 DDPM
DDPM
说到生成模型,VAE (opens new window)、GAN (opens new window)可谓是“如雷贯耳”,本站也有过多次分享。此外,还有一些比较小众的选择,如flow模型 (opens new window)、VQ-VAE (opens new window)等,也颇有人气,尤其是VQ-VAE及其变体VQ-GAN (opens new window),近期已经逐渐发展到“图像的Tokenizer”的地位,用来直接调用NLP的各种预训练方法。除了这些之外,还有一个本来更小众的选择——扩散模型(Diffusion Models)——正在生成模型领域“异军突起”,当前最先进的两个文本生成图像——OpenAI的**DALL·E 2 (opens new window)和Google的Imagen (opens new window)**,都是基于扩散模型来完成的。

从本文开始,我们开一个新坑,逐渐介绍一下近两年关于生成扩散模型的一些进展。据说生成扩散模型以数学复杂闻名,似乎比VAE、GAN要难理解得多,是否真的如此?扩散模型真的做不到一个“大白话”的理解?让我们拭目以待。
新的起点
其实我们在之前的文章**《能量视角下的GAN模型(三):生成模型=能量模型》 (opens new window)、《从去噪自编码器到生成模型》 (opens new window)**也简单介绍过扩散模型。说到扩散模型,一般的文章都会提到能量模型(Energy-based Models)、得分匹配(Score Matching)、朗之万方程(Langevin Equation)等等,简单来说,是通过得分匹配等技术来训练能量模型,然后通过郎之万方程来执行从能量模型的采样。
从理论上来讲,这是一套很成熟的方案,原则上可以实现任何连续型对象(语音、图像等)的生成和采样。但从实践角度来看,能量函数的训练是一件很艰难的事情,尤其是数据维度比较大(比如高分辨率图像)时,很难训练出完备能量函数来;另一方面,通过朗之万方程从能量模型的采样也有很大的不确定性,得到的往往是带有噪声的采样结果。所以很长时间以来,这种传统路径的扩散模型只是在比较低分辨率的图像上做实验。
如今生成扩散模型的大火,则是始于2020年所提出的**DDPM (opens new window)**(Denoising Diffusion Probabilistic Model),虽然也用了“扩散模型”这个名字,但事实上除了采样过程的形式有一定的相似之外,DDPM与传统基于朗之万方程采样的扩散模型可以说完全不一样,这完全是一个新的起点、新的篇章。
准确来说,DDPM叫“渐变模型”更为准确一些,扩散模型这一名字反而容易造成理解上的误解,传统扩散模型的能量模型、得分匹配、朗之万方程等概念,其实跟DDPM及其后续变体都没什么关系。有意思的是,DDPM的数学框架其实在ICML2015的论文**《Deep Unsupervised Learning using Nonequilibrium Thermodynamics》 (opens new window)**就已经完成了,但DDPM是首次将它在高分辨率图像生成上调试出来了,从而引导出了后面的火热。由此可见,一个模型的诞生和流行,往往还需要时间和机遇,
拆楼建楼
很多文章在介绍DDPM时,上来就引入转移分布,接着就是变分推断,一堆数学记号下来,先吓跑了一群人(当然,从这种介绍我们可以再次看出,DDPM实际上是VAE而不是扩散模型),再加之人们对传统扩散模型的固有印象,所以就形成了“需要很高深的数学知识”的错觉。事实上,DDPM也可以有一种很“大白话”的理解,它并不比有着“造假-鉴别”通俗类比的GAN更难。
首先,我们想要做一个像GAN那样的生成模型,它实际上是将一个随机噪声

我们可以将这个过程想象为“建设”,其中随机噪声
这个过程肯定很难的,所以才有了那么多关于生成模型的研究。但俗话说“破坏容易建设难”,建楼你不会,拆楼你总会了吧?我们考虑将高楼大厦一步步地拆为砖瓦水泥的过程:设
