 MOS
MOS
MOS: Model Surgery for Pre-Trained Model-Based Class-Incremental Learning (opens new window)
0. 摘要
类增量学习(CIL)要求模型在不断获取新类别知识的同时,不忘记旧知识。尽管预训练模型(PTMs)在 CIL 中表现出色,但在学习新概念时仍会发生灾难性遗忘。现有工作试图利用轻量级组件来调整 PTM,但遗忘现象仍然来自参数和检索级别。具体来说,模型的迭代更新导致参数漂移,而错误检索不相关的模块导致推理期间的不匹配。为此,我们提出了模型手术(MOS),以挽救模型免于忘记先前的知识。通过训练任务特定的适配器,我们不断调整 PTM 以适应下游任务。为了减轻参数级别的遗忘,我们提出了一种适配器合并方法来学习任务特定的适配器,旨在弥合不同组件之间的差距,同时保留任务特定信息。此外,为了解决检索级别的遗忘,我们在推理期间引入了一种无需训练的自精炼适配器检索机制,利用模型的固有能力以更好地检索适配器。通过联合纠正这些步骤的模型,MOS 可以稳健地抵抗学习过程中的灾难性遗忘。在七个基准数据集上的广泛实验验证了 MOS 的最新性能。代码可在:https://github.com/sun-hailong/AAAI25-MOS (opens new window) 获取。
1. 引言
近年来,深度学习在许多实际应用中取得了显著成果。然而,在开放世界中,数据通常以流式格式出现,需要一种能够增量获取新类别知识的机器学习范式,这被称为类增量学习(CIL)。CIL 中的一个重要挑战是灾难性遗忘,即模型在逐步学习新类别后,逐渐失去识别旧类别的能力。为了应对这一挑战,随着预训练模型(PTMs)的出现,CIL 领域也在不断发展。与“从零开始训练”的传统方法不同,当代 CIL 方法越来越多地利用 PTMs,这些模型最初在庞大的数据集上使用大量资源进行预训练。这种预训练过程赋予了 PTMs 强大的泛化能力。因此,设计一种有效利用 PTMs 并抵抗灾难性遗忘的 CIL 方法,已经引起了研究者的极大关注。由于 PTMs 的泛化能力,现有工作通常冻结预训练权重,并使用额外的轻量级模块来适应增量任务。例如,视觉提示调整定制提示以修改模型行为,促进对下游任务的适应。具体来说,L2P 设计了一个关键查询匹配策略,从提示池中检索实例特定的提示。基于 L2P,DualPrompt 引入了专家提示来编码任务特定信息,并探索了提示深度的影响。此外,CODA-Prompt 提出了一种基于注意力的提示加权方法以增强提示检索的有效性。然而,随着模型学习新概念,灾难性遗忘仍然发生。这种遗忘现象发生在参数和检索级别。