 DER
DER
DER: Dynamically Expandable Representation for Class Incremental Learning](https://arxiv.org/abs/2103.16788) | CVPR 2021 | Code (opens new window)
0. 摘要
我们解决了类别增量学习的问题,这是实现自适应视觉智能的核心步骤。特别是,我们考虑了在有限内存下的增量学习任务设置,旨在实现更好的稳定性与可塑性之间的权衡。为此,我们提出了一种新颖的两阶段学习方法,利用动态可扩展的表示来更有效地建模增量概念。具体来说,在每个增量步骤中,我们冻结先前学习到的表示,并通过一个新的可学习特征提取器增加额外的特征维度。这使我们能够在保留已学知识的同时整合新的视觉概念。我们通过引入基于通道级掩码的剪枝策略,根据新概念的复杂性动态扩展表示。此外,我们引入了一个辅助损失,以鼓励模型学习新颖概念的多样化和区分性特征。我们在三个类别增量学习基准上进行了广泛的实验,我们的方法始终以较大优势超越其他方法。
1. 引言
人类可以轻松地从过去的经验中积累视觉知识,并逐步学习新的概念。受此启发,类别增量学习问题旨在设计能够以顺序方式学习新概念并最终在所有观察到的类别上表现良好的算法。这种能力对于许多现实世界的应用(如智能机器人、人脸识别和自动驾驶)是不可或缺的。然而,实现人类水平的增量学习对于现代视觉识别系统仍然具有挑战性。
在文献中,已有许多尝试解决增量学习问题的努力。其中,最有效的策略可能是保持一个内存缓冲区,存储部分观察到的数据以供未来复习。然而,由于数据内存的有限性,这种增量学习方法在一般的持续学习任务中仍然面临几个典型的挑战。特别是,它要求模型能够有效地整合新概念而不忘记现有知识,这被称为稳定性与可塑性之间的困境。具体来说,过度的可塑性通常会导致旧类别的大幅性能下降,称为灾难性遗忘。相反,过度的稳定性会阻碍新概念的适应。
