 KV Cache
KV Cache
KV Cache是Transformer标配的推理加速功能,transformer官方use_cache这个参数默认是True,但是它只能用于Decoder架构的模型,这是因为Decoder有Causal Mask,在推理的时候前面已经生成的字符不需要与后面的字符产生attention,从而使得前面已经计算的K和V可以缓存起来。
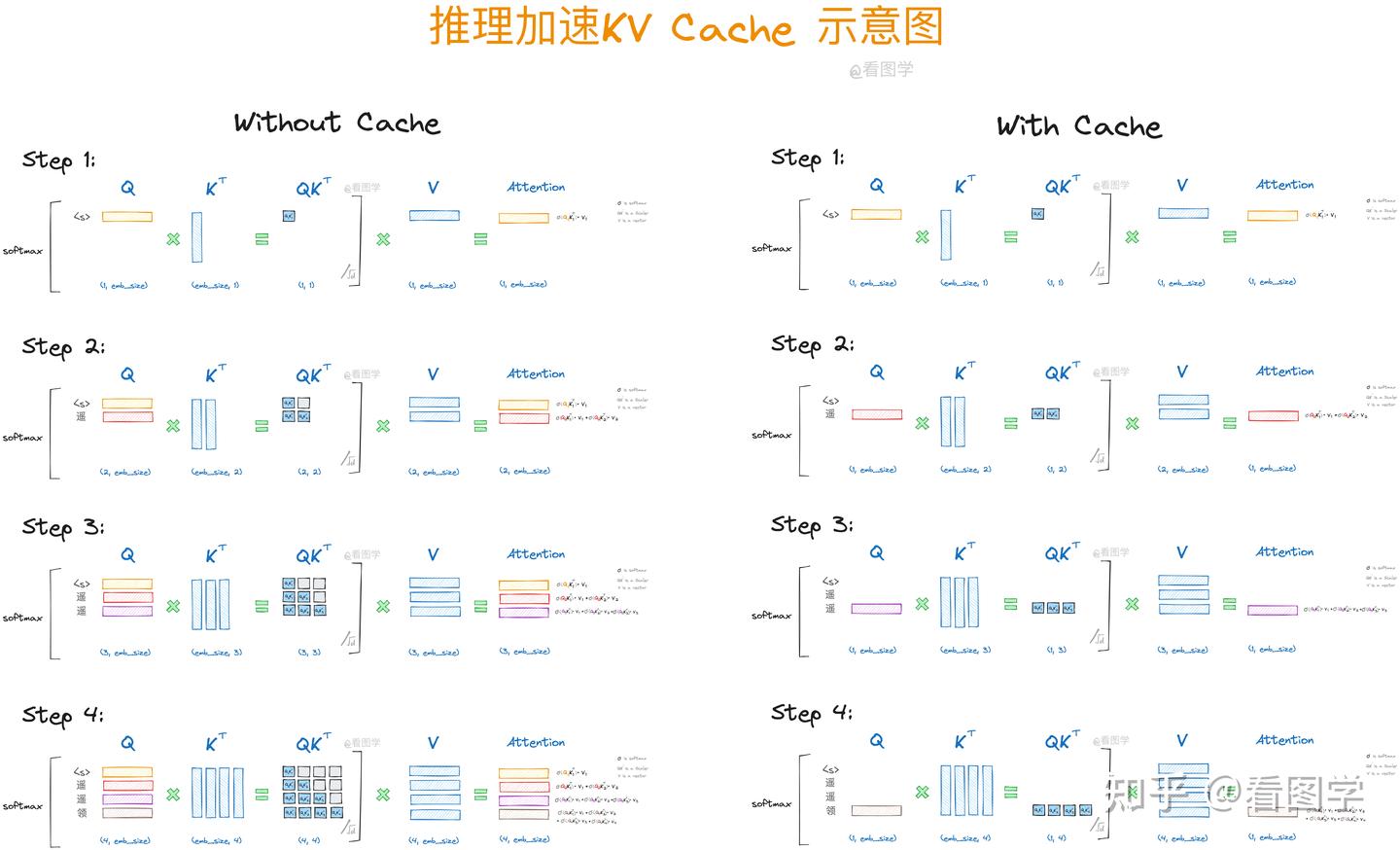
我们先看一下不使用KV Cache的推理过程。假设模型最终生成了“遥遥领先”4个字。
当模型生成第一个“遥”字时,input="<s>", "<s>"是起始字符。Attention的计算如下:
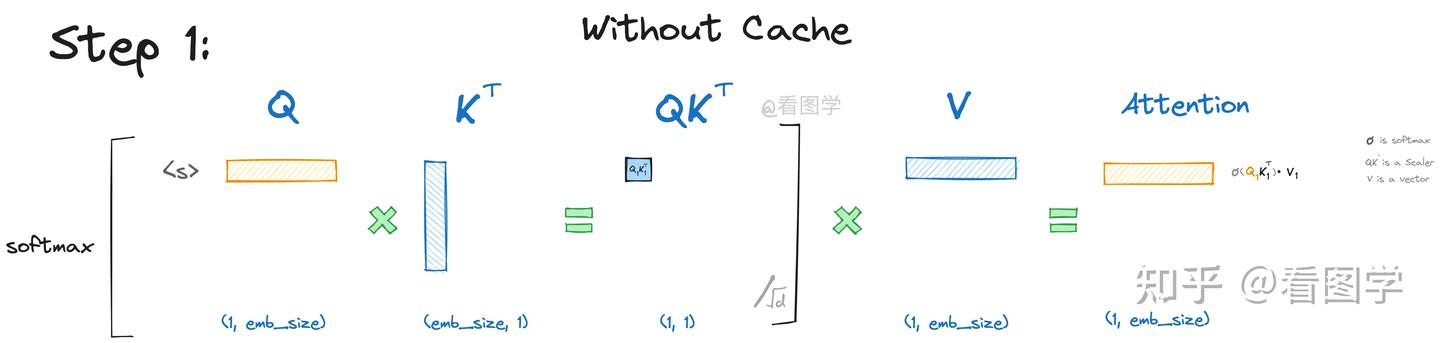
为了看上去方便,我们暂时忽略scale项
如上图所示,最终Attention的计算公式如下,(softmaxed 表示已经按行进行了softmax):
当模型生成第二个“遥”字时,input="<s>遥", Attention的计算如下:
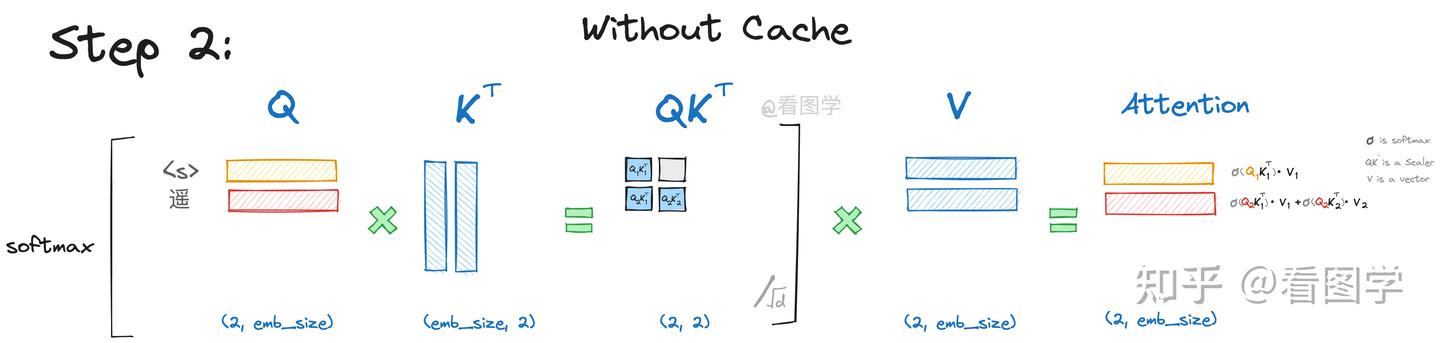
当

假设
其计算公式为:
你会发现,由于
在第二步参与的计算与第一步是一样的,而且第二步生成的 也仅仅依赖于 ,与 毫无关系。 的计算也仅仅依赖于 ,与 毫无关系。
当模型生成第三个“领”字时,input="<s>遥遥"Attention的计算如下:
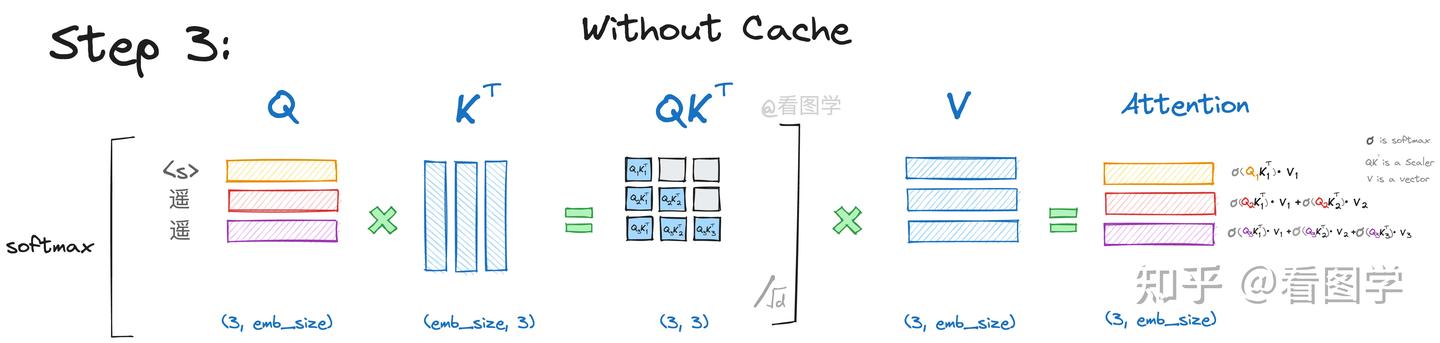
详细的推导参考第二步,其计算公式为:
同样的,
当模型生成第四个“先”字时,input="<s>遥遥领"Attention的计算如下:
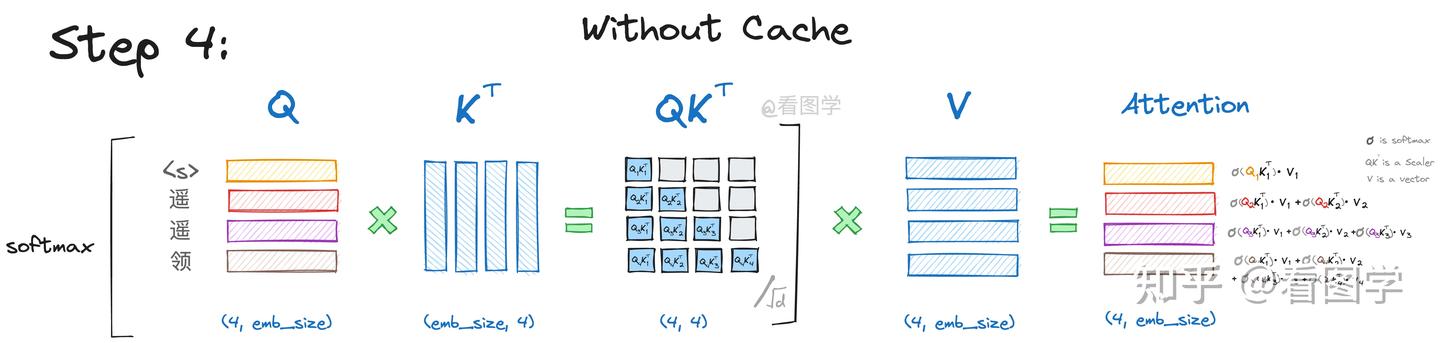
和之前类似,不再赘述。
看上面图和公式,我们可以得出结论:
- 当前计算方式存在大量冗余计算。
只与 有关。 - 推理第
个字符的时候只需要输入字符 即可。
我们每一步其实之需要根据
下面4张图展示了使用KV Cache和不使用的对比。
下面是gpt里面KV Cache的实现。其实明白了原理后代码实现简单的不得了,就是concat操作而已。
if layer_past is not None:
past_key, past_value = layer_past
key = torch.cat((past_key, key), dim=-2)
value = torch.cat((past_value, value), dim=-2)
