 ViT详解
ViT详解
Vision Transformer 详解
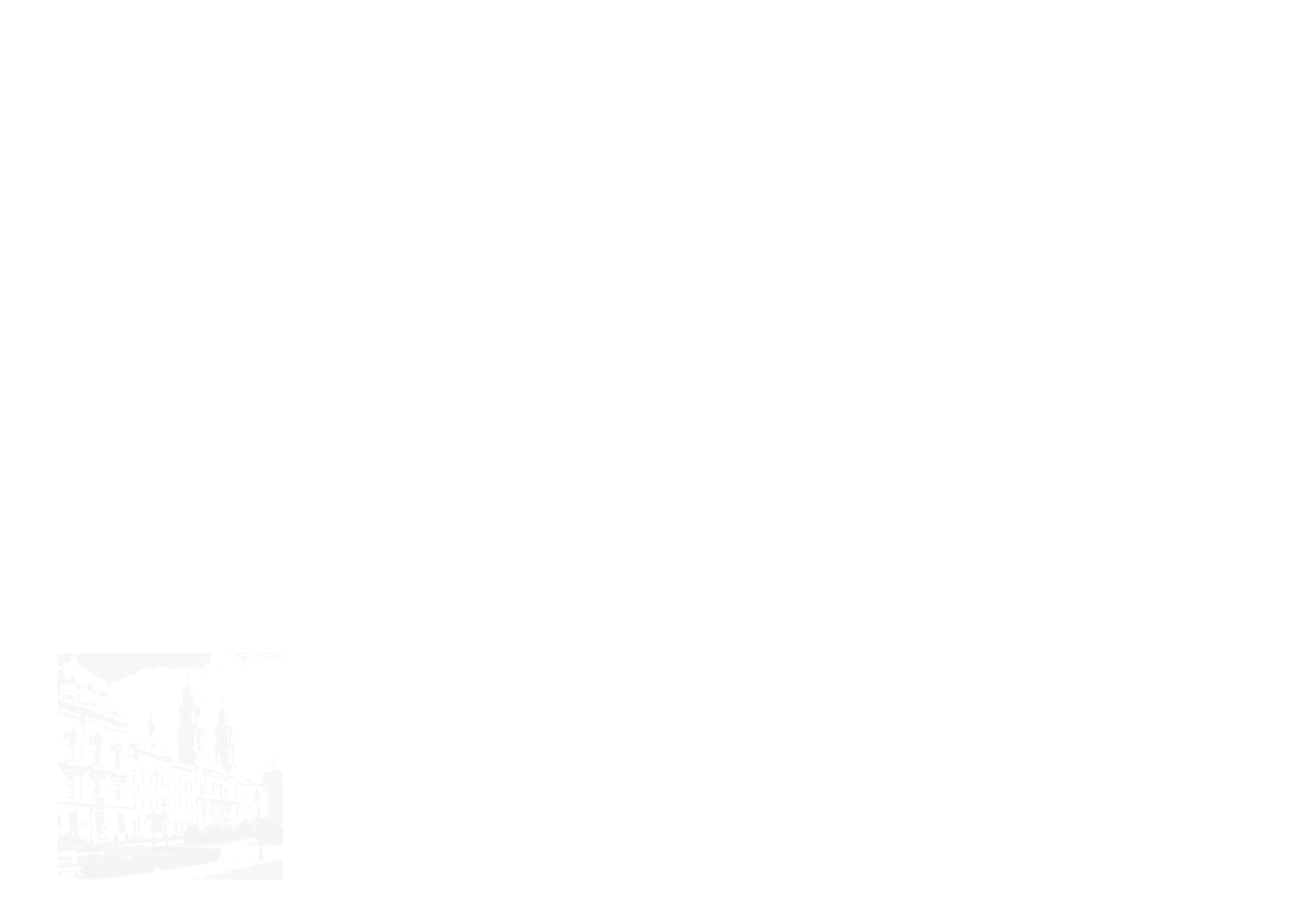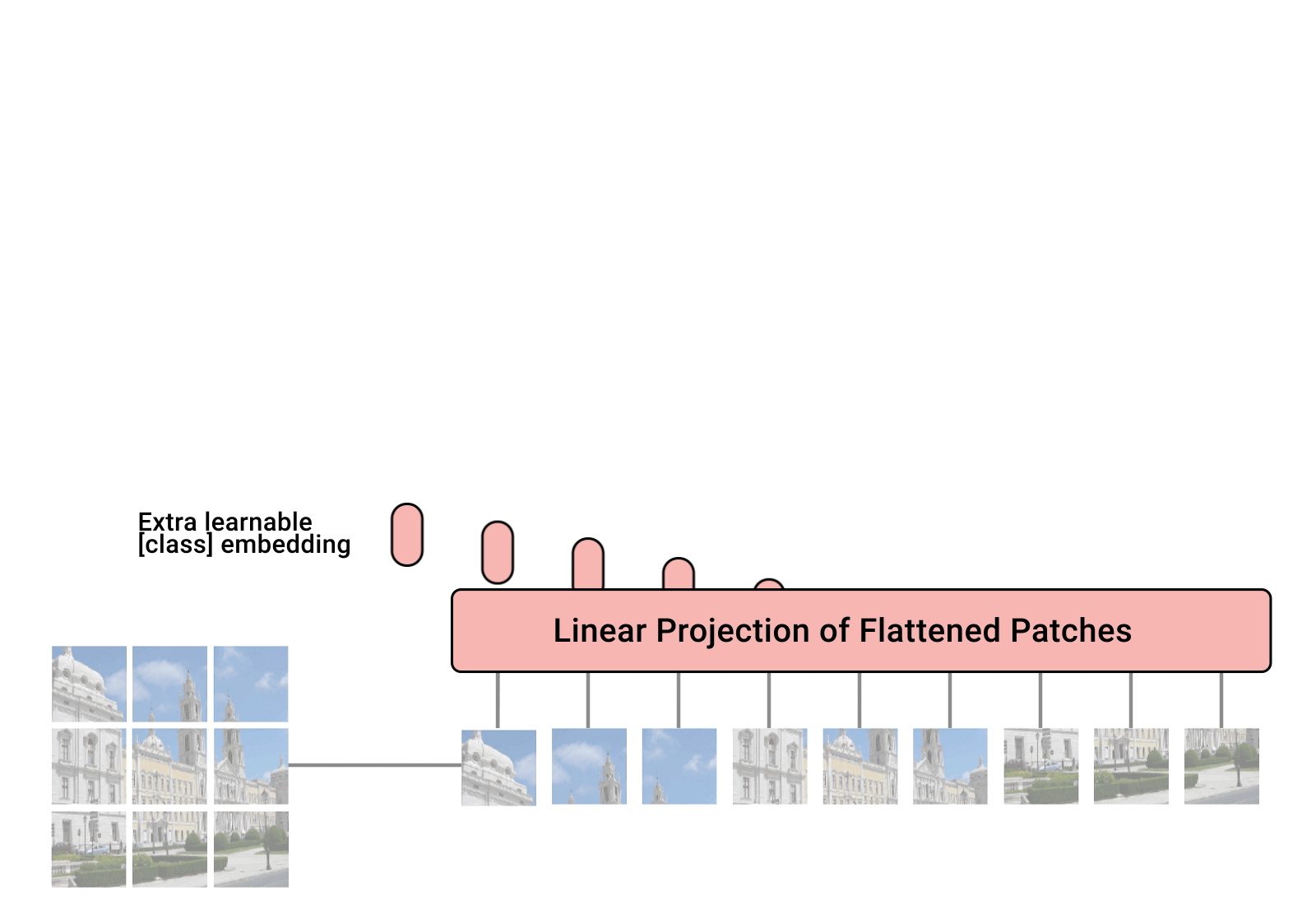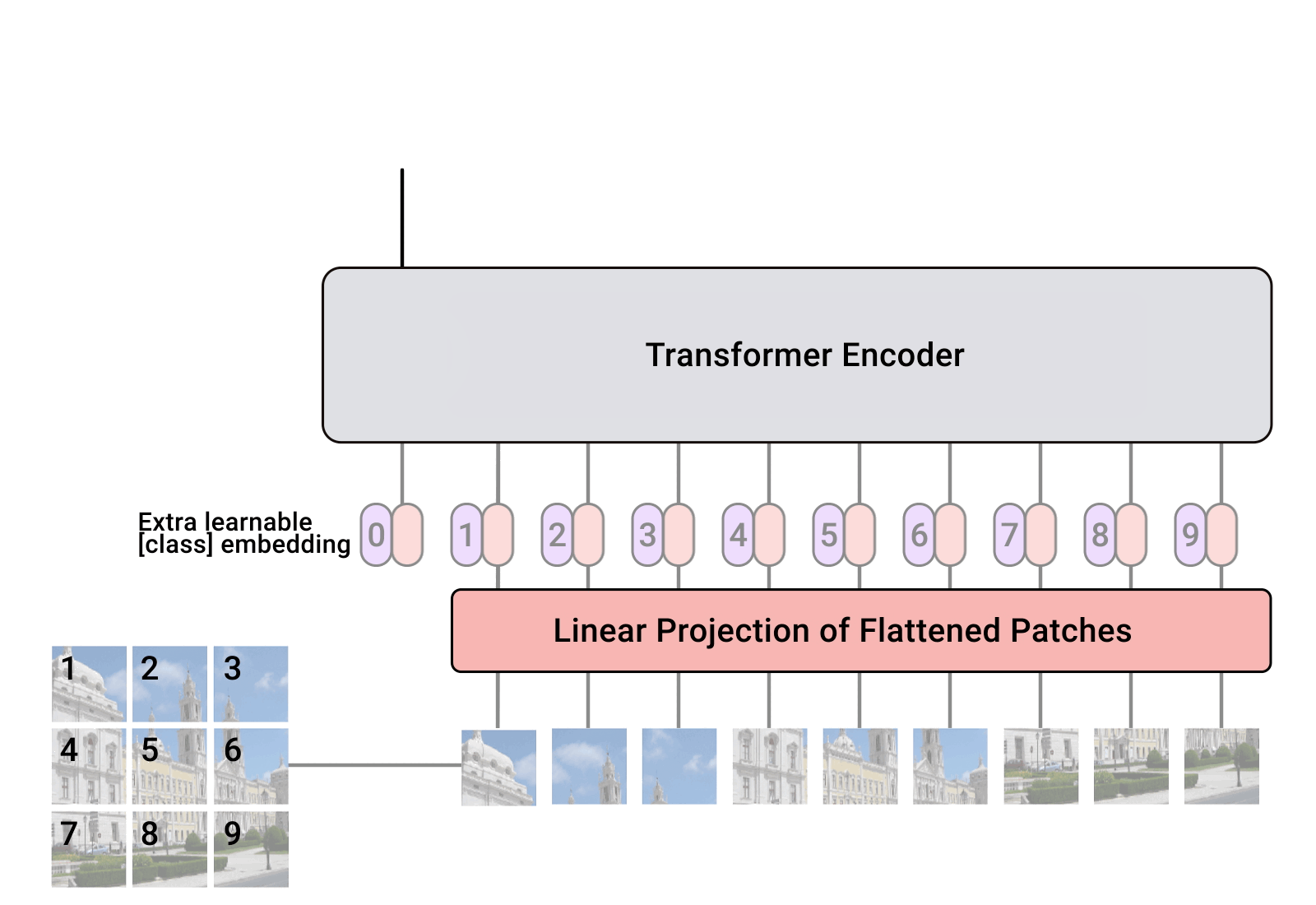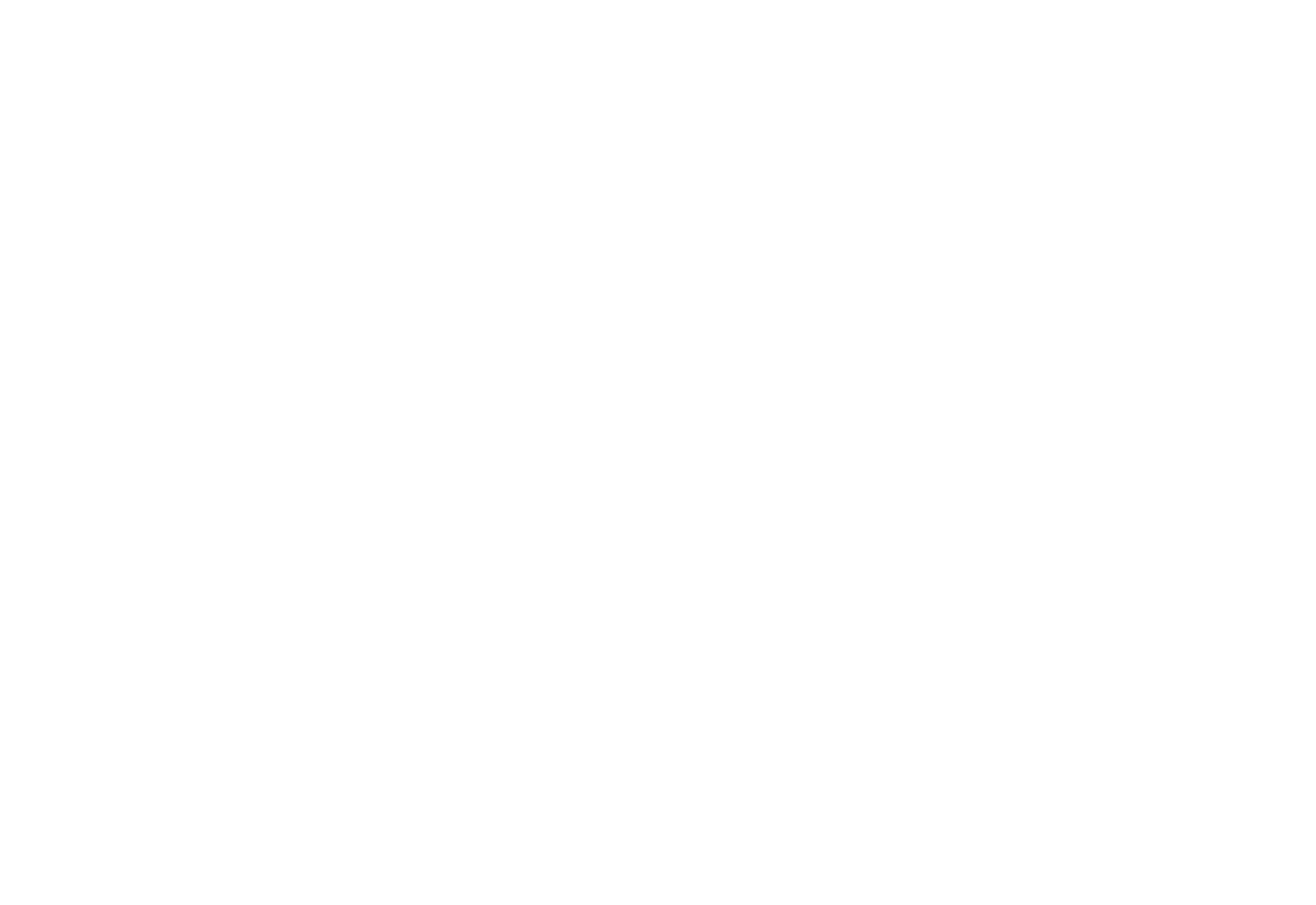
论文名称:An Image Is Worth 16x16 Words: Transformers For Image Recognition At Scale (opens new window)
原论文对应源码:https://github.com/google-research/vision_transformer (opens new window)
PyTorch 实现代码: pytorch_classification/vision_transformer (opens new window)
Tensorflow2 实现代码:tensorflow_classification/vision_transformer (opens new window)
在 bilibili 上的视频讲解:https://www.bilibili.com/video/BV1Jh411Y7WQ (opens new window)
一 前言
Transformer (opens new window)最初提出是针对 NLP 领域的,并且在 NLP 领域大获成功。这篇论文也是受到其启发,尝试将 Transformer 应用到 CV 领域。通过这篇文章的实验,给出的最佳模型在 ImageNet1K 上能够达到 88.55%的准确率(先在 Google 自家的 JFT 数据集上进行了预训练),说明 Transformer 在 CV 领域确实是有效的,而且效果还挺惊人。