建高楼大厦的难度在于,从原材料
该怎么拆
正所谓“饭要一口一口地吃”,楼也要一步一步地建,DDPM做生成模型的过程,其实跟上述“拆楼-建楼”的类比是完全一致的,它也是先反过来构建一个从数据样本渐变到随机噪声的过程,然后再考虑其逆变换,通过反复执行逆变换来完成数据样本的生成,所以本文前面才说DDPM这种做法其实应该更准确地称为“渐变模型”而不是“扩散模型”。
具体来说,DDPM将“拆楼”的过程建模为
其中有
反复执行这个拆楼的步骤,我们可以得到:
可能刚才读者就想问为什么叠加的系数要满足
所以实际上相当于有
这就为计算
又如何建
“拆楼”是
其实这已经非常接近最终的DDPM模型了,接下来让我们将这个过程做得更精细一些。首先“拆楼”的式
的形式,其中
前面的因子
得到损失函数的形式为
可能读者想问为什么要回退一步来给出
降低方差
原则上来说,损失函数
1、从所有训练样本中采样一个
; 2、从正态分布 采样 (两个不同的采样结果);
3、从采样一个 。
要采样的随机变量越多,就越难对损失函数做准确的估计,反过来说就是每次对损失函数进行估计的波动(方差)过大了。很幸运的是,我们可以通过一个积分技巧来将
这个积分确实有点技巧性,但也不算复杂。由于正态分布的叠加性,我们知道
接下来,我们反过来将
代入到式
注意到,现在损失函数关于
再次省掉常数和损失函数的权重,我们得到DDPM最终所用的损失函数:
(提示:原论文中的
递归生成
至此,我们算是把DDPM的整个训练流程捋清楚了。内容写了不少,你要说它很容易,那肯定说不上,但真要说非常困难的地方也几乎没有——没有用到传统的能量函数、得分匹配等工具,甚至连变分推断的知识都没有用到,只是借助“拆楼-建楼”的类比和一些基本的概率论知识,就能得到完全一样的结果。所以说,以DDPM为代表的新兴起的生成扩散模型,实际上没有很多读者想象的复杂,它可以说是我们从“拆解-重组”的过程中学习新知识的形象建模。
训练完之后,我们就可以从一个随机噪声
这对应于自回归解码中的Greedy Search。如果要进行Random Sample,那么需要补上噪声项:
一般来说,我们可以让
从这个生成过程中,我们也可以感觉到它其实跟Seq2Seq的解码过程是一样的,都是串联式的自回归生成,所以生成速度是一个瓶颈,DDPM设了
了解PixelRNN/PixelCNN的读者都知道,这类生成模型是逐个像素逐个像素地生成图片的,而自回归生成是有序的,这就意味着我们要提前给图片的每个像素排好顺序,最终的生成效果跟这个顺序紧密相关。然而,目前这个顺序只能是人为地凭着经验来设计(这类经验的设计都统称为“Inductive Bias”),暂时找不到理论最优解。换句话说,PixelRNN/PixelCNN的生成效果很受Inductive Bias的影响。但DDPM不一样,它通过“拆楼”的方式重新定义了一个自回归方向,而对于所有的像素来说则都是平权的、无偏的,所以减少了Inductive Bias的影响,从而提升了效果。此外,DDPM生成的迭代步数是固定的
超参设置
这一节我们讨论一下超参的设置问题。
在DDPM中,
这是一个单调递减的函数,那为什么要选择单调递减的
其实这两个问题有着相近的答案,跟具体的数据背景有关。简单起见,在重构的时候我们用了欧氏距离
选择单调递减的
代入
最后我们留意到,“建楼”模型中的
文章小结
本文从“拆楼-建楼”的通俗类比中介绍了最新的生成扩散模型DDPM,在这个视角中,我们可以通过较为“大白话”的描述以及比较少的数学推导,来得到跟原始论文一模一样的结果。总的来说,本文说明了DDPM也可以像GAN一样找到一个形象类比,它既可以不用到VAE中的“变分”,也可以不用到GAN中的“概率散度”、“最优传输”,从这个意义上来看,DDPM甚至算得上比VAE、GAN还要简单。
扩散模型原理
