 RAIL
RAIL
0. 摘要
持续学习(Continual Learning, CL)与视觉 - 语言模型(Vision-Language Models, VLMs)的结合克服了传统 CL 仅关注已见过类别的限制。在 VLMs 的持续学习过程中,我们不仅需要防止增量学习知识的灾难性遗忘,还需要保持 VLMs 的零样本能力。然而,现有方法需要额外的参考数据集来维持这种零样本能力,并依赖领域标识提示来跨不同领域分类图像。在本研究中,我们提出了基于回归的分析增量学习(Regression-based Analytic Incremental Learning, RAIL),它利用基于递归岭回归的适配器以非遗忘的方式从一系列领域中学习,并通过将特征投影到高维空间来解耦跨领域相关性。与无训练的融合模块配合,RAIL 能够在没有任何参考数据的情况下绝对保持 VLM 在未见领域上的零样本能力。此外,我们引入了跨领域任务无关增量学习(Cross-domain Task-Agnostic Incremental Learning, X-TAIL)设置。在这一设置中,CL 学习者需要从多个领域增量学习,并在没有任何领域标识提示的情况下对来自已见和未见领域的测试图像进行分类。我们从理论上证明了 RAIL 在增量学习领域上的绝对记忆能力。实验结果证实了 RAIL 在 X-TAIL 和现有的多领域任务增量学习(Multi-domain Task-Incremental Learning, MTIL)设置中的最先进性能。代码发布于 https://github.com/linghan1997/Regression-based-Analytic-Incremental-Learning。
1. 引言
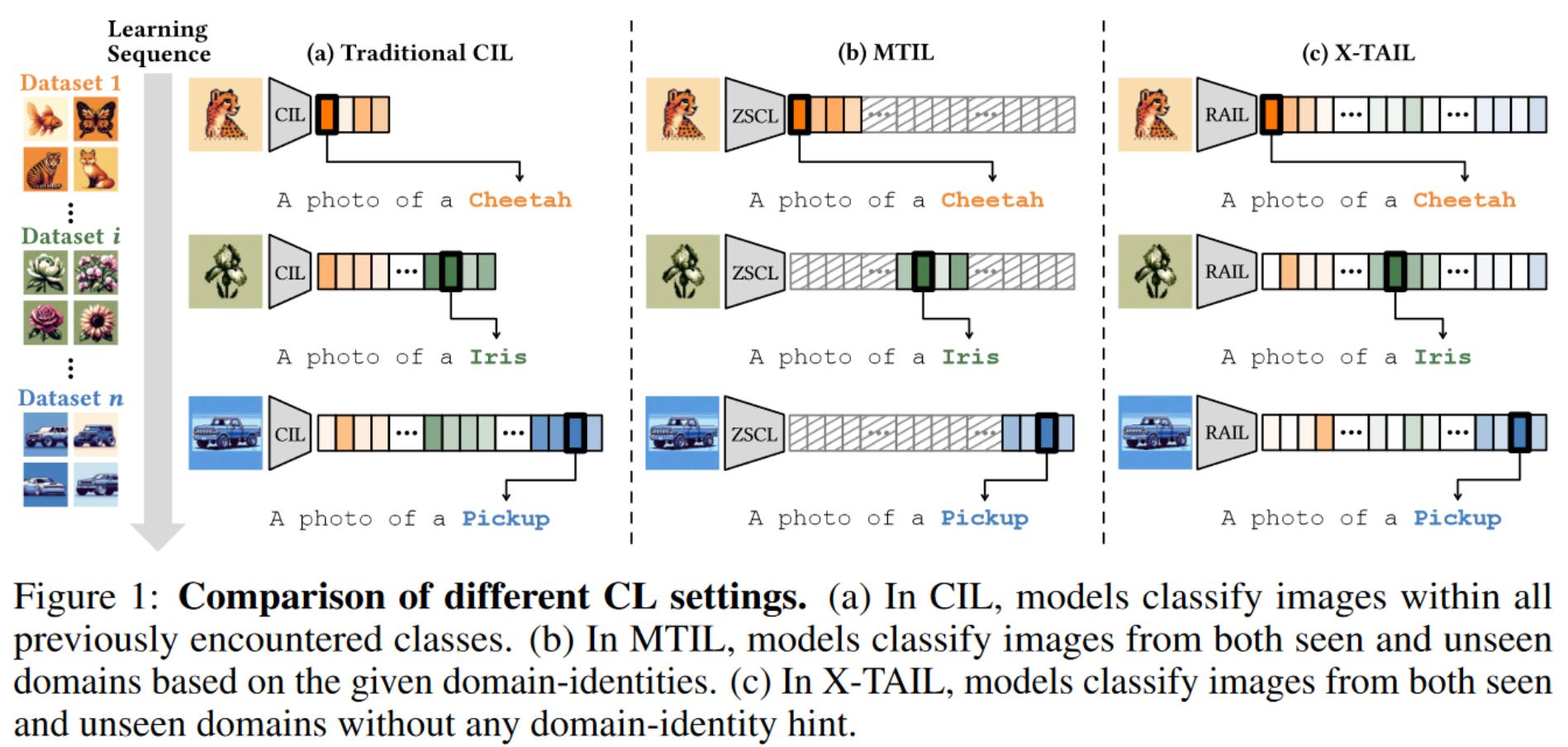
持续学习(Continual Learning, CL)[1,2,3] 是机器学习中的一个关键领域,它要求学习者能够增量学习新数据,而不是从头开始训练。CL 中的主要挑战被称为灾难性遗忘(catastrophic forgetting)[4],即学习新知识会导致对旧知识的遗忘。为此,已经提出了多种 CL 方法 [5,6,7,8,3,9] 来解决遗忘问题。作为一种典型的 CL 设置,类增量学习(Class-Incremental Learning, CIL)(图 1(a))旨在在所有已见类别上实现鲁棒的区分能力。尽管取得了进展,现有方法主要专注于对已见类别中的图像进行分类,从而限制了模型的泛化能力。
