 ASP
ASP
0. 摘要
少样本类增量学习(Few-Shot Class-Incremental Learning,FSCIL)模型旨在在保留旧类知识的同时,利用稀缺样本逐步学习新类别。现有的 FSCIL 方法通常对整个骨干网络进行微调,导致过拟合,从而阻碍新类的学习潜力。另一方面,近年来的基于提示(prompt)的 CIL 方法在每个任务中利用充足的数据训练提示,从而缓解遗忘问题。
在本工作中,我们提出了一种新颖的框架,称为“注意力感知自适应提示(Attention-aware Self-adaptive Prompt,ASP)”。ASP 通过从注意力机制角度减少特定信息,鼓励任务无关提示捕捉共享知识。此外,ASP 中的自适应任务特定提示在信息瓶颈(Information Bottleneck)学习目标的引导下,提供特定信息并将旧类知识迁移到新类。
总之,ASP 避免了对基础任务的过拟合,也不需要在少样本增量任务中依赖大量数据。我们在三个基准数据集上进行了广泛实验,验证了 ASP 在学习新类和减缓遗忘方面,始终优于最先进的 FSCIL 方法和基于提示的 CIL 方法。源代码地址:https://github.com/DawnLIU35/FSCIL-ASP。
1. 引言
随着世界不断变化,现实中的数据也在不断演变。因此,机器学习模型需要跟随数据的变化持续学习新类别,同时保留从先前数据中学到的知识,这被称为类增量学习(Class-Incremental Learning,CIL)【26,42,51,56】。CIL 的主要挑战是灾难性遗忘问题(Catastrophic Forgetting)【11,52】:当模型在新任务上训练后,由于无法完全获取旧任务的数据(例如因存储空间有限或隐私问题【8,45】),会遗忘之前的知识。
尽管许多 CIL 方法假设每个新类都能持续获得充足样本进行训练【12,22,24】,但这一假设在许多现实应用中并不成立。例如,在智能医疗决策系统中,系统需跟踪生理信号并学习新病人信息,而每个新病人仅有有限数据,同时还需保留现有病人数据的知识【38】。这种在有限数据下持续学习新类的任务被称为少样本类增量学习(Few-Shot Class-Incremental Learning,FSCIL)【39,41】。
FSCIL 通常包括:首先使用充足样本训练一个基础模型;随后利用从基础类学到的知识增量学习新类,而这些新类样本非常有限。除了灾难性遗忘的挑战外,FSCIL 还面临着因训练样本过少导致的过拟合问题,从而进一步阻碍模型对新类的学习。