在训练阶段,尽管许多方法使用轻量级组件来调整 PTM,但这些组件的迭代更新将导致参数漂移并触发遗忘。此外,现有工作致力于防止提示之间的冲突或实现正交投影,这加剧了新旧组件之间的参数漂移。在推理期间,训练多个轻量级模块需要选择最相关的一个,但模型可能会错误地检索不相关的模块,导致性能下降。这促使我们质疑是否可能联合纠正模型以抵抗参数和检索级别的灾难性遗忘?面对参数和检索级别的挑战,我们的模型应该能够有效地设计机制来克服这些问题。为了解决参数级别的遗忘,模型需要开发有效的更新方法,确保更新后的参数对旧数据保持区分性。为了克服检索级别的遗忘,模型需要有效的自我纠正策略,以帮助利用相关信息,协助实例特定的轻量级模块检索。为此,我们提出了预训练模型基于类增量学习的模型手术(MOS),以挽救模型免于忘记先前的知识。这种手术分为训练和推理阶段。为了减轻参数级别的遗忘,我们在训练期间提出了一种适配器合并方法,学习任务特定的适配器,同时弥合组件之间的差距,并保留任务特定信息。为了解决检索级别的遗忘,我们在推理期间引入了一种无需训练的自精炼适配器检索机制,利用模型的固有能力以更好地检索适配器。这种机制不需要额外的训练开销,使算法简单高效。最后,为了使模型能够在稳定性和可塑性之间取得平衡,我们提出了一种模型集成方法,整合了模型在多个阶段的能力。它不仅确保了强大的泛化能力,还允许模型快速识别和更新信息。在七个基准数据集上的实验验证了 MOS 的有效性。此外,自精炼适配器检索机制的可视化表明,MOS 有效地学习了适配器检索,以适应各种下游任务。
2. 相关工作
2.1. 类增量学习(CIL)
CIL 的目标是使模型能够获取新类别的知识,同时保留先前学习的信息。现有工作大致可以分为几类。基于知识蒸馏的方法建立了前一阶段模型与当前模型之间的映射,从而帮助后者在增量学习过程中保留早期更新的特征。基于数据重放的方法在训练新类别时选择并重放旧类别的关键示例,以不断修订以前的知识。基于参数正则化的方法旨在通过正则项预测和最小化关键参数的漂移。基于模型校正的方法专注于校正模型的归纳偏差,以确保无偏估计。基于模型扩展的方法为每个任务构建不相互干扰的子网络。在推理期间,它们被组合成一个更大的特征图,并训练一个分类器以有效地校准所有类别。
2.2. 基于预训练模型的 CIL
基于 PTM 的 CIL 已成为当前 CIL 研究领域的热点。随着预训练技术的进展,已经开发了许多参数高效的微调(PEFT)方法。这些方法旨在在冻结预训练权重的同时,以最小的额外资源提高模型性能。在这种情况下,L2P 引入了一个提示池,通过关键查询匹配选择机制选择实例特定的提示来指导 PTM 的响应。DualPrompt 通过设计 G-Prompt 和 E-Prompt 来扩展 L2P,它们分别编码任务不变和任务特定指令。