 LoRAMoE综述
LoRAMoE综述
大模型微调新范式:当LoRA遇见MoE (opens new window)
引言
当LoRA遇见MoE,会擦出怎样的火花?

左侧:原始版本的LoRA,权重是稠密的,每个样本都会激活所有参数;右侧:与混合专家(MoE)框架结合的LoRA,每一层插入多个并行的LoRA权重(即MoE中的多个专家模型),路由模块(Router)输出每个专家的激活概率,以决定激活哪些LoRA模块。
由于大模型全量微调时的显存占用过大,LoRA、Adapter、IA
传统上,LoRA这类适配模块的参数和主干参数一样是稠密的,每个样本上的推理过程都需要用到所有的参数。近来,大模型研究者们为了克服稠密模型的参数效率瓶颈,开始关注以Mistral、DeepSeek MoE为代表的混合专家(Mixure of Experts,简称MoE)模型框架。在该框架下,模型的某个模块(如Transformer的某个FFN层)会存在多组形状相同的权重(称为专家),另外有一个**路由模块(Router)**接受原始输入、输出各专家的激活权重,最终的输出为:
- 如果是软路由(soft routing),输出各专家输出的加权求和;
- 如果是离散路由(discrete routing ),即Mistral、DeepDeek MoE采用的稀疏混合专家(Sparse MoE)架构,则将Top-K(K为固定的 超参数,即每次激活的专家个数,如1或2)之外的权重置零,再加权求和。
在MoE架构中,每个专家参数的激活程度取决于数据决定的路由权重,使得各专家的参数能各自关注其所擅长的数据类型。在离散路由的情况下,路由权重在TopK之外的专家甚至不用计算,在保证总参数容量的前提下极大降低了推理的计算代价。
那么,对于已经发布的稠密大模型的PEFT训练,是否可以应用MoE的思路呢?近来,笔者关注到研究社区开始将以LoRA为代表的PEFT方法和MoE框架进行结合,提出了MoV、MoLORA、LoRAMOE和MOLA等新的PEFT方法,相比原始版本的LORA进一步提升了大模型微调的效率。
本文将解读其中三篇具有代表作的工作,以下是太长不看版:
- https://arxiv.org/abs/2309.05444 (opens new window) [1]:提出于2023年9月,首个结合PEFT和MoE的工作,MoV和MoLORA分别是IA
和LORA的MOE版本,采用token级别的软路由(加权合并所有专家的输出)。作者发现,对3B和11B的T5大模型的SFT,MoV仅使用不到1%的可训练参数量就可以达到和全量微调相当的效果,显著优于同等可训练参数量设定下的LoRA。 - https://arxiv.org/abs/2312.09979 (opens new window) [2]:提出于2023年12月,在MoLORA [1]的基础上,为解决微调大模型时的灾难遗忘问题,将同一位置的LoRA专家分为两组,分别负责保存预训练权重中的世界知识和微调时学习的新任务,并为此目标设计了新的负载均衡loss。
- https://arxiv.org/abs/2402.08562 (opens new window) [3]:提出于2024年2月,使用离散路由(每次只激活路由权重top-2的专家),并发现在每一层设置同样的专家个数不是最优的,增加高层专家数目、降低底层专家数目,能在可训练参数量不变的前提下,明显提升LLaMa-2微调的效果。
MoV和MoLORA:PEFT初见MoE,故事开始
论文链接:https://arxiv.org/abs/2309.05444 (opens new window)
该工作首次提出将LoRA类型的PEFT方法和MoE框架进行结合,实现了MoV(IA
那么,MOV就是将这些可训练向量各自复制

MOV方法的示意图,引自论文[1]。
实验部分,作者在Public Pool of Prompts数据集上指令微调了参数量从770M到11B的T5模型,在8个held out测试集上进行测试。实验的微调方法包括全量微调、原始版本的IA

3B模型的测试结果,只使用0.32%可训练参数的MoV-10的平均accuracy(59.93)接近全量微调(60.06),明显优于使用0.3%可训练参数的原始版本LORA(57.71)。使用0.68%可训练参数的MoV-30(60.61)甚至超过全量微调。
此外,作者还对专家的专门程度(speciality,即每个任务依赖少数几个特定专家的程度)进行了分析,展示MOV-5微调的770M模型最后一层FFN中各专家路由概率的分布:

路由概率的分布,左侧为模型在训练集中见过的任务,右侧为测试集中模型未见过的任务。
可以看出,无论模型是否见过任务数据,大多数任务都有1-2个特别侧重的专家占据了大部分激活概率值,说明MoV这个MoE实现达成了专家的专门化。
LoRAMOE:LoRA专家分组,预训练知识记得更牢
论文链接:https://arxiv.org/abs/2312.09979 (opens new window)
此文为复旦大学NLP组的工作,研究动机是解决大模型微调过程中的灾难遗忘问题。
作者发现,随着所用数据量的增长,SFT训练会导致模型参数大幅度偏离预训练参数,预训练阶段学习到的**世界知识(world knowledge)**逐渐被遗忘,虽然模型的指令跟随能力增强、在常见的测试集上性能增长,但需要这些世界知识的QA任务性能大幅度下降:

左侧为不需要世界知识的常见测试集上的性能,右侧为需要世界知识的QA测试集上的表现,横轴为SFT数据量,红线为模型参数的变化程度。
作者提出的解决方案是:
- 数据部分:加入world knowledge的代表性数据集CBQA,减缓模型对世界知识的遗忘;
- 模型部分:以(1)减少模型参数变化、(2)隔离处理世界知识和新任务知识的参数为指导思想,在上一篇文章的MoLORA思想上设计了LoRAMoE方法,将LoRA专家们划分为两组,一组用于保留预训练参数就可以处理好的(和世界知识相关的)任务,一组用于学习SFT过程中见到的新任务,如下图所示:

为了训练好这样的分组专家,让两组专家在组间各司其职(分别处理两类任务)、在组内均衡负载,作者设计了一种名为localized balancing contraint的负载均衡约束机制。具体地,假设
其中 $\delta $ 为0-1之间的固定值(控制两组专家不平衡程度的超参), $ \operatorname{Type}_e(n)$ 为第
这样设计loss的用意是,对任意一种训练样本,两组LoRA专家组内的
这样一来,即使推理阶段没有数据类型
实验部分,作者在CBQA和一些列下游任务数据集混合而成的SFT数据上微调了LLaMA-2-7B,对比了全量SFT、普通LORA和作者所提的LoRAMoE的性能。结果显示,LoRAMoE有效克服了大模型SFT过程中的灾难性遗忘问题,在需要世界知识的QA任务(下表下半部分)上性能最佳,在与SFT训练数据关系更大的其他任务上平均来说基本与SFT训练的模型相当:

MOLA:统筹增效,更接近输出端的高层需要更多专家
论文链接:https://arxiv.org/pdf/2402.08562.pdf (opens new window)
该工作受到MoE领域先前工作[5]发现的专家个数过多容易导致性能下降的现象之启发,提出了两个问题:
- 现有PEFT+MoE的微调方法是否存在专家冗余的问题?
- 如何在不同中间层之间分配专家个数?
为了解答问题1,作者训练了每层专家个数均为5的LoRA+MoE(基座模型为32层的LLaMa-2 7B),路由机制采用Top-2离散路由,计算了每层self-attention的Q、K、V、O各组专家权重内两两之间求差的Frobenius范数的平均值,可视化如下:

横轴为模型层数,纵轴为专家权重之间的差异程度。
可以看出,层数越高(约接近输出端),专家之间的差异程度越大,而低层的专家之间差异程度非常小,大模型底层的LoRA专家权重存在冗余。该观察自然导出了对问题2答案的猜想**:高层需要更多专家**,在各层的专家个数之和固定的预算约束下,应该把底层的一部分专家挪到高层,用原文标题来说就是:
Higher Layers Need More Experts
为了验证该猜想,作者提出了四个版本的专家个数划分方式分别严重性能,它们统称为MoLA (MoE-LoRA with Layer-wise Expert Allocation),分别是:
- MoLA-△:正三角形,底层专家个数多,高层专家个数少;
- MoLA-▽:倒三角形,底层少,高层多;
- MoLA-▷◁: 沙漏型,两头多、中间少;
- MoLA-□:正方形,即默认的均匀分配。

四种在不同中间层之间划分专家个数的方式。
具体实现中,作者将LLaMA的32层从低到高分为4组,分别是1-8、9-16、17-24、25到32层,以上四种划分方式总的专家个数相等,具体划分分别为:
- MoLA-△:8-6-4-2
- MoLA-▽:2-4-6-8;
- MoLA-▷◁: 8-2-2-8;
- MoLA-□:5-5-5-5。
路由机制为token级别的Top-2路由,训练时加入了负载均衡损失。MoLA的LoRA rank=8,基线方法中LoRA的秩为64(可训练参数量略大于上述四种MoLA,与MOLA-□的8-8-8-8版本相同)评测数据集为MPRC、RTE、COLA、ScienceQA、CommenseQA和OenBookQA,在两种设定下训练模型:
- 设定1:直接在各数据集的训练集上分别微调模型;
- 设定2:先在OpenOrac指令跟随数据集上进行SFT,再在各数据集的训练集上分别微调模型。
从以下实验结果可以看出,在设定1下,MoLA-▽都在大多数数据集上都取得了PEFT类型方法的最佳性能,远超可训练参数量更大的原始版本LoRA和LLaMA-Adapter,相当接近全量微调的结果。