现有的大多数工作试图通过逐步更新数据表示和类别决策边界来实现稳定性与可塑性之间的权衡。例如,正则化方法惩罚先前学习模型的重要权重的变化,而知识蒸馏则通过可用数据保留网络输出,基于结构的方法在为新类别分配更多参数时保持旧参数不变。然而,这些方法要么牺牲了模型的可塑性以换取稳定性,要么由于旧概念的特征退化而容易遗忘。如图1所示,在所有数据上训练的模型(Joint)与先前的最先进模型之间仍然存在较大的性能差距。
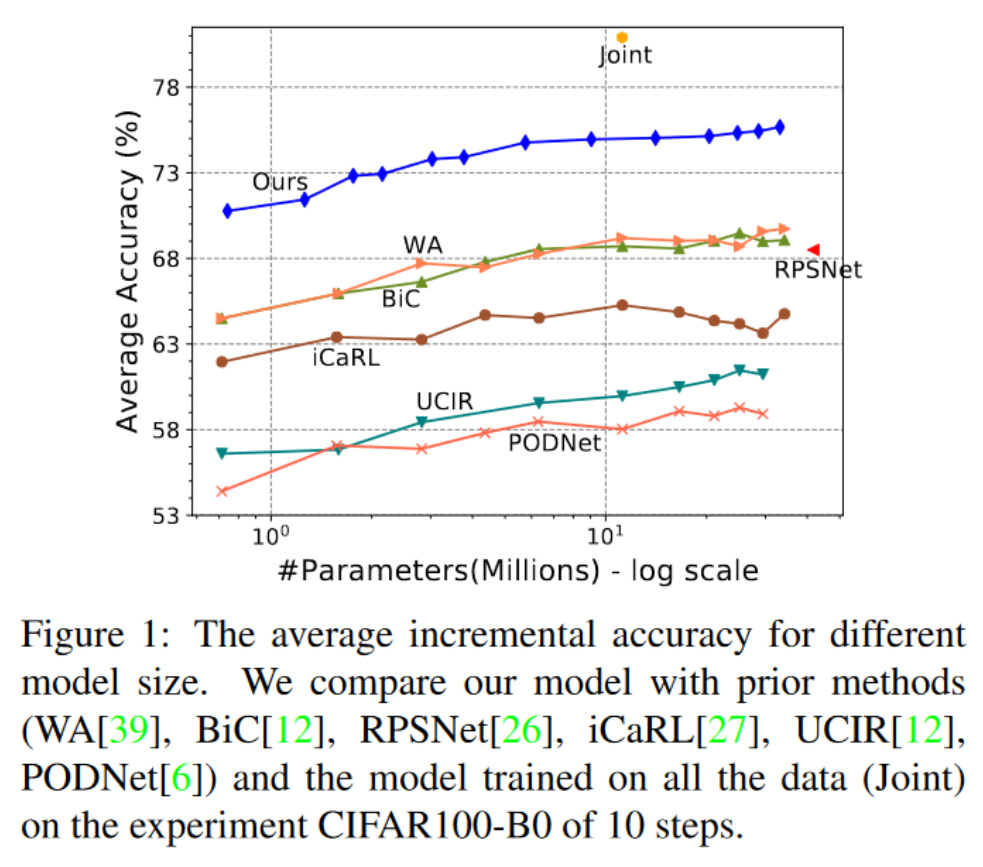
在本工作中,我们旨在解决上述弱点,并在类别增量学习中实现更好的稳定性与可塑性之间的权衡。为此,我们采用了两阶段学习策略,将特征表示的适应与深度网络的最终分类器头(简称分类器)解耦。在这个框架内,我们提出了一种新颖的数据表示,称为超级特征,能够增加其维度以适应新类别。我们的主要思想是冻结先前学习到的表示,并在每个增量步骤中通过一个新的可学习提取器增加额外的特征维度。这使得我们能够保留现有知识,并提供足够的灵活性来学习新概念。此外,我们的超级特征根据新概念的复杂性动态扩展,以保持紧凑的表示。
为了实现这一点,我们开发了一个模块化的深度分类网络,由超级特征提取器网络和线性分类器组成。我们的超级特征提取器网络由多个不同大小的特征提取器组成,每个增量步骤一个。具体来说,在新的步骤中,我们通过一个新的特征提取器扩展超级特征提取器网络,同时保持先前提取器的参数冻结。所有提取器生成的特征被连接在一起,并输入到分类器中进行类别预测。
我们在memory和新数据上训练新的特征提取器和分类器。为了鼓励新的提取器学习新类别的多样化和区分性特征,我们设计了一个辅助损失来区分新旧类别。此外,为了去除模型冗余并学习新类别的紧凑特征,我们应用了基于通道级掩码的可微分剪枝方法,根据新概念的难度动态剪枝网络。最后,在更新表示后,我们冻结超级特征提取器,并在平衡的训练子集上微调分类器,以解决类别不平衡问题。
我们在三个常用的基准(包括CIFAR-100、ImageNet-100和ImageNet-1000数据集)上验证了我们的方法。实验结果和消融研究表明,我们的方法优于先前的最先进方法。有趣的是,我们还发现我们的方法可以在步骤之间实现正向和反向迁移。我们的主要贡献有三点:
- 为了实现更好的稳定性与可塑性之间的权衡,我们开发了动态可扩展的表示和两阶段策略用于类别增量学习。
