 DDIM
DDIM
扩散模型之DDIM
Author: [小小将]
Link: [https://zhuanlan.zhihu.com/p/565698027]
“What I cannot create, I do not understand.” -- Richard Feynman
上一篇文章https://zhuanlan.zhihu.com/p/563661713 (opens new window)介绍了经典扩散模型DDPM的原理和实现,对于扩散模型来说,一个最大的缺点是需要设置较长的扩散步数才能得到好的效果,这导致了生成样本的速度较慢,比如扩散步数为1000的话,那么生成一个样本就要模型推理1000次。这篇文章我们将介绍另外一种扩散模型DDIM(https://arxiv.org/abs/2010.02502 (opens new window)),DDIM和DDPM有相同的训练目标,但是它不再限制扩散过程必须是一个马尔卡夫链,这使得DDIM可以采用更小的采样步数来加速生成过程,DDIM的另外是一个特点是从一个随机噪音生成样本的过程是一个确定的过程(中间没有加入随机噪音)。
DDIM原理
在介绍DDIM之前,先来回顾一下DDPM。在DDPM中,扩散过程(前向过程)定义为一个马尔卡夫链:
注意,在DDIM的论文中,
扩散过程的一个重要特性是可以直接用
而DDPM的反向过程也定义为一个马尔卡夫链:
这里用神经网络
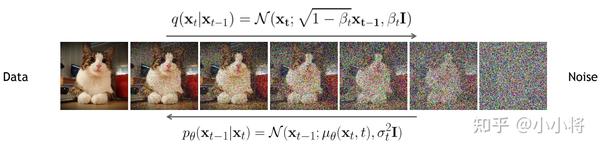
我们近一步发现后验分布
其中这个高斯分布的方差是定值,而均值是一个依赖
然后我们基于变分法得到如下的优化目标:
根据两个高斯分布的KL公式,我们近一步得到:
根据扩散过程的特性,我们通过重参数化可以近一步简化上述目标:
如果去掉系数,那么就能得到更简化的优化目标:
仔细分析DDPM的优化目标会发现,DDPM其实仅仅依赖边缘分布
这里要同时满足
这里的方差
这部分的证明见DDIM论文的附录部分,另外博客https://kexue.fm/archives/9181 (opens new window)也从待定系数法来证明了分布
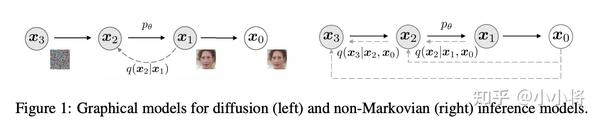
注意,这里只是一个前向过程的示例,而实际上我们上述定义的推理分布并不需要前向过程就可以得到和DDPM一样的优化目标。与DDPM一样,这里也是用神经网络
这里将生成过程分成三个部分:一是由预测的
这里考虑两种情况,一是
上面我们终于得到了DDIM模型,那么我们现在来看如何来加速生成过程。虽然DDIM和DDPM的训练过程一样,但是我们前面已经说了,DDIM并没有明确前向过程,这意味着我们可以定义一个更短的步数的前向过程。具体地,这里我们从原始的序列
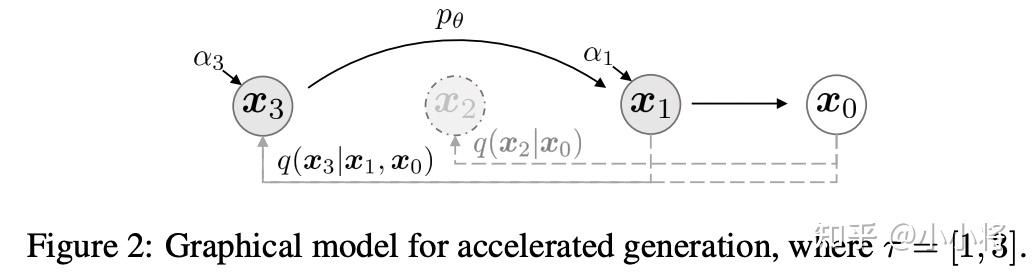
那么生成过程也可以用这个子序列的反向马尔卡夫链来替代,由于
其实上述的加速,我们是将前向过程按如下方式进行了分解:
其中
论文共设计了两种方法来采样子序列,分别是:
- Linear:采用线性的序列
; - Quadratic:采样二次方的序列
;
这里的
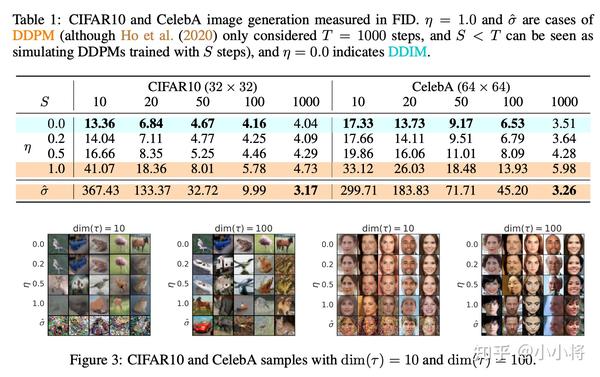
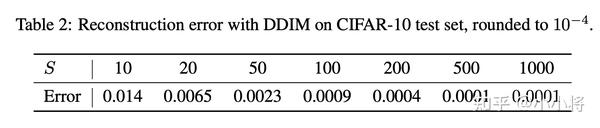
实验结果
下表为不同的
代码实现
DDIM和DDPM的训练过程一样,所以可以直接在DDPM的基础上加一个新的生成方法(这里主要参考了https://github.com/ermongroup/ddim (opens new window)以及https://github.com/huggingface/diffusers/blob/main/src/diffusers/schedulers/scheduling_ddim.py (opens new window)),具体代码如下所示:
class GaussianDiffusion:
def __init__(self, timesteps=1000, beta_schedule='linear'):