设定1下的实验结果
在设定2下,也是倒三角形的专家个数分配方式MoLA-▽最优,验证了“高层需要更多专家”的猜想。

笔者点评:从直觉来看,模型的高层编码更high-level的信息,也和目标任务的训练信号更接近,和编码基础语言属性的底层参数相比需要更多调整,和此文的发现相符,也和迁移学习中常见的layer-wise学习率设定方式(顶层设定较高学习率,底层设定较低学习率)的思想不谋而合,未来可以探索二者的结合是否能带来进一步的提升。
大模型微调新范式【续篇】——句向量聚类路由MoE+LoRA (opens new window)
上一篇文章https://zhuanlan.zhihu.com/p/683637455 (opens new window)梳理了最近出现的几篇将LoRA+MoE结合用于大模型微调的工作,反响不错。今天介绍一篇新看的工作https://arxiv.org/pdf/2312.12379.pdf (opens new window),主要改动是(太长不看版):
- Cluster-conditional MoE(句向量聚类路由MoE): 按instruction(整个句子)在预训练embedding模型的向量空间中的聚类中心当作MoE gate的输入,而不是采用token级别的routing(每个token embedding作为MoE gate的输入);
- Universal Expert:每个样本都会用到一个universal expert,和之前工作中的universal expert的主要区别是,它的权重由激活值最大(
)的专家决定,为 。
%E5%A4%A7%E6%A8%A1%E5%9E%8B%E5%BE%AE%E8%B0%83%E6%96%B0%E8%8C%83%E5%BC%8F%E7%BB%AD%E7%AF%87%E5%8F%A5%E5%90%91%E9%87%8F%E8%81%9A%E7%B1%BB%E8%B7%AF%E7%94%B1MoELoRA_Sam%E8%81%8A%E7%AE%97%E6%B3%95/v2-f8b51845f2ba90b1f430dd0967266b9e_1440w.jpg)
实验主要是在多模态大模型InstructBLIP的多模态SFT阶段做的,效果要好过普通的LoRA、上一篇文章介绍的采用token级别routing的LoRA+MoE。下面详细来看。
上期回顾
Sam多吃青菜:大模型微调新范式:当LoRA遇见MoE (opens new window)
- https://arxiv.org/abs/2309.05444 (opens new window):提出于2023年9月,首个结合PEFT和MoE的工作,MoV和MoLORA分别是IA
和LORA的MOE版本,采用token级别的软路由(加权合并所有专家的输出)。作者发现,对3B和11B的T5大模型的SFT,MoV仅使用不到1%的可训练参数量就可以达到和全量微调相当的效果,显著优于同等可训练参数量设定下的LoRA。 - https://arxiv.org/abs/2312.09979 (opens new window):提出于2023年12月,在MoLORA [1]的基础上,为解决微调大模型时的灾难遗忘问题,将同一位置的LoRA专家分为两组,分别负责保存预训练权重中的世界知识和微调时学习的新任务,并为此目标设计了新的负载均衡loss。
- https://arxiv.org/abs/2402.08562 (opens new window):提出于2024年2月,使用离散路由(每次只激活路由权重top-2的专家),并发现在每一层设置同样的专家个数不是最优的,增加高层专家数目、降低底层专家数目,能在可训练参数量不变的前提下,明显提升LLaMa-2微调的效果。
MoCLE:采用句向量聚类路由的LoRA+MoE,更适合多模态大模型SFT
https://arxiv.org/pdf/2312.12379.pdf (opens new window)
普通的MoE使用token级别的路由,将每个token的中间embedding作为MoE gate的输入得到各个expert的激活权重,而MoCLE使用句子级别的聚类路由,即将每个样本的Intruction部分用SentenceTransformer这种预训练句向量模型抽取的向量表示,先在训练集上做K-means,推理的时候把测试样本对应的最近聚类中心的embedding作为MoE gate的输入,得到激活权重
为了保证泛化性,另外设一个每个测试样本都会用到的LoRA专家,其激活值权重为1减去最大的专家激活值
实验中以all-MiniLM-L6-v2为聚类用的embedding模型,InstructBLIP为基座大模型,在LLaVA-Instruct150K、COCO(captioning)和一些VQA数据集上做insutrction tuning。结果显示,该工作提出的MoCLE可以缓解多模态SFT中不同任务的冲突问题,结构在大多数测试集上超过原版的InstructBLIP:
%E5%A4%A7%E6%A8%A1%E5%9E%8B%E5%BE%AE%E8%B0%83%E6%96%B0%E8%8C%83%E5%BC%8F%E7%BB%AD%E7%AF%87%E5%8F%A5%E5%90%91%E9%87%8F%E8%81%9A%E7%B1%BB%E8%B7%AF%E7%94%B1MoELoRA_Sam%E8%81%8A%E7%AE%97%E6%B3%95/v2-83d629cf16fb0ed863322c1575dfbfed_1440w.jpg)
Ablation Study显示了句子级别的聚类路由带来的提升:
%E5%A4%A7%E6%A8%A1%E5%9E%8B%E5%BE%AE%E8%B0%83%E6%96%B0%E8%8C%83%E5%BC%8F%E7%BB%AD%E7%AF%87%E5%8F%A5%E5%90%91%E9%87%8F%E8%81%9A%E7%B1%BB%E8%B7%AF%E7%94%B1MoELoRA_Sam%E8%81%8A%E7%AE%97%E6%B3%95/v2-5ebcb9ff06831c28aa0c6d163b20de5c_1440w.jpg)
%E5%A4%A7%E6%A8%A1%E5%9E%8B%E5%BE%AE%E8%B0%83%E6%96%B0%E8%8C%83%E5%BC%8F%E7%BB%AD%E7%AF%87%E5%8F%A5%E5%90%91%E9%87%8F%E8%81%9A%E7%B1%BB%E8%B7%AF%E7%94%B1MoELoRA_Sam%E8%81%8A%E7%AE%97%E6%B3%95/v2-5a84c040e2131627266bb0c2bf70eb82_1440w.jpg)
点评
这种用句向量聚类中心作为MoE gate输入的做法有点像KNN的思想,能比常见的token级别routing要好还挺惊喜的,不知道文章的结论是否适用于纯语言的LLM。
LLaVA-MoLE
摘要
LLaVA-MoLE 提出了一种高效的专家混合(MoE)设计,它是一种用于指令微调 MLLM 的稀疏低秩自适应(MoLE)的混合。在 Transformer 层内,我们通过为 MLP 层创建一组专门用于 LoRA 的专家,扩展了 LoRA 方法,并基于路由函数将每个 token 路由到排名第一的专家,允许对来自不同领域的令牌进行自适应选择。由于 LoRA 专家被稀疏激活,与原始的 LoRA 方法相比,训练和推理成本基本保持不变。 使用 MoE 设计替换 LLaVA-1.5 的普通 LoRA,最终模型被命名为 LLaVA-MoLE。广泛的实验证明,LLaVA-MoLE 在混合多个不同的指令数据集以及各种配置时,有效地缓解了数据冲突问题,并在强大的普通 LoRA 基线上实现了一致的性能提升。最重要的是,在混合数据集上,LLaVA-MoLE 甚至可以超过使用两倍样本训练的普通 LoRA 基线的性能。
背景介绍
研究中发现,当前使用普通 LoRA 进行训练的 MLLM 对于训练数据的配置非常敏感。如图1所示,我们采用了来自不同领域的三个指令微调数据集:
- 一个包含各种视觉语言指令数据混合的通用多任务数据集;
- 一个针对图表、表格和文档理解构建的面向文档的数据集;
- 一个由病理图像上的问答对组成的生物医学数据集。
通过对比,当 MLLM 在每个单独的数据集上进行微调时,它在相应的基准测试上取得了合理的性能。但是,当将文档和生物医学数据集与通用数据集混合在一起时,经过训练的LLaVA-Mix 在通用基准测试上的性能从 306.3 下降到 295.8,这意味着添加与通用多任务指令明显不同的数据会导致冲突。这严重阻碍了通过添加来自新领域的训练数据来扩展 MLLM 能力的可能性。
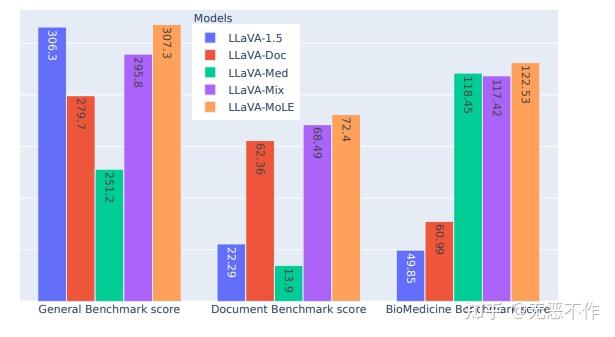
图1
解决方法
为了解决上述问题,提出了将稀疏的 LoRA 专家混合应用于 LLaVA-1.5 进行指令微调,从而得到模型 LLaVA-MoLE。重新设计了 LoRA 应用于 LLM 的 Transformer 层中的MLP。不仅仅向原始线性层添加一对低秩分解矩阵,而是引入了一组具有与原始 LoRA 相同结构但不同权重的专家。如图2所示,LLaVA-MoLE 与稀疏的 LoRA 专家混合模型的整体框架。模型基于LLaVA-1.5,其中输入图像经过 CLIP ViT处理,然后通过一个两层 MLP 进行投影。输入文本被 tokenizer 和 embedding 处理,然后与视觉输入连接以输入 LLM。LLM 的每一层都是使用提出的稀疏的 LoRA 专家进行训练的。FFN 根据路由器的输出分布选择并与一个 LoRA 专家进行组合。自注意力也使用 LoRA 进行训练,但不应用MoE(混合专家)技术。
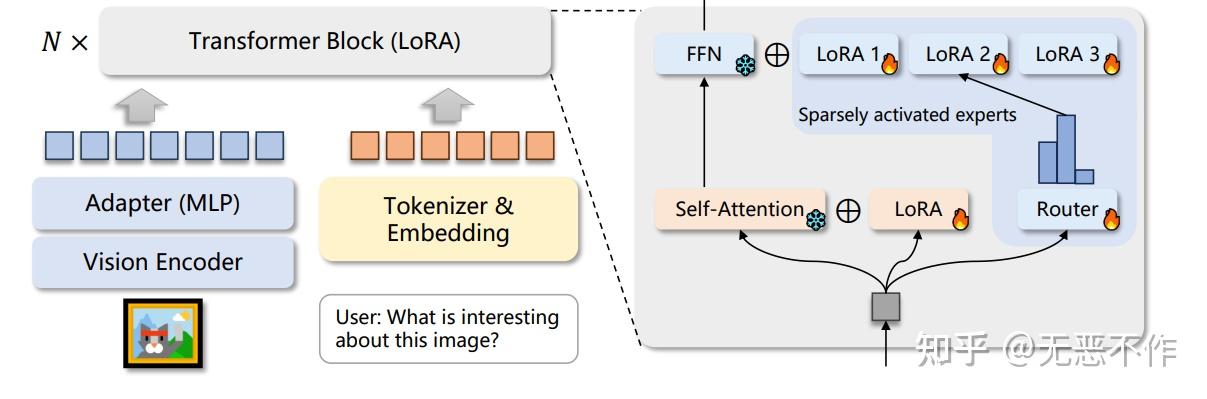
图2

广告
(专享)知乎知物 15 倍超浓缩咖啡萃取液 2 盒
知乎
¥65.00
去购买 (opens new window)
其中作者推导一个多模态大型语言模型(MLLM)可以表示为:
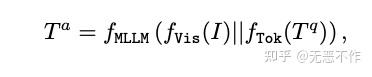
作者提出的方法的目标是在混合不同类型的指令数据时减轻冲突。为此,我们引入了一组 LoRA 专家和每个 Transformer 层的路由器。在每个输入标记处,路由器学习选择最合适的专家进行激活,以便模型具有处理不同类型输入的额外能力。假设每层有 K 个专家,选择具有最高路由函数值的专家:
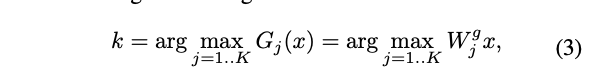
为了更具体,现代 LLMs 中的 FFN 层通常是多层的。在这种情况下,FFN 的每个线性层都有一个独立的 MoE,但它们共享同一个路由器,即这些层的专家选择是相同的。通过仅激活排名第一的专家,实际计算成本与使用普通 LoRA 的原始 FFN 大致相同。(这部分公式含义可以参见论文,不展开介绍了)
负载均衡
如前一节介绍的,通过将每一个 token 路由到单个专家,MoE 模型的总计算量基本接近于普通的 LoRA 模型。然而,如果专家分配严重不平衡,低负载的专家将会有浪费的空闲时间。与之前的稀疏 MoE 方法类似,引入 MoE 层引入了负载平衡损失,其公式为:


广告
知乎知物经典深烘焙日式意式挂耳(16包/盒) 日式*1+
知乎自营
¥75.00
去购买 (opens new window)
每层的损失取平均,并乘以一个常数因子
实验
实验配置,作者将 PathVQA 用作生物医学领域的指令数据。它包含来自 4,998 张病理图像的32,799 个问题。训练集有 19,755 个问答对,测试集有 3,370 个开放式问题和 3,391 个闭合式问题。我们在开放式和闭合式问题集上报告结果。
对于这两个阶段,我们使用 Deepspeed ZeRO-2 优化在64个 NVIDIA A100 80GB GPU 上进行模型训练。在三个数据集的混合上微调一个 LLaVA-MoLE 模型大约需要16小时。采用 AdamW 优化器进行训练,并进行学习率预热。在图3中列出了训练配置的重要参数。
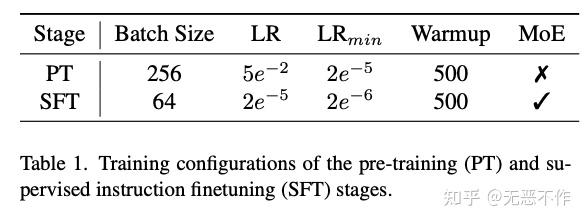
图3
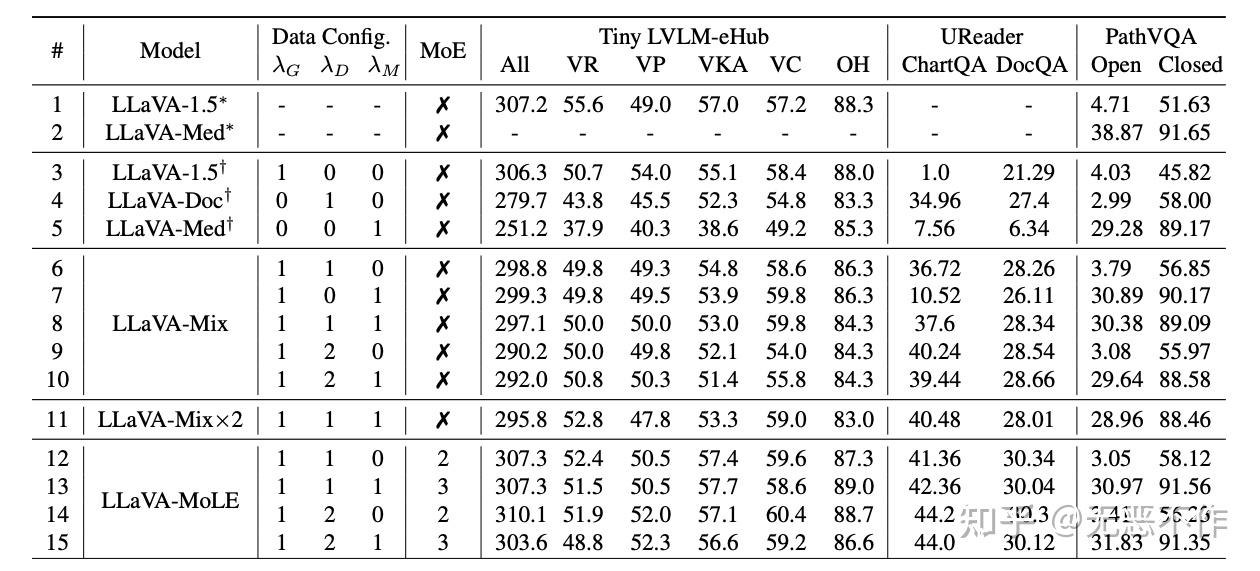
图4
图 4 中使用不同数据和 MoE 配置训练的模型的实验结果。λG、λD 和 λM 分别是用于一般多任务数据、文档数据和生物医学数据的采样频率。采样频率为 0 表示未使用该数据集。VR、VP、VKA、VC 和 OH 分别代表粗略能力类别的视觉推理、视觉感知、视觉知识获取、视觉常识和物体幻觉。∗表示官方发布的模型,†表示我们复现的模型,×2表示模型训练了两个周期。LLaVA-Mix 和 LLaVA-MoLE 是使用不同的数据集混合配置进行训练的,通过追加数据配置来区分它们。LaVA-MoLE 可以成功解决多任务数据存在的冲突问题。
总结
本文的贡献总结如下:
- 基于先进的 MLLM 模型和大规模数据集,发现在将 MLLM 在明显不同的指令数据集混合上进行指令微调时存在数据冲突问题。
- 提出了 LLaVA-MoLE,它是通过稀疏的 LoRA 专家混合进行指令微调,以解决数据冲突问题,而不会显著增加训练计算或内存。允许调整混合中每个数据集的采样比例,以在特定任务上实现更高的性能,而不影响其他任务。
- 广泛的实验证明,与使用普通 LoRA 微调相比,LLaVA-MoLE 在多个基准测试上对于各种数据配置都实现了一致的性能提升。
MOELoRA
摘要
最近在大型语言模型(LLMs)领域出现了一股热潮,引起了许多领域的重视。为了将 LLM 定制到特定领域,如基于网络的医疗保健系统,需要使用领域知识进行微调。然而,在为医疗应用进行LLM微调时会出现两个问题。
- 第一个问题是任务多样性,真实世界的医疗场景中存在许多不同的任务。这种多样性通常导致微调不够优化,因为存在数据不平衡和摇摆问题。
- 此外,微调的高成本可能会阻碍 LLM 的应用。LLMs 中的大量参数导致在微调过程中需要消耗巨大的时间和计算资源,这很难合理解释。
作者提出了一种新颖的用于多任务医疗应用的参数高效微调框架,称为 MOELoRA。该框架旨在充分利用 MOE 进行多任务学习和 LoRA 进行参数高效微调的优势。为了验证所提方法的有效性和实用性,作者在一个公开的多任务中文医学数据集上进行了全面的实验。实验结果表明,MOELoRA 优于现有的参数高效微调方法。
背景介绍
由于大型语言模型(LLMs)在语言理解和生成方面的卓越能力,如 ChatGPT 和ChatGLM,它们在学术界和工业界引起了广泛的关注。许多工作致力于研究 LLMs 在各个领域的潜在应用。对于 LLMs 而言,医疗领域是一个特别适合的领域,因为 LLMs 的应用可以使患者和医生受益。对于患者而言,基于LLM的在线聊天机器人可以提供方便的医学知识获取途径;对于医生而言,基于 LLM 的临床决策支持系统(CDSS)可以减轻他们的工作负担并提高诊断效率。
将 LLMs 用于医疗领域的微调通常涉及两个主要挑战:
- 任务多样性问题:在真实世界的临床环境中,LLMs 可以应用于各种任务,如医生推荐、诊断预测、药物推荐、医学命名实体识别、临床报告生成等。由于这些任务的输入和输出非常不同,很难为所有任务微调一个统一的模型。
- 高调整成本:在 Bert 时代,微调所有模型参数是一种标准方法,但对于 LLMs 来说,由于其庞大的规模,这变得具有挑战性。LLMs中大量的参数可能导致实际中的时间和计算开销非常高。因此,迫切需要参数高效的微调方法。
解决方法
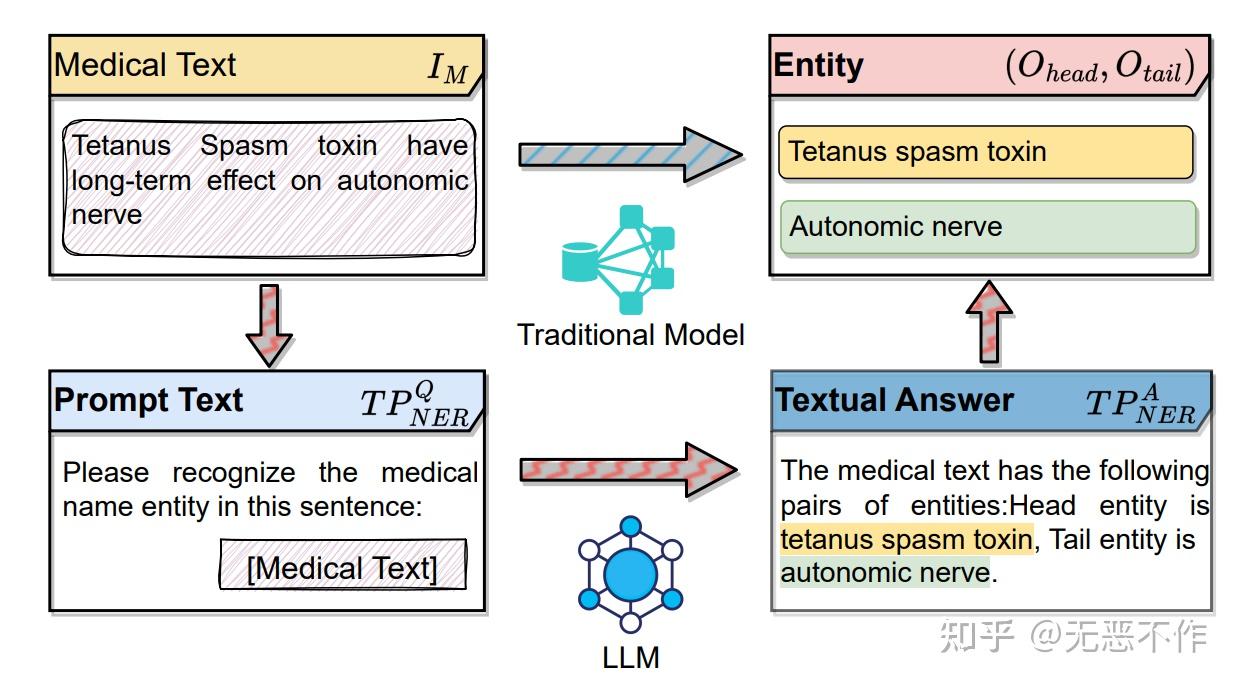
图5
在当代基于网络的医疗保健环境中,智能医疗系统越来越普遍。许多研究试图通过定义一致的输入和输出模式来标准化医疗任务,从而简化模型设计过程。以医学命名实体识别(NER)为例,如图 5 所示,传统模型通常处理医学文本(表示为