各种研究【41】已被提出以应对 FSCIL 场景。其中一些工作专注于提升基础模型对新出现的少样本类别的泛化能力【6, 33, 63】,而其他研究则致力于寻找在有限数据下对新任务进行增量训练的更优策略【5, 9, 20, 50】。然而,大多数现有方法会对基础模型中的所有参数进行微调,这会导致基础类上的过拟合,并阻碍模型对新类的可迁移性。
另一方面,近期的基于提示的 CIL 方法【34, 53, 54】利用了预训练视觉 Transformer(Vision Transformer,ViT)【10】所固有的泛化能力,通过固定骨干参数,仅训练少量称为“提示(prompts)”的新参数。它们通常通过键 - 查询(key-query)机制学习任务特定提示,并将已见任务的知识存储在专门的提示池中。通过这种方式,它们无需使用旧数据样本的回放缓存(rehearsal buffer)即可保留旧任务的知识。
然而,为了训练任务特定提示,这些基于提示的方法仍然需要从新任务中获得充足的数据样本,而这在少样本增量学习任务中并不具备。
在本文中,我们提出了一种新颖的框架,称为注意力感知自适应提示(Attention-Aware Self-Adaptive Prompt,ASP),以克服现有 FSCIL 和基于提示的 CIL 方法在 FSCIL 设定下的不足。
ASP 旨在利用预训练 ViT 的内在泛化能力以及从充足的基础类中学到的知识,促进在有限数据下对新类的持续学习。具体而言,ASP 固定 ViT 骨干网络,在注意力模块之间引入提示,以适配 FSCIL 任务,其中提示被分解为:
- 注意力感知任务无关提示(Task-Invariant Prompts,TIP),以及
- 自适应任务特定提示(Task-Specific Prompts,TSP)。
注意力模块对每个 TIP 给予相同的关注,无论具体任务为何,从而鼓励 TIP 仅包含可以在基础类与新类之间通用的任务无关信息。
与以往的键 - 查询机制不同,ASP 使用一个**提示编码器(prompt encoder)**将输入图像转换为提示特征。受信息瓶颈(Information Bottleneck,IB)理论【2】的启发,ASP 引导提示编码器生成与语义信息高度相关、与图像中冗余信息弱相关的提示特征。
为了进一步提升泛化能力,ASP 在整个训练集上聚合提示特征,以避免对单个图像的过拟合。对于某个特定输入图像,其对应的 TSP 由平均提示特征和其自身提示特征共同组成。
因此,ASP 避免了对整个骨干网络的微调,缓解了过拟合问题,也避免了在训练新类 TSP 时对大量数据的依赖。
最后,为了进一步提升模型判别能力,ASP 引入了一种基于相似性的损失函数,用于将特征向量聚集到其类别中心。类别中心则由训练期间的锚点样本(anchor samples)估计而得。