if use_cache is True:
present = (key, value)
else:
present = None
if self.reorder_and_upcast_attn:
attn_output, attn_weights = self._upcast_and_reordered_attn(query, key, value, attention_mask, head_mask)
else:
attn_output, attn_weights = self._attn(query, key, value, attention_mask, head_mask)
2
3
4
5
6
7
8
9
10
11
12
13
14
最后需要注意当sequence特别长的时候,KV Cache其实还是个Memory刺客。
比如batch_size=32, head=32, layer=32, dim_size=4096, seq_length=2048, float32类型,则需要占用的显存为(感谢网友指正) 2 * 32 * 4096 * 2048 * 32 * 4 / 1024/1024/1024 /1024 = 64G。
前几天,幻方发布的DeepSeek-V2 (opens new window)引起了大家的热烈讨论。首先,最让人哗然的是1块钱100万token的价格,普遍比现有的各种竞品API便宜了两个数量级,以至于有人调侃“这个价格哪怕它输出乱码,我也会认为这个乱码是一种艺术”;其次,从模型的技术报告看,如此便宜的价格背后的关键技术之一是它新提出的MLA(Multi-head Latent Attention),这是对GQA的改进,据说能比GQA更省更好,也引起了读者的广泛关注。
MHA
MHA(Multi-Head Attention),也就是多头注意力,是开山之作《Attention is all you need》 (opens new window)所提出的一种Attention形式,可以说它是当前主流LLM的基础工作。在数学上,多头注意力MHA等价于多个独立的单头注意力的拼接,假设输入的(行)向量序列为
简单起见,这里省略了Attention矩阵的缩放因子。实践上,常见的设置是
由于这里只考虑了主流的自回归LLM所用的Causal Attention,因此在token by token递归生成时,新预测出来的第
而后面的MQA、GQA、MLA,都是围绕“如何减少KV Cache同时尽可能地保证效果”这个主题发展而来的产物。
瓶颈
一个自然的问题是:为什么降低KV Cache的大小如此重要?