在为 LLMs 进行任务重构之后,我们可以使用纯语言数据对基础大型语言模型进行微调,例如LlaMA,ChatGLM等。然后,微调后的模型通过生成规范化的答案来完成医疗任务。
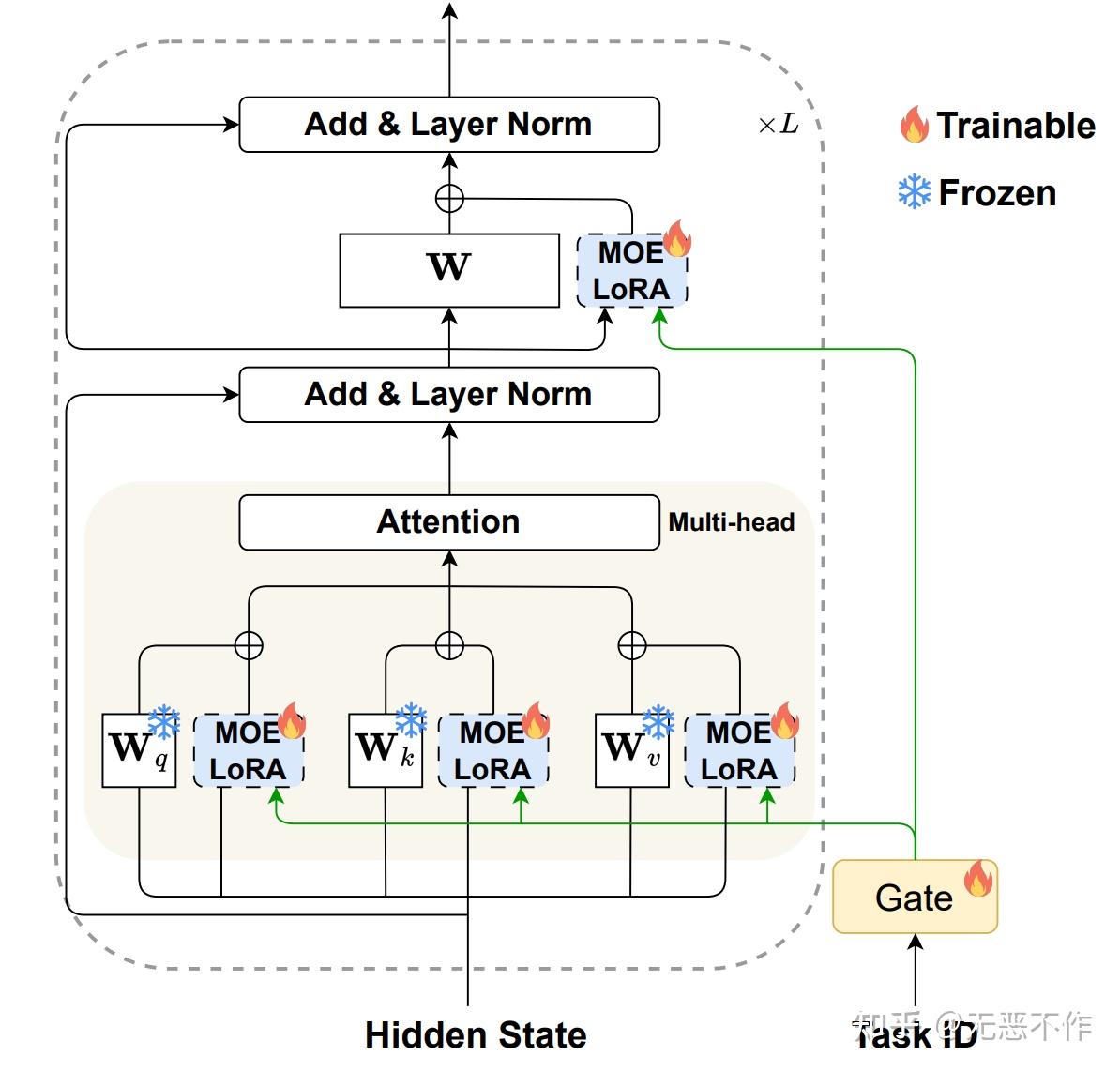
图6
图 6 提供了使用 MOELoRA 对 LLMs 进行参数高效微调的过程的可视化表示。在参数高效微调领域,LoRA 仅引入了两个低秩矩阵作为密集层的替代。在此基础上,作者的方法将 MOELoRA 层集成到每个密集层中,使它们能够获取键、查询和值,并促进前馈过程。此方法的一个重要优势是,只微调 MOELoRA 层的参数,保持原始 LLM 的其余参数不变。这种方法大大降低了微调的成本。
此外,每个 MOELoRA 层都包含多个共享的专家。这些专家被设计用于捕捉不同医学领域的多样化知识。引入了一个任务驱动的门函数,以确保为每个任务学习到独特的参数集。该函数确定了所有 MOELoRA 层中专家的贡献权重,使得可以生成针对不同任务定制的不同更新参数。值得注意的是,作者为所有 MOELoRA 层使用单个 gating 函数,而不是在 gating 和MOELoRA 层之间建立对应关系。这种设计选择是有意的,旨在减少可调参数的数量,并减轻过参数化的风险。
MOELoRA
在原始的 LoRA 中,所有任务的参数都进行微调,导致难以学习医学知识的各个方面。解决这个挑战的一个潜在解决方案是将整个参数集分割成几个部分,并推导出各种组合。多任务专家模型(MOE),使用多个专家网络来捕捉多任务信息的不同方面,与组合概念相吻合。这一观点引导作者设计了 MOELoRA,无缝地整合了 LoRA 和 MOE 的优势。为了使 LoRA 和 MOE 的不同前向过程协调一致,我们引入了一组专家,表示为 {Ei}i=1N
为了确保不同任务学习到不同的参数,每个专家的贡献应该是任务特定的。在下图 7 中,项 ωji
的这些贡献权重。(细节参考论文原文)
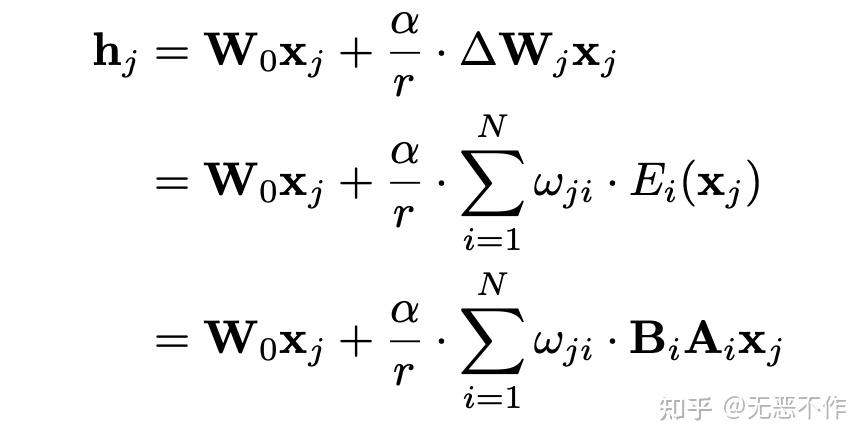
图7
MOELoRA 的训练和推理过程如下图 8 所示。

