 机器学习术语
机器学习术语
Batch
我们实际上在算微分的时候,并不是真的对所有 Data 算出来的

每一个 Batch 的大小就是大 B 一笔的资料,我们每次在 Update 参数的时候,我们是拿大 B 一笔资料出来,算个 Loss,算个 Gradient,Update 参数,拿另外 B 一笔资料,再算个 Loss,再算个 Gradient,再 Update 参数,以此类推,所以我们不会拿所有的资料一起去算出 Loss,我们只会拿一个 Batch 的资料,拿出来算 Loss,所有的 Batch 看过一遍,叫做一个 Epoch。batch_size是指一个 batch 中的样本总数。
Shuffle 有很多不同的做法,但一个常见的做法就是,在每一个 Epoch 开始之前,会分一次 Batch,然后呢, 每一个 Epoch 的 Batch 都不一样,就是第一个 Epoch,我们分这样子的 Batch,第二个 Epoch,会重新再分 一次 Batch,所以哪些资料在同一个 Batch 裡面,每一个 Epoch 都不一样的这件事情,叫做 Shuffle。
Epoch
当一个完整的数据集通过了神经网络一次并且返回了一次,这个过程称为一个 epoch。
为什么要使用多于一个 epoch?
我知道这刚开始听起来会很奇怪,在神经网络中传递完整的数据集一次是不够的,而且我们需要将完整的数据集在同样的神经网络中传递多次。但是请记住,我们使用的是有限的数据集,并且我们使用一个迭代过程即梯度下降,优化学习过程和图示。因此仅仅更新权重一次或者说使用一个 epoch 是不够的。
随着 epoch 数量增加,神经网络中的权重的更新次数也增加,曲线从欠拟合变得过拟合。
那么,几个 epoch 才是合适的呢?
不幸的是,这个问题并没有正确的答案。对于不同的数据集,答案是不一样的。但是数据的多样性会影响合适的 epoch 的数量。比如,只有黑色的猫的数据集,以及有各种颜色的猫的数据集。
Iterator
理解迭代,只需要知道乘法表或者一个计算器就可以了。迭代是 batch 需要完成一个 epoch 的次数。记住:在一个 epoch 中,需要 batch_size 的个数和迭代次数是相等的。
例如对于一个有 60000 个训练样本的数据集。将 60000 个样本分成大小为 600 的 batch_size,那么完成一个 epoch 需要 100 个 iteration,则 batch_size 的个数也为 100,即 60000=100xbatch_size。

backbone、head、neck 和 fine-tune
以一个图像分类的卷积神经网络为例,网络分成两部分,前部分是由卷积层、归一化层、激活层、池化层堆叠的,输入图像在经过若干层卷积、归一化层、激活层和池化层的堆叠后进入全连接层,经过几次全连接后输出每个类别的概率值。
在这里,前面卷积层、归一化层、激活层和池化层的堆叠部分属于 backbone。意思是神经网络的躯干部分,这部分也称为特征提取网络。
后面的全连接层的堆叠属于 head。意思是神经网络的头部,实现模型任务的预测,称为 predictor head,这部分网络也称为分类网络。
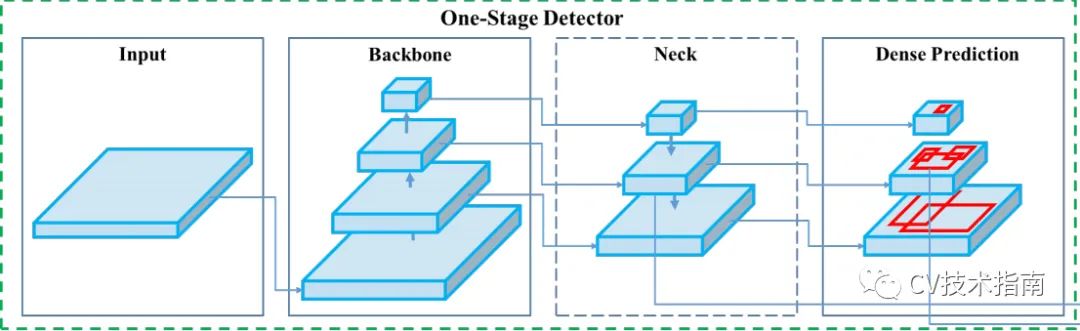
再以目标检测中的 YOLO_V4 中的图为例。
如上图所示,在 backbone 后,常构建特征金字塔,在特征金字塔部分做一些处理,如多尺度融合,再将特征金字塔的输出进行预测。因此,特征金字塔这部分放在 backbone 和 head 之间,称为 neck(脖子),这里的 Dense Prediction 即为 head。
关于 backbone 即常见的经典网络,如 VGG,ResNet,MobileNet,ShuffleNet,DenseNet 等,当某个模型提到 backbone 使用的是 VGG,即表示使用的是 VGG 的 backbone 部分,而不包括 VGG 的 head。
这里解释一下为何是这样。神经网络有多种解释,其中一种解释如下,神经网络被认为是在提取特征,计算机视觉的传统方法就是人为地设定某些特征,再进行分类。如 HOG 特征,LBP 特征,在提取完特征后,使用分类器对这些特征进行分类,如 SVM 分类器。
这里的 backbone 部分则认为是一个特征提取网络,而 head 部分则被认为是分类网络,因此特征提取的部分可以共享,它们的本质都是在提取图片的特征,而分类网络则对应到具体的任务,如分类猫狗,分类网络需要从提取的特征中分成猫狗两类。