CODA-Prompt 通过开发分解的提示,并使用基于注意力的加权方法将它们组合起来。DAP 将提示选择扩展到提示生成。SLCA 揭示了在表示层以较低的学习率微调 ViT 骨干网络比提示策略获得更高的准确性。APER 探索了各种 PEFT 方法,并表明原型分类器作为一个强基线,而 RanPAC 进一步扩展了 APER 在随机投影中。EASE 将多个任务特定骨干的特征表示连接起来。
3. 预备知识
3.1. 类增量学习
类增量学习的目标是获取不断演变的数据流引入的新类别知识,同时保留先前的知识,以构建统一的分类器。考虑一系列 B 个训练阶段,表示为
其中
3.2. 使用 PTMs 的 CIL 学习分析
在类增量学习中使用 PTMs 的代表性工作是 L2P 方法。他们引入了一种冻结预训练权重的策略,并构建了一个可学习的提示池,可以在所有任务中共享。这个提示池表示为
其中 K 是所有键的集合,
其中
4. MOS:基于预训练模型的 CIL 模型手术
面对抵抗灾难性遗忘的挑战,我们需要一种联合纠正模型的方法。MOS 的关键思想是在两个方面设计模型手术,即减轻参数漂移的训练阶段手术和测试阶段手术,以检索更好的轻量级模块。训练阶段手术的目标是利用先前学到的知识来提高当前任务的性能,使模型能够更快地适应新任务。测试阶段手术寻求一种机制,以更好的方式检索适配器,而无需额外的开销。因此,模型可以从持续的轻量级模块更新和有效的检索能力中受益,而不会忘记现有知识。我们首先介绍用于减轻参数漂移的渐进式合并适配器的处理过程,然后讨论自精炼适配器检索机制。我们在最后部分用伪代码总结了推理功能。
4.1. 渐进式合并适配器
为了处理模型迭代更新引起的参数漂移,我们需要弥合不同轻量级模块之间的差距。换句话说,随着模型不断接收新数据和任务,有效地保留和利用先前学到的知识至关重要。这种方法允许模型将先前的知识转移到新任务,并减轻参数漂移问题。在方程 (3) 中,给定输入 x 的嵌入是使用实例特定提示获得的。在增量阶段,可能会出现潜在问题,即对现有提示的迭代更新可能使它们更好地匹配新任务,可能导致忘记旧任务。由于上述方法中的大型提示池加剧了错误检索,我们建议通过使用较少数量的轻量级模块来减轻这个问题。具体来说,通过直接将适配器调整(Rebuffi, Bilen, and Vedaldi 2017)整合到 PTM 中以优化单个适配器来编码任务特定信息,我们通过应用这种方法实现了这一目标。这种增强的整合有助于更有效地吸收任务特定信息。通过这种方法,我们只需要优化一组适配器来编码任务特定信息。表示预训练模型中有 L 个变换器块,每个块都有一个自注意力模块和一个 MLP 层。我们通过残差连接将适配器集成到每个层的 MLP 中。适配器是一个瓶颈模块,包括一个下投影层