图8
3.5 推理和优化
优化:作者讨论 MOELoRA 的优化和推理过程。如上算法过程中总结了整个过程,首先根据 LLM 中指定的层和几个超参数配置 MOELoRA(第1-3行)。然后,为了进行参数高效的微调,LLM 中的所有预训练参数都被冻结(第4行)。在优化过程中,代地随机从所有任务中抽取一批数据,而不是像一些多任务研究那样将来自同一任务的样本分组成一批。作者选择随机抽样的批次进行性能比较实验。使用数据批次,可以进行前向过程并计算训练损失(第6-7行)。在参数更新方面,值得注意的是,作者只微调 MOELoRA 和任务驱动的门函数的参数。
推理:MOELoRA可以通过方程(6)为每个任务恢复微调的参数矩阵。在推理过程中,首先为每个任务恢复训练好的 LLM 参数(第10-13行),这意味着每个任务都有自己的 LLM 参数。然后,可以应用相应的 LLM 来完成指定的任务。
实验
在本节中,作者对一个多任务的中文医学数据集进行了全面的实验。通过对实验结果的详细分析,试图回答以下研究问题(RQ):
- RQ1:在性能方面,MOELoRA 与其他参数高效微调策略和跨任务泛化方法相比如何?
- RQ2:MOE 架构和 gating 函数对微调过程有何影响?此外,不同的训练策略如何影响MOELoRA 的性能?
- RQ3:专家数量和MOELoRA的秩如何影响性能结果?
- RQ4:专家是否专门捕捉特定知识方面的信息?
通过回答这些问题,可以深入了解 MOELoRA 的性能、架构和训练策略对于多任务学习的影响,并探讨专家的特化程度以及它们在捕捉特定知识方面的能力。这些实验结果将有助于我们评估 MOELoRA 的优势和适用性,并为进一步改进和应用提供指导。
数据集:作者的实验是在 PromptCBLUE 数据集上进行的,该数据集包含16个不同的医学任务,每个任务都使用特定的提示转换为纯文本格式,以确保与 LLM 兼容。
基准线:在实验中,作者与三个不同的基准线组进行了对比,分别是:
- 无微调的LLM
- 微调的LLM
- 跨任务泛化。后两组利用 ChatGLM 6B 进行微调
实现细节:使用PyTorch 1.12.0 和 Python 3.6. 5。在Tesla V100 GPU上运行代码以加速计算。LLM ChatGLM 6B 选为微调的基础模型。其他配置如下:
- 模型层:对于所有 LoRA 微调基准线和提出的 MOELoRA。
- 输入/输出长度:最大输入长度和输出长度分别配置为1,024和196。
- 参数:我们将 batchsize 大小设置为 64,最大训练步数为 8,000。LoRA 的秩 r 固定为16,LoRA 的 dropout α = 0.1。对于 MOELoRA,专家数量设置为 8。
如图 9 所示,基线和 MOELoRA 在 PromptCBLUE 上的整体结果。粗体表示最高分数,下划线表示基线的最佳结果。 "*"表示相对于最佳基线的统计显著改进(即,双边 t 检验,p < 0.05)。
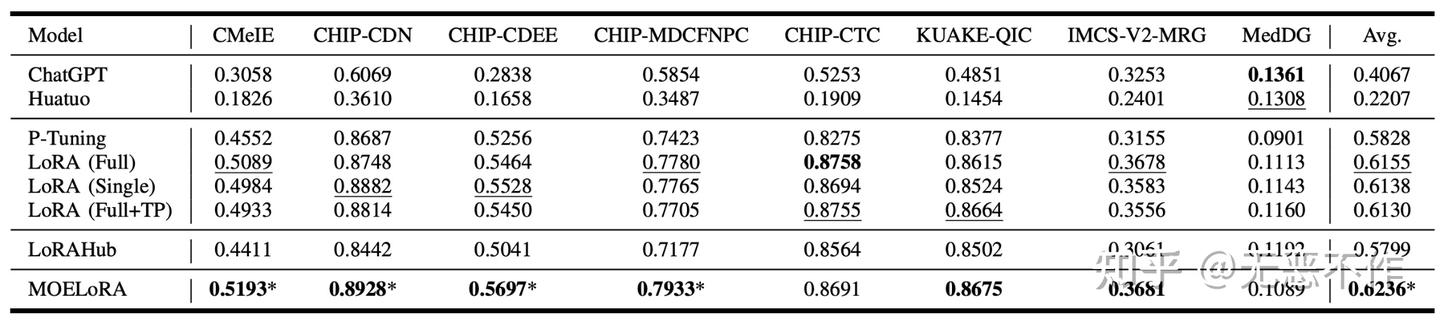
图9
MOELoRA 和竞争基准线的综合实验结果如图 9 所示。分析所有任务的平均分数,可以明显看出MOELoRA 始终优于所有其他方法。