我们工作的主要贡献如下:
我们提出了 ASP,这是一种创新的基于提示的方法,可同时应对现有 FSCIL 方法中的过拟合问题,以及基于提示方法在 FSCIL 情景下对数据需求过高的问题。
我们设计了注意力感知的 TIP和自适应的 TSP,以实现从基础类到新类的知识迁移,并减缓对旧类的遗忘。
我们在三个基准数据集上进行了大量实验,表明 ASP 在学习新类和保留旧类性能方面显著优于最先进的 FSCIL 和基于提示的 CIL 方法。
2. 相关工作
2.1 类增量学习(Class-Incremental Learning)
非基于提示的方法:
通常,增量学习可分为三种不同的设置:任务增量(TIL)、领域增量(DIL)和类增量学习(CIL)【42】。在这三者中,CIL 被认为是最具挑战性的场景【41】,要求在学习新类别的同时不遗忘旧类别。
当前的 CIL 研究主要沿着三个方向展开。
- 最有效的方向是重放方法(rehearsal methods)【4, 30, 31, 48, 49】,它们建立一个重放缓冲区用于存储之前任务的样本;
- 第二种方法试图识别当前任务中的重要参数,并在增量任务中防止其发生变化【3, 18, 58】;
- 此外,还有大量方法利用知识蒸馏技术来保留先前任务的知识,从而克服遗忘问题【14, 22, 30】。
近年来,部分无重放(rehearsal-free)方法【25, 53】开始受到关注,因为在实际应用中并不总是允许存储重放样本【54】。值得注意的是,ASP 同样不需要重放缓冲区来存储任何数据样本。
通常,CIL 方法在每个增量任务中都需要足够的训练数据来学习新类别,但这在 FSCIL 情境下并不成立。
基于提示的方法:
提示学习方法(prompt-based methods)【21, 55】最初被提出用于自然语言处理任务,以更好地利用预训练知识完成下游任务。其基本思想是:固定骨干网络参数,仅微调一小部分新参数(即“提示”),这些提示被添加到输入文本或图像之前【16】。
近期,使用 ViT 骨干的基于提示的 CIL 方法在学习新类别和防止灾难性遗忘方面取得了显著表现。
- L2P【54】最早提出使用键 - 查询机制,从提示池中选择任务特定提示;
- DualP【53】引入任务无关提示(TIP)以捕捉不同任务之间的共享信息。但其 TIP 仍包含过多任务特定信息,TSP 则需要在增量任务中用充足数据进行训练。这种做法在新任务样本有限的情况下,容易对少样本任务发生严重过拟合,从而最终导致 FSCIL 性能下降;
- 随后,CodaP【34】提出端到端地训练提示池及其选择机制;