二 Vision Transformer 模型详解
下图是原论文中给出的关于 Vision Transformer(ViT)的模型框架。简单而言,模型由三个模块组成:
- Linear Projection of Flattened Patches(Embedding 层)
- Transformer Encoder(图右侧有给出更加详细的结构)
- MLP Head(最终用于分类的层结构)

2.1 Embedding 层结构详解
对于标准的 Transformer 模块,要求输入的是 token(向量)序列,即二维矩阵[num_token, token_dim],如下图,token0-9 对应的都是向量,以 ViT-B/16 为例,每个 token 向量长度为 768。

对于图像数据而言,其数据格式为[H, W, C]是三维矩阵明显不是 Transformer 想要的。所以需要先通过一个 Embedding 层来对数据做个变换。如下图所示,首先将一张图片按给定大小分成一堆 Patches。以 ViT-B/16 为例,将输入图片(224x224)按照 16x16 大小的 Patch 进行划分,划分后会得到[16, 16, 3] -> [768]

在代码实现中,直接通过一个卷积层来实现。 以 ViT-B/16 为例,直接使用一个卷积核大小为 16x16,步距为 16,卷积核个数为 768 的卷积来实现。通过卷积[224, 224, 3] -> [14, 14, 768],然后把 H 以及 W 两个维度展平即可[14, 14, 768] -> [196, 768],此时正好变成了一个二维矩阵,正是 Transformer 想要的。

