 随机变量及其分布
随机变量及其分布
随机变量及其分布
随机变量的概念
- 随机变量(Random variable) :值随机会而定的变量,研究随机试验的一串事件。可按维数分为一维、二维至多维随机变量。按性质可分为离散型随机变量以及连续型随机变量。
- 分布(Distribution) :事件之间的联系,用来计算概率。
- 示性函数(Indication function) :
,事件 随机变量 示出来, 为事件 示性函数。
离散型随机变量及其分布
离散型随机变量 :设
一随机变量,如果 只取有限个或可数个值,则称 一个(一维)离散型随机变量。 概率函数 :设
一随机变量,其全部可能值为 ,则 为 概率函数。 概率分布 :离散型随机变量的概率分布可以用分布表来表示:
可能值 ... ... 概率 ... ... 概率分布函数 :
- 定义 :设
一随机变量,则函数
- 定义 :设
称为
性质 :
,有 . - 当
, ;当 , .
离散型随机变量分布函数 :
对于离散型随机变量,
。
二项分布(Bionomial distribution):
定义 :设某事件
一次试验中发生的概率为 ,先把试验独立地重复n次,以 这n次试验中发生的次数,则 值 ,且有 称
从二项分布,记为 . 服从二项分布的条件 :1. 各次试验的条件是稳定的,即事件
概率 各次试验中保持不变;2. 各次试验的独立性
泊松分布(Poisson distribution) :
定义 :设随机变量
概率分布为 则称
从参数为 Poisson分布,并记 . 特点 :
描述稀有事件发生概率
作为二项分布的近似。若
,其中 大, 小,而 太大时(一般 ),则 分布接近泊松分布 . 推导 :
若事件
,且 大, 小,而 太大时,设 ,
连续型随机变量及其分布
连续型随机变量 :设
一随机变量,如果 不仅有无限个而且有不可数个值,则称 一个连续型随机变量。 概率密度函数 :
定义 :设连续型随机变量
概率分布函数 ,则 导数 为 概率密度函数。 性质 :
- 对于所有的
,有 ; ; - 对于任意的
,有 .
- 对于所有的
注 :
- 对于任意的
,有 . - 假设有总共一个单位的质量连续地分布在
,那么 示在点 质量密度且 示在区间 的全部质量。
- 对于任意的
概率分布函数 :设
一连续型随机变量,则 正态分布(Normal distribution) :
定义 :如果一个随机变量具有概率密度函数
其中
,则称 正态随机变量,并记为 .特别地, 正态分布成为标准正态分布。用 示标准正态分布 分布函数和密度函数。 性质 :
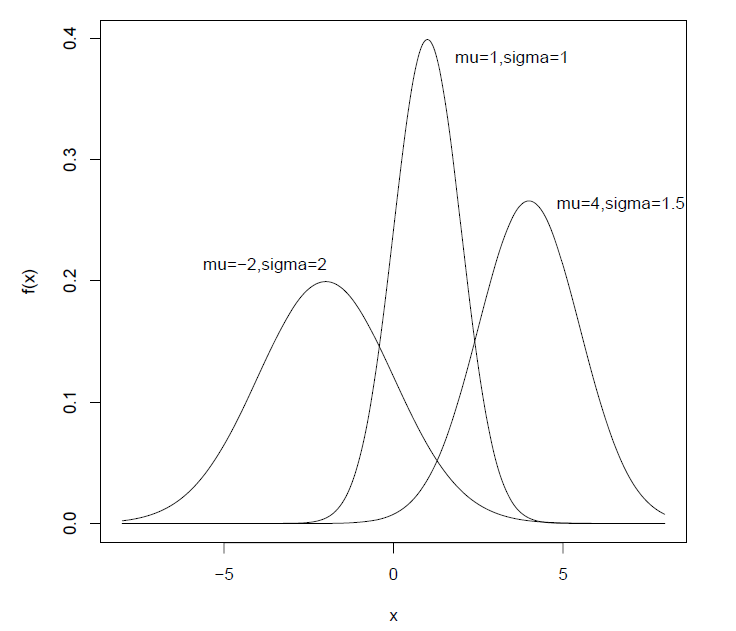
- 正态分布的密度函数是以
对称轴的对称函数, 为位置参数,密度函数在 达到最大值,在 严格单调。 大小决定了密度函数的陡峭程度,通常称 正态分布的形状参数。 - 若
,则 .