因此,Zheng 等人 [10] 提出了多领域任务增量学习(Multi-domain Task-Incremental Learning, MTIL),它将 CL 与视觉 - 语言模型(VLMs)[11,12,13,14](如 CLIP[13])的零样本能力结合。这种集成使模型能够对尚未遇到的领域进行分类,增强了其在多个领域的泛化能力(图 1(b))。几种方法 [10,15] 专门为 MTIL 设计,要求模型在 CL 过程中保留增量学习的知识以及 VLMs 的零样本能力。然而,这些方法需要领域标识提示来指示测试图像的具体领域,这在实际场景中往往不适用 [7]。此外,在训练过程中需要使用参考数据集来维持预训练 VLMs 的零样本性能。
为了解决上述限制,我们提出了基于回归的分析增量学习(Regression-based Analytic Incremental Learning, RAIL),这是一种新颖的方法,能够增量学习新知识并在已见和未见领域上有效执行。具体来说,我们从原始和对偶两个角度利用非线性投影函数来增强预训练 CLIP 提取的特征表达能力。这使学习者能够在没有任何领域标识提示的情况下对跨领域标签集中的图像进行分类。在增量学习过程中,RAIL 利用基于岭回归的适配器递归地更新参数。这相当于一次性学习所有遇到的领域,实现了对已学习领域的绝对记忆。此外,我们冻结了预训练的 CLIP,并设计了一个无训练的融合模块来确定测试数据是否属于已见或未见领域。这一策略绝对保留了 CLIP 在未见领域上的零样本能力,满足了在动态环境中部署模型的实际需求。
为了展示我们方法的有效性,我们提出了跨领域任务无关增量学习(Cross-domain Task-Agnostic Incremental Learning, X-TAIL)设置,如图 1(c) 所示。特别是,X-TAIL 要求 CL 方法将预训练的 VLM 增量转移到多个领域,同时评估模型在已见和未见领域上的性能。此外,X-TAIL 禁止使用领域提示,使其更加现实和具有挑战性 [3]。因此,有效的 CL 方法必须同时将测试图像分类到正确的领域和类别。
我们的贡献总结如下:
- 我们提出了一种新的 CL 方法 RAIL,能够在不遗忘预训练和增量学习知识的情况下,将预训练的 VLM 增量适应到多个领域。