- 我们提出了一个辅助损失,以促进新添加的特征模块有效学习新类别,并提出了模型剪枝步骤以学习紧凑特征。
- 我们的方法在所有三个基准上实现了新的最先进性能,模型复杂度范围广泛,如图1所示。
2. 相关工作
类别增量学习旨在连续学习新类别。一些工作尝试在没有访问先前数据的情况下解决问题。然而,主流的方法是基于有限数据内存的复习策略,可以从表示学习和分类器学习两个主要方面进行分析。
表示学习:当前的工作主要分为以下三类。基于正则化的方法采用最大后验估计,期望重要参数发生小的变化,并顺序更新模型参数的后验。然而,其复杂的计算通常需要基于强模型假设的近似。例如,EWC使用拉普拉斯近似,假设权重落在上一步最优权重的局部区域内。这严重限制了模型适应新概念的能力。基于蒸馏的方法使用知识蒸馏来保留表示。iCaRL和EE2L在网络的输出上计算蒸馏损失。UCIR使用归一化的特征向量来应用蒸馏损失,而不是网络的预测。PODNet使用基于空间的蒸馏损失来限制模型的变化。TPCIL使模型保留CNN特征空间的拓扑结构。知识蒸馏的性能取决于保存数据的质量和数量。基于结构的方法保持与先前类别相关的学习参数不变,并以不同形式(如未使用的参数、额外的网络)分配新参数以学习新知识。CPG提出了一种压缩和选择/扩展机制,通过选择性权重共享交替剪枝深度模型并扩展架构。然而,大多数基于结构的方法是为任务持续学习设计的,需要在推理时知道任务身份。对于类别增量学习,RPSNet提出了一种随机路径选择算法,逐步选择最优路径作为新类别的子网络。CCGN为每个卷积层配备了任务特定的门控模块,以选择应用于给定输入的过滤器,并使用任务预测器在推理时选择门控模块。
分类器学习:由于内存有限,类别不平衡问题是分类器学习的主要挑战。一些工作(如LWF.MC、RWalk)在一阶段训练中联合训练提取器和分类器。相比之下,最近有许多工作通过在表示学习后引入独立的分类器学习阶段来解决类别不平衡问题。EEIL在平衡的训练子集上微调分类器。BiC添加了一个偏差校正层来校正模型的输出,该层在单独的验证集上训练。WA通过对齐新旧类别的权重向量的范数来校正偏差权重。