在输入 Transformer Encoder 之前注意需要加上[class]token 以及 Position Embedding。 在原论文中,作者说参考 BERT,在刚刚得到的一堆 tokens 中插入一个专门用于分类的[class]token,这个[class]token 是一个可训练的参数,数据格式和其他 token 一样都是一个向量,以 ViT-B/16 为例,就是一个长度为 768 的向量,与之前从图片中生成的 tokens 拼接在一起,Cat([1, 768], [196, 768]) -> [197, 768]。然后关于 Position Embedding 就是之前 Transformer 中讲到的 Positional Encoding,这里的 Position Embedding 采用的是一个可训练的参数(1D Pos. Emb.),是直接叠加在 tokens 上的(add),所以 shape 要一样。以 ViT-B/16 为例,刚刚拼接[class]token 后 shape 是[197, 768],那么这里的 Position Embedding 的 shape 也是[197, 768]。

在 Bert(及其它 NLP 任务中):
输入 = token_embedding(将单个词转变为词向量) +position_embedding(位置编码,用于表示 token 在输入序列中的位置) + segment_emebdding(非必须,在 bert 中用于表示每个词属于哪个句子)。
在 ViT 中,同样存在 token_embedding 和 postion_emebedding。

2.1.1 Token Emebdding
我们记 token emebdding 为(768, 768)的矩阵。
由前文知经过 patch 处理后输入(196, 768),则输入
你可能想问,输入 (196,768)的矩阵啊,我为什么还要过一次 embedding 呢?
这个问题的关键不在于数据的维度,而在于 embedding 的含义。原始的
2.1.2 Position Embedding(位置向量)
记位置向量为(196,768)的矩阵,表示 196 个维度为 768 的向量,每个向量表示对应 token 的位置信息。
构造位置向量的方法有很多种,在 ViT 中,作者做了不同的消融实验,来验证不同方案的效果(论文附录 D.4)部分。在源码中默认使用的是1D Pos. Emb.,对比不使用Position Embedding准确率提升了大概3个点,和2D Pos. Emb.比起来没太大差别。
方案一:不添加任何位置信息
将输入视为一堆无序的 patch,不往其中添加任何位置向量。
方案二:使用 1-D 绝对位置编码
也就是我们在上文介绍的方案,这也是 ViT 最终选定的方案。1-D 绝对位置编码又分为函数式(Transformer 的三角函数编码,详情可参见这篇文章 (opens new window))和可学习式(Bert 采用编码方式),ViT 采用的是后者。之所以被称为“绝对位置编码”,是因为位置向量代表的是 token 的绝对位置信息(例如第 1 个 token,第 2 个 token 之类)。
方案三:使用 2-D 绝对位置编码

如图所示,因为图像数据的特殊性,在 2-D 位置编码中,认为按全局绝对位置信息来表示一个 patch 是不足够的(如左侧所示),一个 patch 在 x 轴和 y 轴上具有不同含义的位置信息(如右侧所示)。因此,2-D 位置编码将原来的 PE 向量拆成两部分来分别训练。
方案四:相对位置编码(relative positional embeddings)

相对位置编码(RPE)的设计思想是**:我们不应该只关注patch的绝对位置信息,更应该关注patch间的相对位置信息**。如图所示,对于token4,它和其余每一个token间都存在相对位置关系,我们分别用
那么接下来,只要在正常计算attention的过程中,将这5个向量当作bias添加到计算过程中(如图公式所示),我们就可以正常训练这些相对位置向量了。为了减少训练时的参数量,我们还可以做clip操作,在制定clip的步数
关于相对位置编码的更多信息,可以阅读原始论文 (opens new window)
实验结果
这四种位置编码方案的实验结果如下:

可以发现除了“不加任何位置编码”的效果显著低之外,其余三种方案的结果都差不多。所以作者们当然选择最快捷省力的 1-D 位置编码方案啦。当你在阅读 ViT 的论文中,会发现大量的消融实验细节(例如分类头<cls>要怎么加),作者这样做的目的也很明确:“我们的方案是在诸多可行的方法中,逐一做实验比对出来的,是全面考虑后的结果。”这也是我一直觉得这篇论文在技术之外值得借鉴和反复读的地方。
2.2 为什么要处理成 patch
第一个原因,是为了减少模型计算量。
在Transformer中,假设输入的序列长度为
在ViT中,
第二个原因,是图像数据带有较多的冗余信息。
和语言数据中蕴含的丰富语义不同,像素本身含有大量的冗余信息。比如,相邻的两个像素格子间的取值往往是相似的。因此我们并不需要特别精准的计算粒度(比如把
2.3 Transformer Encoder 详解
Transformer Encoder 其实就是重复堆叠 Encoder Block
- Layer Norm,这种 Normalization 方法主要是针对 NLP 领域提出的,这里是对每个 token 进行 Norm 处理,之前也有讲过 Layer Norm 不懂的可以参考链接 (opens new window)
- Multi-Head Attention,这个结构之前在讲 Transformer 中很详细的讲过,不在赘述,不了解的可以参考链接 (opens new window)
- Dropout/DropPath,在原论文的代码中是直接使用的 Dropout 层,但在
rwightman实现的代码中使用的是 DropPath(stochastic depth),可能后者会更好一点。 - MLP Block,如图右侧所示,就是全连接+GELU 激活函数+Dropout 组成也非常简单,需要注意的是第一个全连接层会把输入节点个数翻 4 倍
[197, 768] -> [197, 3072],第二个全连接层会还原回原节点个数[197, 3072] -> [197, 768]

2.4 MLP Head 详解
上面通过 Transformer Encoder 后输出的 shape 和输入的 shape 是保持不变的,以 ViT-B/16 为例,输入的是[197, 768]输出的还是[197, 768]。注意,在 Transformer Encoder 后其实还有一个 Layer Norm 没有画出来,后面有我自己画的 ViT 的模型可以看到详细结构。这里我们只是需要分类的信息,所以我们只需要提取出[class]token 生成的对应结果就行,即[197, 768]中抽取出[class]token 对应的[1, 768]。接着我们通过 MLP Head 得到我们最终的分类结果。MLP Head 原论文中说在训练 ImageNet21K 时是由Linear+tanh激活函数+Linear组成。但是迁移到 ImageNet1K 上或者你自己的数据上时,只用一个Linear即可。

网络结构详细图(以 ViT-B/16 为例)

算法结构图左侧 Patch Embedding 的 shape 是 196*768
三 Hybrid 模型详解
在论文 4.1 章节的Model Variants中有比较详细的讲到 Hybrid 混合模型,就是将传统 CNN 特征提取和 Transformer 进行结合。下图绘制的是以 ResNet50 作为特征提取器的混合模型,但这里的 Resnet 与之前讲的 Resnet 有些不同。首先这里的 R50 的卷积层采用的 StdConv2d 不是传统的 Conv2d,然后将所有的 BatchNorm 层替换成 GroupNorm 层。在原 Resnet50 网络中,stage1 重复堆叠 3 次,stage2 重复堆叠 4 次,stage3 重复堆叠 6 次,stage4 重复堆叠 3 次,但在这里的 R50 中,把 stage4 中的 3 个 Block 移至 stage3 中,所以 stage3 中共重复堆叠 9 次。

通过 R50 Backbone 进行特征提取后,得到的特征矩阵 shape 是[14, 14, 1024],接着再输入 Patch Embedding 层,注意 Patch Embedding 中卷积层 Conv2d 的 kernel_size 和 stride 都变成了 1,只是用来调整 channel。后面的部分和前面 ViT 中讲的完全一样,就不在赘述。
下表是论文用来对比 ViT,Resnet(和刚刚讲的一样,使用的卷积层和 Norm 层都进行了修改)以及 Hybrid 模型的效果。通过对比发现,在训练 epoch 较少时 Hybrid 优于 ViT,但当 epoch 增大后 ViT 优于 Hybrid。

四 模型架构的数学表达
训练中的计算过程:
:第 i 块 patch :Token Embedding,1-D Positional Embedding :和 Bert 类似,是额外加的一个分类头 :最终 ViT 的输入
(1)即是我们说的图像预处理过程,(2)即是计算 multi-head attention 的过程,(3)是计算 MLP 的过程。(4)是最终分类任务,LN 表示是一个简单的线性分类模型,<cls>对应的向量。
五 ViT 效果
5.1 不同 ViT 模型的表示符号
5.2 ViT VS 卷积神经网络
既然 ViT 的目的是替换卷积神经网络,那么当然要比较一下它和目前 SOTA 的卷积网络间的性能了。
作者选取了 ResNet 和 Noisy Student 这两种经典高性能的卷积神经网络与 ViT 进行比较,比较内容为预测图片类别的准确性与训练时长,结果如下:

前三列 Ours-JFT(ViT-H/14),Ours-JFT(ViT-L/16),Ours-I12K(ViT-L/16)表示三个 ViT 预训练模型,它们分别在不同规模和不同数据集(JFT, I12K)上预训练而来。后两列表示两个卷积神经网络模型。
纵向的 ImageNet,ImageNet Real 等表示不同的图像数据集,当我们的 ViT 模型和卷积模型预训练好后,我们就可以借助这些 pretrain 模型,在图像数据集上做 fine-tune,而表格里给出的就是 fine-tune 后的准确率。
观察表格,我们发现一个有趣的现象**:ViT 和卷积神经网络相比,表现基本一致**。关于这一点,我们会在下文详细分析。虽然准确率没有突出表现,但是训练时间上 ViT 的还是有亮点的,表格最后一行表示,假设用单块 TPU 训练模型,所需要的天数。我们发现 ViT 最高也只需要 2500 核-天(当然其实这个值也不小啦),卷积网络要花至 9900 核-天以上。所以 ViT 的一个优势在于,训练没那么贵了。关于这点,我的猜想是基于 Transformer 架构的 ViT,和卷积神经网络相比,更适合做切分均匀的矩阵计算,这样我们就能把参数均匀切到不同卡上做分布式训练,更好利用 GPU 算力,平衡整个训练系统了。
现在,我们回到刚才的问题,为什么 ViT 相比卷积网络,在准确率上没有突出优势?为了解答这个问题,我们先来看卷积神经网络的归纳偏置(inductive biases)
5.2.1 卷积神经网络的归纳偏置
归纳偏置用大白话来说,就是一种假设,或者说一种先验知识。有了这种先验,我们就能知道哪一种方法更适合解决哪一类任务。所以归纳偏置是一种统称,不同的任务其归纳偏置下包含的具体内容不一样。
对图像任务来说,它的归纳偏置有以下两点:
- 空间局部性(locality):假设一张图片中,相邻的区域是有相关特征的。比如太阳和天空就经常一起出现。
- 平移等边性(translation equivariance):
。假设一张图中,左上角有一个太阳,你对这张图正常做卷积得到特征图,则左上角的卷积可表示为 ,做完卷积后,你想把左上角的特征图移动到右上角去,则你这一顿操作可以用 来表示。这一系列操作等同于,你先把左上角的太阳移动到右上角去( ),然后再做卷积 ,这就是图像的平移等边性。不论物体移动到哪里,只要给卷积核的输入不变,那么输出也是一致的。
在这两种先验假设下,CNN成为了图像任务最佳的方案之一。卷积核能最大程度保持空间局部性(保存相关物体的位置信息)和平移等边性,使得在训练过程中,最大限度学习和保留原始图片信息。
好,那么现在,如果说ViT相比于卷积,在图像任务上没有显著优势,那大概率ViT对这两种先验的维护没有CNN做的好,具体来看:

图中箭头所指的两部分都属于同一栋建筑。在卷积中,我们可以用大小适当的卷积核将它们圈在一起。但是在ViT中,它们之间的位置却拉远了,如果我把patch再切分细一些,它们的距离就更远了。虽然attention可以学习到向量间的想关系,但是ViT在空间局部性的维护上,确实没有卷积做的好。而在平移等边性上,由于ViT需要对patch的位置进行学习,所以对于一个patch,当它位置变幻时,它的输出结果也是不一样的。所以,ViT的架构没有很好维护图像问题中的归纳偏置假设。
但是,这就意味着ViT没有翻盘的一天了吗?当然不是,不要忘了,Transformer架构的模型都有一个广为人知的特性:大力出奇迹。只要它见过的数据够多,它就能更好地学习像素块之间的关联性,当然也能抹去归纳偏置的问题。
5.2.2 ViT:大力出奇迹
作者当然也考虑到了这点,所以采用了不同数量的数据集,对 ViT 进行训练,效果如下:

如图,横轴表示不同量级的数据集(越往右数据集越大),纵轴表示准确率。图中灰色阴影部分表示在相应数据集下,不同架构的卷积神经网络的准确率范围。可以发现,当数据集较小时,ViT表现明显弱于卷积网络。但当数据量级大于21k时,ViT的能力就上来了。
5.3 ViT 的 Attention 到底看到了什么
讲完了 ViT 的整体效果,我们来探究下 ViT 具体学到了什么,才能帮助它达到这样的效果。我们首先来看 attention 层。