- 为了满足 CL 方法需要从新领域顺序学习数据并对跨领域图像进行分类的实际场景,我们提出了新的设置 X-TAIL,以评估 VLM 零样本能力的保持和新领域的适应性。
- 我们从理论上证明了 RAIL 在增量学习领域上的绝对记忆能力,并证明了预训练 VLM 在未见领域上的零样本能力被绝对保留。
- 我们通过实验表明,所提出的方法在现有的 MTIL 和新颖的 X-TAIL 设置中均达到了最先进的性能。
2. 相关工作
早期的 CL 方法专注于任务增量学习(Task-Incremental Learning, TIL)[16],其中在测试时提供任务标识。随后,提出了更具实际意义和挑战性的类增量学习(Class-Incremental Learning, CIL)[7] 设置,其中在推理时禁止访问任务标识。因此,CIL 的方法必须区分在学习任务中遇到的所有类别。最近,Zheng 等人 [10] 提出了多领域任务增量学习(Multi-Domain Task-Incremental Learning, MTIL),专门用于评估具有预训练 VLMs 的 CL 方法。在 MTIL 中,预训练的 VLM 持续适应多领域任务。在已见和未见任务上的性能衡量了增量获取和预训练知识的保留。然而,它仍然需要任务标识在推理时创建特定的领域标签空间。除此之外,X-TAIL 结合了 CIL 和 MTIL 的挑战,其中模型从各种传入领域学习新类别,并在没有任何领域标识的情况下区分已见和未见类别。
流行的持续学习方法包括基于回放、基于蒸馏、基于正则化和基于架构的方法 [3]。基于回放的方法如 iCaRL[7] 通常存储之前任务数据的一小部分作为样本。然后,模型在新的任务数据和保存的样本上联合训练,以保留先前知识。基于蒸馏的方法如 LwF[6] 使用权重或函数正则化将知识从之前的模型转移到当前模型进行知识蒸馏。基于正则化的方法如 ZSCL[10] 通过向交叉熵损失函数添加正则化项来惩罚模型参数或特征空间的偏移。为了在无法访问预训练数据集的情况下保持强大预训练模型的鲁棒性,ZSCL 利用大规模参考数据集来正则化参数空间。基于架构的方法 [17,18,19] 通过构建任务特定参数来扩展模型,以避免任务间干扰。例如,MoE-Adapters[15] 将预训练的 CLIP 与专家混合(Mixture of Experts, MoE)[20] 结合,从不同领域学习。通过利用参考数据集初始化任务标识指示器,使模型能够区分未见任务和已见任务。