- 最新的 HideP【46】则将 CIL 分解为多个层次组件并分别优化。
然而,所有现有的基于提示的 CIL 方法都不适用于 FSCIL 情境,因为它们都需要在增量任务中使用足够样本来捕捉任务特定知识并将其存储于提示中。与此相反,ASP 无需为新任务训练新的 TSP,因此在少样本增量任务中效果良好。
3. 预备知识(Preliminaries)
少样本类增量学习旨在通过其各自的数据
其中
第一个任务(基础任务)具有充足的训练数据
FSCIL 模型可拆分为一个骨干网络
使其与真实类别一致。
视觉任务的基于提示方法通常采用预训练的视觉 Transformer(ViT)【10】作为骨干网络
ViT 模型包含多个多头自注意力(Multi-Head Self-Attention,MSA)层。设第
其中
提示微调(Prompt Tuning, ProT)【16, 21】是一种常用方法,其在第
其中
在 ViT 的第一个层之前,输入图像被分割为若干 patch,并转化为序列形式
原型网络(Prototypical Network)【35】广泛用于少样本学习问题。它计算类别
其中
对于一个包含
根据【47, 61】,新类原型会被追加到
4. 方法(Methodology)
具有良好泛化能力的基础模型有助于适应少样本的新类别【36, 61】。为了防止基础类过拟合并利用预训练 ViT 的泛化能力来在有限数据下学习新类别,ASP 固定预训练的骨干网络,并学习可迁移基础类知识到新类的提示。受 DualP【53】启发,我们将提示分解为:
- 注意力感知的任务无关提示(Task-Invariant Prompts,TIP)
- 自适应的任务特定提示(Task-Specific Prompts,TSP)
在第 4.1 节中,ASP 保持所有 TIP 在不同任务中拥有一致的注意力,从而包含最小的任务特定信息;
在第 4.2 节中,ASP 使用提示编码器(prompt encoder)将输入图像映射为 TSP,并结合信息瓶颈(IB)理论增强其泛化能力【23】。
因此,该提示编码器也可以用于新类数据,无需额外训练。
最后,在第 4.3 节中,我们引入锚点损失(Anchor Loss),通过将类特征拉向其类别中心,进一步增强模型判别能力。
ASP 仅在基础任务上使用充足数据进行训练,随后在少样本增量任务中利用公式 (11) 更新提示。我们的整体训练流程如图 1 所示。
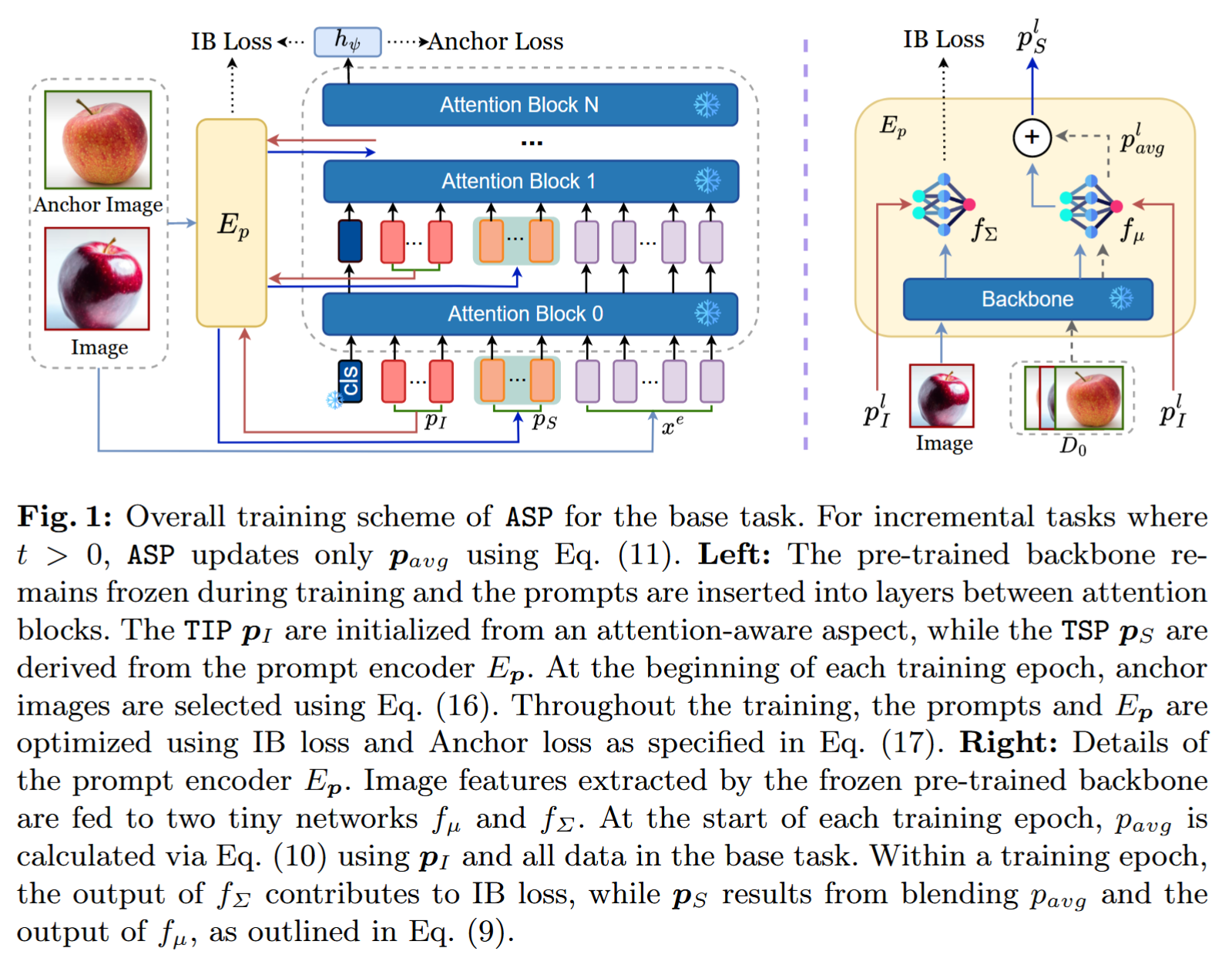
4.1 注意力感知任务无关提示(Attention-Aware Task-Invariant Prompts)