扩散模型包括两个过程**:前向过程(forward process)和反向过程(reverse process),其中前向过程又称为扩散过程(diffusion process),如下图所示。无论是前向过程还是反向过程都是一个参数化的马尔可夫链(Markov chain)**,其中反向过程可以用来生成数据,这里我们将通过变分推断来进行建模和求解。
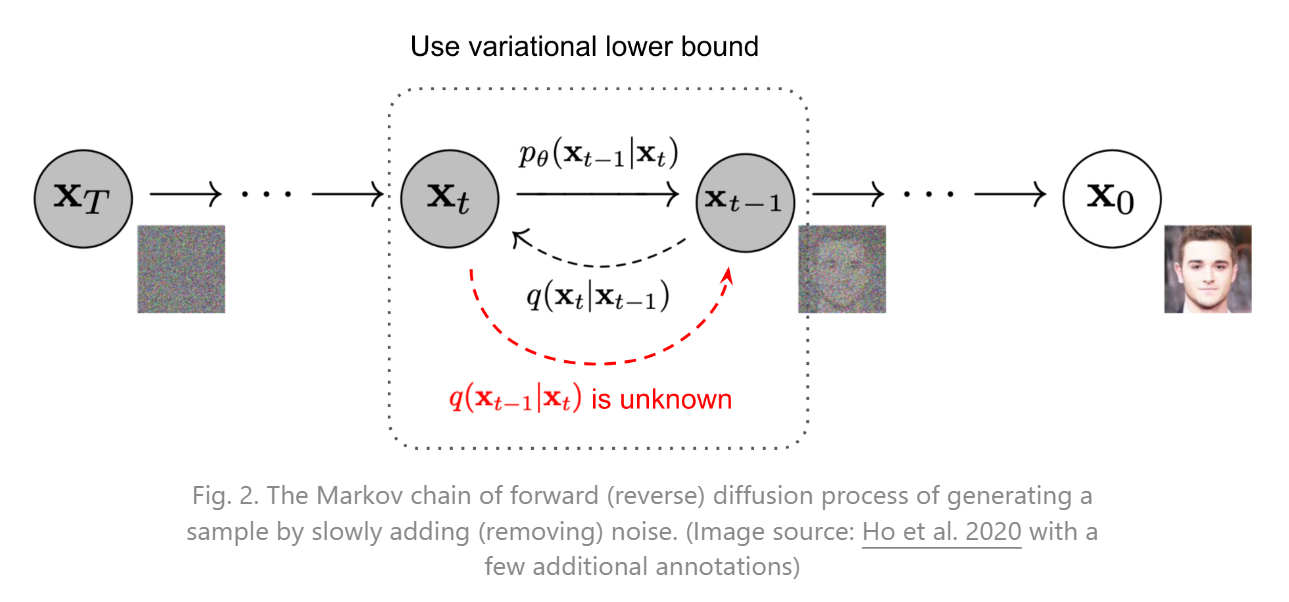
扩散过程
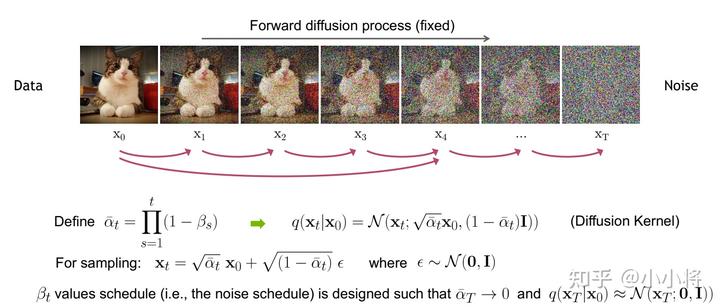
扩散过程是指的对数据逐渐增加高斯噪音直至数据变成随机噪音的过程。对于原始数据
这里

另外要指出的是,扩散过程往往是固定的,即采用一个预先定义好的variance schedule,比如DDPM就采用一个线性的variance schedule。
扩散过程的一个重要特性是我们可以直接基于原始数据
上述推到过程利用了两个方差不同的高斯分布
扩散过程的这个特性很重要。首先,我们可以看到signal_rate和noise_rate。更近一步地,我们可以基于
反向过程
扩散过程是将数据噪音化,那么反向过程就是一个去噪的过程,如果我们知道反向过程的每一步的真实分布

估计分布
这里
虽然分布
下面我们来具体推导这个分布,首先根据贝叶斯公式,我们有:
由于扩散过程的马尔卡夫链特性,我们知道分布
所以,我们有:
这里的
可以看到方差是一个定量(扩散过程参数固定),而均值是一个依赖
优化目标
上面介绍了扩散模型的扩散过程和反向过程,现在我们来从另外一个角度来看扩散模型:如果我们把中间产生的变量看成隐变量的话,那么扩散模型其实是包含
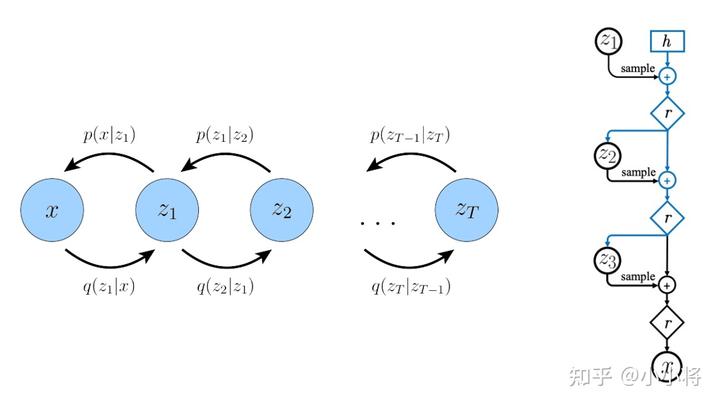
相比VAE来说,扩散模型的隐变量是和原始数据同维度的,而且encoder(即扩散过程)是固定的。既然扩散模型是隐变量模型,那么我们可以就可以基于变分推断来得到variational lower bound (opens new window)(VLB,又称ELBO)作为最大化优化目标,这里有:
这里最后一步是利用了Jensen's inequality (opens new window)(不采用这个不等式的推导见博客What are Diffusion Models? (opens new window)),对于网络训练来说,其训练目标为VLB取负:
我们近一步对训练目标进行分解可得:
可以看到最终的优化目标共包含
$p_{\theta}(\mathbf{x}0\vert\mathbf{x}1)=\prod^D{i=1}\int ^{\delta+(x_0^i)}{\delta-(x_0^i)}\mathcal{N}(x_0; \mu^i_\theta(x_1, 1), \Sigma^i_\theta(x_1, 1))dx\ \delta_+(x)= \begin{cases} \infty& \text{ if } x=1 \ x+\frac{1}{255}& \text{ if } x <1 \end{cases} \ \delta_+(x)= \begin{cases} -\infty& \text{ if } x=-1 \ x-\frac{1}{255}& \text{ if } x >-1 \end{cases} $
在DDPM中,会将原始图像的像素值从[0, 255]范围归一化到[-1, 1],像素值属于离散化值,这样不同的像素值之间的间隔其实就是2/255,我们可以计算高斯分布落在以ground truth为中心且范围大小为2/255时的概率积分即CDF,具体实现见https://github.com/hojonathanho/diffusion/blob/master/diffusion_tf/utils.py#L116-L133 (opens new window)(不过后面我们的简化版优化目标并不会计算这个对数似然)。
而
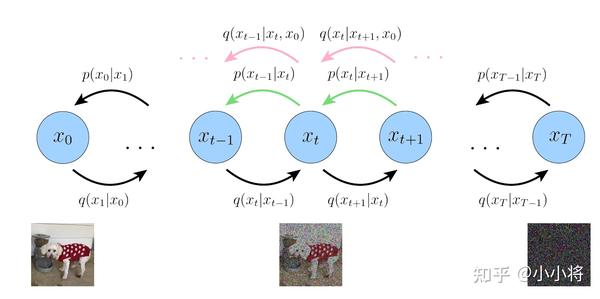
之所以前面我们将