上述方法要么忽略了预训练知识的遗忘问题,要么需要多次迭代和大规模参考数据集进行训练,这使得在持续学习场景中高效适应新数据变得具有挑战性。相比之下,RAIL 采用了一种分析解决方案,能够在一个 epoch 内达到最优,无需额外的参考数据,确保了其效率。
3. 跨领域任务无关增量学习
3.1 问题设置
我们将跨领域任务无关增量学习(Cross-domain Task-Agnostic Incremental Learning, X-TAIL)定义如下。给定一个预训练的 VLM,学习者需要将其增量转移到 N 个不同的领域
与 TIL 中的任务标识类似,领域标识提示允许学习者在评估期间在特定领域的标签空间内对输入数据进行分类。本质上,学习者知道测试图像的领域,这在实际应用场景中是不现实的。例如,学习者应该从所有可能的类别
3.2 数据集
在 X-TAIL 的跨领域设置中,学习者应涵盖尽可能广泛的数据分布。根据先前的工作 [10,15,21,13,22,23],我们为我们的设置选择了来自不同领域的 10 个不同的图像分类数据集:Aircraft [24]、Caltech101 [25]、DTD [26]、EuroSAT [27]、Flowers [28]、Food [29]、MNIST [30]、OxfordPet [31]、StanfordCars [32] 和 SUN397 [33]。具体来说,为了防止学习重叠类别的冗余并保持设置的完整性,排除了 CIFAR-100 [34],因为它包含许多与其他领域重叠的类别。因此,X-TAIL 下的 CL 方法应能够区分来自所有领域的 1,100 个类别的图像。
3.3 评估指标
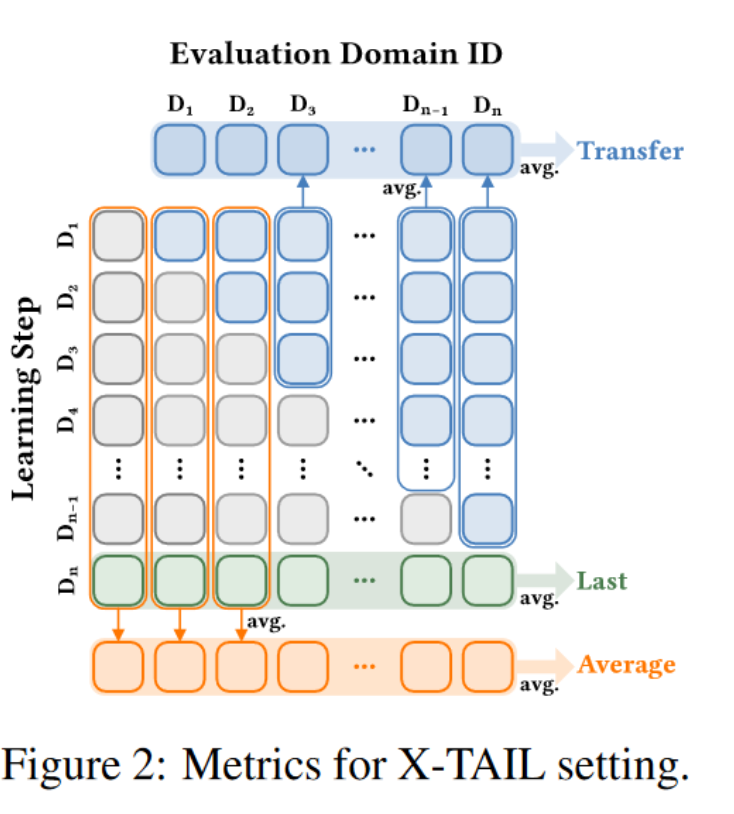
我们采用了 [10] 中的评估指标来评估我们的设置。如图 2 所示,每列表示在每次学习步骤后对特定领域的性能,而行对应于学习顺序。在传统的 CL 设置中,只测量学习者已接触测试领域样本的下对角线的结果。然而,X-TAIL 将此评估扩展到覆盖整个矩阵,记录在已学习和未学习领域上的性能。“Average”指标(橙色块的平均值)表示所有学习步骤在所有领域上的平均准确率。对角线下的灰色和绿色块显示了模型在学习这些领域后对这些领域的分类性能。具体来说,绿色块表示模型在学习所有领域后对这些领域的最终性能。“Last”指标(绿色块的平均值)反映了学习者对新领域的适应性。此外,右上矩阵中的蓝色块表示模型在学习这些领域之前对这些领域的零样本性能。这些块的平均值称为“Transfer”指标,用于衡量零样本能力在整个增量学习过程中的保留程度。