讨论:我们的工作是基于结构的方法,与我们的工作最相似的是RPSNet和CCGN。RPSNet无法保留每个旧概念的内在结构,并且通过在每个ConvNet阶段将先前学习的特征与新学习的特征相加,逐渐忘记已学概念。在CCGN中,由于只有部分层的参数被冻结,学习到的表示可能会逐渐退化。相比之下,我们保持先前学习到的表示不变,并通过新的特征提取器参数化的新特征来增强它。这使得我们能够在先前学习到的表示的子空间中保留旧概念的内在结构,并通过最终分类器重用该结构以减轻遗忘。
3. 方法
在本节中,我们提出了解决类别增量学习问题的方法,旨在实现更好的稳定性与可塑性之间的权衡。为此,我们提出了动态可扩展的表示(DER),逐步用新特征增强先前学习到的表示,并提出了一种两阶段学习策略。
下面我们首先在第3.1节中介绍类别增量学习的问题设置和我们方法的概述。然后我们在第3.2节中介绍可扩展表示学习及其损失函数。接着,我们在第3.3节中描述表示的动态扩展,并在第3.4节中介绍分类器学习的第二阶段。
3.1. 问题设置与方法概述
首先,我们介绍类别增量学习的问题设置。与任务增量学习不同,类别增量学习在推理时不需要任务ID。具体来说,在类别增量学习中,模型观察到一系列类别组
我们的方法采用复习策略,将部分数据保存为内存
表示学习阶段:为了在稳定性与可塑性之间实现更好的权衡,我们固定先前的特征表示,并通过一个新的特征提取器在输入数据和内存数据上进行训练来扩展它。我们设计了一个辅助损失来促进新提取器学习多样化和区分性特征。为了提高模型效率,我们通过引入基于通道级掩码的剪枝方法,根据新类别的复杂性动态扩展表示。我们提出的表示的概述如图2所示。
分类器学习阶段:在表示学习之后,我们使用当前可用的数据
第 重新训练分类器,以通过采用平衡微调方法解决类别不平衡问题。
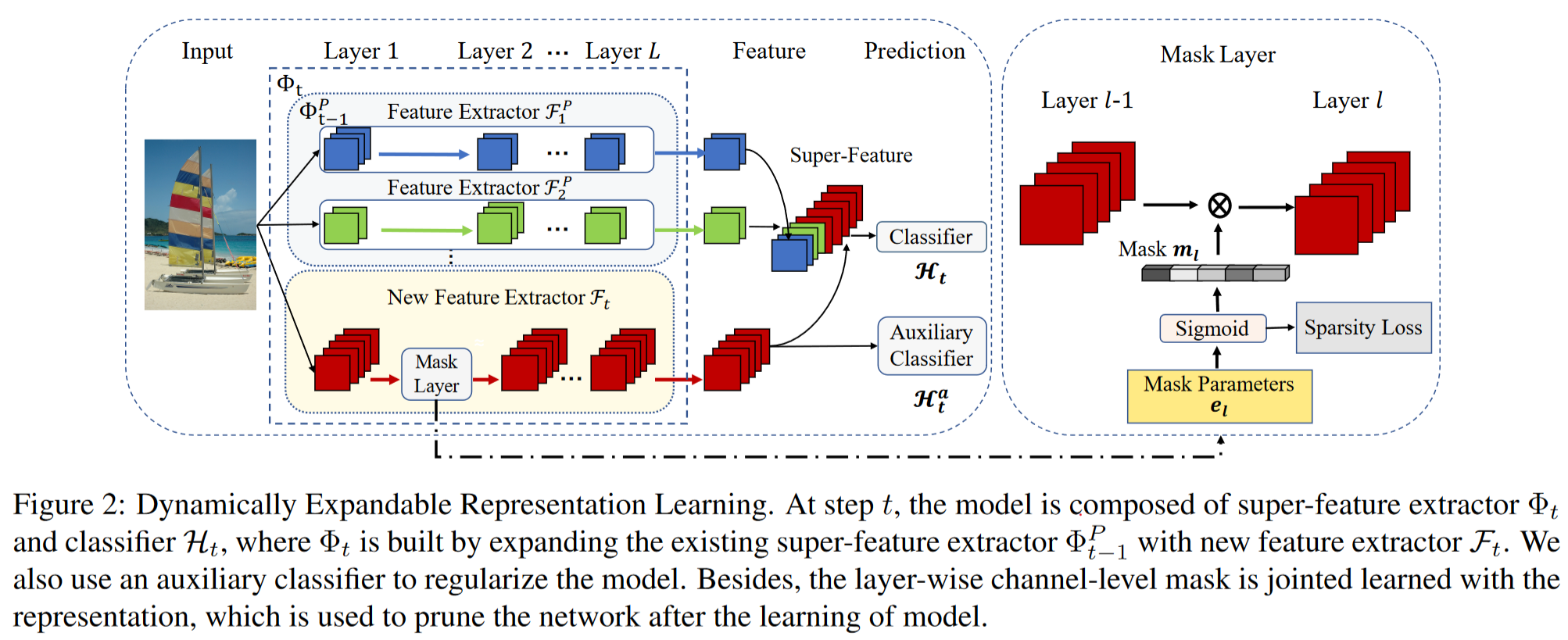
3.2 可扩展表示学习
我们首先介绍可扩展表示。在第
这里我们重新使用之前的
然后预测结果
为了减少灾难性遗忘,我们在第
我们可以从估计先验分布
训练损失
我们使用交叉熵损失在记忆和新数据上学习模型,如下所示:
其中
为了强制网络学习新概念的多样化和判别性特征,我们进一步开发了一个辅助损失,作用于新特征
其中
3.3. 动态扩展
为了去除模型冗余并保持紧凑的表示,我们根据新类别的复杂性动态扩展超级特征。具体来说,我们采用基于通道级掩码的可微分剪枝方法,将提取器
通道级掩码:我们的剪枝方法基于可微分的通道级掩码,改编自HAT。对于新特征提取器
其中
其中
在训练期间,
掩码学习:在每个epoch中,
其中
sigmoid函数的一个问题是梯度由于
其中
稀疏损失:在每个步骤中,我们鼓励模型在最小性能下降的情况下最大限度地减少参数数量。出于此动机,我们添加了一个基于所有可用权重中使用权重的比率的稀疏损失:
其中
在添加稀疏损失后,最终的损失函数为:
其中
3.4. 分类器学习
在表示学习阶段,我们重新训练分类器头,以减少由不平衡训练引入的分类器权重偏差。具体来说,我们首先用随机权重重新初始化分类器,然后从当前可用数据
4. 实验
在本节中,我们进行了广泛的实验以验证我们算法的有效性。特别是在CIFAR-100、ImageNet-100和ImageNet-1000数据集上使用两种广泛使用的基准协议评估了我们的方法。我们还进行了一系列消融研究,以评估每个组件的重要性,并进一步深入了解我们的方法。下面我们首先在第4.1节中介绍实验设置和实现细节,然后在第4.2节中介绍CIFAR100数据集的实验结果。接着,我们在第4.3节中展示ImageNet-100和ImageNet-1000数据集的评估结果。最后,我们在第4.4节中介绍我们方法的消融研究和分析。
4.1. 实验设置与实现细节
数据集:CIFAR-100由32x32像素的彩色图像组成,包含100个类别。它有50,000张训练图像,每个类别500张,以及10,000张评估图像,每个类别100张。ImageNet-1000是一个包含1,000个类别的大规模数据集,包含约120万张RGB训练图像和50,000张验证图像。ImageNet-100是从ImageNet-1000数据集中选择100个类别构建的。
基准协议:对于CIFAR-100基准,我们在两个流行的协议上测试我们的方法,包括:
- CIFAR100-B0:我们遵循[27]中提出的协议,将100个类别分为5、10、20、50个增量步骤,每个批次的固定内存大小为2,000个样本;
- CIFAR100-B50:我们遵循[12]中引入的协议,从训练50个类别的模型开始,剩余的50个类别分为2、5、10个步骤,每个类别的内存为20个样本。我们比较了每个步骤的平均增量精度,即每个步骤精度的平均值。
我们还在ImageNet-100上评估了我们的方法,使用了两个协议:
- ImageNet100-B0:协议[27]从零开始以10个类别为批次训练模型,每个批次的固定内存大小为2,000;
- ImageNet100-B50:协议[12]从训练50个类别的模型开始,剩余的50个类别以10个步骤引入,每个类别的内存为20个样本。为了公平起见,我们使用与协议[27, 12]相同的ImageNet子集和类别顺序。对于ImageNet-1000,我们评估了我们的方法在协议[27]上,称为ImageNet1000-B0基准,该协议以100个类别为批次训练模型,总共10个步骤,固定内存大小为20,000。具体来说,我们使用与[27]相同的类别顺序进行ImageNet-1000。此外,我们比较了ImageNet-100和ImageNet-1000数据集上的top-1和top-5平均增量精度以及最后一步的精度。
实现细节:我们的方法使用PyTorch实现。对于CIFAR-100,我们采用ResNet-18作为特征提取器
4.2. CIFAR100上的评估
定量结果:表1总结了CIFAR100-B0基准的结果。我们可以看到,我们的方法在不同增量分割中始终以显著优势优于其他方法。随着分割中步骤数量的增加,我们的方法与其他方法之间的差距持续增加,这表明我们的方法在步骤较长的困难分割上表现更好。特别是在50个步骤的增量设置下,我们将平均增量精度从64.32%提高到72.05%(+7.73%),且参数数量更少。值得注意的是,尽管大幅减少了模型参数,但我们的方法由于剪枝导致的性能下降可以忽略不计,这表明我们的剪枝方法的成功。如图3的左面板所示,可以看到我们的方法在每个步骤中始终优于其他方法。此外,随着新类别的不断添加,我们的方法与其他方法之间的差距也在增加。具体来说,在50个步骤的增量分割下,最后一步的精度从42.75%提高到58.66%(+15.91%),这进一步证明了我们方法的有效性。
