研究者将Transformer和U-Net结合用于医学图像分割,有助于提高分割精度。在医学图像分割领域,Transformer与U-Net的结合主要包括TransUNet、TransClaw U-Net、LeViT-UNet、Teeth U-Net和UTNet。
- Chen 等人提出了 TransUNet。在这个网络中,CNN 和Transformer的混合结构被用作编码器,编码器中的特征图通过解码器进行上采样,并将高分辨率 CNN 特征图结合起来实现精确定位。
- Chang 等人提出了 TransClaw U-Net。在这个网络中,编码器采用混合结构,特征图通过卷积操作提取并通过Transformer增强,解码器部分是双向设计:一种方式是直接上采样,另一种方式是在上采样的同时进行跳跃连接,有效地实现了医学图像的分割。
- Xu 等人提出了 LeViT-UNet。在这个网络中,LeViT 被用作编码器,LeViT 中的Transformer块和卷积块的多尺度特征图通过跳跃连接传递到解码器,有效地重用了空间特征。
- 由于牙齿与全景牙科 X 射线图像之间的边界模糊,使得从全景牙科 X 射线图像中分割牙齿变得困难,Hou 等人提出了 Teeth U-Net,在这个网络中,设计了一个扩张的混合自注意力块,用于在更大的感知领域中捕获牙科特征信息。
- Gao 等人提出了 UTNet,在该网络中,自注意力被集成到 CNN 中以增强医学图像分割,并且在编码器和解码器中都使用了自注意力模块来捕获长距离依赖关系。
3.5.2. Transformer与 GAN 结合
由于疾病的多样性和复杂性,通过单一模态医学图像很难诊断疾病类型和定位病变。通过多模态医学图像融合获得的融合图像具有更丰富的特征和更全面的信息,可以帮助医学图像更好地服务于临床应用。GAN 是医学图像跨模态重建中最常见的深度学习技术,通过对抗学习机制,可以模拟医学图像中的重要信息。Transformer不仅可以处理长序列信息,还可以学习不同模态之间的关系,并能有效地提取多模态医学图像中的特征。因此,将Transformer和 GAN 结合可以提高医学图像融合的有效性和精度。在医学图像合成领域,Transformer和 GAN 的结合主要包括 RTCGAN、D-ESRGAN、MedViTGAN、CT-GAN 和 TCGAN。
- Zhao 等人提出了新的 GAN 模型 RTCGAN,该模型利用 CNN 和Transformer从 MR 和 CT 图像中提取多级特征,CNN 可以感知局部纹理特征,Transformer可以感知全局相关性。
- Wang 等人提出了 D-ESRGAN,这是一种超分辨率双编码器生成对抗网络,在该网络中,补偿了虹膜图像中纹理信息的损失,同时新生成的纹理特征保持更自然。D-ESRGAN 不仅集成了残差 CNN 编码器以提取局部特征,而且还使用了 ViT 编码器以捕获全局关联信息。
- Li 等人提出了基于Transformer架构的 MedViTGAN,以端到端的方式合成病理图像以增强图像。
- Pan 等人提出了 CT-GAN,该模型可以通过整合静息态功能磁共振成像(rs-fMRI)中包含的功能信息和扩散张量成像(DTI)中包含的结构信息,更好地预测阿尔茨海默病。
- Li 等人提出了 TCGAN,该模型使用双生成器架构来融合 PET 和 CT,双生成器是将 CNN 生成器和Transformer生成器串联连接。
3.5.3. Transformer与 YOLO 结合
使用计算机实现医学图像检测可以帮助专家更准确地控制疾病。与自然图像不同,医学检测图像中大多数病变检测目标的边缘通常是模糊和不规则的,并且像素数量很少。通过传统方法很难准确定位病变,这通常会导致漏检和误检问题。近年来,基于深度神经网络的物体检测方法在医学图像中得到了广泛应用。YOLO 是一种具有实时性和准确性特点的单阶段深度学习检测方法。Transformer可以通过对图像中的全局特征进行建模来有效地提取病变位置信息。因此,添加到 YOLO 骨干网络中的Transformer机制可以更好地提取病变的复杂特征,并提高检测精度。在医学图像检测领域,Transformer和 YOLO 的结合主要包括 CL-YOLOv5、YOLO-LOGO、RDFNet、改进的 YOLO 和 CCGL-YOLOV5。
- Zhou 等人提出了 CL-YOLOv5。在这个网络中,设计了一个余弦加权计算Transformer,以有效地学习全局特征关系,并增强网络提取病变的能力。
- Su 等人提出了 YOLO-LOGO,用于数字乳腺 X 线照片中乳腺癌肿瘤的检测。在这个网络中,使用目标检测模型 YOLOV5L6 来定位和裁剪乳腺肿瘤,并对整张图像和裁剪后的图像分别在全局和局部Transformer分支上进行训练。
- Jiang 等人提出了 RDFNet,由于目前对龋齿检测的研究不足。在这个网络中,基于原始 SPP 结构添加了改进的Transformer编码器模块,以提高网络提取龋齿特征的能力,并实现快速龋齿检测。
