统计量及其分布
统计量及其分布
统计量及其分布
总体与样本
总体
在一个统计问题里,研究对象的全体叫做总体,构成总体的每个成员称为个体。根据个体的数量指标数量,定义总体的维度,如每个个体只有一个数量指标,总体就是一维的,同理,个体有两个数量指标,总体就是二维的。总体就是一个分布,数量指标就是服从这个分布的随机变量。 总体根据个体数分为有限总体和无限总体,当有限总体的个体数充分大时,其可以看为无限总体。
样本
- 定义:
从总体中随机抽取的部分个体组成的集合称为样本,样本个数称为样本容量。
性质:
二重性:抽取前随机,是随机变量;抽取后确定,是一组数值。
随机性:每个个体都有同等的机会被选入样本。
独立性:每个样本的取值不影响其他样本取值,即分部独立。
满足后面两个性质称为简单随机样本,则
分组样本
只知样本观测值所在区间,而不知具体值的样本称为分组样本。缺点:与完全样本相比损失部分信息。优点:在样本量较大时,用分组样本既简明扼要,又能帮助人们更好地认识总体。
样本数据的整理与显示
经验分布函数
若将样本观测值
小到大进行排列,得到有序样本 ,用有序样本定义如下函数 则称为
该样本的经验分布函数。 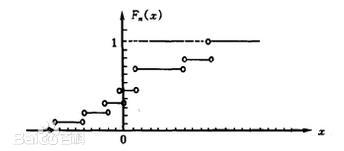
格里纹科定理
设
取自总体分布函数为 样本, 该样本的经验分布函数,则当 ,有 表明当 n 相当大时,经验分布函数
总体分布函数 一个良好的近似。它是经典统计学的一块基石。 频数频率分布表
有样本
作频数频率分布表的操作步骤如下: - 确定组数 k;
- 确定每组组距,通常取每组组距相等为 d(方便起见,可选为整数);
- 确定组限(下限
小于最小观测值,上限 大于最大观测值); - 统计样本数据落入每个区间的频数,并计算频率。
该表能够简明扼要地把样本特点表示出来。不足之处是该表依赖于分组,不同的分组方式有不同的频数频率分布表。
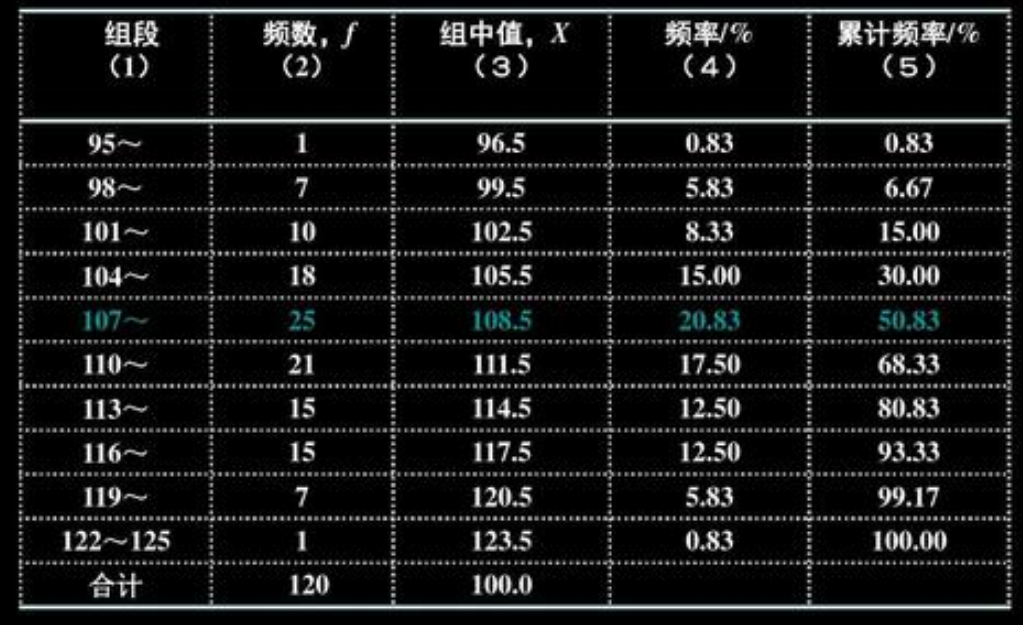
直方图
- 利用频数频率分布表上的区间(横坐标)和频数(纵坐标)可作为频数直方图;
- 若把纵坐标改为频率就得频率直方图;
- 若把纵坐标改为频率/组距,就得到单位频率直方图。这时长条矩形的面积之和为 1.