对于两个高斯分布的KL散度,其计算公式为(具体推导见https://zhuanlan.zhihu.com/p/452743042 (opens new window)):
那么就有:
那么优化目标
从上述公式来看,我们是希望网络学习到的均值
将这个公式带入上述优化目标(注意这里的损失我们加上了对
近一步地,我们对
这里的
DDPM近一步对上述目标进行了简化,即去掉了权重系数,变成了:
这里的
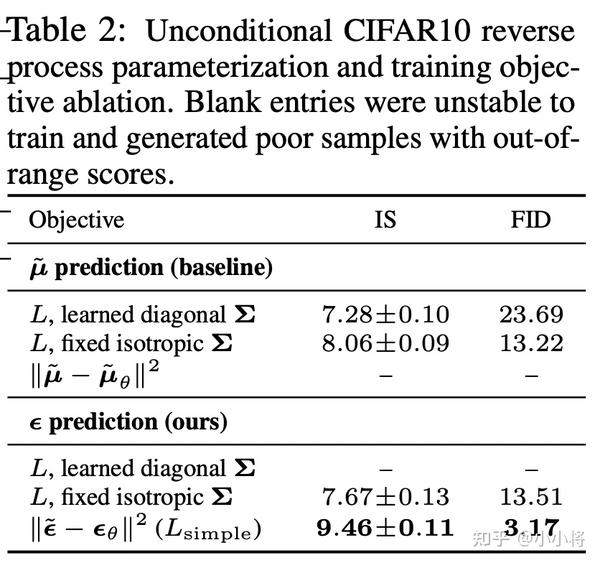
虽然扩散模型背后的推导比较复杂,但是我们最终得到的优化目标非常简单,就是让网络预测的噪音和真实的噪音一致。DDPM的训练过程也非常简单,如下图所示:随机选择一个训练样本->从1-T随机抽样一个t->随机产生噪音-计算当前所产生的带噪音数据(红色框所示)->输入网络预测噪音->计算产生的噪音和预测的噪音的L2损失->计算梯度并更新网络。

一旦训练完成,其采样过程也非常简单,如上所示:我们从一个随机噪音开始,并用训练好的网络预测噪音,然后计算条件分布的均值(红色框部分),然后用均值加标准差乘以一个随机噪音,直至t=0完成新样本的生成(最后一步不加噪音)。不过实际的代码实现和上述过程略有区别(见https://github.com/hojonathanho/diffusion/issues/5 (opens new window):先基于预测的噪音生成
模型设计
前面我们介绍了扩散模型的原理以及优化目标,那么扩散模型的核心就在于训练噪音预测模型,由于噪音和原始数据是同维度的,所以我们可以选择采用AutoEncoder架构来作为噪音预测模型。DDPM所采用的模型是一个基于residual block和attention block的U-Net模型。如下所示:
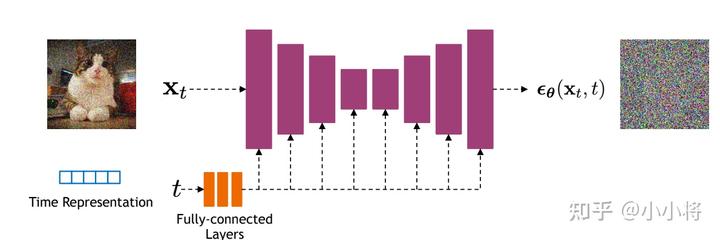
U-Net属于encoder-decoder架构,其中encoder分成不同的stages,每个stage都包含下采样模块来降低特征的空间大小(H和W),然后decoder和encoder相反,是将encoder压缩的特征逐渐恢复。U-Net在decoder模块中还引入了skip connection,即concat了encoder中间得到的同维度特征,这有利于网络优化。DDPM所采用的U-Net每个stage包含2个residual block,而且部分stage还加入了self-attention模块增加网络的全局建模能力。 另外,扩散模型其实需要的是
代码实现
最后,我们基于PyTorch框架给出DDPM的具体实现,这里主要参考了三套代码实现:
- https://github.com/hojonathanho/diffusion (opens new window)(官方TensorFlow实现)
- https://github.com/openai/improved-diffusion (opens new window) (OpenAI基于PyTorch实现的DDPM+)
- https://github.com/lucidrains/denoising-diffusion-pytorch (opens new window)
首先,是time embeding,这里是采用https://arxiv.org/abs/1706.03762 (opens new window)中所设计的sinusoidal position embedding,只不过是用来编码timestep:
# use sinusoidal position embedding to encode time step (https://arxiv.org/abs/1706.03762)
def timestep_embedding(timesteps, dim, max_period=10000):
"""
Create sinusoidal timestep embeddings.