其中
我们通过优化方程 (5),使适配器将任务特定信息整合到嵌入中,从而促进新任务的学习。在理想情况下,如果测试样本的任务 ID 已知,我们可以使用此 ID 轻松选择相应的任务特定适配器以获得最佳结果。然而,在 CIL 设置中,测试阶段不允许获得这样的任务 ID。为了解决这一挑战并减轻参数漂移,我们提出了训练阶段手术,该手术使用基于指数移动平均(EMA)的适配器合并策略:
其中
4.2. 自精炼适配器检索机制
在获得这些任务特定适配器后,我们使用基于原型的分类器进行预测。具体来说,在每个增量阶段的训练过程后,我们使用适配器
其中 N 是类别 i 的实例数量。方程 (7) 说明了分类器的构造。在推理期间,我们直接采用类原型作为分类器权重,即
其中
其中
例如,在每个任务包含 10 个类别的场景中,类别 0 到 9 在任务 0 中,而类别 10 到 19 在任务 1 中。随后,如果
在方程 (11) 中,第 1 部分仅在第一个增量任务上训练,作为上游和下游数据集之间的重要桥梁。它不仅表现出强大的泛化能力,还具有快速识别和更新信息的能力。相比之下,第 2 部分采用渐进式合并适配器和自精炼适配器检索机制进行深度处理和有意识记忆。
5. 实验
在本节中,我们在七个基准数据集上评估 MOS,并将其与其他最新方法进行比较,以展示其优越性。此外,我们提供了消融研究和可视化分析,以验证 MOS 的鲁棒性。
5.1. 实施细节
数据集
由于 PTMs 拥有关于上游任务的广泛知识,我们遵循 Zhou et al. 2024a,在 CIFAR100、CUB200、ImageNetR、ImageNet-A、objectNet、Omnibenchmark 和 VTAB 上评估性能。这些数据集代表了典型的 CIL 基准,并包括与 ImageNet(即预训练数据集)存在显著领域差异的离群数据集。具体来说,VTAB 有 50 个类别,CIFAR100 有 100 个类别,CUB、ImageNet-R、ImageNet-A、ObjectNet 有 200 个类别,OmniBenchmark 有 300 个类别。更多细节报告在补充材料中。
数据集分割
遵循基准设置 Rebuffi et al. 2017; Wang et al. 2022c,我们使用“B-m Inc-n”的表示法来表示类别分割,其中 m 表示初始任务中的类别数量,n 表示每个后续增量任务中的类别数量。m=0 表示总类别平均分配给每个任务。为了进行一致和公平的比较,我们在分割数据之前使用随机种子 1993 随机洗牌类别顺序。我们确保所有方法在训练和测试集的一致性,遵循 Zhou et al. 2024a。