4. 方法
4.1 动机
尽管 CLIP 展示了零样本分类的泛化能力,但在某些不熟悉的领域中仍然表现不佳 [21]。利用 CLIP 的强大的特征提取能力,线性探测提供了一种直接的方法将 CLIP 转移到这些领域 [13]。在各种线性解决方案中,岭回归(Ridge Regression, RR)通过将图像特征映射到独热编码目标,提供了一种有效的分类策略 [35]。给定预训练的 CLIP 图像编码器
其中
在 X-TAIL 的背景下,分类器需要区分来自不同领域的广泛类别。然而,来自不同领域的图像提取的 CLIP 特征存在一定的跨领域相关性,导致领域区分能力有限。基于 Cover 定理 [36],一种有前途的方法 [37,38,39] 是通过某些非线性投影函数将特征投影到高维空间来增强特征的线性可分性。我们从两个角度探索这种非线性投影函数:
原始形式岭回归:根据 [38],我们使用随机初始化的隐藏层(Randomly-initialized Hidden Layer, RHL)将原始特征投影到更高维空间。通过显式定义投影函数
其中
对偶形式岭回归[40]:与手动设计投影函数不同,我们利用核方法 [41] 基于对偶形式岭回归的内积性质隐式定义
其中
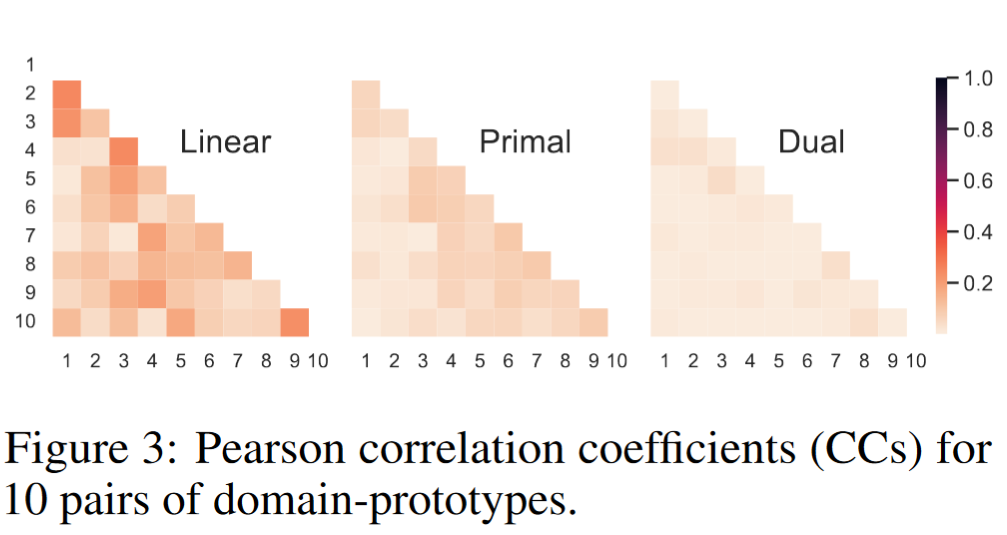
为了实证验证这些非线性投影是否增强了来自不同领域的 CLIP 特征的可分性,我们在第 3.2 节引入的 10 个领域上联合训练了三种分类器(分别称为 Linear、Primal 和 Dual)。为了与标准线性回归形式进行比较,我们取平均权重向量作为领域原型,然后计算 10 对领域原型之间的域间皮尔逊相关系数(CCs)。如图 3 所示,线性回归分类器表现出较高的跨领域相关性。相比之下,原始形式中的 RHL 显著降低了这些相关性。对偶形式中核技巧提供的隐式投影能够更好地解耦不同领域。我们进一步评估了领域内准确率,表示将图像正确分类到适当领域的比率。图 4 显示,领域内准确率与跨领域相关性呈负相关。原始和对偶形式通过投影设计均表现出一定的改进,允许在没有领域标识提示的情况下将图像准确分类到其各自领域。

4.2 基于回归的分析增量学习