- Qi 等人提出了改进的 YOLO 网络,在这个网络中,将 CBAM(卷积块注意力模块)和多头自注意力机制与 yolov3 网络结合,用于胸部 CT 图像中肺结节的检测。
- Zhou 等人提出了 CCGL-YOLOV5,用于肺癌检测,在这个网络中,设计了一个跨模态融合Transformer模块,用于多模态特征融合。
3.5.4. Transformer与 ResNet 结合
基于深度学习的医学图像分类在计算机辅助诊断中起着关键作用,例如加快胶片阅读、缩短患者等待时间以及减轻影像科医生的负担。在视觉Transformer之前,用于分类医学图像的深度学习是基于 CNN 的。经典的 CNN 模型包括 ResNet 和 DenseNet。其中,ResNet 可以通过跳跃连接有效缓解网络深度增加引起的梯度消失和网络退化问题。将Transformer中的自注意力机制引入 ResNet,使模型能够更好地建模长距离依赖关系,帮助捕获图像中的全局上下文信息。在医学图像分类和识别领域,Transformer和 ResNet 的结合主要包括 Trans-ResNet、ASI-DBNet、DCET-Net、RMT-Net 和 REC-ResNet。
- Li 等人提出了 Trans-ResNet 网络,用于阿尔茨海默病分类。在这个网络中,使用 ResNet-18 从输入图像中提取局部语义信息,然后生成的特征图被划分并输入Transformer网络进行分类。
- Zhou 等人提出了 ASI-DBNet,用于快速准确分类脑癌。在这个网络中,设计了自适应稀疏交互块,以实现 ResNet 分支和 ViT 分支之间的交互,这使得在交互过程中传递的特征图更有益。
- Zou 等人提出了 DCET-Net,这是一个基于 CNN 和Transformer两个骨干网络的双流网络,用于乳腺癌组织病理图像分类。该网络使用 CNN 捕获组织病理图像的局部深度特征,并使用Transformer增强深度特征的全局信息,呈现出更具区分性的特征。
- Ren 等人提出了一种新的深度学习网络 RMT-Net,基于 ResNet-50 和Transformer的结合。在这个网络中,使用Transformer捕获长距离特征信息,并通过深度卷积获得局部特征。
- Zhou 等人提出了 REC-ResNet,这是一种用于 COVID-19 辅助诊断的模型,使用 ResNet50 作为主干网络,并引入了三种特征增强策略,以提高模型的特征提取能力。
3.5.5. Transformer与 DenseNet 结合
与 ResNet 相比,DenseNet 提出了一种密集连接机制:所有层都是相互连接的,并且每个层都与所有前面的层在通道维度上连接,作为下一层的输入,这不仅可以实现特征重用,还可以提高效率。Transformer使用自注意力机制计算所有位置,使网络中的每个位置都能相互交互,进一步提高特征重用。将 DenseNet 和Transformer结合可以捕获更多的全局上下文信息,并改善特征重用,从而提高模型的性能。在医学图像分类和识别领域,Transformer和 DenseNet 的结合主要包括 DRLTransformer、DDSF-Net 和 DPE-BoTNet。
- Zhou 等人提出了 DRLTransformer。在这个网络中,设计了重引用密集块和层次Transformer,用于 CT 图像中 COVID-19 的识别。
- Zhou 等人提出了 DDSF-Net,用于肺炎诊断。在这个网络中,使用Transformer学习全局上下文语义信息,卷积层用于提取局部特征,并使用密集连接方法实现两种信息流的深层和浅层特征融合。
- Nakai 等人提出了基于 DenseNet201 的 DPE-BoTNet,用于皮肤病分类。通过结合Transformer和 DenseNet,可以同时建模局部交互和全局依赖,以提高皮肤病分类性能。
4. 结论
ViT 在深度学习领域取得了突破性进展,在 ViT 中,有四个主要步骤,即“四个秘密”,如图像块划分、标记选择、位置编码添加和注意力计算,现有的关于计算机视觉中Transformer的研究主要集中在上述四个步骤上。因此,“如何划分图像块?”、“如何选择标记?”、“如何添加位置编码?”和“如何计算注意力?”对于提高 ViT 性能至关重要。但到目前为止,大多数综述文献都是从应用的角度进行总结的,没有相应的文献从技术角度全面总结这四个步骤,这在一定程度上限制了 ViT 的进一步发展。因此,针对上述问题,本文全面总结了 ViT 的 4 个机制和 5 个应用,主要贡献如下:首先,针对“如何划分图像块?”,总结了图像块划分机制的 5 项关键技术:(1)从单一尺寸划分到多尺寸划分;(2)从固定数量划分到自适应数量划分;(3)从非重叠划分到重叠划分;(4)从语义分割划分到语义聚合划分;(5)从原始图像划分到特征图划分。