 LoRA-Pro
LoRA-Pro
文章解读
“LoRA-GA”通过梯度SVD来改进LoRA的初始化,从而实现LoRA与全量微调的对齐。当然,从理论上来讲,这样做也只能尽量对齐第一步更新后的
对齐全量
LoRA的参数化方式是
其中
和
其中
LoRA-GA的想法是,我们至少要让全量微调和LoRA的
其最优解可以通过对
逐步对齐
LoRA-Pro的想法更彻底,它希望对齐全量微调和LoRA的每一个
看上去已经没有能够让我们修改的地方了?不,LoRA-Pro非常机智地想到:既然“
其中
这时候我们就可以调整
下面我们来求解这个优化问题。简单起见,在求解过程中我们省略下标
简化目标
由于
其中
其中
然后让它等于零就可以解出式
同理,
完整结果
有了结论
注意式
其中
代回目标函数得
根据式
留意到
最优参数
至此,我们求解出了
比如,现在
这个
第一个优化目标可以理解为让
令它等于零我们就可以解出同样的
LoRA-Pro选择的
这样做的意图也很明显:
现在我们得到关于
一般讨论
我们来捋一捋到目前为止我们所得到的结果。我们的模型还是常规的LoRA,目标则是希望每一步更新都能逼近全量微调的结果。为此,我们假设优化器是SGD,然后对比了同样
接下来就又回到优化分析中老生常谈的问题:前面的分析都是基于SGD优化器的,但实践中我们更常用的是Adam,此时要怎么改呢?如果对Adam优化器重复前面的推导,结果就是
不过我们也可以考虑一个近似的方案,前述
这也是LoRA-Pro最终所用的更新算法(更准确地说,LoRA-Pro用的是AdamW,结果稍复杂一些,但并无实质不同)。然而,且不说如此改动引入的额外复杂度如何,这个算法最大的问题就是它里边的滑动更新变量
一个比较简单的方案(但笔者没有实验过)就是直接用
实验结果
LoRA-Pro在GLUE上的实验结果更加惊艳,超过了全量微调的结果:
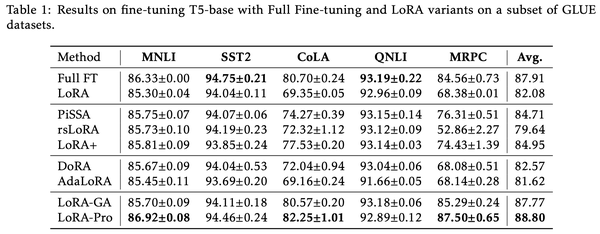
不过论文也就只有这个实验了。看上去LoRA-Pro成文比较仓促,可能是看到LoRA-GA后觉得“撞车”感太明显,所以先赶出来占个坑吧。笔者刚刷到LoRA-Pro时,第一反应也是跟LoRA-GA撞车了,但仔细阅读之下才发现,它跟LoRA-GA实际上是同一思想下互补的结果。
从LoRA-Pro的结果来看,它包含了
文章小结
本文介绍了另一个对齐全量微调的工作LoRA-Pro,它跟上一篇的LoRA-GA正好是互补的两个结果,LoRA-GA试图通过改进初始化来使得LoRA跟全量微调对齐,LoRA-Pro则更彻底一些,它通过修改优化器的更新规则来使得LoRA的每一步更新都尽量跟全量微调对齐,两者都是非常精彩的LoRA改进,都是让人赏心悦目之作。
ChatGPT全文翻译 ⬇️
0. 摘要
低秩适应(LoRA)已成为通过将原始矩阵重新参数化为两个低秩矩阵的乘积来进行参数高效微调基础模型的主要方法。尽管其效率较高,但 LoRA 的性能通常不如完整微调。本文提出了一种方法,称为 LoRA-Pro,以缩小这种性能差距。
首先,我们深入研究了 LoRA 和完整微调的优化过程。我们揭示了尽管 LoRA 采用低秩近似,但它忽略了完整微调的优化过程。为了解决这一问题,我们引入了一个新概念,称为“等效梯度”,该虚拟梯度使重新参数化矩阵的优化过程等效于 LoRA,并可用于量化 LoRA 与完整微调之间的差异。等效梯度是从矩阵 A 和 B 的梯度推导出的。为了缩小性能差距,我们的方法在优化过程中最小化等效梯度与从完整微调中获得的梯度之间的差异。通过解决该目标,我们推导出更新矩阵 A 和 B 的最优闭合解。我们的方法约束了优化过程,缩小了 LoRA 与完整微调之间的性能差距。
在自然语言处理任务上的广泛实验验证了我们方法的有效性。
1. 引言
基础模型 [1-5] 已经成为现代深度学习的基石。通过在大规模数据集上进行预训练,这些模型通常表现出卓越的泛化能力和多功能性。令人瞩目的是,某些基础模型甚至展示了突现属性 [6-7]。因此,基础模型已广泛应用于各种下游任务。
尽管这些优势明显,但基础模型庞大的参数数量限制了它们的广泛应用。庞大的参数量使得这些任务的微调成本非常高。为了应对此问题,近期研究集中在参数高效微调(PEFT)方法 [8-11]。PEFT 方法通过冻结基础模型并仅微调小规模的轻量化适配器,降低了微调成本。在大多数参数被冻结的情况下,PEFT 实现了更快的微调,并且需要更少的计算资源。