类似 DualP【53】,任务无关提示在基础类训练后固定,用于后续少样本增量任务。尽管 DualP 为所有任务使用相同的 TIP,但由于每个提示标记的注意力差异,它们在不同任务中并不传递完全相同的信息。因此,这些提示实际上仍然携带任务特定的信息。
为减少提示中的任务特定信息,ASP 鼓励对每个提示标记的注意力保持一致。注意力矩阵定义为:
设第
注意力取决于提示标记的值。若两个提示标记值相同,则可保证其注意力一致。最简单的方式是在训练前将每个提示标记初始化为相同的值,这些值在梯度下降优化过程中将保持不变【32】。
在基础类训练中,我们使用提示
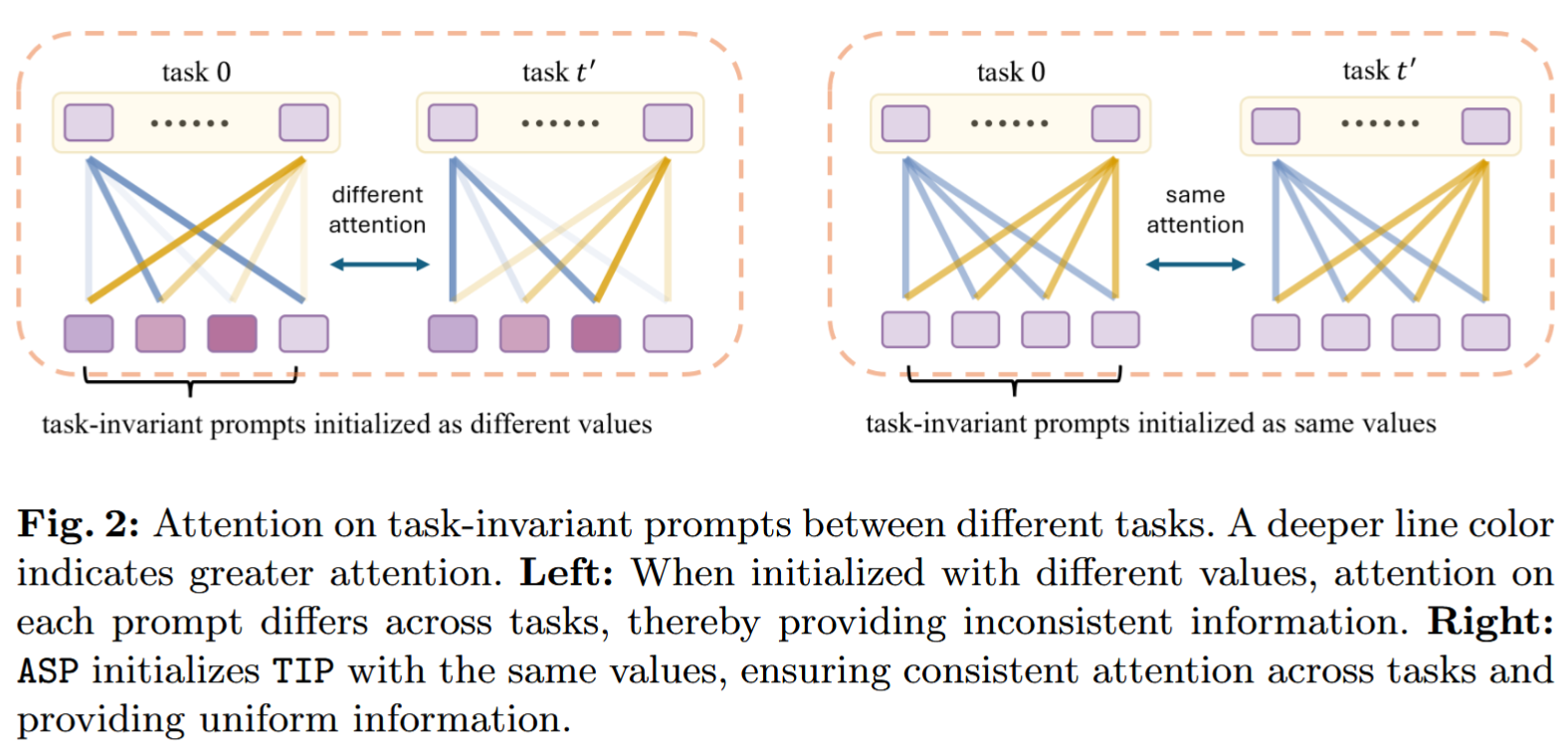
由于
在训练基础类后,TIP 在后续少样本增量任务中保持固定。
4.2 自适应任务特定提示(Self-Adaptive Task-Specific Prompts)
仅依赖 TIP 可能会导致欠拟合,因为它只考虑了不同任务的共享属性,忽略了独有特征。为将任务特定信息融入提示,先前研究【53, 54】采用键 - 查询机制,根据输入图像生成任务特定提示。然而,这些方法需要大量训练数据来捕获这些信息。
相比之下,ASP 使用一个紧凑的神经网络作为提示编码器
提示学习目标:
受 IB 理论【2】启发,我们提出以下提示学习目标:
其中随机变量
该损失中:
- 最大化
强化提示与语义信息的相关性; - 最小化
抑制输入中的冗余信息影响提示,从而提升泛化性。
由于直接计算互信息不可行(通常需要对联合分布积分),我们采用变分推断进行近似,其下界为:
其中
我们接下来介绍 Eq. (7) 的计算方法。近似联合分布
其中
假设提示编码器满足:
即通过两个全连接网络
我们使用提示编码器
在基础类训练阶段,第
其中
在第
其中
最终,第
4.3 锚点损失(Anchor Loss)
在基础类训练阶段,我们的目标是训练一个特征提取器,使其满足以下两个条件:
- 最大化类别间特征嵌入的距离;
- 最小化类别内特征嵌入的距离。
此外,我们还希望得到一个分类器头
按照【28, 47】的做法,我们使用一个无偏置项的全连接层作为分类器头
其中
为了区分类别特征和原型,我们在 Eq. (8) 中采用交叉熵损失函数:
该损失函数的作用是:
- 拉近特征
与其类别原型 ; - 同时推远它与其他类别的原型
, 。
然而,只有“拉近”的操作是准确的,而“推远”的操作可能会使得类别原型远离类别均值,从而导致错误分类。与以往工作类似【47, 62】,我们在基础类训练结束后,用类别均值