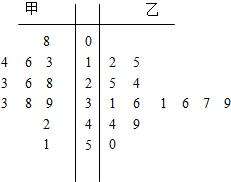
茎叶图
把样本中的每个数据分为茎与叶,把茎放于一侧,叶放于另一侧,就得到一张该样本的茎叶图。比较两个样本时,可画出背靠背的茎叶图。茎叶图保留数据中全部信息,当样本量较大,数据很分散,横跨二、三个数量级时,茎叶图并不适用。
统计量及其分布
统计量
不含未知参数的样本函数称为统计量。统计量的分布称为抽样分布。
样本均值
定义:
样本
算数平均值称为样本均值,记为 .分组样本均值 ,其中 n 为样本量,k 为组数, 第 i 组的组中值和频率,分组样本均值是完全样本均值的一种较好的近似。 样本均值是样本的位置特征,样本中大多数值位于
右。平均可消除一些随机干扰,等价交换也是在平均数中实现的。 性质:
,样本数据 样本均值 偏差之和为零; - 样本数据
样本均值 偏差平方和最小,即对任意的实数 c 有 ; - 若总体分布为
,则 精确分布为 ; - 若总体分布未知,但其期望
方差 在,则当 n 较大时, 渐进分布为 ,这里渐进分布是指 n 较大时的近似分布。
样本方差与样本标准差
样本方差有两种,
,后者为无偏方差,也是最常用的。(这是因为当 总体方差时,总有 , ,表明 系统偏小的误差, 此系统偏差。)称 样本标准差。 样本方差是样本的散布特征,
越大样本越分散, 小分布越集中,样本标准差比样本方差使用更频繁,因为前者和样本均值有着相同的单位。 计算有如下三个公式可供选用: 在分组样本场合,样本方差的近似计算公式为
其中 k 为组数,
别为第 i 个区间的组中值与频数, 分组样本的均值。 样本矩及其函数
- 样本的 k 阶原点矩
,样本均值 样本的一阶原点矩; - 样本的 k 阶中心距
,样本方差 为样本的二阶中心矩; - 样本变异系数
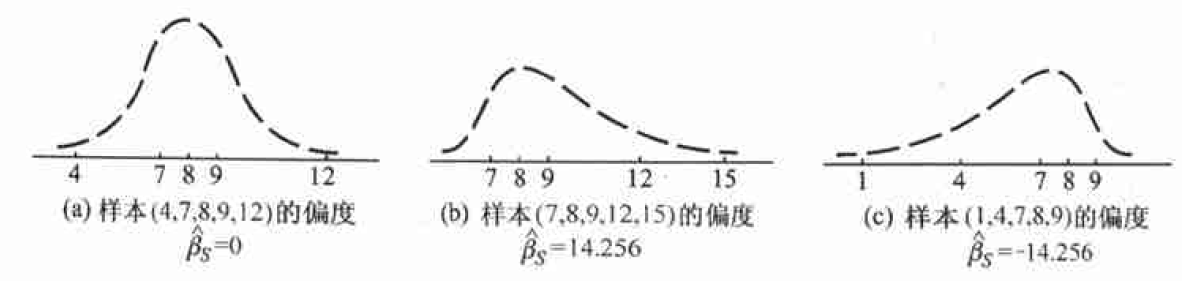
; - 样本的偏度
,反映样本数据与对称性偏离程度和偏离方向; - 样本的峰度
,反映总体分布密度曲线在其峰值附近的陡峭程度和尾部粗细.
- 样本的 k 阶原点矩
次序统计量及其分布
设
取自某总体的一个样本, 为该样本的第 i 个次序统计量(升序排序后,第 i 个样本)。 为该样本的最小次序统计量; 为该样本的最大次序统计量; 为该样本的次序统计量,即不独立也不同分布; 为样本极差。 设总体 密度函数为 ,分布函数为 , 样本,则有 - 样本第 k 个次序统计量
密度函数为
- 样本第 i 个与第 j 个次序统计量的联合密度函数为
样本中位数与样本分位数
设
取自某总体的样本, 该样本的次序统计量,则样本中位数 义为 样本的 p 分位数
义为 其中[x]表示向下取整。中位数对样本的极端值有抗干扰性,或称有稳健性。 样本分位数的渐近分布:设总体的密度函数为
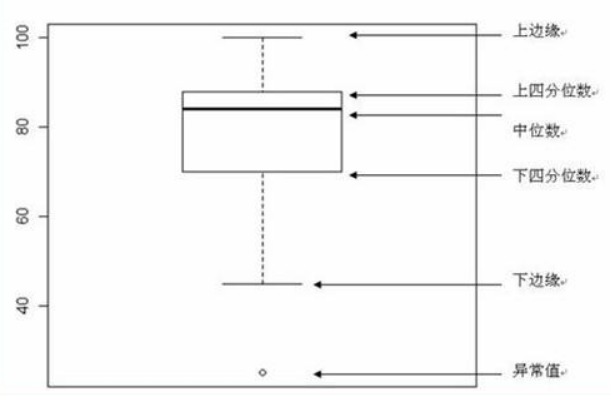
, 总体的 p 分位数。若 连续且 ,则当 n 充分大时,有 五数概括与箱线图
五数指用样本的五个次序统计量,即最小观测值,最大观测值,中位数,第一 4 分位数和第三 4 分位数。其图形为箱线图,可描述样本分布形状。