pass
# ...
# use ddim to sample
@torch.no_grad()
def ddim_sample(
self,
model,
image_size,
batch_size=8,
channels=3,
ddim_timesteps=50,
ddim_discr_method="uniform",
ddim_eta=0.0,
clip_denoised=True):
# make ddim timestep sequence
if ddim_discr_method == 'uniform':
c = self.timesteps // ddim_timesteps
ddim_timestep_seq = np.asarray(list(range(0, self.timesteps, c)))
elif ddim_discr_method == 'quad':
ddim_timestep_seq = (
(np.linspace(0, np.sqrt(self.timesteps * .8), ddim_timesteps)) ** 2
).astype(int)
else:
raise NotImplementedError(f'There is no ddim discretization method called "{ddim_discr_method}"')
# add one to get the final alpha values right (the ones from first scale to data during sampling)
ddim_timestep_seq = ddim_timestep_seq + 1
# previous sequence
ddim_timestep_prev_seq = np.append(np.array([0]), ddim_timestep_seq[:-1])
device = next(model.parameters()).device
# start from pure noise (for each example in the batch)
sample_img = torch.randn((batch_size, channels, image_size, image_size), device=device)
for i in tqdm(reversed(range(0, ddim_timesteps)), desc='sampling loop time step', total=ddim_timesteps):
t = torch.full((batch_size,), ddim_timestep_seq[i], device=device, dtype=torch.long)
prev_t = torch.full((batch_size,), ddim_timestep_prev_seq[i], device=device, dtype=torch.long)
# 1. get current and previous alpha_cumprod
alpha_cumprod_t = self._extract(self.alphas_cumprod, t, sample_img.shape)
alpha_cumprod_t_prev = self._extract(self.alphas_cumprod, prev_t, sample_img.shape)
# 2. predict noise using model
pred_noise = model(sample_img, t)
# 3. get the predicted x_0
pred_x0 = (sample_img - torch.sqrt((1. - alpha_cumprod_t)) * pred_noise) / torch.sqrt(alpha_cumprod_t)
if clip_denoised:
pred_x0 = torch.clamp(pred_x0, min=-1., max=1.)