低秩适应 [8],也称为 LoRA,是最著名的 PEFT 方法之一,已在各个领域得到广泛采用。受以往工作的启发 [12-13],LoRA 假设模型适应过程中权重的变化表现出低秩结构。为了捕捉这一点,LoRA 通过将这些变化表示为两个低秩矩阵的乘积来重新参数化它们:
本文提出了一种新型 PEFT 方法,称为 LoRA-Pro,旨在缩小 LoRA 与完整微调之间的性能差距。尽管 LoRA 通过重新参数化权重变化为两个低秩矩阵的乘积来进行低秩近似,但它未能在优化过程中逼近完整微调。为了衡量它们在优化过程中的差异,我们提出了一种新颖的概念,即 LoRA 优化的“等效梯度”。等效梯度描述了低秩近似后原始矩阵的梯度(尽管它不可直接训练),由矩阵 A 和 B 的梯度组成。因此,在 LoRA 微调过程中,我们的目标不仅是用低秩矩阵逼近原始矩阵,还要在梯度下降过程中最小化等效梯度与完整微调梯度之间的差异。这是通过为矩阵 A 和 B 选择合适的梯度来实现的,确保微调过程更加准确和高效。为此,我们将其形式化为一个优化问题,然后推导出该问题的理论解,给出更新矩阵 A 和 B 的最优梯度解。这些解确保等效梯度与完整微调的优化动态密切匹配。通过这种方式,我们增强了 LoRA 的有效性,缩小了 LoRA 与完整微调之间的性能差距。
我们的主要贡献总结如下:
- 我们发现 LoRA 逼近了低秩矩阵,但未能逼近完整参数微调的优化过程。这一缺陷是 LoRA 与完整微调之间性能差距的原因之一。
- 我们引入了等效梯度的概念,使我们能够量化 LoRA 与完整微调之间的优化过程差异。通过最小化这种差异,我们推导出了 LoRA 的最优闭合更新解。
- 在自然语言处理任务上的广泛实验验证了我们方法的有效性。
2. 相关工作
2.1 参数高效微调
由于基础模型的巨大规模,近年来的研究重点集中在开发参数高效的微调方法 [8-11, 14-16]。这些方法旨在通过只调整模型的一小部分参数来降低微调的成本。通常,这些方法可以分为两类。
第一类是适配器微调 [9, 10, 17-20],其核心思想是在模型的特定层中插入一些小型的神经网络模块,称为适配器。在微调过程中,模型的主体部分保持冻结,只有轻量化的适配器模块被微调,从而显著减少了微调的内存占用。
第二类是提示微调 [11, 21-24]。提示微调通过在输入数据中添加专门设计的提示或可学习的标记来适应特定任务,而不是直接修改基础模型的内部参数。
本文我们关注的是低秩适应(LoRA) [8],它是适配器微调领域内一个著名的方法。
2.2 低秩适应
低秩适应,最初称为 LoRA [8],已演变为一个广泛的类别,涵盖基于低秩近似的参数高效微调方法 [8, 14-16, 25-33]。LoRA 假设预训练模型权重的变化表现出低秩结构。因此,它将这些变化重新参数化为低秩矩阵的乘积,从而减少了微调的成本。
针对该方法的不同方面,已经提出了多个 LoRA 的变体。例如,DoRA [14] 通过引入一个可学习的幅度向量来重新缩放低秩矩阵的归一化乘积,从而改进了 LoRA [8]。另一个变体 rsLoRA [27] 引入了一个新的缩放因子,以稳定高秩场景下的训练。LoRA+ [28] 通过对两个低秩矩阵应用不同的学习率,进一步改进了 LoRA。此外,Galore [33] 通过将完整参数训练的梯度投影到低秩空间,减少了预训练和微调过程中的内存占用。
3. 方法
在本节中,我们首先回顾 LoRA [8](第 3.1 节)。接下来,我们从优化的角度对比了 LoRA 和完整微调(第 3.2 节)。最后,在第 3.3 节中,我们指出 LoRA 在优化过程中未能逼近完整微调,并提出 LoRA-Pro 作为解决方案,以缩小这一性能差距。
3.1 回顾低秩适应
首先,让我们回顾一下低秩适应(LoRA) [8]。LoRA 的核心思想围绕着识别标准微调过程中变化矩阵
这里,
27],
3.2 LoRA 与完整微调的比较
尽管 LoRA 在多个领域得到了广泛的应用,但其性能仍然不如完整微调。在本节中,我们回顾并比较了 LoRA 和完整微调的优化过程。在完整微调中,我们使用微分来分析损失变化与权重变化之间的关系:
其中,
在 LoRA 优化中,给定
类似地,LoRA 设置
3.3 等效梯度的低秩适应
定义 3.1(等效梯度)
在 LoRA 优化的背景下,我们定义等效梯度为:
其中,
从公式 (3) 中我们可以看到,矩阵 A 和 B 的变化通过链式法则与矩阵 W 的变化紧密相连:
相比于完整微调,这相当于使用等效梯度
基于这一关系,我们在定义 1 中引入了等效梯度的概念。等效梯度描述了低秩适应后矩阵 W 的梯度,尽管 W 不是可训练的参数。为了缩小性能差距,我们的目标是精心选择合适的
定理 3.1
假设矩阵
其中,
闭式解
幸运的是,目标函数 (7) 有一个闭式解。根据定理 3.1,我们得到了更新矩阵 A 和 B 的最优梯度,确保等效梯度能够最好地逼近完整微调的梯度。此外,我们还发现
定理 3.2
在使用定理 3.1 的闭式解更新矩阵 A 和 B 时,我们的更新步骤如下:
其中,
尽管定理 3.1 提供了优化问题
定理 3.3
考虑优化问题:
其中,
当且仅当
X 的选择
虽然等效梯度本身与矩阵
4. 实验结果
在本节中,我们评估了我们提出的 LoRA-Pro 方法在多个自然语言理解数据集上的表现。为了提供全面的对比,我们包含了以下基线方法:1)完整微调和标准 LoRA [8];2)保持原始结构的 LoRA 变体,如 rsLoRA [27]、LoRA+ [28]、PiSSA [34];3)结构上有改动的 LoRA 变体,包括 DoRA [14] 和 AdaLoRA [35]。
结果如表 1 所示。我们在 GLUE 数据集的一个子集上微调了 T5-base 模型 [36]。从表 1 中可以看出,LoRA-Pro 在 5 个数据集中的 3 个数据集上取得了最高分数,并且在所有 5 个数据集上的平均得分也最高。此外,平均来看,LoRA-Pro 相较于标准 LoRA [8] 提升了 6.72 分。这些结果验证了我们方法的有效性。
表 1:在 GLUE 数据集的子集上使用 T5-base 进行微调的结果(完整微调和 LoRA 变体)。
| 方法 | MNLI | SST2 | CoLA | QNLI | MRPC | 平均分数 |
|---|---|---|---|---|---|---|
| 完整微调 | 86.33±0.00 | 94.75±0.21 | 80.70±0.24 | 93.19±0.22 | 84.56±0.73 | 87.91 |
| LoRA | 85.30±0.04 | 94.04±0.11 | 69.35±0.05 | 92.96±0.09 | 68.38±0.01 | 82.08 |
| PiSSA | 85.75±0.07 | 94.07±0.06 | 74.27±0.39 | 93.15±0.14 | 76.31±0.51 | 84.71 |
| rsLoRA | 85.73±0.10 | 94.19±0.23 | 72.32±1.12 | 93.12±0.09 | 52.86±2.27 | 79.64 |
| LoRA+ | 85.81±0.09 | 93.85±0.24 | 77.53±0.20 | 93.14±0.03 | 74.43±1.39 | 84.95 |
| DoRA | 85.67±0.09 | 94.04±0.53 | 72.04±0.94 | 93.04±0.06 | 68.08±0.51 | 82.57 |
| AdaLoRA | 85.45±0.11 | 93.69±0.20 | 69.16±0.24 | 91.66±0.05 | 68.14±0.28 | 81.62 |
| LoRA-GA | 85.70±0.09 | 94.11±0.18 | 80.57±0.20 | 93.18±0.06 | 85.29±0.24 | 87.77 |
| LoRA-Pro | 86.92±0.08 | 94.46±0.24 | 82.25±1.01 | 92.89±0.12 | 87.50±0.65 | 88.80 |
5. 结论
在本文中,我们提出了 LoRA-Pro,一种旨在缩小 LoRA 与完整微调之间性能差距的新方法。为此,我们引入了“等效梯度”的概念,它使我们能够量化 LoRA 与完整微调在优化过程中的差异。通过最小化这种差异,我们推导出了 LoRA 的最优闭式更新解。此外,我们证明了这些解在优化过程中确保了损失的减少。这些解不仅对微调矩阵进行了低秩近似,还保持了与完整微调优化的一致性,从而实现了更有效的微调。最后,我们通过在自然语言处理任务上的广泛实验验证了我们方法的有效性。