:param timesteps: a 1-D Tensor of N indices, one per batch element.
These may be fractional.
:param dim: the dimension of the output.
:param max_period: controls the minimum frequency of the embeddings.
:return: an [N x dim] Tensor of positional embeddings.
"""
half = dim // 2
freqs = torch.exp(
-math.log(max_period) * torch.arange(start=0, end=half, dtype=torch.float32) / half
).to(device=timesteps.device)
args = timesteps[:, None].float() * freqs[None]
embedding = torch.cat([torch.cos(args), torch.sin(args)], dim=-1)
if dim % 2:
embedding = torch.cat([embedding, torch.zeros_like(embedding[:, :1])], dim=-1)
return embedding
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
由于只有residual block才引入time embedding,所以可以定义一些辅助模块来自动处理,如下所示:
# define TimestepEmbedSequential to support `time_emb` as extra input
class TimestepBlock(nn.Module):
"""
Any module where forward() takes timestep embeddings as a second argument.
"""
@abstractmethod
def forward(self, x, emb):
"""
Apply the module to `x` given `emb` timestep embeddings.
"""
class TimestepEmbedSequential(nn.Sequential, TimestepBlock):
"""
A sequential module that passes timestep embeddings to the children that
support it as an extra input.
"""
def forward(self, x, emb):
for layer in self:
if isinstance(layer, TimestepBlock):
x = layer(x, emb)
else:
x = layer(x)
return x
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
这里所采用的U-Net采用GroupNorm进行归一化,所以这里也简单定义了一个norm layer以方便使用:
# use GN for norm layer
def norm_layer(channels):
return nn.GroupNorm(32, channels)
2
3
U-Net的核心模块是residual block,它包含两个卷积层以及shortcut,同时也要引入time embedding,这里额外定义了一个linear层来将time embedding变换为和特征维度一致,第一conv之后通过加上time embedding来编码time:
# Residual block
class ResidualBlock(TimestepBlock):
def __init__(self, in_channels, out_channels, time_channels, dropout):
super().__init__()
self.conv1 = nn.Sequential(
norm_layer(in_channels),
nn.SiLU(),
nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1)
)
# pojection for time step embedding
self.time_emb = nn.Sequential(
nn.SiLU(),
nn.Linear(time_channels, out_channels)
)
self.conv2 = nn.Sequential(
norm_layer(out_channels),
nn.SiLU(),
nn.Dropout(p=dropout),
nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1)
)
if in_channels != out_channels:
self.shortcut = nn.Conv2d(in_channels, out_channels, kernel_size=1)
else:
self.shortcut = nn.Identity()
def forward(self, x, t):
"""
`x` has shape `[batch_size, in_dim, height, width]`
`t` has shape `[batch_size, time_dim]`
"""
h = self.conv1(x)
# Add time step embeddings
h += self.time_emb(t)[:, :, None, None]
h = self.conv2(h)
return h + self.shortcut(x)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
这里还在部分residual block引入了attention,这里的attention和transformer的self-attention是一致的:
# Attention block with shortcut
class AttentionBlock(nn.Module):
def __init__(self, channels, num_heads=1):
super().__init__()
self.num_heads = num_heads
assert channels % num_heads == 0
self.norm = norm_layer(channels)
self.qkv = nn.Conv2d(channels, channels * 3, kernel_size=1, bias=False)
self.proj = nn.Conv2d(channels, channels, kernel_size=1)
def forward(self, x):
B, C, H, W = x.shape
qkv = self.qkv(self.norm(x))
q, k, v = qkv.reshape(B*self.num_heads, -1, H*W).chunk(3, dim=1)
scale = 1. / math.sqrt(math.sqrt(C // self.num_heads))
attn = torch.einsum("bct,bcs->bts", q * scale, k * scale)
attn = attn.softmax(dim=-1)
h = torch.einsum("bts,bcs->bct", attn, v)
h = h.reshape(B, -1, H, W)