基于上述投影方法,我们提出了基于回归的分析增量学习(Regression-based Analytic Incremental Learning, RAIL)方法,该方法结合了基于岭回归的适配器和无训练的融合模块。适配器逐步将预训练的 CLIP 适应到新领域,而无训练的融合模块保留了 CLIP 在未见领域上的零样本能力。RAIL 的概述如图 5 所示。训练和测试算法的伪代码见附录 A。
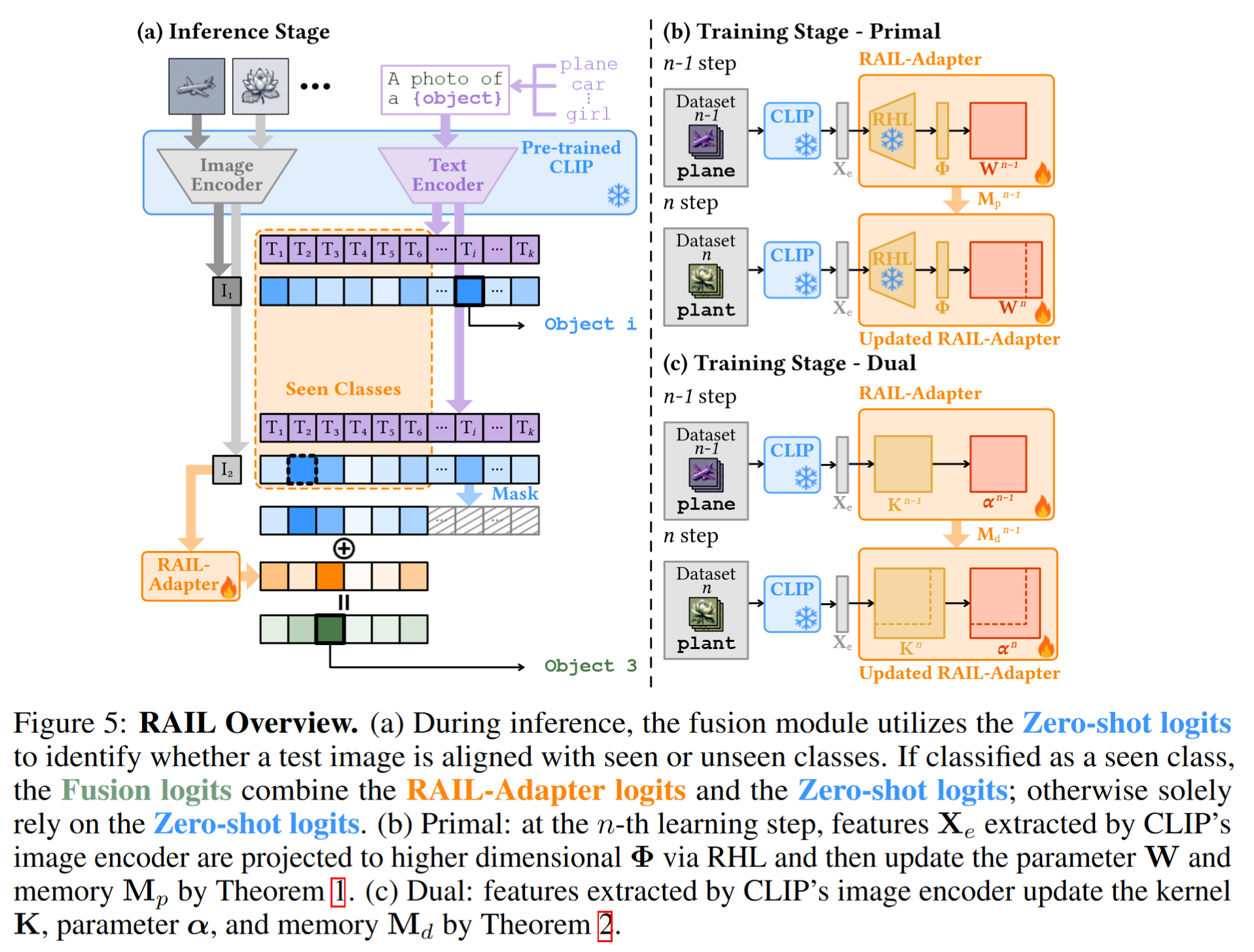
4.2.1 RAIL-Adapter
在数据逐步到达的 CL 背景下,我们将原始和对偶岭回归解扩展到增量学习方式。我们的解与联合训练获得的解相同,实现了对已学习知识的绝对非遗忘。设
其中
定理 1:通过下式计算参数:
其中
类似地,满足式 (4) 的对偶参数
定理 2:通过下式计算参数:
其中:
记忆矩阵为
在每个增量学习步骤中,核矩阵
具体来说,
4.2.2 RAIL-Fusion
接下来,我们引入了融合策略,该策略利用 RAIL-Adapter 在已见领域上的细化知识,同时保留 CLIP 在未见领域上的预训练知识。为了在没有领域标识提示的情况下区分来自不同领域的数据,一种常见的方法 [18] 是从类别原型中计算领域中心。测试图像首先根据到这些领域中心的距离分配到特定领域,然后由领域特定的分类器进行分类。然而,当未见领域的统计信息不可用时,这种方法会失效。
另一种解决方案是利用 CLIP 的零样本能力来指示测试图像的领域。尽管 CLIP 在跨领域上具有强大的泛化能力,但在增量学习过程中,某些跨领域错误(即错误分类到不正确的领域)仍然存在且不会减少。因此,将跨已见领域的图像分类任务委托给 RAIL-Adapter,这显著减少了这些错误,如第 4.1 节所述。因此,CLIP 的零样本能力仅用于区分未见领域(即 Out-Of-Distribution, OOD)和已见领域(即 In-Distribution, ID)中的类别,以保持其在未见领域上的性能。我们将这种方法总结为 RAIL-Fusion,它结合了 CLIP 的零样本logits和 RAIL-Adapter 的logits进行预测,无论测试图像的领域是已见还是未见。
具体来说,CLIP 首先基于其零样本logtis进行粗略预测,即图像嵌入与跨领域标签集
其中
其中
5. 实验