- 正态分布的密度函数是以
图像(密度和分布函数图) :
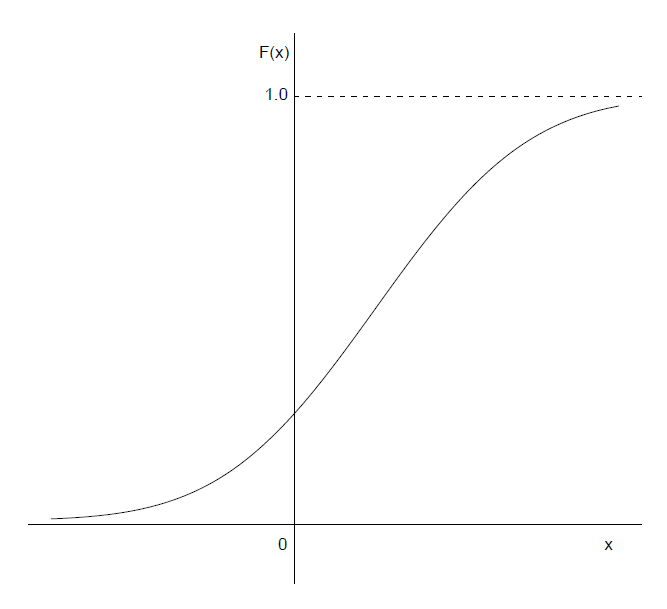
指数分布(Exponential distribution) :
定义 :若随机变量
有概率密度函数 其中
常数,则称 从参数为 指数分布。 概率分布函数 :
性质 :
无后效性,即无老化,要来描述寿命(如元件等)的分布。
证明 :
“无老化”就是说在时刻
常工作的条件下,其失效率总保持为某个常数 ,与 关,可表示 失效率,失效率越高,平均寿命就越小。
图像(密度函数) :
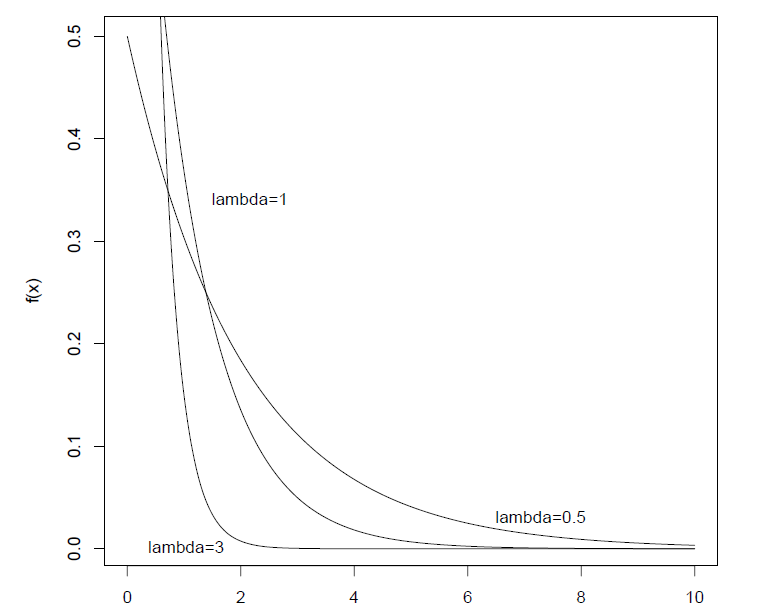
均匀分布(Uniform distribution) :
定义 :设
,如果分布 有密度函数 则该分布为区间
的均匀分布。 概率分布函数 :
性质 :
多维随机变量(随机向量)
随机向量 :设
.如果每个 是一个随机变量, ,则称 随机变量或者随机向量。 离散型随机向量的分布 :如果每一个
是一个离散型随机变量, ,则称 一 离散型随机变量。设 所有可能取值为 ,则称 为
随机变量 概率函数,这也是其联合分布。 其具有下列性质:
注 :对于高维离散型随机变量,一般不使用分布函数
多项式分布
定义 :设
某一试验之下的完备事件群,分别以 事件 概率,则 .将试验独立地重复 ,以 在这 试验中事件 现的次数 ,则 一个 随机向量。该分布记作 . 概率分布函数 :
连续型随机向量的分布 :
连续型随机变量,如果存在 的非负函数 ,使得对任意的 ,有 则称为
概率密度函数。有 则称为
(联合)分布函数。其中分布函数 有下述性质: 调非降; - 对任意的
,有 ;
边缘分布 :因为
每个分量 是一维随机变量,故它们都有各自的分布 ,这些都是一维分布,称为随机向量 其分布 边缘分布。 离散型随机向量

行和与列和就是边缘分布。即固定某个
,即可计算边缘分布,故有 连续型随机向量
为求某分量
概率密度函数,只需把 的 定,然后对 间做定积分,如
注 :二维正态分布
边缘分布密度分别是一维正态分布 。因此联合分布可推边缘分布,而边缘分布不可推联合分布。
条件分布和随机变量的独立性
离散型随机变量的条件分布 :设