众所周知,一般情况下LLM的推理都是在GPU上进行,单张GPU的显存是有限的,一部分我们要用来存放模型的参数和前向计算的激活值,这部分依赖于模型的体量,选定模型后它就是个常数;另外一部分我们要用来存放模型的KV Cache,这部分不仅依赖于模型的体量,还依赖于模型的输入长度,也就是在推理过程中是动态增长的,当Context长度足够长时,它的大小就会占主导地位,可能超出一张卡甚至一台机(8张卡)的总显存量。
在GPU上部署模型的原则是:能一张卡部署的,就不要跨多张卡;能一台机部署的,就不要跨多台机。这是因为“卡内通信带宽 > 卡间通信带宽 > 机间通信带宽”,由于“木桶效应”,模型部署时跨的设备越多,受设备间通信带宽的的“拖累”就越大,事实上即便是单卡H100内SRAM与HBM的带宽已经达到了3TB/s,但对于Short Context来说这个速度依然还是推理的瓶颈,更不用说更慢的卡间、机间通信了。
所以,减少KV Cache的目的就是要实现在更少的设备上推理更长的Context,或者在相同的Context长度下让推理的batch size更大,从而实现更快的推理速度或者更大的吞吐总量。当然,最终目的都是为了实现更低的推理成本。
要想更详细地了解这个问题,读者可以进一步阅读《FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness》 (opens new window)、《A guide to LLM inference and performance》 (opens new window)、《LLM inference speed of light》 (opens new window)等文章。
MQA
MQA,即“Multi-Query Attention”,是减少KV Cache的一次非常朴素的尝试,首次提出自《Fast Transformer Decoding: One Write-Head is All You Need》 (opens new window),这已经是2019年的论文了,这也意味着早在LLM火热之前,减少KV Cache就已经是研究人员非常关注的一个课题了。
MQA的思路很简单,直接让所有Attention Head共享同一个K、V,用公式来说,就是取消MHA所有的
使用MQA的模型包括PaLM (opens new window)、StarCoder (opens new window)、Gemini (opens new window)等。很明显,MQA直接将KV Cache减少到了原来的