这段话同时也解释了 fine-tune 的原理,使用一个预训练好的 backbone,针对你自己的任务,自己搭建相应的分类网络,在训练时冻结 backbone 的参数,只训练分类网络的参数。这是因为预训练好的 backbone 已经具备很好的特征提取能力,因此对于你自己的图像,网络只需要学习如何将提取后的特征按你定义的类别进行分类。
Preprocess 和 Postprocess
Preprocess 为预处理,图像在送入神经网络之前,需要进行一定的处理。
通常的处理是使用 opencv 中的 resize 将所有图像缩放到同一尺寸,并根据数据集的标注设置网络的 label。此外,如果有必要的话,还会进行数据增强,如调整图像饱和度,镜像,加噪声,随机掩码等方式。
预处理的必要性:大部分神经网络在 backbone 后将数据进行 flatten(即将四维的张量变成二维)的操作,再进行全连接,此时全连接层输入的神经元个数即为 flatten 后的长度,若输入的图像的尺寸不一样,则全连接层输入的神经元个数无法一致,会报错。此外,对于没有全连接层,其它类似的处理部分(除少数外),也会要求 backbone 后的输出大小一致。
Postprocess 指的是对网络预测的结果进行后处理,对于普通的分类网络不需要后处理,但对于目标检测、语义分割这样的任务,需要对网络的输出进行处理,将预测的结果通过图像进行可视化。
例如目标检测中的 YOLO,其输出一个 7x7x30 的张量,输出 98 个预测框,但实际一张图片没这么的目标,则需要进行 NMS 这样的处理来去除一些不合理的预测框,且我们无法直接看待这些预测框是否准确,就需要将其在原图像上显示出来,以直观感受预测的效果如何。
feature map
字面意思:特征图。
根据前面的解释,神经网络是在将图像从高维像素空间映射到低维的特征空间,这个映射是通过一层一层卷积和激活来进行的,卷积具备提取特征的能力。
例如在数字图像处理中,我们是通过 sobel 算子来检测轮廓,而 sobel 算子可以认为是 3x3 的卷积的其中一种情况,在这种情况下,它就可以提取图像的轮廓,那在其它情况下就可以提取其它的特征,因此卷积的过程就是在提取特征的过程,经过卷积提取特征和激活函数的映射后的输出称为 feature maps。
One-Shot学习
- 定义: One-Shot学习是Few-Shot学习的一种特殊情况,其中模型仅从每个类别的一个样本中学习。这在数据极度稀缺的情况下尤为关键。
公司门禁用了人脸识别,你只提供一张照片,门禁就能认识各个角度的你,这就是 one-shot。可以把 one-shot 理解为用 1 条数据 finetune 模型。
- 应用: 常用于面部识别和手写字符识别等场景,在这些应用中,获取同一类别的大量样本通常非常困难。
- 常用模型:
- 孪生网络(Siamese Networks): 一种特殊的神经网络架构,通过比较两个输入样本的相似性来进行分类。
- 度量学习(Metric Learning): 与Few-Shot学习类似,One-Shot学习也依赖于度量学习,通过学习一个相似性度量,使模型能够识别与已知样本相似的新样本。
- 原型网络(Prototype Networks): 基于类别原型的模型,通过计算新样本与每个类别原型之间的距离来进行分类。
Zero-Shot学习
- 定义: Zero-Shot学习是指在模型训练时从未见过某些类别的样本,但模型仍然能够识别这些新类别。这通常通过利用类别的语义信息(如描述或属性)来实现,将已知类别与未知类别关联起来。
用 wikipedia、新闻等,训练一个 GPT 模型,直接拿来做对话任务,这个就是 zero-shot。
- 应用: 适用于不断出现新类别的场景,例如物体识别或理解新语言。Zero-Shot学习可以在不需要重新训练的情况下处理新增类别。
- 常用模型:
- 语义嵌入模型(Semantic Embedding Models): 通过将输入数据和类别描述映射到共享的特征空间,使模型能够泛化到未见过的类别。
- 属性分类器(Attribute Classifiers): 利用类别的属性信息,将未见过的类别与已知类别关联。
- 生成对抗网络(Generative Adversarial Networks, GANs): 用于生成虚拟样本,帮助模型学习识别未见过的类别。
Few-Shot学习
- 定义: Few-Shot学习指的是在只有少量样本的情况下训练模型以识别新类别。通常,每个类别只提供少数几个样本用于训练。
zero-shot训练的模型发现胡说八道有点多,找了一些人标注了少量优质数据喂进去,这就是 few-shot
- 应用: 这种方法在图像分类、自然语言处理以及其他数据稀缺的任务中非常有用。例如,医学图像分析中,由于标注成本高,获取大量数据比较困难。
- 常用模型:
- 元学习(Meta-Learning): 通过学习如何学习,让模型能够在见过少量新样本后快速适应新任务。
- 度量学习(Metric Learning): 通过学习一个相似性度量函数,使模型能够将相似的样本聚集在一起。
- 迁移学习(Transfer Learning): 利用在大规模数据集上预训练的模型,通过微调适应小样本的新任务。
自监督学习 (Self-Supervised Learning)
- 定义: 自监督学习是一种不依赖人工标注数据的监督学习方法。模型通过从数据本身生成“伪标签”,利用这些伪标签来进行学习。
- 原理: 自监督学习的核心思想是利用数据的内在结构来构造监督信号。例如,在图像处理中,可以通过预测被遮挡部分的像素值或相邻帧之间的关系来生成伪标签;在自然语言处理中,模型可以通过预测被遮挡的词汇或句子顺序来进行训练。
- 最新成熟的模型:
- SimCLR: 一种基于对比学习的自监督方法,通过最大化同一数据增强版本的特征相似性来学习有意义的表示。
- BYOL (Bootstrap Your Own Latent): 通过不使用负样本来生成数据的潜在表示,并在不同视角下进行对比来训练模型。
- CLIP (Contrastive Language–Image Pre-training): 由OpenAI开发,通过对比文本和图像来预训练模型,使其能够理解图像和文本的语义关系。
半监督学习 (Semi-Supervised Learning)
- 定义: 半监督学习结合了少量标注数据和大量未标注数据进行模型训练。通过利用未标注数据的信息,模型可以在有限的标注数据下提升性能。
- 原理: 半监督学习的关键是如何有效地利用未标注数据。常见的方法包括:
- 一致性正则化(Consistency Regularization): 假设模型对相同数据在不同扰动下的输出应该一致。通过这种方法,可以利用未标注数据来约束模型的预测一致性。
- 伪标签(Pseudo-Labeling): 通过模型对未标注数据的预测生成伪标签,然后将这些伪标签作为监督信号来训练模型。
- 混合方法(MixMatch): 将多种半监督学习技术(如伪标签和一致性正则化)结合在一起,提高模型的鲁棒性和准确性。
- 最新成熟的模型:
- FixMatch: 结合伪标签和一致性正则化的半监督学习方法,通过使用未标注数据的伪标签和增强数据的置信度来训练模型。
- MixMatch: 一种将数据增强、伪标签和一致性正则化结合起来的方法,有效地利用了标注和未标注数据。
无监督学习 (Unsupervised Learning)
- 定义: 无监督学习是指在没有任何标注数据的情况下进行学习。模型通过挖掘数据的内在结构和模式,自动生成有用的表示或分类。
- 原理: 无监督学习依赖于数据的内在模式和特征来进行学习,常见的任务包括聚类、降维和生成建模。例如,聚类算法试图将数据分成具有相似特征的组,而降维算法则试图将高维数据映射到低维空间以便于理解和处理。
- 最新成熟的模型:
- Variational Autoencoders (VAEs): 一种生成模型,通过学习数据的隐变量表示来生成新样本,常用于图像生成和数据降维。
- 生成对抗网络(Generative Adversarial Networks, GANs): 通过两个对抗网络(生成器和判别器)来生成逼真的数据样本,广泛应用于图像生成、风格迁移等领域。
- K-Means: 一种经典的聚类算法,将数据点分配到K个类中,使得每个类中的数据点尽可能相似。
- t-SNE: 一种常用于数据降维的技术,将高维数据映射到二维或三维空间中,保留数据的局部结构。
Linear Probing
在深度学习中,**线性探测(Linear Probing)**是一种评估预训练模型所学特征质量的方法。具体而言,在适配下游任务时,冻结预训练模型的参数,仅对模型最后一层的线性层进行参数更新。这种方法用于检验预训练模型的好坏,一般情况下,线性探测的结果会差于微调。
与之相对,**微调(Fine-Tuning)**则是在预训练模型的基础上,对整个模型的参数进行调整,以适应特定的下游任务。相比之下,线性探测更为简单,计算成本更低,但其性能可能不如全面微调。因此,线性探测通常用于快速评估预训练模型的特征表示能力,而微调则用于在特定任务上获得最佳性能。 citeturn0search3
需要注意的是,线性探测的效果在很大程度上取决于预训练模型所学特征的质量。如果预训练模型学到了高质量的特征,即使只训练一个简单的线性分类器,也能在下游任务中取得良好的性能。因此,线性探测被广泛用于自监督学习等领域,以评估模型学习到的特征的有效性。 citeturn0search2