二维离散型随机变量,对于给定的事件 ,其概率 ,则称 为在给定
条件下 条件分布律。类似的,称 为在给定
条件下 条件分布律。 连续型随机变量的条件分布 :设
二维连续型随机变量,对于给定条件 的条件概率密度为 类似的,在
的条件概率密度为 二维正态分布
,其联合密度分布等于条件密度分布的乘积。 随机变量的独立性
称随机变量
互独立, 离散型随机变量
则联合分布律等于各自的边缘分布律的乘积,即
其中
值域中的任意一点。 连续型随机变量
则联合密度等于各自的边缘密度的乘积,即
更具一般地
设
随机变量,如果它们的联合分布函数等于各自边缘分布函数的乘积,即 则称随机变量
互独立。
一些重要的结论

随机变量的函数的概率分布
最简单的情形,是由一维随机变量
离散型分布的情形 :设
分布律为 ,令 ,则 分布律为 即把
以取的不同值找出来,把与某个值相应的全部 的概率加起来,即得 这个值的概率。 连续型分布的情形
一个变量的情况
设
密度函数 .设 , 一个严格单调的函数,即当 ,必有 当 ,必有 .又设 导数 在。由于 严格单调性,其反函数 在,且 导数 存在。有 密度函数 多个变量的情形
以两个为例,设
密度函数 , 是 函数: 要求
概率密度函数 .假定 一一对应变换有逆变换: 即雅可比行列式
不为0.在
平面上任取一个区域 ,变换后到 面的区域 ,则有 随机变量和的密度函数
设
联合密度函数为 , 密度函数: - 一般的,
. - 若
立,则 .
两个独立的正态变量的和仍服从正态分布,且有关的参数相加,其逆命题也成立。
- 一般的,
随机变量商的密度函数 设
联合密度函数为 , 密度函数: - 一般的,
. - 若
立,则 .
- 一般的,
统计学三大分布
引入两个重要的特殊函数:
和 其中,
卡方分布,记作
密度函数 :
性质 :1. 设
立, ,则 2. 若
立,且都服从指数分布,则 布,记作 设
立, ,而 ,则 . 密度函数 :
性质 :密度函数关于原点对称,其图形与正态分布
密度函数的图形相似。 布,记作 设
立, ,而 ,则 密度函数 :
三大分布的几个重要性质
设
立同分布,有公共的正态分布 .记 .则 . 设
假定同1,则 设
立, 有分布 , 有分布 ,则 若
,则