# 4. compute variance: "sigma_t(η)" -> see formula (16)
# σ_t = sqrt((1 − α_t−1)/(1 − α_t)) * sqrt(1 − α_t/α_t−1)
sigmas_t = ddim_eta * torch.sqrt(
(1 - alpha_cumprod_t_prev) / (1 - alpha_cumprod_t) * (1 - alpha_cumprod_t / alpha_cumprod_t_prev))
# 5. compute "direction pointing to x_t" of formula (12)
pred_dir_xt = torch.sqrt(1 - alpha_cumprod_t_prev - sigmas_t**2) * pred_noise
# 6. compute x_{t-1} of formula (12)
x_prev = torch.sqrt(alpha_cumprod_t_prev) * pred_x0 + pred_dir_xt + sigmas_t * torch.randn_like(sample_img)
sample_img = x_prev
return sample_img.cpu().numpy()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
这里以MNIST数据集为例,训练的扩散步数为500,直接采用DDPM(即推理500次)生成的样本如下所示:

同样的模型,我们采用DDIM来加速生成过程,这里DDIM的采样步数为50,其生成的样本质量和500步的DDPM相当:

完整的代码示例见https://github.com/xiaohu2015/nngen (opens new window)。
其它:重建和插值
在DDIM论文中,还额外讨论了两个小点的内容**:重建和插值**。所谓重建是指的首先用原始图像求逆得到对应的噪音然后再进行生成的过程;而插值是指的对两个随机噪音进行插值从而得到融合两种噪音的图像。 首先是重建,对于DDIM,其
我们进一步对上述公式进行变换可得到:
当
这里令
看成ODE后,我们可以利用如下公式对生成过程进行逆操作:
这意味着,我们可以由一个原始图像
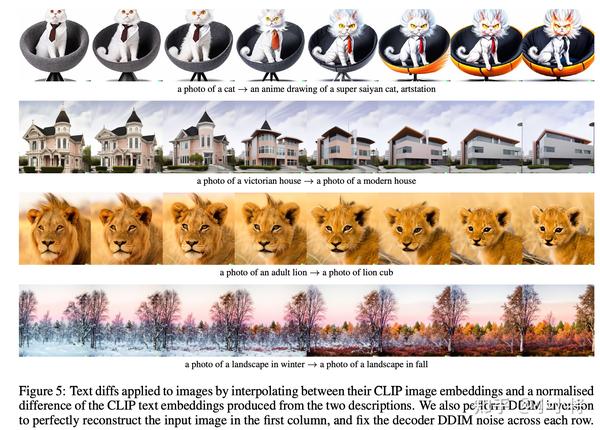
第二个插值,对于DDIM,两个不同的随机噪音会产生不同的图像,但是如果我们对这两个随机噪音进行插值生成新的
这里的参数

DDIM的重建和插值也在文本转图像模型DALLE-2中使用,不过这里插值的是扩散模型的条件CLIP image embedding,详情见论文**https://arxiv.org/abs/2204.06125 (opens new window)**。


小结
如果从直观上看,DDIM的加速方式非常简单,直接采样一个子序列,其实论文https://arxiv.org/abs/2102.09672 (opens new window)也采用了类似的方式来加速。另外DDIM和其它扩散模型的一个较大的区别是其生成过程是确定性的。
参考
- https://arxiv.org/abs/2010.02502 (opens new window)
- https://github.com/ermongroup/ddim (opens new window)
- https://github.com/openai/improved-diffusion (opens new window)
- https://github.com/huggingface/diffusers/blob/main/src/diffusers/schedulers/scheduling_ddim.py (opens new window)
- https://github.com/CompVis/latent-diffusion/blob/main/ldm/models/diffusion/ddim.py (opens new window)
- https://kexue.fm/archives/9181 (opens new window)