h = self.proj(h)
return h + x
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
对于上采样模块和下采样模块,其分别可以采用插值和stride=2的conv或者pooling来实现:
# upsample
class Upsample(nn.Module):
def __init__(self, channels, use_conv):
super().__init__()
self.use_conv = use_conv
if use_conv:
self.conv = nn.Conv2d(channels, channels, kernel_size=3, padding=1)
def forward(self, x):
x = F.interpolate(x, scale_factor=2, mode="nearest")
if self.use_conv:
x = self.conv(x)
return x
# downsample
class Downsample(nn.Module):
def __init__(self, channels, use_conv):
super().__init__()
self.use_conv = use_conv
if use_conv:
self.op = nn.Conv2d(channels, channels, kernel_size=3, stride=2, padding=1)
else:
self.op = nn.AvgPool2d(stride=2)
def forward(self, x):
return self.op(x)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
上面我们实现了U-Net的所有组件,就可以进行组合来实现U-Net了:
# The full UNet model with attention and timestep embedding
class UNetModel(nn.Module):
def __init__(
self,
in_channels=3,
model_channels=128,
out_channels=3,
num_res_blocks=2,
attention_resolutions=(8, 16),
dropout=0,
channel_mult=(1, 2, 2, 2),
conv_resample=True,
num_heads=4
):
super().__init__()
self.in_channels = in_channels
self.model_channels = model_channels
self.out_channels = out_channels
self.num_res_blocks = num_res_blocks
self.attention_resolutions = attention_resolutions
self.dropout = dropout
self.channel_mult = channel_mult
self.conv_resample = conv_resample
self.num_heads = num_heads
# time embedding
time_embed_dim = model_channels * 4
self.time_embed = nn.Sequential(
nn.Linear(model_channels, time_embed_dim),
nn.SiLU(),
nn.Linear(time_embed_dim, time_embed_dim),
)
# down blocks
self.down_blocks = nn.ModuleList([
TimestepEmbedSequential(nn.Conv2d(in_channels, model_channels, kernel_size=3, padding=1))
])
down_block_chans = [model_channels]
ch = model_channels
ds = 1
for level, mult in enumerate(channel_mult):
for _ in range(num_res_blocks):
layers = [
ResidualBlock(ch, mult * model_channels, time_embed_dim, dropout)
]
ch = mult * model_channels
if ds in attention_resolutions:
layers.append(AttentionBlock(ch, num_heads=num_heads))
self.down_blocks.append(TimestepEmbedSequential(*layers))
down_block_chans.append(ch)
if level != len(channel_mult) - 1: # don't use downsample for the last stage
self.down_blocks.append(TimestepEmbedSequential(Downsample(ch, conv_resample)))
down_block_chans.append(ch)
ds *= 2
# middle block
self.middle_block = TimestepEmbedSequential(
ResidualBlock(ch, ch, time_embed_dim, dropout),
AttentionBlock(ch, num_heads=num_heads),
ResidualBlock(ch, ch, time_embed_dim, dropout)
)
# up blocks
self.up_blocks = nn.ModuleList([])
for level, mult in list(enumerate(channel_mult))[::-1]:
for i in range(num_res_blocks + 1):
layers = [
ResidualBlock(
ch + down_block_chans.pop(),
model_channels * mult,
time_embed_dim,
dropout
)
]
ch = model_channels * mult
if ds in attention_resolutions:
layers.append(AttentionBlock(ch, num_heads=num_heads))
if level and i == num_res_blocks:
layers.append(Upsample(ch, conv_resample))
ds //= 2
self.up_blocks.append(TimestepEmbedSequential(*layers))
self.out = nn.Sequential(
norm_layer(ch),
nn.SiLU(),
nn.Conv2d(model_channels, out_channels, kernel_size=3, padding=1),
)
def forward(self, x, timesteps):
"""
Apply the model to an input batch.
:param x: an [N x C x H x W] Tensor of inputs.
:param timesteps: a 1-D batch of timesteps.
:return: an [N x C x ...] Tensor of outputs.