因此,有必要将类别特征对齐到其类别均值,从而为新类别保留足够表示空间,以提升新类的准确性【36, 61】。
对于任意输入样本,我们最大化其特征与对应类别均值之间的余弦相似度:
由于训练过程中类别均值不断变化,在每个小批量之后重新计算它们的成本较高。因此,我们使用锚点样本(anchor sample)来估算类别均值。
在每个训练周期开始时,先计算精确的类别均值,然后选择与该均值最相似的样本作为该类别的锚点样本:
接着使用该锚点的特征向量作为类别均值的估计值,即:
最终的训练损失函数为:
其中
5. 实验(Experiments)
在本节中,我们首先介绍 FSCIL 的实验细节,包括数据集、评估协议、训练细节以及对比方法。随后,我们在三个基准数据集上比较 ASP 与各类基准方法的性能,展示 ASP 的有效性。此外,我们还进行了消融实验验证 ASP 中各组件的贡献,最后提供更多实验结果以供进一步分析。我们将在论文接收后公开代码。
5.1 实现细节(Implementation Details)
数据集:
遵循 FSCIL 研究【47, 61】和基于提示的 CIL 研究【37, 46, 53】,我们在三个数据集上评估 ASP 的性能: CIFAR100【19】、CUB200-2011【43】、ImageNet-R【13】
具体设置如下:
- CIFAR100 被划分为 60 个基础类和 40 个新类。新类进一步划分为 8 个任务,每个任务包含 5 个类别,每类 5 个样本(即 5-way 5-shot);
- CUB200 和 ImageNet-R 分别以 100 个类构成基础任务,剩余 100 个类则划分为 10 个任务,每个任务为 10-way 5-shot。
评估协议:
遵循以往研究【6, 39, 61】,我们记录第
- 平均准确率定义为
,用于衡量模型整体性能; - 遗忘率(performance dropping rate, PD)定义为
,用于衡量灾难性遗忘程度; - 调和准确率(Harmonic Accuracy, HAcc)【28】用于衡量模型在基础类与新类之间的平衡性,定义为:
其中
训练细节:
所有实验使用 PyTorch【27】在 NVIDIA RTX A6000 GPU 上进行。我们采用【34, 62】的设置,选择使用在 ImageNet1K 上预训练的 ViT-B/16 作为骨干网络
- 所有图像被统一调整为 224×224;
- 使用 SGD 优化器,训练 20 个 epoch;
- 学习率设为 0.01(CIFAR100 和 CUB200),ImageNet-R 使用 0.03;
- 批量大小:CIFAR100 为 48,CUB200 和 ImageNet-R 为 24。