我们在 X-TAIL 和 MTIL 设置下评估 RAIL 方法,如第 3.2 节所述。学习顺序按字母顺序设置为:Aircraft、Caltech101、DTD、EuroSAT、Flowers、Food、MNIST、OxfordPet、StanfordCars 和 SUN397。随机顺序的额外实验见附录 G 中的表 3。为了确保与不同领域的兼容性,我们遵循常见的做法,为每个领域采样 16-shot 的训练集,同时使用原始测试集进行评估 [21,44,45,22,46]。实现细节见附录 D。
5.1 对比结果
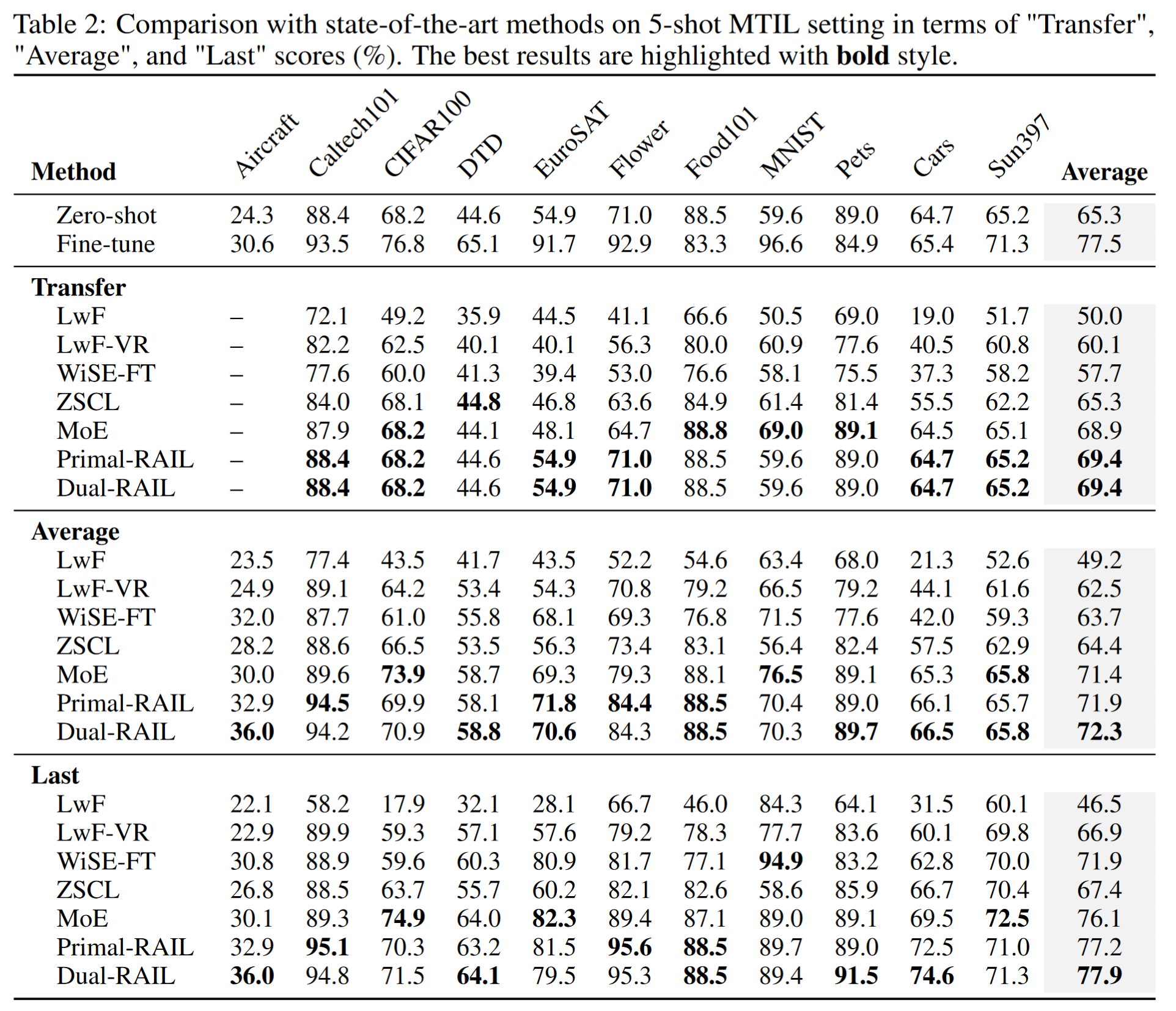
跨领域任务无关增量学习:RAIL 和其他基线方法在 X-TAIL 设置下 10 个领域的平均性能如表 1 的“Average”列所示。每个领域的具体性能见以各领域命名的列。我们评估了原始形式和对偶形式的 RAIL。“Zero-shot”表示预训练 CLIP 模型在每个领域上的零样本性能。“Fine-tuned”表示在 10 个领域联合数据集上微调 CLIP 图像和文本编码器的性能,作为比较的强基线。

具体来说,原始形式的 RAIL 在“Transfer”准确率上比之前的最佳方法提高了 6.4%,在“Average”准确率上提高了 7.7%,在“Last”准确率上提高了 8.6%。对偶形式的 RAIL 在“Average”准确率上进一步比原始形式提高了 1.2%,在“Last”准确率上提高了 3.3%,同时由于相同的融合策略,保持了“Transfer”准确率的一致性。这些结果表明,RAIL 具有更稳定的迁移性能,并且对灾难性遗忘更具鲁棒性,有效地保留了来自新领域和预训练的知识。我们在随机顺序下重复了实验,结果见表 3。RAIL 始终优于基线,进一步验证了之前的结论。
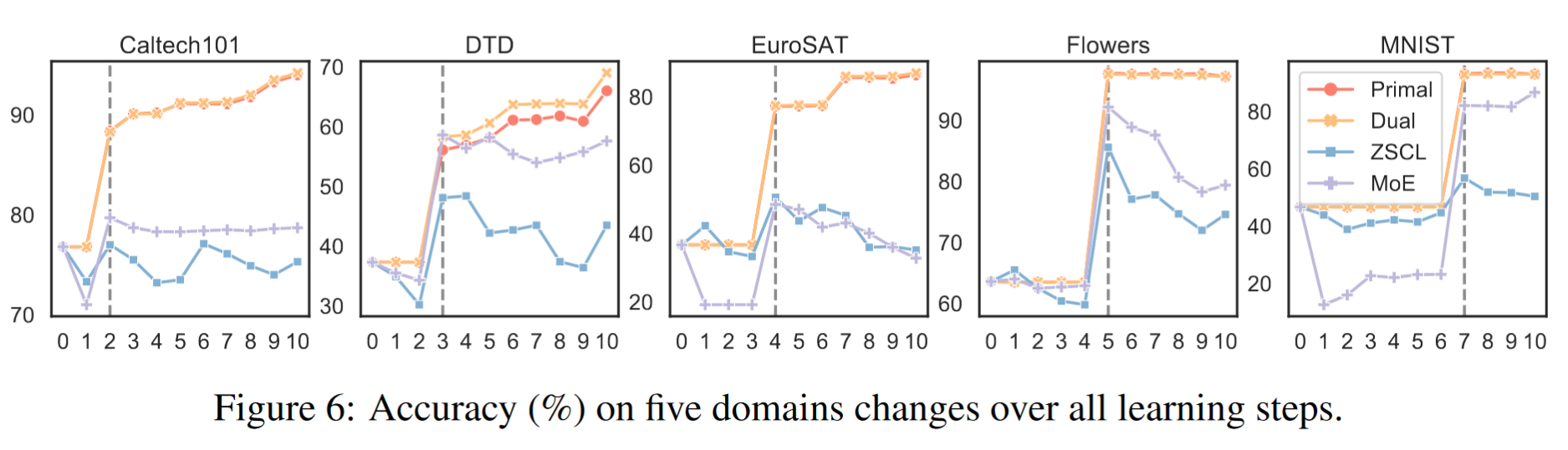
我们在图 6 中展示了几个示例领域上的准确率变化情况。我们观察到,在学习相应领域之前,RAIL 的准确率与零样本结果保持一致。此外,RAIL 表现出强大的跨领域区分能力。例如,一旦学习了 DTD,学习更多新领域不会影响 DTD 上的准确率。某些领域的准确率(如 Caltech101)甚至有所提高,这是由于融合模块能够通过学习更多领域来减少 OOD 错误。