"""
hs = []
# time step embedding
emb = self.time_embed(timestep_embedding(timesteps, self.model_channels))
# down stage
h = x
for module in self.down_blocks:
h = module(h, emb)
hs.append(h)
# middle stage
h = self.middle_block(h, emb)
# up stage
for module in self.up_blocks:
cat_in = torch.cat([h, hs.pop()], dim=1)
h = module(cat_in, emb)
return self.out(h)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
对于扩散过程,其主要的参数就是timesteps和noise schedule,DDPM采用范围为[0.0001, 0.02]的线性noise schedule,其默认采用的总扩散步数为1000。
# beta schedule
def linear_beta_schedule(timesteps):
scale = 1000 / timesteps
beta_start = scale * 0.0001
beta_end = scale * 0.02
return torch.linspace(beta_start, beta_end, timesteps, dtype=torch.float64)
2
3
4
5
6
我们定义个扩散模型,它主要要提前根据设计的noise schedule来计算一些系数,并实现一些扩散过程和生成过程:
class GaussianDiffusion:
def __init__(
self,
timesteps=1000,
beta_schedule='linear'
):
self.timesteps = timesteps
if beta_schedule == 'linear':
betas = linear_beta_schedule(timesteps)
elif beta_schedule == 'cosine':
betas = cosine_beta_schedule(timesteps)
else:
raise ValueError(f'unknown beta schedule {beta_schedule}')
self.betas = betas
self.alphas = 1. - self.betas
self.alphas_cumprod = torch.cumprod(self.alphas, axis=0)
self.alphas_cumprod_prev = F.pad(self.alphas_cumprod[:-1], (1, 0), value=1.)
# calculations for diffusion q(x_t | x_{t-1}) and others
self.sqrt_alphas_cumprod = torch.sqrt(self.alphas_cumprod)
self.sqrt_one_minus_alphas_cumprod = torch.sqrt(1.0 - self.alphas_cumprod)
self.log_one_minus_alphas_cumprod = torch.log(1.0 - self.alphas_cumprod)
self.sqrt_recip_alphas_cumprod = torch.sqrt(1.0 / self.alphas_cumprod)
self.sqrt_recipm1_alphas_cumprod = torch.sqrt(1.0 / self.alphas_cumprod - 1)
# calculations for posterior q(x_{t-1} | x_t, x_0)
self.posterior_variance = (
self.betas * (1.0 - self.alphas_cumprod_prev) / (1.0 - self.alphas_cumprod)
)
# below: log calculation clipped because the posterior variance is 0 at the beginning
# of the diffusion chain
self.posterior_log_variance_clipped = torch.log(self.posterior_variance.clamp(min =1e-20))
self.posterior_mean_coef1 = (
self.betas * torch.sqrt(self.alphas_cumprod_prev) / (1.0 - self.alphas_cumprod)
)
self.posterior_mean_coef2 = (
(1.0 - self.alphas_cumprod_prev)
* torch.sqrt(self.alphas)
/ (1.0 - self.alphas_cumprod)
)
# get the param of given timestep t
def _extract(self, a, t, x_shape):
batch_size = t.shape[0]
out = a.to(t.device).gather(0, t).float()
out = out.reshape(batch_size, *((1,) * (len(x_shape) - 1)))
return out
# forward diffusion (using the nice property): q(x_t | x_0)
def q_sample(self, x_start, t, noise=None):
if noise is None:
noise = torch.randn_like(x_start)
sqrt_alphas_cumprod_t = self._extract(self.sqrt_alphas_cumprod, t, x_start.shape)
sqrt_one_minus_alphas_cumprod_t = self._extract(self.sqrt_one_minus_alphas_cumprod, t, x_start.shape)
return sqrt_alphas_cumprod_t * x_start + sqrt_one_minus_alphas_cumprod_t * noise
# Get the mean and variance of q(x_t | x_0).
def q_mean_variance(self, x_start, t):
mean = self._extract(self.sqrt_alphas_cumprod, t, x_start.shape) * x_start
variance = self._extract(1.0 - self.alphas_cumprod, t, x_start.shape)
log_variance = self._extract(self.log_one_minus_alphas_cumprod, t, x_start.shape)
return mean, variance, log_variance
# Compute the mean and variance of the diffusion posterior: q(x_{t-1} | x_t, x_0)
def q_posterior_mean_variance(self, x_start, x_t, t):
posterior_mean = (
self._extract(self.posterior_mean_coef1, t, x_t.shape) * x_start
+ self._extract(self.posterior_mean_coef2, t, x_t.shape) * x_t
)
posterior_variance = self._extract(self.posterior_variance, t, x_t.shape)
posterior_log_variance_clipped = self._extract(self.posterior_log_variance_clipped, t, x_t.shape)
return posterior_mean, posterior_variance, posterior_log_variance_clipped
# compute x_0 from x_t and pred noise: the reverse of `q_sample`
def predict_start_from_noise(self, x_t, t, noise):
return (
self._extract(self.sqrt_recip_alphas_cumprod, t, x_t.shape) * x_t -
self._extract(self.sqrt_recipm1_alphas_cumprod, t, x_t.shape) * noise
)
# compute predicted mean and variance of p(x_{t-1} | x_t)
def p_mean_variance(self, model, x_t, t, clip_denoised=True):
# predict noise using model
pred_noise = model(x_t, t)
# get the predicted x_0: different from the algorithm2 in the paper
x_recon = self.predict_start_from_noise(x_t, t, pred_noise)
if clip_denoised:
x_recon = torch.clamp(x_recon, min=-1., max=1.)