提示长度设置如下:
- ImageNet-R 使用
; - CIFAR100 与 CUB200 使用
。
所有实验使用三个随机种子进行重复实验,最终结果取平均。
对比方法:
我们首先比较两种经典 CIL 方法:
- iCaRL【30】
- Foster【44】
此外,还对比三种最先进的 FSCIL 方法:
- CEC【59】
- FACT【61】
- TEEN【47】
最后,比较三种最新的基于提示的 CIL 方法:
- L2P【54】
- DualP【53】
- CodaP【34】
5.2 基准对比(Benchmark Comparisons)
在本节中,我们报告 ASP 与多种基准方法在 FSCIL 设定下的性能表现。对于 CIFAR100 和 ImageNet-R,我们在表 1 和表 2 中展示了每个任务的详细准确率(Top-1 accuracy
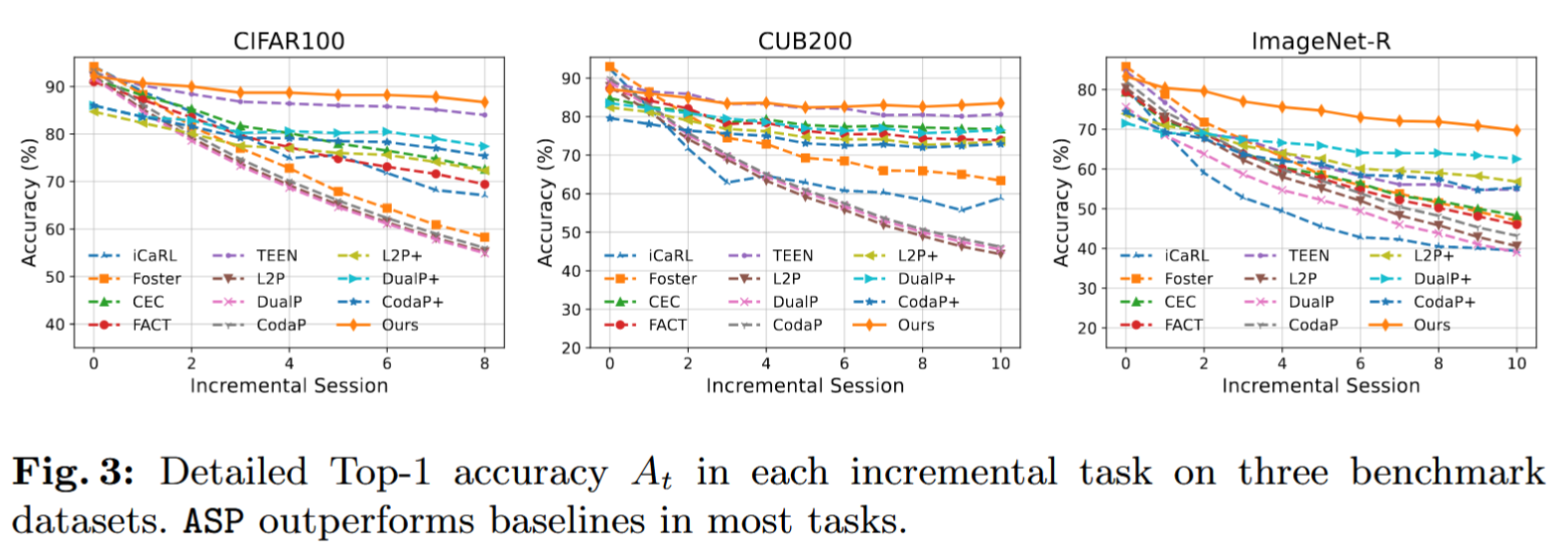
在 CIFAR100、CUB200 和 ImageNet-R 三个数据集上的实验结果显示:
- ASP 在最后一个任务的 Top-1 准确率
分别达到 86.7%、83.5% 和 69.7%,相比排名第二的方法分别高出 2.7%、2.9% 和 7.2%; - 除了第一个任务外,ASP 在多数增量任务中表现最佳。之所以在第一个任务中略逊,是因为经典 CIL 和 FSCIL 方法会使用充足数据对所有参数进行微调,因此合理地获得更高起始性能;
- ASP 在平均准确率
上同样表现优异,在三个数据集上分别为 89.0%、83.8%、75.3%,分别高出排名第二方法 1.7%、0.7%、9.2%; - 在**性能下降率(PD)**方面,ASP 在 CIFAR100 和 CUB200 上取得最低值,在 ImageNet-R 上排名第二;
- 在**调和准确率(HAcc)**方面,ASP 在三个数据集上均为最佳,分别达到 85.3%、83.4%、67.0%,表明 ASP 在持续学习新类的同时,也能良好保留基础类性能。
一个有趣的发现是,原始的基于提示的 CIL 方法在 HAcc 指标上几乎无法学习新类。我们认为其主要原因是:分类器头为全连接层,极易对少样本数据发生严重过拟合。因此,我们将原始分类器替换为类均值构建的原型网络,分别命名为 L2P+、DualP+ 和 CodaP+。 从表 1 和表 2 中的 HAcc 结果可以看出,这种改动显著提高了其在 FSCIL 设定下学习新类的能力。
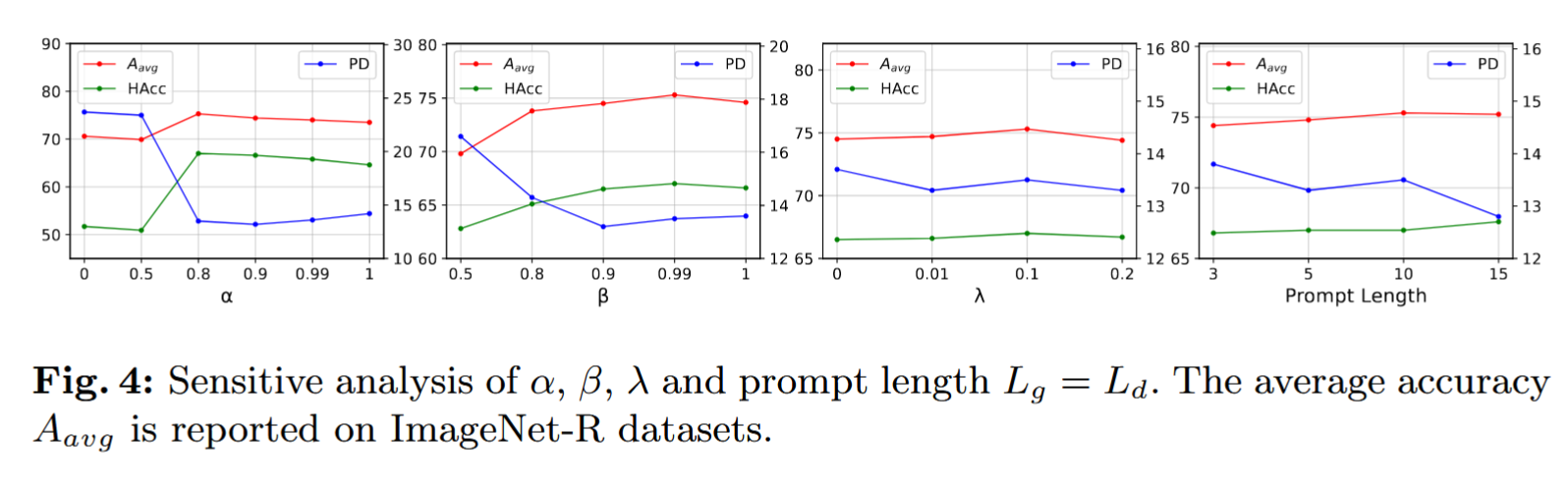