效果方面,目前看来大部分任务的损失都比较有限,且MQA的支持者相信这部分损失可以通过进一步训练来弥补回。此外,注意到MQA由于共享了K、V,将会导致Attention的参数量减少了将近一半,而为了模型总参数量的不变,通常会相应地增大FFN/GLU的规模,这也能弥补一部分效果损失。
GQA
然而,也有人担心MQA对KV Cache的压缩太严重,以至于会影响模型的学习效率以及最终效果。为此,一个MHA与MQA之间的过渡版本GQA(Grouped-Query Attention)应运而生,出自论文《GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints》 (opens new window),是去年的工作。
事后看来,GQA的思想也很朴素,它就是将所有Head分为
这里的
在llama2/3-70B中,GQA的
MLA
有了MHA、MQA、GQA的铺垫,我们理解MLA(Multi-head Latent Attention)就相对容易一些了。DeepSeek-V2的技术报告里是从低秩投影的角度引入MLA的,以至于有部分读者提出“为什么LoRA提出这么久了,直到MLA才提出对KV Cache低秩分解的做法”之类的疑问。
然而,笔者认为低秩投影这个角度并不贴近本质,因为要说低秩投影的话,事实上只要我们将GQA的所有K、V叠在一起,就会发现GQA也相当于在做低秩投影:
这里我们将所有
Part 1
GQA在投影之后做了什么呢?首先它将向量对半分为两份分别作为K、V,然后每一份又均分为
然而,理论上这样是能增加模型能力,但别忘了GQA的主要目的是减少KV Cache,出于节省计算和通信成本的考虑,我们一般会缓存的是投影后的
对此,MLA发现,我们可以结合Dot-Attention的具体形式,通过一个简单但不失巧妙的恒等变换来规避这个问题。首先,在训练阶段还是照常进行,此时优化空间不大;然后,在推理阶段,我们利用
这意味着推理阶段,我们可以将
再次强调,本文的主题是一直都是减少KV Cache,那到目前为止,MLA做到了什么呢?答案是通过不同的投影矩阵来增强了GQA的能力,并且推理时可以保持同样大小的KV Cache。那么反过来,如果我们只需要跟GQA相近的能力,那么是不是就可以再次减少KV Cache了?换言之,
(注:这里有一个细节,就是
Part 2
一切似乎都很完美,看上去一个又好又省的理想设计就要出炉了。不过别急,当我们再深入思考一下就会发现,到目前为止的MLA有一个难以绕开的缺陷——不兼容RoPE(旋转位置编码) (opens new window)。