model_mean, posterior_variance, posterior_log_variance = \
self.q_posterior_mean_variance(x_recon, x_t, t)
return model_mean, posterior_variance, posterior_log_variance
# denoise_step: sample x_{t-1} from x_t and pred_noise
@torch.no_grad()
def p_sample(self, model, x_t, t, clip_denoised=True):
# predict mean and variance
model_mean, _, model_log_variance = self.p_mean_variance(model, x_t, t,
clip_denoised=clip_denoised)
noise = torch.randn_like(x_t)
# no noise when t == 0
nonzero_mask = ((t != 0).float().view(-1, *([1] * (len(x_t.shape) - 1))))
# compute x_{t-1}
pred_img = model_mean + nonzero_mask * (0.5 * model_log_variance).exp() * noise
return pred_img
# denoise: reverse diffusion
@torch.no_grad()
def p_sample_loop(self, model, shape):
batch_size = shape[0]
device = next(model.parameters()).device
# start from pure noise (for each example in the batch)
img = torch.randn(shape, device=device)
imgs = []
for i in tqdm(reversed(range(0, timesteps)), desc='sampling loop time step', total=timesteps):
img = self.p_sample(model, img, torch.full((batch_size,), i, device=device, dtype=torch.long))
imgs.append(img.cpu().numpy())
return imgs
# sample new images
@torch.no_grad()
def sample(self, model, image_size, batch_size=8, channels=3):
return self.p_sample_loop(model, shape=(batch_size, channels, image_size, image_size))
# compute train losses
def train_losses(self, model, x_start, t):
# generate random noise
noise = torch.randn_like(x_start)
# get x_t
x_noisy = self.q_sample(x_start, t, noise=noise)
predicted_noise = model(x_noisy, t)
loss = F.mse_loss(noise, predicted_noise)
return loss
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
其中几个主要的函数总结如下:
q_sample:实现的从散过程; q_posterior_mean_variance:实现的是后验分布的均值和方差的计算公式;predict_start_from_noise:q_sample的逆过程,根据预测的噪音来生成; p_mean_variance:根据预测的噪音来计算均值和方差; p_sample:单个去噪step;p_sample_loop:整个去噪音过程,即生成过程。
扩散模型的训练过程非常简单,如下所示:
# train
epochs = 10
for epoch in range(epochs):
for step, (images, labels) in enumerate(train_loader):
optimizer.zero_grad()
batch_size = images.shape[0]
images = images.to(device)
# sample t uniformally for every example in the batch
t = torch.randint(0, timesteps, (batch_size,), device=device).long()
loss = gaussian_diffusion.train_losses(model, images, t)
if step % 200 == 0:
print("Loss:", loss.item())
loss.backward()
optimizer.step()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
这里我们以mnist数据简单实现了一个https://github.com/xiaohu2015/nngen/blob/main/models/diffusion_models/ddpm_mnist.ipynb (opens new window),下面是一些生成的样本:

对生成过程进行采样,如下所示展示了如何从一个随机噪音生成一个手写字体图像:

另外这里也提供了CIFAR10数据集的demo:https://github.com/xiaohu2015/nngen/blob/main/models/diffusion_models/ddpm_cifar10.ipynb (opens new window),不过只训练了200epochs,生成的图像只是初见成效。

小结
相比VAE和GAN,扩散模型的理论更复杂一些,不过其优化目标和具体实现却并不复杂,这其实也让人感叹**:一堆复杂的数据推导,最终却得到了一个简单的结论**。要深入理解扩散模型,DDPM只是起点,后面还有比较多的改进工作,比如加速采样的https://arxiv.org/abs/2010.02502 (opens new window)以及DDPM的改进版本https://arxiv.org/abs/2102.09672 (opens new window)和https://arxiv.org/abs/2105.05233 (opens new window)。
这篇文章特别参考了OpenAI研究员的博客https://lilianweng.github.io/posts/2021-07-11-diffusion-models/ (opens new window)(部分公式在此基础上进行加工修改)以及谷歌研究员的论文https://arxiv.org/abs/2208.11970 (opens new window)。**
注:本人水平有限,如有谬误,欢迎讨论交流。
参考
- 扩散模型之DDPM (opens new window)
- https://arxiv.org/abs/2006.11239 (opens new window)
- https://arxiv.org/abs/2208.11970 (opens new window)
- https://spaces.ac.cn/archives/9119/comment-page-1 (opens new window)
- https://keras.io/examples/generative/ddim/ (opens new window)
- https://lilianweng.github.io/posts/2021-07-11-diffusion-models/ (opens new window)
- https://cvpr2022-tutorial-diffusion-models.github.io/ (opens new window)
- https://github.com/openai/improved-diffusion (opens new window)
- https://huggingface.co/blog/annotated-diffusion (opens new window)
- https://github.com/lucidrains/denoising-diffusion-pytorch (opens new window)
- https://github.com/hojonathanho/diffusion (opens new window)