训练细节
我们使用 PyTorch 和 PILOT 在 NVIDIA RTX 4090 上使用相同的网络骨干实现所有模型。由于 PTMs 的广泛范围是公开可用的,我们选择了两个代表性模型,分别表示为 ViTB/16-IN1K 和 ViT-B/16-IN21K。它们都最初在 ImageNet21K 上预训练,而前者在 ImageNet1K 上进行了微调。在 MOS 中,我们将批量大小设置为 48,并使用 SGD 优化器进行 20 个周期的训练,动量为 0.9。学习率最初设置为 0.01,并遵循余弦退火衰减模式。适配器中的投影维度 r 设置为 16,EMA 因子参数α设置为 0.1。
比较方法
我们选择了最新的基于 PTM 的 CIL 方法进行比较,如 Finetune Adapter、L2P、DualPrompt、CODA-Prompt、SimpleCIL、APER、SLCA、EASE。此外,我们将 MOS 与传统的 CIL 方法进行比较,这些方法通过 PTM 进行了修改,包括 LwF、FOSTER、MEMO、iCaRL、DER。我们报告了顺序微调 PTM 的基线方法,表示为 Finetune。所有方法都使用相同的 PTM 实现,以进行公平比较。
评估协议
遵循 Rebuffi et al. 2017 建立的基准,我们将第 b 阶段后的 Top-1 准确率表示为
5.2. 基准比较
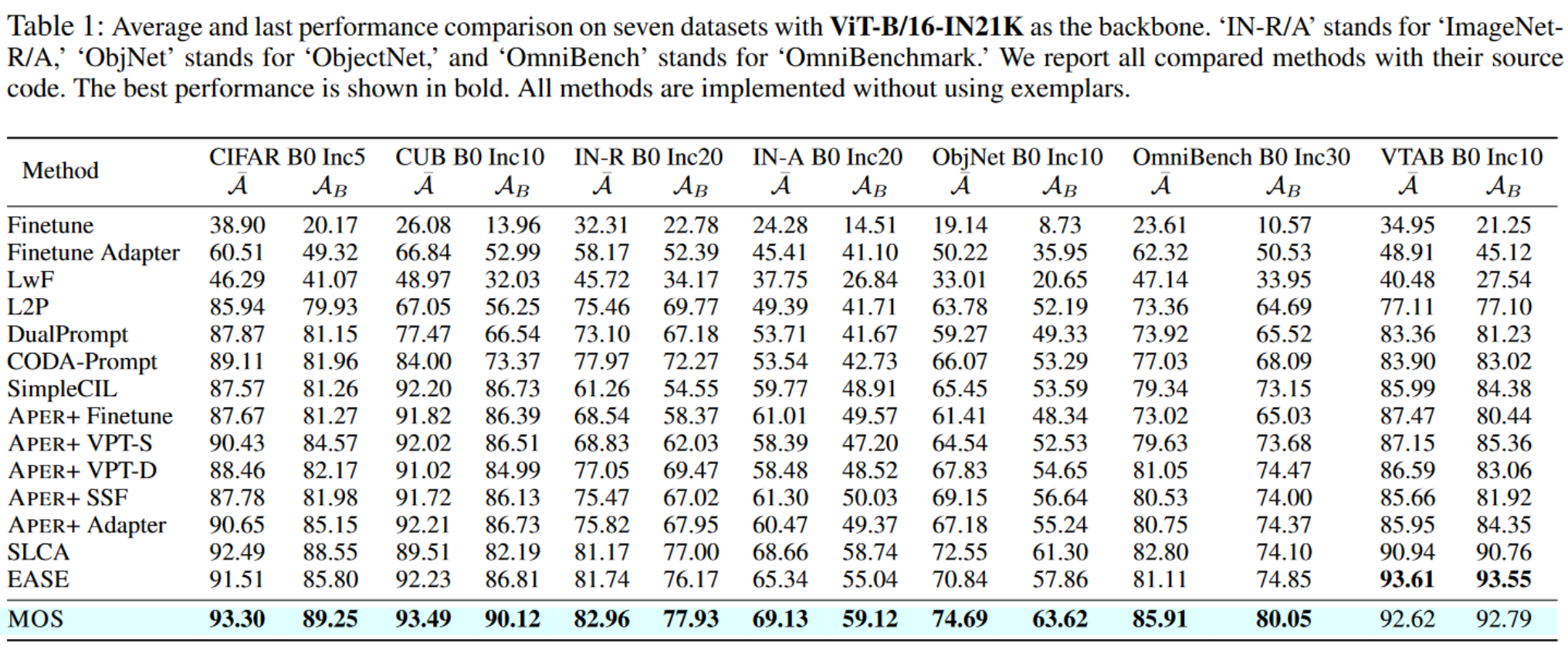
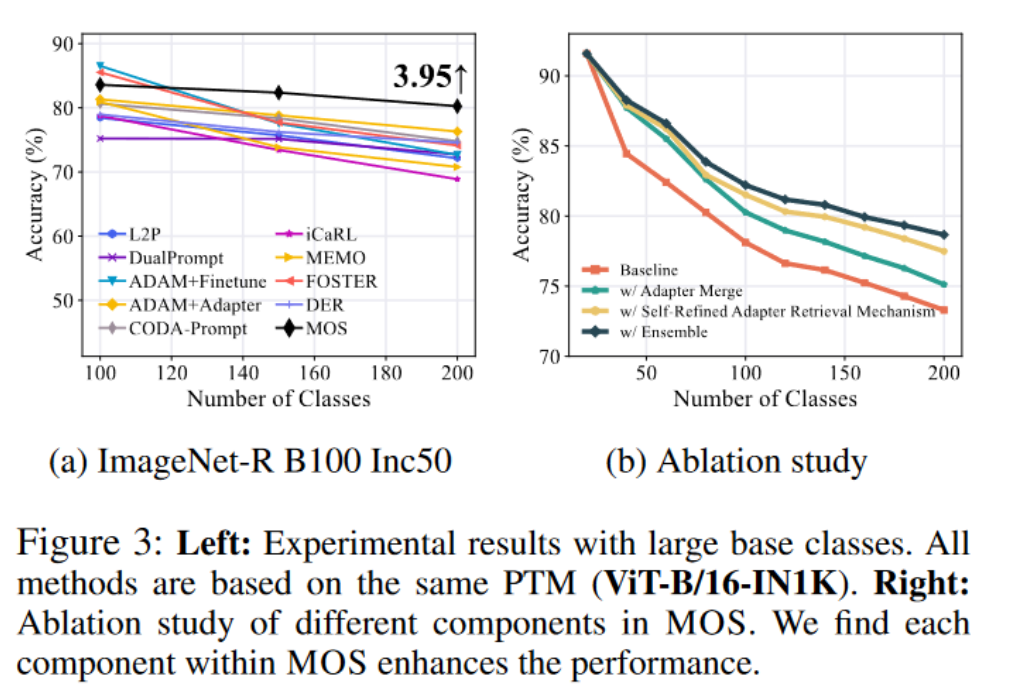
在本节中,我们在七个数据集和各种骨干权重上将 MOS 与其他最新方法进行比较。如表 1 所示,MOS 在所有七个基准测试中表现出最佳性能,显著超过了最新方法,如 SLCA、EASE 和 APER。此外,我们使用 ViT-B/16-IN1K 在图 2 中展示了不同方法在增量性能趋势的分析。值得注意的是,MOS 在 CUB、ObjectNet 和 OmniBenchmark 上比亚军方法高出 2%∼5%,如每个图像末尾的注释中突出显示的那样。除了表 1 和图 2 中呈现的 B0 设置外,我们将实验扩展到更大的基础设置。在图 3a 中,我们使用相同的 PTM 将 MOS 与几种最新方法和传统方法进行比较。尽管传统方法需要存储示例以恢复以前的知识,MOS 在这种设置中也实现了最新性能。广泛的实验验证了 MOS 的有效性。
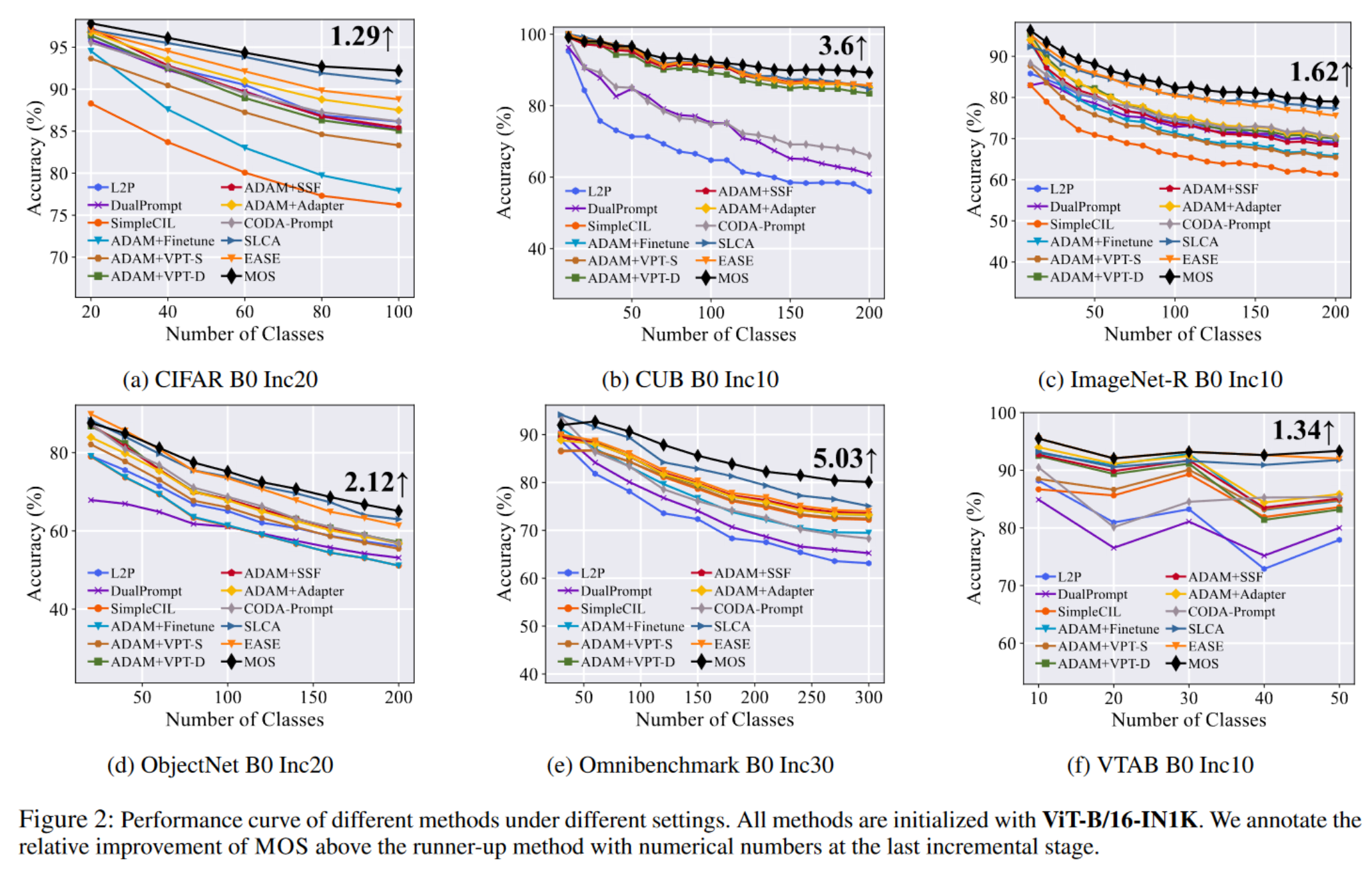
5.3. 消融研究