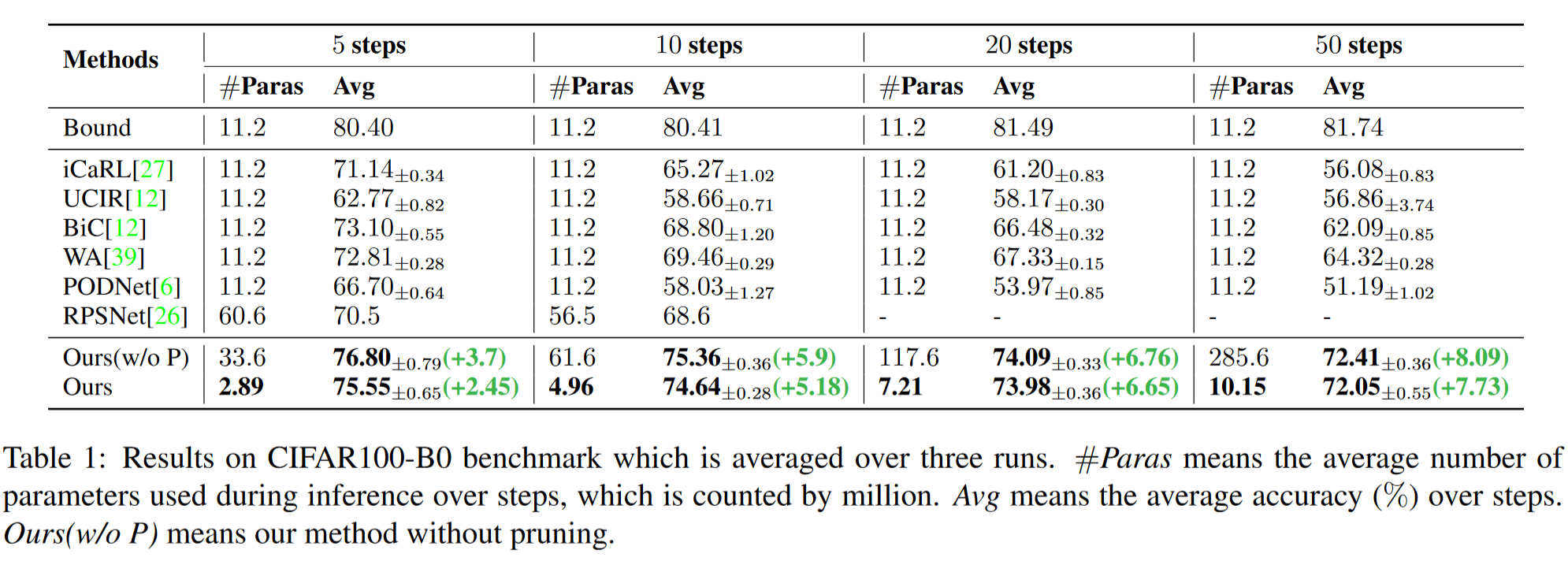
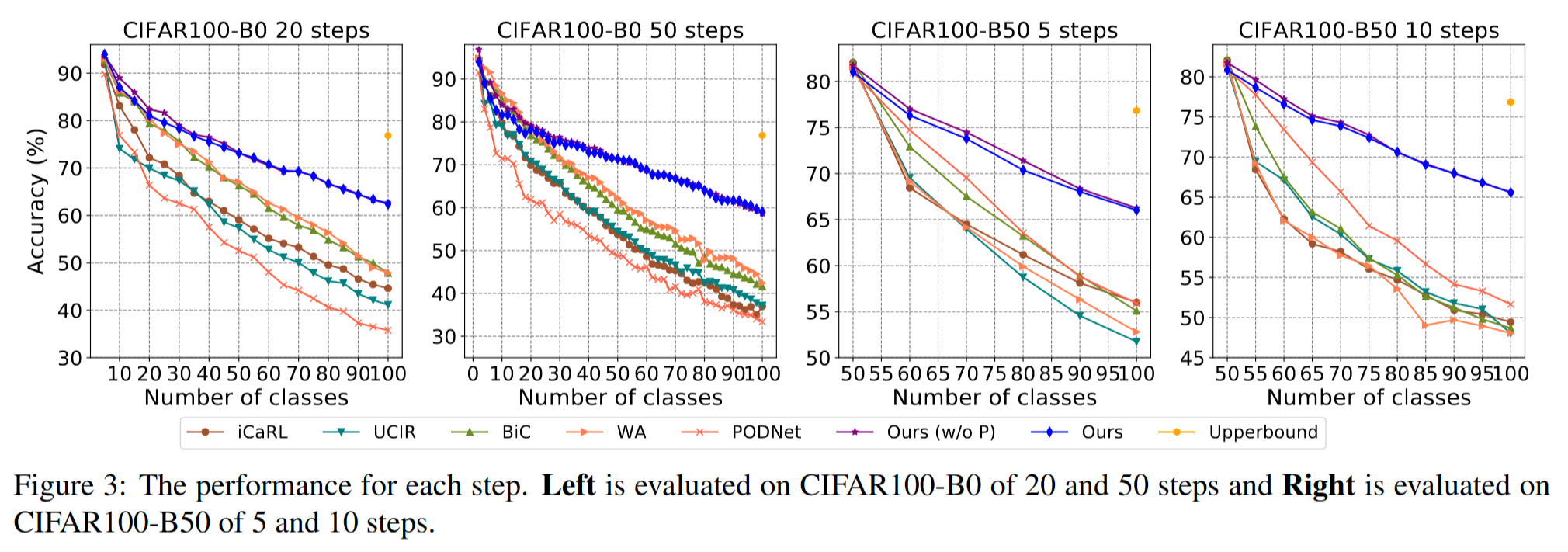
我们还在CIFAR100-B50基准上比较了我们方法与先前方法的性能,如表2所示,结果显示我们的方法在所有分割中均以显著增益提高了性能。特别是在10个步骤的增量设置下,我们的方法比PODNet高出8.41%的平均增量精度。如图3的右面板所示,我们的方法在每个步骤中均优于其他方法。特别是,在10个步骤的分割中,我们的方法将最后一步的精度从52.56%提高到65.58%(+13.02%)。此外,与未剪枝的方法相比,我们的方法以更少的参数实现了类似的性能。
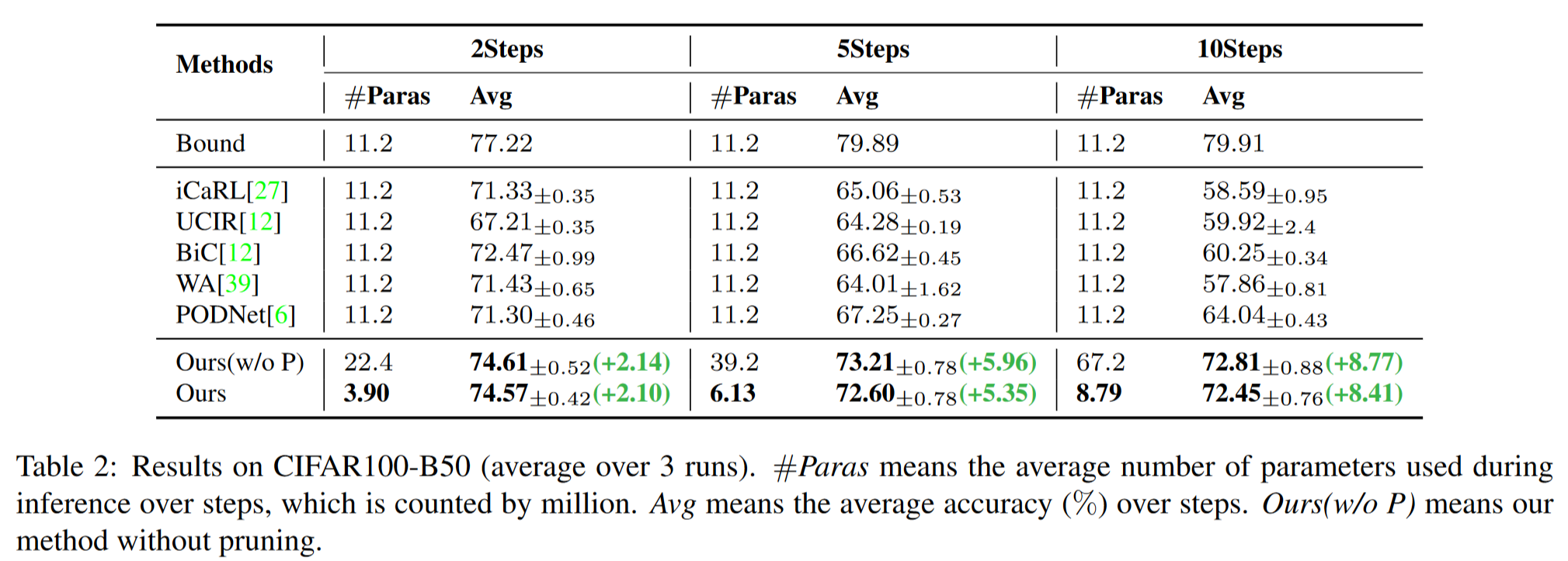
值得注意的是,先前的方法通常只在其中一个协议上表现良好,其中WA在CIFAR100-B0上是最先进的,而PODNet在CIFAR100-B50上是最先进的。相比之下,我们的方法在两个协议上始终优于其他方法。
模型大小的影响:我们进行了广泛的实验,研究模型大小对性能的影响。如图1所示,我们可以看到我们的方法在各种模型大小下始终显著优于其他方法。我们还注意到,随着模型大小的增加,我们的方法相比于大多数其他方法的改进变得更加显著,这表明我们的方法能够充分利用大模型的潜力。
4.3. ImageNet上的评估
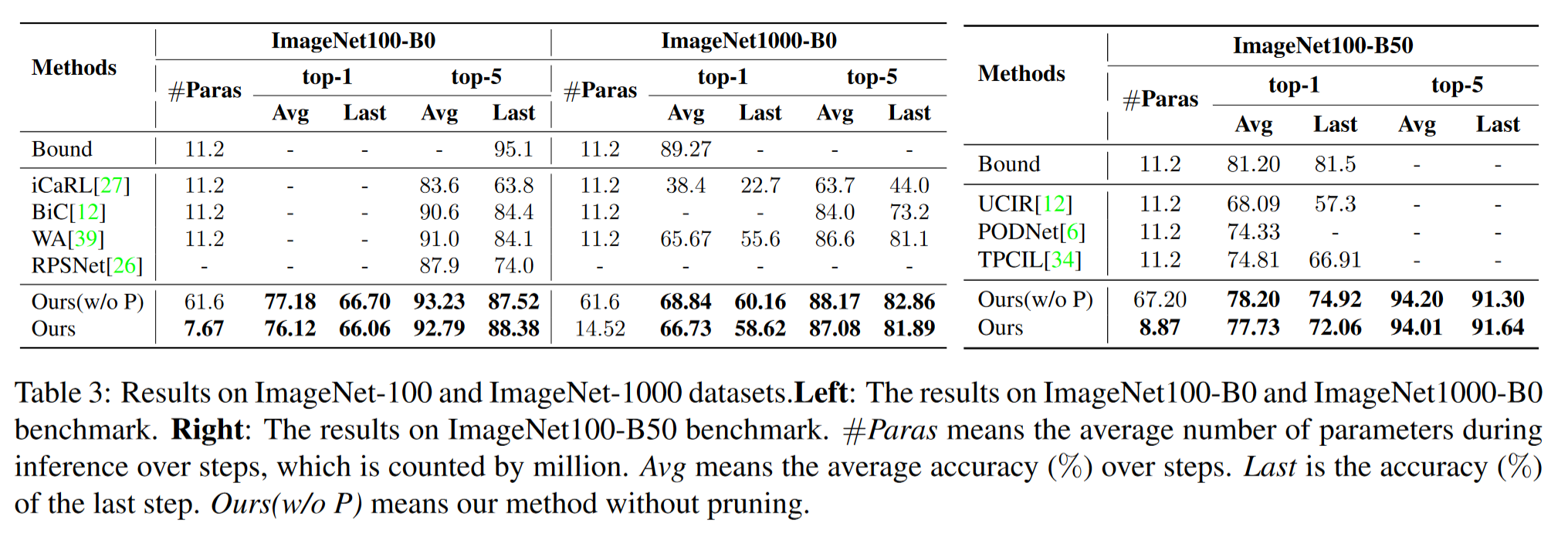
表3总结了ImageNet-100和ImageNet-1000数据集的实验结果。我们可以看到,我们的方法在ImageNet-100和ImageNet-1000数据集的所有分割中均以显著优势优于其他方法,特别是最后一步的精度。具体来说,我们的方法在ImageNet100-B0基准上的平均top-5精度比最先进方法高出约1.79%。