这张实验图刻画了ViT的16个multi-head attention学到的像素距离信息。横轴表示网络的深度,纵轴表示“平均注意力距离”,我们设第
图中每一列上,都有16个彩色原点,它们分别表示16个head观测到的平均像素距离。由图可知,在浅层网络中,ViT还只能关注到距离较近的像素点,随着网络加深,ViT逐渐学会去更远的像素点中寻找相关信息了。这个过程就和用在CNN中用卷积逐层去扩大感受野非常相似。
下图的左侧表示原始的输入图片,右侧表示ViT最后一层看到的图片信息,可以清楚看见,ViT在最后一层已经学到了将注意力放到关键的物体上了,这是非常有趣的结论:

5.4 ViT 的位置编码学到了什么
我们在上文讨论过图像的空间局部性(locality),即有相关性的物体(例如太阳和天空)经常一起出现。CNN采用卷积框取特征的方式,极大程度上维护了这种特性。其实,ViT也有维护这种特性的方法,上面所说的attention是一种,位置编码也是一种。
我们来看看ViT的位置编码学到了什么信息:

上图是ViT-L/32模型下的位置编码信息,图中每一个方框表示一个patch,图中共有7*7个patch。而每个方框内,也有一个7*7的矩阵,这个矩阵中的每一个值,表示当前patch的position embedding和其余对应位置的position embedding的余弦相似度。颜色越黄,表示越相似,也即patch和对应位置间的patch密切相关。
注意到每个方框中,最黄的点总是当前patch所在位置,这个不难理解,因为自己和自己肯定是最相似的。除此以外颜色较黄的部分都是当前patch所属的行和列,以及以当前patch为中心往外扩散的一小圈。这就说明ViT通过位置编码,已经学到了一定的空间局部性。
六 总结:ViT 的意义何在
到此为止,关于 ViT 模型,我们就介绍完毕了。一顿读下来,你可能有个印象:如果训练数据量不够多的话,看起来 ViT 也没比 CNN 好多少呀,ViT 的意义是什么呢?
这是个很好的问题**,因为在工业界,人们的标注数据量和算力都是有限的**,因此 CNN 可能还是首要选择。
但是,ViT 的出现,不仅是用模型效果来考量这么简单,今天再来看这个模型,发现它的意义在于:
- 证明了一个统一框架在不同模态任务上的表现能力。在 ViT 之前,NLP 的 SOTA 范式被认为是 Transformer,而图像的 SOTA 范式依然是 CNN。ViT 出现后,证明了用 NLP 领域的 SOTA 模型一样能解图像领域的问题,同时在论文中通过丰富的实验,证明了 ViT 对 CNN 的替代能力,同时也论证了大规模+大模型在图像领域的涌现能力(论文中没有明确指出这是涌现能力,但通过实验展现了这种趋势)。这也为后续两年多模态任务的发展奠定了基石。
- 虽然 ViT 只是一个分类任务,但在它提出的几个月之后,立刻就有了用 Transformer 架构做检测(detection)和分割(segmentation)的模型。而不久之后,GPT 式的无监督学习,也在 CV 届开始火热起来。
- 工业界上,对大部分企业来说,受到训练数据和算力的影响,预训练和微调一个 ViT 都是困难的,但是这不妨碍直接拿大厂训好的 ViT 特征做下游任务。同时,低成本的微调方案研究,在今天也层出不穷。
七 ViT改进
在迁移学习方面,即先在ImageNet上预训练,然后在其它分类数据集上finetune,这里测试了6个数据集,结果如下表所示,其中在较小的数据集上(CARS和Flowers,训练数据较少,类别少),只finetune attention层效果比finetune全部层要好一点。但是在其它较大一点的数据集上(INAT-18,INAT-19和CIFAR-100),只finetune attention层和finetune全部层存在较大的性能gap,而且也差于只finetune FFN层。这主要是因为这些数据集存在较多的ImageNet1K没有的新类别,需要更多的参数来学习,而attention层的参数只占整个模型的1/3;对于较大的模型如ViT-L,其性能gap就较小一点,因为此时attention层参数也达到了finetune所需。
Reference
- Vision Transformer 详解 (opens new window)
- https://arxiv.org/pdf/2010.11929.pdf
- https://www.bilibili.com/video/BV15P4y137jb/?spm_id_from=333.337.search-card.all.click
- https://arxiv.org/pdf/1803.02155.pdf
- https://blog.csdn.net/qq_44166630/article/details/127429697
- 再读 ViT,还有多少细节是你不知道的 (opens new window)