在本节中,我们通过逐步添加每个组件来进行消融研究,以评估它们在 MOS 中的有效性。具体来说,我们在 ImageNet-R B0 Inc20 设置上展示了这种消融研究。如图 3b 所示,“基线”指的是与
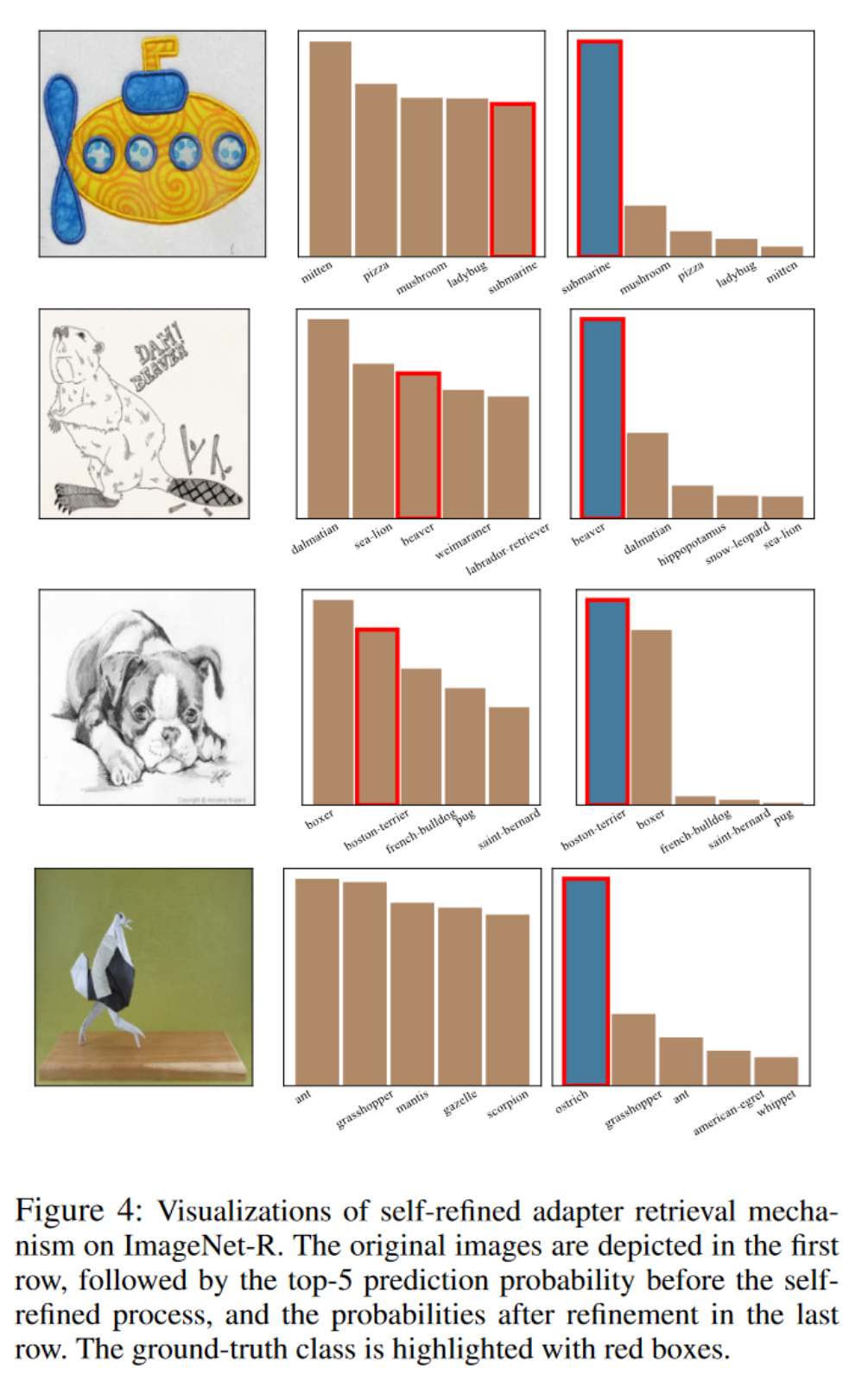
5.4. 可视化
在本节中,我们讨论了自精炼适配器检索机制的工作方式。为了直观地说明这一点,我们提供了自精炼过程前后的预测结果的可视化,并分析了它们的差异。我们从 ImageNet-R 中选择了图像,并使用了在 B0 Inc20 设置下训练的模型。结果如图 4 所示。正如这些图所示,MOS 能够纠正错误的预测。这在下面的例子中尤为明显,最初的前 5 个类别预测概率不包括真实类别,但 MOS 准确地纠正了这个错误。它表明模型可以使用其固有的能力选择当前样本最合适的适配器。因此,MOS 可以使用这个适配器提取更合适的特征,这有助于提高预测准确性。这些可视化揭示了自精炼适配器检索机制可以帮助纠正输出,从而增强对真实类别的关注。
6. 结论
增量学习是现实世界系统中日益突出的范式。本文提出了一种新的模型手术(MOS),用于基于预训练模型的 CIL,以挽救模型免于忘记先前的知识。具体来说,我们引入了适配器合并方法来减轻参数漂移,并设计了一种无需训练的自精炼适配器检索机制,以便在推理期间更好地检索适配器。我们的方法通过利用模型的固有能力,平衡了稳定性和可塑性的困境,增强了泛化和适应性。在七个基准数据集上的广泛实验验证了 MOS 的有效性。在未来的工作中,我们旨在探索更多的应用场景,如少样本类增量学习。
附录
在本补充部分,我们提供了关于 MOS 的更多信息,包括对其组件的进一步分析、参数敏感性、多次运行、运行时间比较以及自精炼适配器检索机制的更多可视化。
1. 进一步分析
在本节中,我们对 MOS 的组件进行了进一步分析,以研究它们的有效性,例如参数敏感性、多次运行和自精炼机制的更多可视化。此外,我们还比较了 MOS 与其他方法的运行时间。
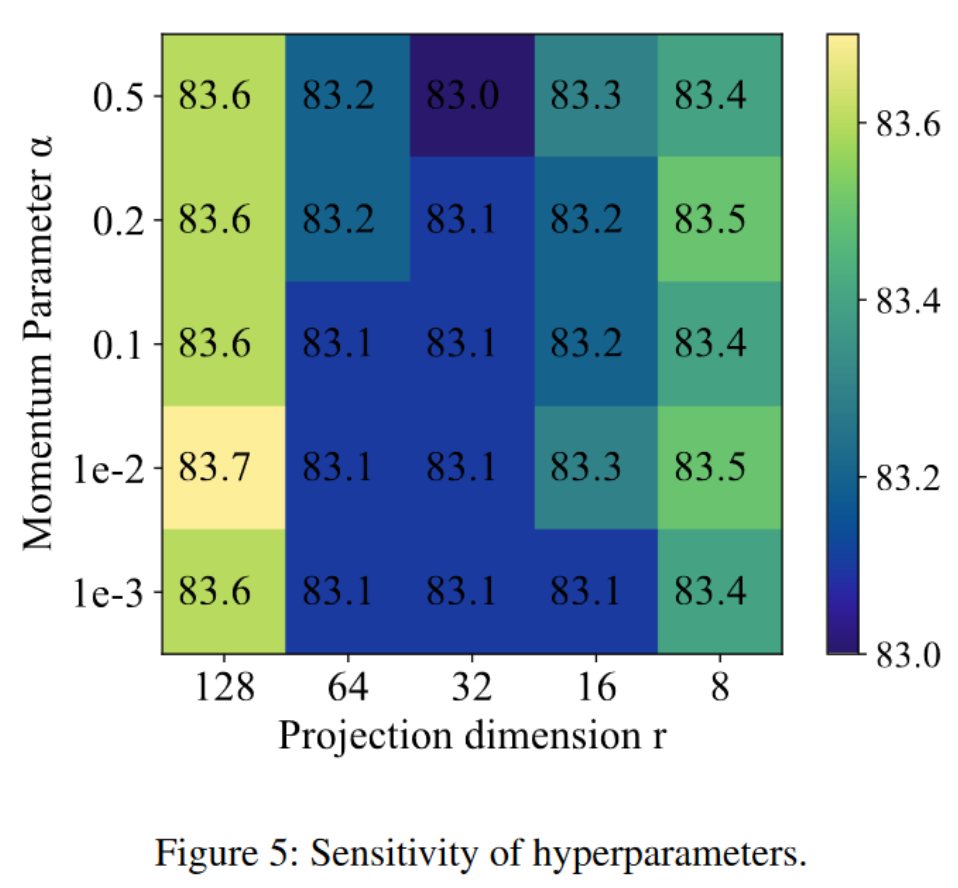
参数敏感性
在主要论文中,我们介绍了渐进式合并适配器,其中包含两个关键超参数:适配器中的投影维度 r 和用于指数移动平均(EMA)方法的合并动量α。为了评估这些参数的敏感性,我们在 ImageNet-R B0 Inc20 数据集上进行了实验。具体来说,我们将 r 在集合{8, 16, 32, 64, 128}中变化,将α在{0.001, 0.01, 0.1, 0.2, 0.5}中变化。这些设置的平均性能如图 5 所示。如图中所示,模型的性能在一系列参数值中保持稳定。此外,我们可以推断出这些参数并不高度敏感。基于这些发现,并考虑到减少参数数量的可能性,我们推荐默认设置 r = 16, α = 0.1 用于其他数据集。