5.3 消融实验(Ablation Study)
我们在 CIFAR100 上进行消融实验,以验证 ASP 中各模块的贡献。我们将 ASP 的训练拆解为五个模块:
TIP-Base:只使用任务无关提示训练基础任务;
TIP+TSP:在 TIP-Base 的基础上加入任务特定提示;
TIP+TSP+IB:加入信息瓶颈目标,用于优化提示编码器;
TIP+TSP+IB+Avg:加入平均提示机制提升泛化性;
TIP+TSP+IB+Avg+AL (ASP):加入锚点损失,形成完整 ASP 模型。
结果如表 3 所示:
使用 TIP 训练基础任务(TIP-Base)后保持其冻结,并在增量任务中添加 TSP(TIP+TSP),显著提升了新类性能;加入 IB 目标后,进一步提升了模型的泛化能力,说明该正则项能有效引导提示向语义相关方向压缩;平均提示(Avg)引入后,新类准确率继续上升,验证其在防止过拟合方面的有效性;最终加入锚点损失(AL)后,基础类准确率提升明显,说明该模块能帮助特征聚类并构建更稳健的原型。
结论:ASP 中的每个模块均对最终性能提升起到了关键作用。
5.4 提示特征可视化(Prompt Visualization)
为了进一步验证 ASP 学习到的提示特征的泛化性,我们将 CIFAR100 中不同类样本在任务 10 训练结束后的提示特征
5.5 模型复杂度分析(Model Complexity)
我们比较了各类方法的训练参数量(Trainable Params)和训练时间(Training Time),结果如表 4 所示。
ASP 仅需训练提示编码器和提示参数,训练参数远少于需微调整个骨干的 FSCIL 方法;
同时,ASP 的训练时间也优于 L2P 和 DualP,说明 ASP 在效率和性能之间取得良好平衡。
6. 结论(Conclusion)
本文提出了一种新颖的注意力感知自适应提示方法(Attention-aware Self-Adaptive Prompt,ASP),以应对少样本类增量学习(FSCIL)任务。
ASP 固定了预训练的视觉 Transformer 骨干网络,避免了对基础类的过拟合,并设计了两个互补的提示模块:
- 任务无关提示(TIP):通过保持注意力一致性,学习基础类与新类之间共享的类无关知识;
- 任务特定提示(TSP):通过提示编码器在信息瓶颈目标的指导下学习,并引入平均提示机制,增强了对新类的泛化能力。
此外,ASP 引入锚点损失,引导模型学习判别性强且分布紧凑的特征表示。
我们在三个基准数据集上进行了大量实验,结果显示 ASP 在多个评估指标上均显著优于当前最先进的 FSCIL 方法和基于提示的 CIL 方法。