其次,针对“如何选择标记?”,总结了标记选择机制的 3 项关键技术:(1)基于分数的标记选择;(2)基于合并的标记选择;(3)基于卷积和池化的标记选择。第三,针对“如何添加位置编码?”,总结了位置编码机制的 5 项关键技术:(1)绝对位置编码;(2)相对位置编码;(3)条件位置编码;(4)局部增强位置编码;(5)零填充位置编码。第四,针对“如何计算注意力?”,基于时间线总结了 18 种注意力机制,如 Focal Self-attention、W-MSA 和 SW-MSA、Cross-Attention、Spatially Separable Self-Attention、Long Short Distance Attention、Pale-Shaped Self-attention、Cross-Shaped Window Self-Attention、Regional-to-Local Attention、Dual Attention、Depthwise Separable Self-attention、Deformable Attention、Multi-axis Attention、Bilateral Local Attention、Neighborhood Attention、HiLo Attention、Multi-Scale Dilated Attention、QuadTree Attention、Bi-Level Routing Attention。第五,讨论了 ViT 在医学图像处理领域的广泛应用,通过与 U-Net、GAN、YOLO、ResNet 和 DenseNet 的结合进行了探讨。
5. 未来工作
尽管 ViT 在计算机视觉领域取得了突破性进展,并发挥了重要作用,但为 ViT、图像块划分机制、标记选择机制、位置编码机制和注意力机制的研究设计合理的网络模型和良好的泛化效果非常重要,构建多任务的统一框架、降低高维数据计算、实现小样本学习以及具有良好的模型结构可解释性都是 ViT 未来发展方向。首先,ViT 图像块划分机制的研究。图像块划分机制的未来方向如下:(1)非正方形图像块划分,如矩形、圆形、三角形等,用于提取具有复杂形状的目标特征;(2)多图像块划分,用于并行处理多尺度特征;(3)动态图像块划分,根据图像中目标的大小动态确定图像块大小,以更好地适应图像中的不同目标。其次,ViT 标记选择机制的研究。标记选择机制的未来方向如下:(1)自适应评分策略,模型根据每个标记的特征和所有标记之间的相互关系自适应地对每个标记进行评分;(2)自适应合并策略,如何合并冗余标记对 ViT 标记选择至关重要;(3)与其他进化算法相结合的选择策略,如遗传算法、蚁群算法等方法,研究最优标记搜索策略。第三,ViT 位置编码机制的研究。这是一种基于位置编码生成器的机制,如正弦函数、余弦函数、高斯函数、多项式函数等。第四,ViT 注意力机制的研究。注意力机制的未来方向如下:(1)注意力机制的选择,如何选择适当的注意力机制并提高模型性能对 ViT 至关重要;(2)选择注意力计算区域的问题;(3)多模态注意力机制,同时关注视觉、语音、文本等多种模态信息,并提高模型的泛化能力。第五,构建多任务统一框架的研究。传统的多模态模型对不同类型的数据采用不同的处理方法,因此在特征拼接时不可避免地无法对齐模式。不仅模型结构复杂,而且不同数据类型的处理结果也不理想。目前,Transformer在文本、图像、视频、语言等方面取得了巨大成功。Transformer自注意力机制具有强大的特征提取和模态对齐能力。因此,如何构建一个统一的框架以捕获多模态数据之间的内部关系将是未来的发展趋势。第六,降低高维数据计算的研究。由于参数众多和计算复杂度高,现有的视觉Transformer模型训练和推理时间较长,需要大量的计算资源和时间以及强大的硬件支持。即使硬件设备的性能不断提高,Transformer仍然无法满足计算效率的要求。因此,如何提高Transformer模型的计算效率是一个热门且困难的问题。第七,实现小样本学习的研究。与 CNN 相比,Transformer模型具有更多的参数,因此其训练通常依赖于更多的训练样本。目前的训练方法是在大型数据集上预训练视觉Transformer模型,然后使用少量数据对模型进行微调以适应任务类型。然而,对于一些训练样本稀疏的视觉任务,通常很难获得大量的训练数据,训练数据的数量和质量限制了模型的训练和性能提升。因此,如何实现小样本学习并利用先验知识仍然是一个挑战。第八,ViT 可解释性的研究。与 CNN 和 RNN 相比,Transformer具有更大的容量,其架构可以支持大规模数据训练。然而,理论原因尚不清楚。Transformer中每一层的注意力以复杂的方式混合在后续层中,因此很难可视化输入标记对最终预测的相对权重。为了更好地设计和改进Transformer模型结构,有必要深入研究和理解其操作机制和内部信息交互。因此,研究Transformer模型的可解释性具有重要意义。