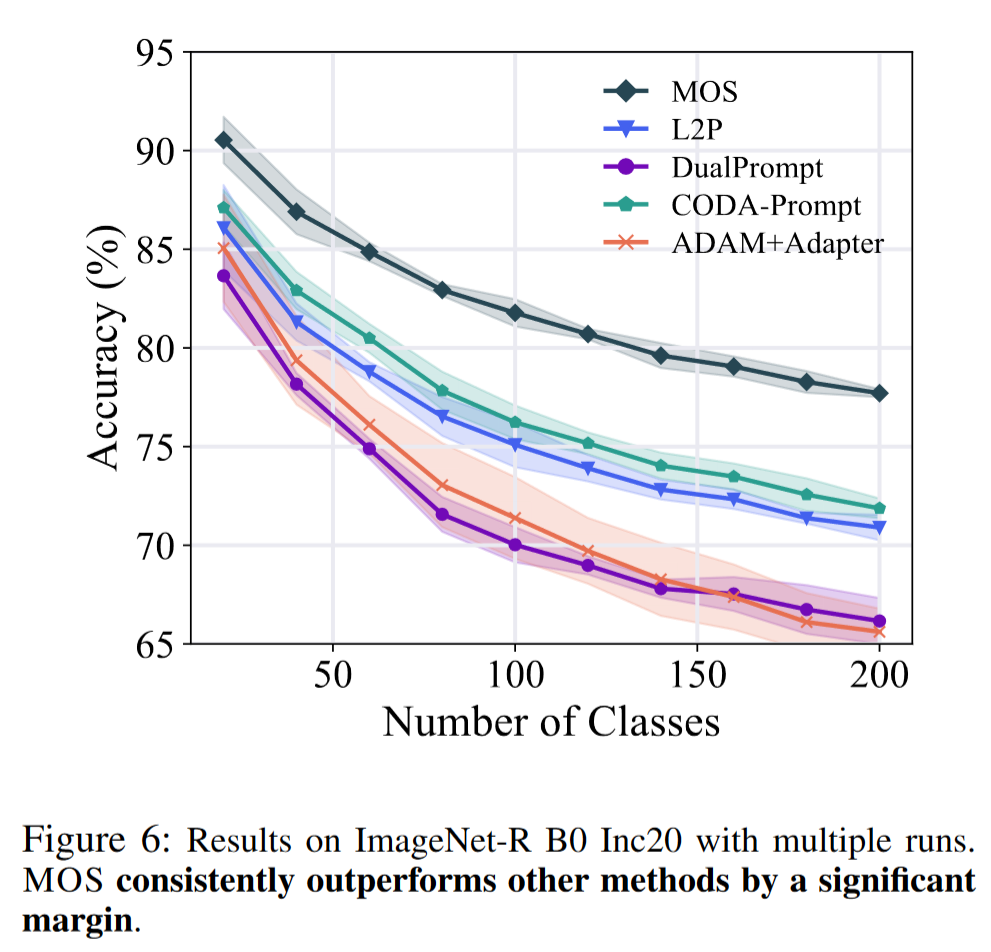
多次运行
在主要论文中,我们在不同数据集上进行了实验,遵循 Rebuffi 等人的方法,使用种子 1993 随机化类别顺序。本节通过使用多个随机种子重复这些实验,具体为{1993, 1994, 1995, 1996, 1997},来扩展这项工作。这种方法产生了不同方法的五组增量结果,使我们能够计算并呈现图 6 中的平均值和标准差。如图中所示,我们可以推断 MOS 在不同随机种子中一致地超越其他方法。
运行时间比较
本节介绍了不同类增量学习方法的比较运行时间。所有实验都在单个 NVIDIA 4090 GPU 上进行。具体来说,我们在 ImageNet-R 上训练所有方法 10 个周期,在 CIFAR-100 上训练 20 个周期。结果如图 7 所示。结果表明 MOS 在运行时间上优于 CODA-Prompt、L2P 和 DualPrompt,同时实现了更好的性能。这些结果验证了 MOS 的有效性。
更多可视化
在主要论文中,通过四个可视化图解释了自精炼机制的工作方式。为了进一步直观地展示这种方法的有效性,提供了额外的可视化图。具体来说,我们从 ImageNet-R 中选择了图像,并使用了在 B0 Inc20 设置下训练的模型,ViT-B/16-IN1K。进一步的结果如图 9 所示。这些图示展示了 MOS 纠正错误预测的能力。此外,这些可视化图突出了自精炼机制在纠正输出和增强对真实类别关注方面的帮助。

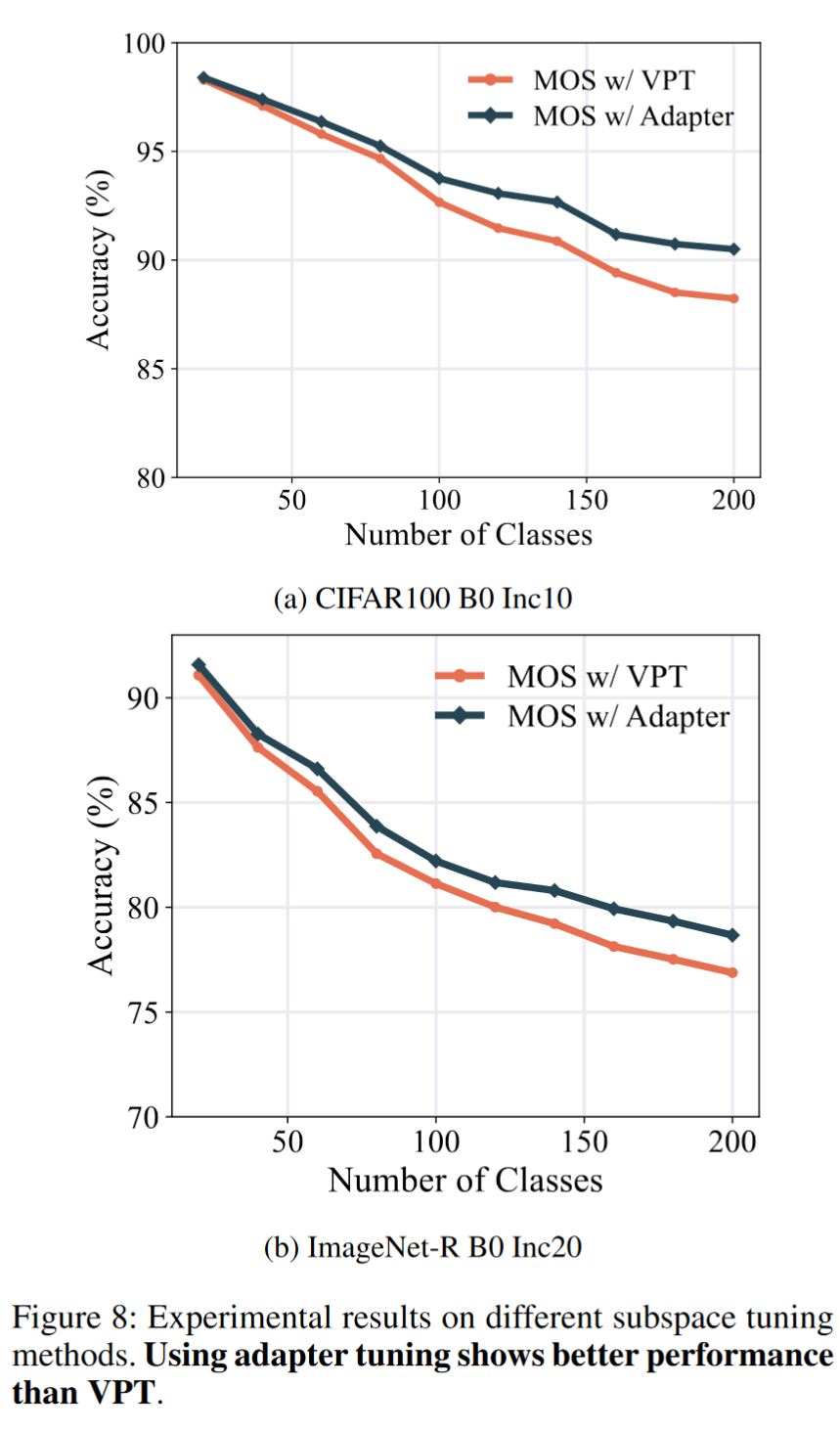
适配器调整与 VPT
在主要论文中,我们通过适配器调整构建了任务特定组件。然而,除了适配器调整外,还有其他方法可以高效地调整预训练模型的参数,如视觉提示调整(VPT)。在本节中,我们将我们的方法与各种参数高效微调(PEFT)技术集成,并在 CIFAR100 和 ImageNet-R 上进行了实验。我们保持一致的设置,只改变 PEFT 训练方法,并在图 8 中展示了结果。从图中,我们观察到使用适配器进行模型手术比使用 VPT 实现了更好的性能,这些数据集上的性能提高了约 2%。这种优越性主要来自两个方面:首先,适配器调整比 VPT 具有更强的调整能力。其次,适配器调整只需要为每个任务学习一组适配器,而 VPT 需要构建一个大的提示池,使检索变得复杂。因此,我们选择适配器调整作为 MOS 中模型手术的实现方式。
2. 高斯分布的分类器对齐示例生成细节
在本节中,我们提供了如何使用高斯分布对分类器进行对齐的详细说明。由于预训练模型(PTM)的表示通常是良态分布的,因此在训练每个任务特定的适配器