多领域任务增量学习:我们按照 [15] 中的设置评估我们的方法在 5-shot MTIL 上的性能,并与 [15] 中报告的基线性能进行比较。在这种背景下,RAIL 简化为多个领域特定分类器的结构,分别在每个领域上进行训练。领域标识引导测试图像到相应的分类器进行领域内预测。对比结果如表 2 所示。RAIL 在所有三个指标上始终优于之前的最先进方法。这些结果表明,所提出的非线性投影显著提高了 CLIP 提取特征的可分性。因此,基于岭回归的分类器能够有效地将预训练模型适应到新领域。
5.2 讨论
回归目标:对于 VLMs,除了使用独热编码标签作为式 (4) 中的回归目标
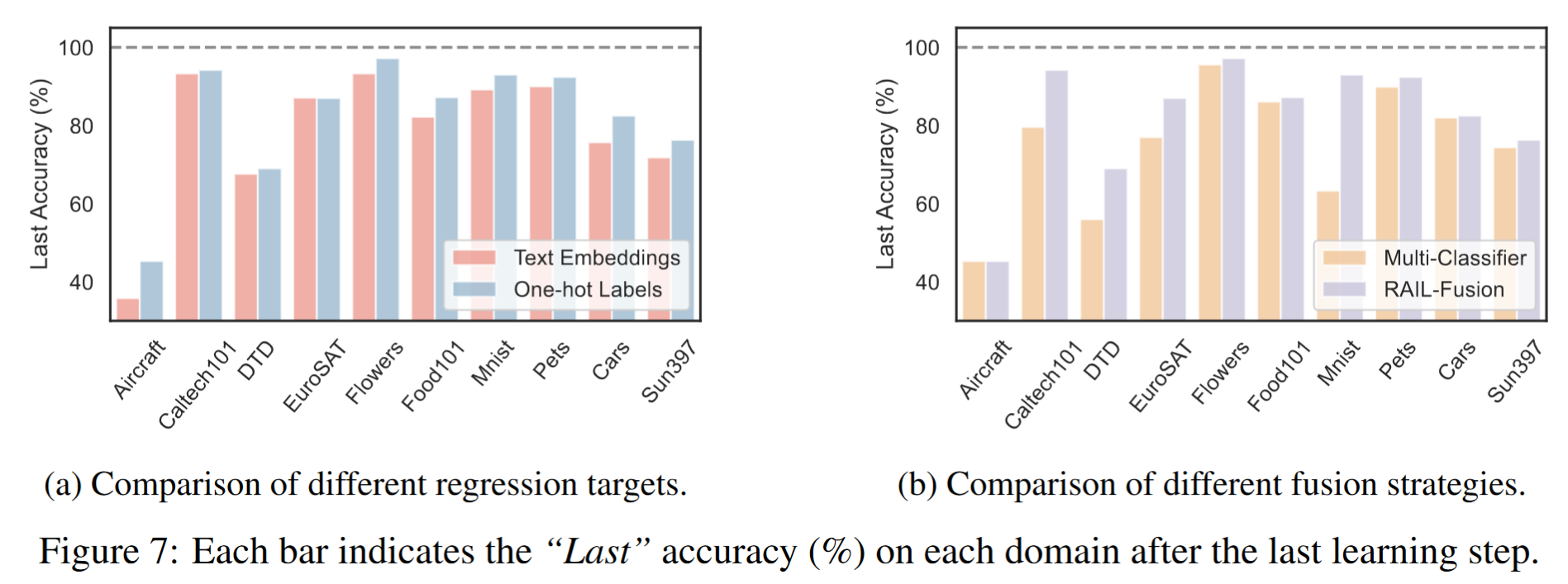
融合策略:与多领域相关的 CL 设置通常分为两个阶段:领域标识推理和领域内预测 [19]。如第 4.2.2 节所述,在 X-TAIL 中区分来自不同领域的类别的一种直观策略是利用 CLIP 的零样本预测作为领域指示器,然后与多个领域特定分类器协作,在每个不同的领域内进行分类。我们通过比较对偶 RAIL-Adapter 在 10 个领域上的“Last”准确率来评估 RAIL-Fusion 策略的有效性。“Transfer”准确率在这两种策略之间保持一致。
如图 7b 所示,RAIL-Fusion 策略在大多数领域中优于多分类器方法,平均提高了 7.5%。这种改进归功于 RAIL-Fusion 的设计,它专注于区分未见类别(OOD 领域)和已见类别(ID 领域),而不是识别特定领域(见第 4.2.2 节)。这种 OOD 检测设计随着 ID 领域数量的增加逐步减少错误,使其在动态适应新领域时特别有效。相比之下,使用领域指示器的方法在每个领域的跨领域错误保持稳定水平,导致最终预测中的错误传播。这对于领域内准确率较低的领域尤其关键,其中领域指示器与正确领域之间的任何偏差都会显著影响性能。由于 RAIL-Adapter 的非线性投影设计,这些跨领域错误得到了缓解。
6. 结论
在本工作中,我们提出了跨领域任务无关增量学习(X-TAIL),以评估在持续学习背景下预训练知识的保留和跨领域区分能力。我们引入了一种新的 CL 方法——基于回归的分析增量学习(RAIL),以提高预训练视觉 - 语言模型在逐步传入领域上的性能,同时保持其在未见领域上的零样本能力。我们从理论上证明了对已学习知识的绝对记忆,并展示了融合模块从根本上避免了 VLM 零样本能力的遗忘。在现有和提出的设置下的全面实验证明了我们方法的优越性。
7. 致谢
本研究得到了中国国家自然科学基金(62306117)和广州市基础与应用基础研究基金(2024A04J3681)的支持。