刚才我们说了,MLA之所以能保持跟GQA一样大小的KV Cache,其关键一步是“将
这里的
前段时间,笔者也很荣幸跟DeepSeek团队讨论过这个问题,但这个问题可以说非常本质,所以当时笔者实际上也没能提出什么有效的建议。最简单的方式是放弃RoPE,换用其他基于Attention Bias的位置编码,如ALIBI (opens new window),但DeepSeek的实验显示它明显不如RoPE(注意,MLA不是不能加RoPE,而是加了RoPE之后无法用恒等变换技巧来减少KV Cache),笔者也提议过换Sandwich (opens new window),它不像ALIBI单调衰减到负无穷,估计效果会好些,但感觉是治标不治本。还有一个折中的办法是将
这样
最后发布的MLA,采取了一种混合的方法——每个Attention Head的Q、K新增
这样一来,没有RoPE的维度就可以重复“Part 1”的操作,在推理时KV Cache只需要存
Part 3
最后有一个细节,就是MLA的最终版本,还将Q的输入也改为了低秩投影形式,这与减少KV Cache无关,主要是为了减少训练期间参数量和相应的梯度(原论文说的是激活值,个人表示不大理解)所占的显存:
注意
可以发现,其实在训练阶段,除了多了一步低秩投影以及只在部分维度加RoPE外,MLA与Q、K的Head Size由
推理阶段的MLA则改为
此时Q、K的Head Size变成了
那为什么还能提高推理效率呢?这又回到“瓶颈”一节所讨论的问题了,我们可以将LLM的推理分两部分:第一个Token的生成(Prefill)和后续每个Token的生成(Generation),Prefill阶段涉及到对输入所有Token的并行计算,然后把对应的KV Cache存下来,这部分对于计算、带宽和显存都是瓶颈,MLA虽然增大了计算量,但KV Cache的减少也降低了显存和带宽的压力,大家半斤八两;但是Generation阶段由于每步只计算一个Token,实际上它更多的是带宽瓶颈和显存瓶颈,因此MLA的引入理论上能明显提高Generation的速度。
还有一个细节充分体现了这个特性。一般的LLM架构参数满足
小结
本文简单概述了多头注意力的演变历程,特别是从MHA向MQA、GQA,最终到MLA的变化理念,最后详细展开了对MLA的介绍。在本文中,MLA被视为GQA的一般化,它用投影矩阵的方式替代了GQA的分割、重复,并引入了一个恒等变换技巧来可以进一步压缩KV Cache,同时采用了一种混合方法来兼容RoPE。总的来说,MLA称得上是一种非常实用的注意力变体。