图10
为了更深入地探讨 RQ2 并了解 MOELoRA 中每个组件的贡献,作者在图 10 中展示了消融研究结果。去除 MOE的 变体(实质上回到LoRA(Full))排除了 MOE 架构。它表现出较差的性能,与完整的 MOELoRA 相比,突出了 MOE 架构的重要性。同样,去除 gating 函数的变体,它使用均匀的专家权重绕过门函数,也落后于 MOELoRA,突显了gating 函数的有效性。多个 gating 函数的变体为每个 MOELoRA 层使用独特的 gating 函数。可以看到,它在几个任务上实现了可比较的结果,但由于过度参数化而略逊于单个门函数设计。此外,多个门函数还会导致更高数量的可训练参数,与单个门函数设置相比效率降低。
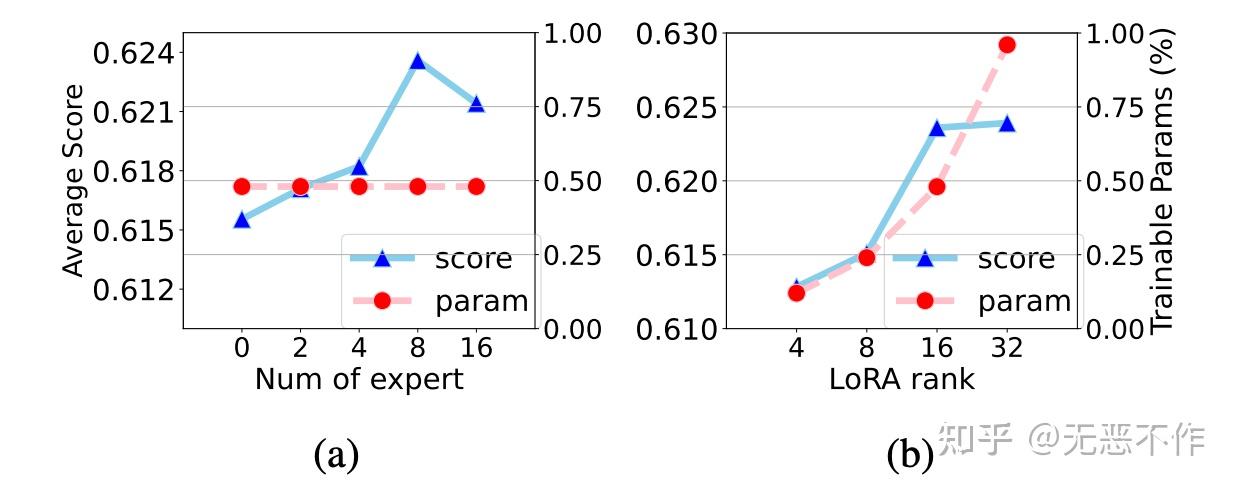
图11
为了回答 RQ3,作者深入研究了超参数对 MOELoRA 性能的影响。从图 11b 中观察到,虽然 r的增加始终提高性能,但也会导致可训练参数的相应增加。考虑到效率和性能之间的平衡,r 的一个实际选择是 16。
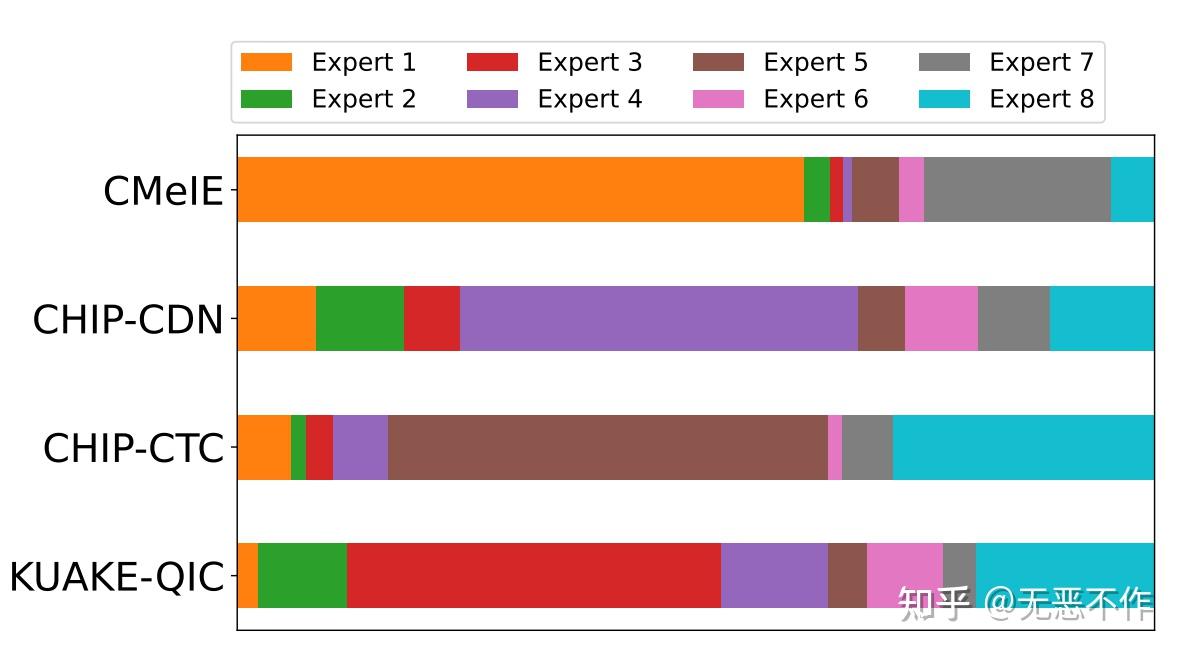
图12
对于RQ4,在图 12 中呈现了四个任务中的专家权重的可视化。对于每个任务,不同颜色的条的长度表示相应专家的权重。由于专家权重被归一化为1,因此每个任务的条的长度相同。在宏观层面上,明显可以看出每个专家的贡献差异很大,突显了不同专家在医学知识的不同方面专长的观点。此外,权重在不同任务之间的显著差异突出了医学应用的多样性。仔细观察 CHIP-CDN 和KUAKE-QIC 任务,可以看到它们的专家权重在很大程度上是一致的,只有专家 3 和 4 有些例外。鉴于 CHIP-CDN 可以被视为 KUAKE-QIC 的前身——因为诊断词归一化可以增强查询分类——专家权重的相似性表明 MOELoRA 擅长利用共享知识来使内在相关的任务受益。
总结
在本文中,作者首先迈出了一步,探索了 LLM 驱动的医学应用的多任务参数高效微调方法。为了满足微调的效率要求和多任务的有效性要求,作者提出了一种新颖的多任务微调框架。具体而言,设计了 MOELoRA 架构,它由多个低秩专家组成,作为可训练参数来学习与任务相关的知识并保持高效性。此外,我们设计了一种任务驱动的 gating 函数,用于为不同任务生成不同的微调参数。通过对一个多任务的中文医学数据集进行全面的实验,验证了所提出的MOELoRA 的有效性。在未来,作者将进一步探索如何通过微调将显式的医学知识(如知识图谱)与 LLM 相结合。
Higher Layers Need More LoRA Experts
https://arxiv.org/abs/2402.08562
MOLA:提出于 2024 年 2 月,使用离散路由(每次只激活路由权重 top-2 的专家),并发现在每一层设置同样的专家个数不是最优的,增加高层专家数目、降低底层专家数目,能在可训练参数量不变的前提下,明显提升 LLaMa-2 微调的效果。
该工作受到 MoE 领域先前工作发现的专家个数过多容易导致性能下降的现象之启发,提出了两个问题:
- 现有 PEFT+MoE 的微调方法是否存在专家冗余的问题?
- 如何在不同中间层之间分配专家个数?
为了解答问题 1,作者训练了每层专家个数均为 5 的 LoRA+MoE(基座模型为 32 层的 LLaMa-2 7B),路由机制采用 Top-2 离散路由,计算了每层 self-attention 的 Q、K、V、O 各组专家权重内两两之间求差的 Frobenius 范数的平均值,可视化如下:

可以看出,层数越高(约接近输出端),专家之间的差异程度越大,而低层的专家之间差异程度非常小,大模型底层的 LoRA 专家权重存在冗余。该观察自然导出了对问题 2 答案的猜想:高层需要更多专家,在各层的专家个数之和固定的预算约束下,应该把底层的一部分专家挪到高层,用原文标题来说就是:Higher Layers Need More Experts
为了验证该猜想,作者提出了四个版本的专家个数划分方式分别严重性能,它们统称为 MoLA(MoE-LoRA with Layer-wise Expert Allocation),分别是:
MoLA-△:正三角形,底层专家个数多,高层专家个数少; MoLA-▽:倒三角形,底层少,高层多; MoLA-▷◁: 沙漏型,两头多、中间少; MoLA-□:正方形,即默认的均匀分配。