其中
其中
3. 比较方法的详细介绍
在本节中,我们详细介绍了主要论文中比较的方法。每种方法都使用相同的预训练模型(PTM)以确保公平比较。这些方法列举如下:
Finetune:在新任务上持续训练时更新所有参数与 PTM,但容易受到显著的灾难性遗忘影响。
LwF:旨在通过知识蒸馏抵抗遗忘,创建最后阶段模型与当前模型之间的桥梁,以传递过去知识。
L2P:将视觉提示调整集成到类增量学习中,使用预训练的视觉变换器。它进一步建立了一个提示池,便于选择实例特定的提示。
DualPrompt:基于 L2P 方法引入了两类提示:通用提示和专家提示。
CODA-Prompt:认识到实例特定提示选择的局限性。这种方法试图通过提示重新加权来克服这些挑战。具体来说,它通过注意力机制改进了提示选择过程,用于提示重新加权。
SimpleCIL:提出了一个基于原型的分类器,使用 PTM。初始化 PTM,为每个类别建立一个原型分类器,使用余弦分类器进行分类过程。
APER:通过整合预训练模型和适应模型扩展 SimpleCIL。这种方法将初始增量阶段视为唯一的适应阶段,在该阶段定制 PTM 以提取任务特定特征。因此,该模型有效地统一了泛化能力和适应性。
SLCA:将先前类别的高斯建模扩展到先前工作中的分类器校正。
EASE:连接多个任务特定骨干的特征表示,从而实现优越性能。它设计了一个语义映射策略,用于分类器补充,以补偿不断扩展的特征和先前分类器。
上述方法都是示例自由的,意味着它们不需要使用示例。另一方面,我们还在主要论文中评估了一些基于示例的方法,如下:
iCaRL:使用知识蒸馏和基于示例的重放来复习以前的知识。此外,它利用最近中心均值分类器进行最终分类过程。
DER:利用动态可扩展的表示,更有效地增强增量概念建模。
FOSTER:为了减少 DER 相关的内存负担,这种方法建议通过知识蒸馏压缩骨干网络。因此,整个学习过程中只维护一个单一的骨干网络。这种方法有效地实现了特征扩展,同时最小化内存消耗。
MEMO:试图从另一种策略减少与 DER 相关的内存需求。它将网络架构有效地分为两个不同的部分:专门的(深层)层和泛化的(浅层)层。这种设计使得专门的层可以扩展,同时利用现有的泛化层作为共同基础。
在实验中,我们根据这些方法的源代码和 PILOT 重现了上述方法。
4. 不同设置下更多结果
在本节中,我们展示了不同方法在各种设置下的更多实验结果。我们特别详细说明了这些方法在使用 ViT-B/16-IN21K 和 ViT-B/16-IN1K 时的增量性能,如图 10、图 11 和图 12 所示。结果表明 MOS 在不同数据集上始终超越其他方法,实现了显著的优势。