对于ImageNet100-B50基准,最后一步的top-1精度从66.91%提高到72.06%(+5.15%)。此外,我们的方法在ImageNet1000-B0基准上将最后一步的top-1精度从55.6%提高到58.62%(+3.02%)。尽管top-5精度的差距较小,但我们认为这是因为top-5精度对稍微不准确的预测更具容忍性,因此对遗忘不太敏感。
4.4. 消融研究与分析
我们进行了详尽的消融研究,以评估我们方法中每个组件的贡献。我们还在附录中对超参数进行了敏感性研究。此外,我们研究了每种方法的表示的反向迁移和正向迁移。
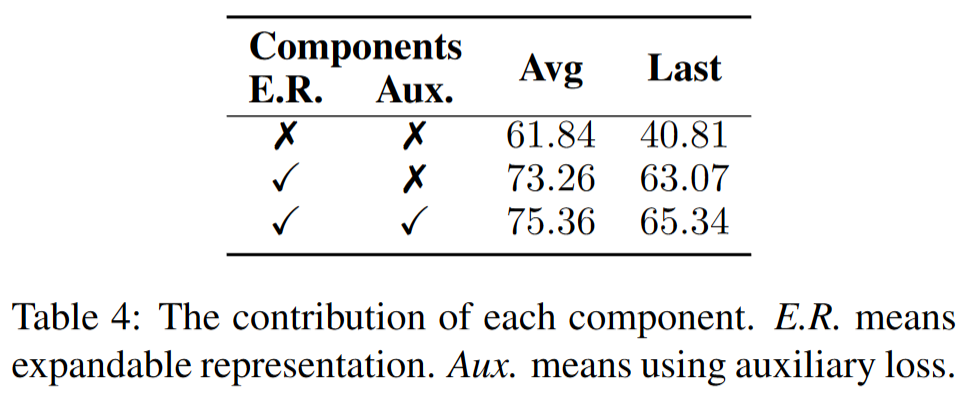
每个组件的影响:表4总结了我们在CIFAR100-B0上进行的10个步骤的消融实验结果。我们可以看到,通过表示扩展,平均精度从61.84%显著提高到73.26%。我们还表明,使用辅助损失后,模型的性能进一步提高了2.10%。
表示的反向迁移:为了评估表示的质量,我们引入了一个通过使用所有观察到的数据微调分类器获得的理想决策边界,这使我们能够排除分类器的影响。然后,我们定义第
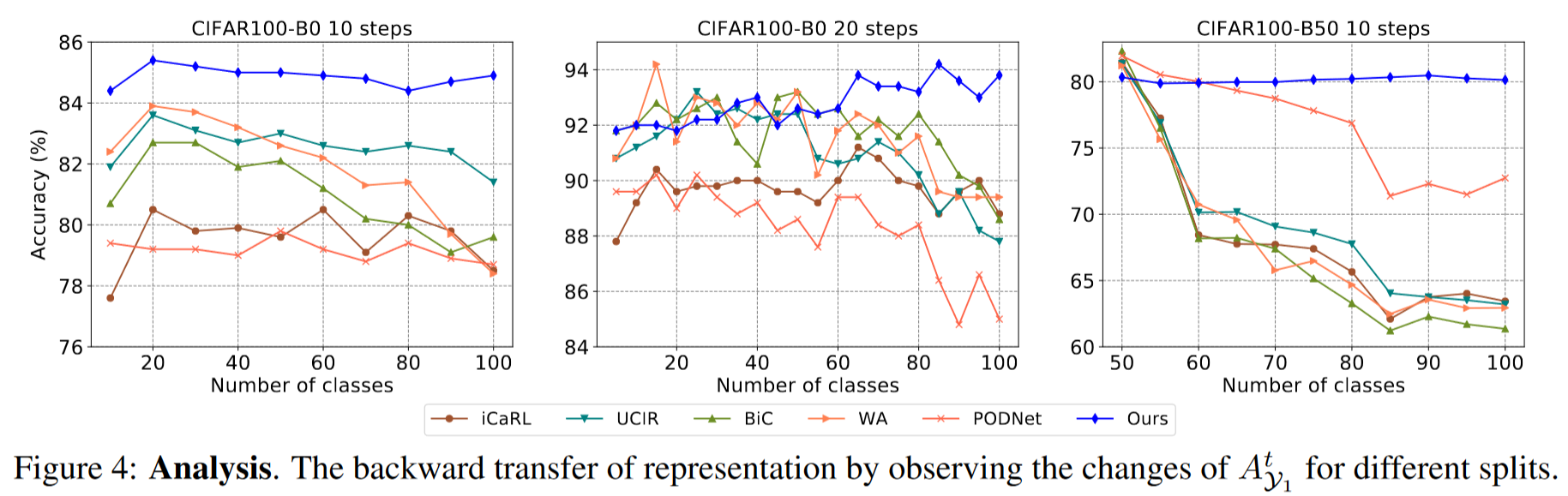
结果如表5所示。我们可以看到,其他方法遭受了严重的遗忘。相比之下,我们的方法甚至实现了正向反向迁移+1.36%,并且精度随步骤增加而提高,这进一步证明了我们方法的优越性。
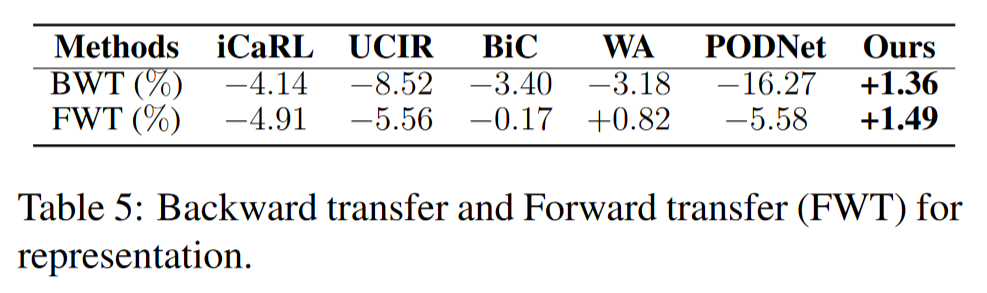
表示的正向迁移:我们还测量了现有知识对后续概念性能的影响,称为正向迁移。具体来说,我们定义了表示的正向迁移率如下:
其中
5. 结论
在本工作中,我们提出了动态可扩展的表示,以改进类别增量学习的表示。在每个步骤中,我们冻结先前学习到的表示,并通过新的参数化特征增强它。我们还引入了基于通道级掩码的剪枝方法,根据新概念的难度动态扩展表示,并引入了一个辅助损失以更好地学习新颖的区分性特征。我们在三个主要的增量分类基准上进行了详尽的实验。实验结果表明,我们的方法始终以显著优势优于其他方法。有趣的是,我们还发现我们的方法甚至可以实现正向和反向迁移。