具体实现中,作者将 LLaMA 的 32 层从低到高分为 4 组,分别是 1-8、9-16、17-24、25 到 32 层,以上四种划分方式总的专家个数相等,具体划分分别为:
MoLA-△:8-6-4-2 MoLA-▽:2-4-6-8; MoLA-▷◁: 8-2-2-8; MoLA-□:5-5-5-5。
路由机制为 token 级别的 Top-2 路由,训练时加入了负载均衡损失。MoLA 的 LoRA rank=8,基线方法中 LoRA 的秩为 64(可训练参数量略大于上述四种 MoLA,与 MOLA-□ 的 8-8-8-8 版本相同)评测数据集为 MPRC、RTE、COLA、ScienceQA、CommenseQA 和 OenBookQA,在两种设定下训练模型:
- 设定 1:直接在各数据集的训练集上分别微调模型;
- 设定 2:先在 OpenOrac 指令跟随数据集上进行 SFT,再在各数据集的训练集上分别微调模型。
从以下实验结果可以看出,在设定 1 下,MoLA-▽ 都在大多数数据集上都取得了 PEFT 类型方法的最佳性能,远超可训练参数量更大的原始版本 LoRA 和 LLaMA-Adapter,相当接近全量微调的结果。

在设定 2 下,也是倒三角形的专家个数分配方式 MoLA-▽ 最优,验证了“高层需要更多专家”的猜想。

笔者点评:从直觉来看,模型的高层编码更 high-level 的信息,也和目标任务的训练信号更接近,和编码基础语言属性的底层参数相比需要更多调整,和此文的发现相符,也和迁移学习中常见的 layer-wise 学习率设定方式(顶层设定较高学习率,底层设定较低学习率)的思想不谋而合,未来可以探索二者的结合是否能带来进一步的提升。
MoCLE-Mixture of Cluster-conditional LoRA Experts for Vision-language Instruction Tuning
- Cluster-conditional MoE(句向量聚类路由 MoE): 按 instruction(整个句子)在预训练 embedding 模型的向量空间中的聚类中心当作 MoE gate 的输入,而不是采用 token 级别的 routing(每个 token embedding 作为 MoE gate 的输入);
- Universal Expert:每个样本都会用到一个 universal expert,和之前工作中的 universal expert 的主要区别是,它的权重由激活值最大的专家决定(
)

MoV 和 MoLORA:提出于 2023 年 9 月,首个结合 PEFT 和 MoE 的工作,MoV 和 MoLORA 分别是
Multi-Task Dense Prediction via Mixture of Low-Rank Experts
文章提出的 MLoRE 是一种利用低秩(Low-Rank)结构和对专家支路的重新设计的多任务密集预测算法。如图 2 所示,文章所设计的 MLoRE 模块以不同任务的任务特定特征为输入,然后将每个任务特定特征根据路由网络计算出的路由值送入不同的低秩专家网络,低秩专家依靠低秩结构可以拥有更低的参数量。同时,为了保证建模全局任务联系,所有的特征都将通过一个同样的任务通用路径,最后,将来自任务通用路径,任务共享低秩专家网络和任务特定专家网络的特征相加,在建模任务间关系的同时也能生成有区分度的任务特定特征。此外,模块去除了所有路径中的激活函数,实现了重新参数化以减少推理时的计算成本。通过这一设计,MLoRE 模块能够显著提高多任务密集预测的性能,并有效解决了全局任务关系建模和参数计算成本增加的问题。

整体框架:文章所提出的 MLoRE 是基于解码器的多任务密集预测方法。它使用一个训练好的 ViT(Vision Transformer)作为所有任务的编码器。然后在不同的层上提取特征,这些特征通过一个轻量的任务特定卷积层得到该层的任务特定的特征。这些特征被输入到 MLoRE 模块中,从而在建立不同任务之间的联系的同时建立更加具有区分度的特征。经过 MLoRE 处理后,来自不同层的特征最后被连接到一起,通过任务特定的预测头获得不同任务的密集预测。
专家混合模型:在多任务密集预测里,一个专家混合模型通常包含
图片
此外,在有些方法[8]中,会通过稀疏激活的方式减少推理时的计算量,同时让不同的专家学到不同的知识。具体来说,每个任务只会激活对应的路由值在前 k 的专家,其余的专家的知识都和最终结果无关。
低秩专家混合模型:如图 2 所示,文章所提出的低秩混合专家模型主要包含三个支路。其中第一个支路是任务共享通用支路,它包含一个 3x3 的卷积层。来自所有任务的任务特定特征都会通过这一个支路,这一支路也因此会接受来自所有任务的梯度,所以可以建模所有的任务之间的联系。同时,为了防止来自不同的任务的梯度会影响整个模型的优化,这个支路向后传递的梯度被停止,而梯度只会经由其它两个支路进行向后传递。这一支路的设计虽然并不复杂,但是在实验中体现出了对性能的显著的提升,体现了建模所有任务之间的联系对多任务学习的重要性。
第二个支路是任务共享低秩专家支路,这一支路包含
第三个支路是任务特定的低秩专家支路。这一支路为每个任务设定了一个单独的低秩专家,设计这一专家的目的是让 MLoRE 模块能够建模任务之间联系的同时也能提升建模的特征的区分度。
来自三个支路的输出被线性加和到一起,得到最终的任务特定特征,其中第 t 个任务的任务特定特征可以被表示如下:
其中
路由网络的设计:如图 2 所示,每个低秩混合专家支路在每个任务上都由一个路由网络来控制专家的分配,关于路由网络的设计,参照之前的工作Strip pooling: Rethinking spatial pooling for scene parsing (opens new window),文章认为路由中的全局信息也十分重要,所以设计了两条支路,一条支路从通道的角度进行处理,另一条支路从全局的特征角度进行处理,两者结合就可以实现全局的感受野,从而实现更加准确的专家分配,更好地挖掘任务与任务之间的关系。
重参数化:在推理时,为了减少激活大量专家带来的计算量增长,我们把专家和所有支路中的激活函数去除,从而实现全线性的专家网络(可参考Diverse branch block: Building a convolution as an inception-like unit (opens new window))。具体而言,我们首先把所有的低秩专家转化为一个 3x3 的卷积核,然后在推理时,通过对不同的样本和任务计算出不同的路由值之后,对其权重进行加权求和。在Diverse branch block: Building a convolution as an inception-like unit (opens new window)中证明了这样可以得到和正常推理相同的结果,但是因为多个专家网络被转化为单个卷积核,因此能够令计算量不会随着专家数量的增长而增长,同时不损害其学到的任务间关系。
Mixture-of-LoRAs: An Efficient Multitask Tuning for Large Language Models
摘要:首先在每个域上训练一个单独的 LoRA Module,然后训练一个路由器,选择最优的 module 融合到 LLM 的每个 trasnformer 层中。路由器的训练数据是从每个域任务中均匀采样得到。

Routing Strategy
- 采用序列级(sequence-level)的路由策略,训练阶段根据数据标签选择相应的域专家
- Model 的训练和路由的训练分开完成
MoA Architecture
: LLM attention + feed-forward 的权重,训练过程中固定不变 : 路由参数,每层一个,实现方式为两层 MLP : transformer 每层定义的 LoRA
实验结果
MTLoRA: A Low-Rank Adaptation Approach for Efficient Multi-Task Learning
https://arxiv.org/pdf/2403.20320.pdf