 Recurrent Neural Networks
Recurrent Neural Networks
Recurrent Neural Networks
RNN,或者说最常用的LSTM,一般用于记住之前的状态,以供后续神经网络的判断,它由input gate、forget gate、output gate和cell memory组成,每个LSTM本质上就是一个neuron,特殊之处在于有4个输入:
三门控制信号 、 ,每个时间点的输入都是由当前输入值+上一个时间点的输出值+上一个时间点cell值来组成
应用举例
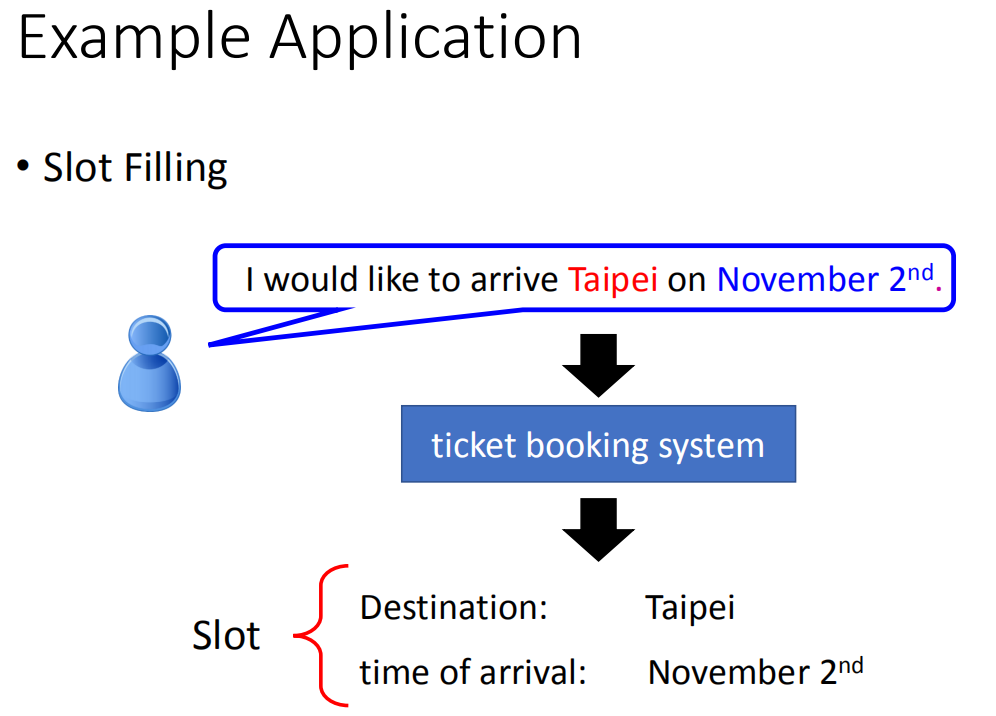
这边举的例子是slot filling,我们假设订票系统听到用户说:“ i would like to arrive Taipei on November 2nd”,你的系统有一些slot(有一个slot叫做Destination,一个slot叫做time of arrival),系统要自动知道这边的每一个词汇是属于哪一个slot,比如Taipei属于Destination这个slot,November 2nd属于time of arrival这个slot。
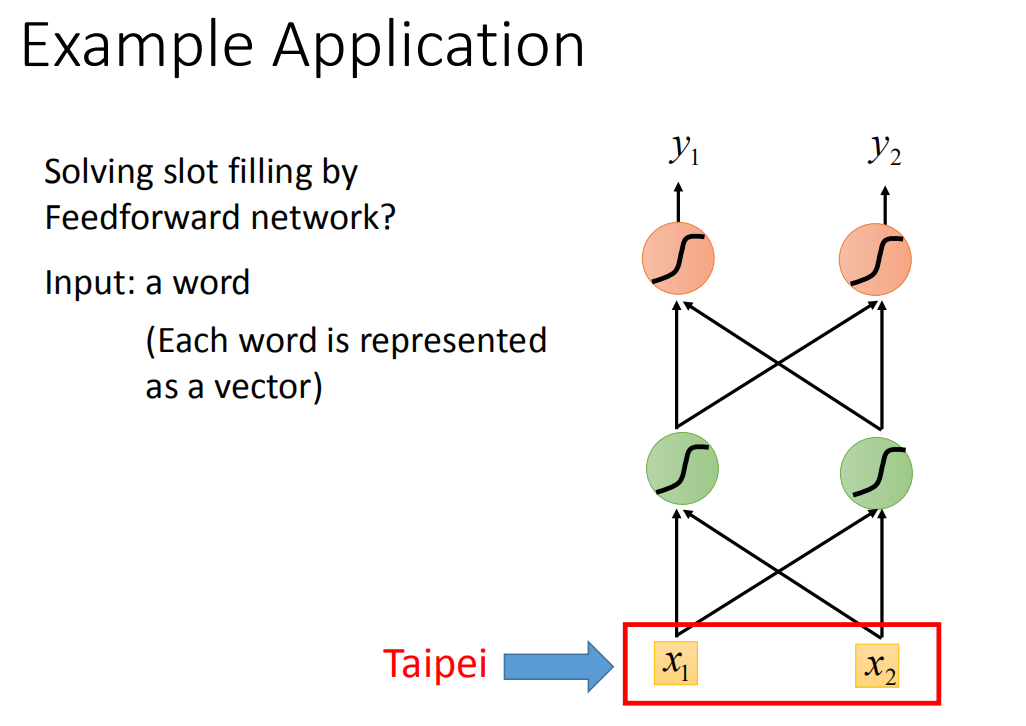
这个问题你当然可以使用一个feedforward neural network来解,也就是说我叠一个feedforward neural network,input是一个词汇(把Taipei变成一个vector)丢到这个neural network里面去(你要把一个词汇丢到一个neural network里面去,就必须把它变成一个向量来表示)。以下是把词汇用向量来表示的方法:
1-of-N encoding

Beyond 1-of-N encoding
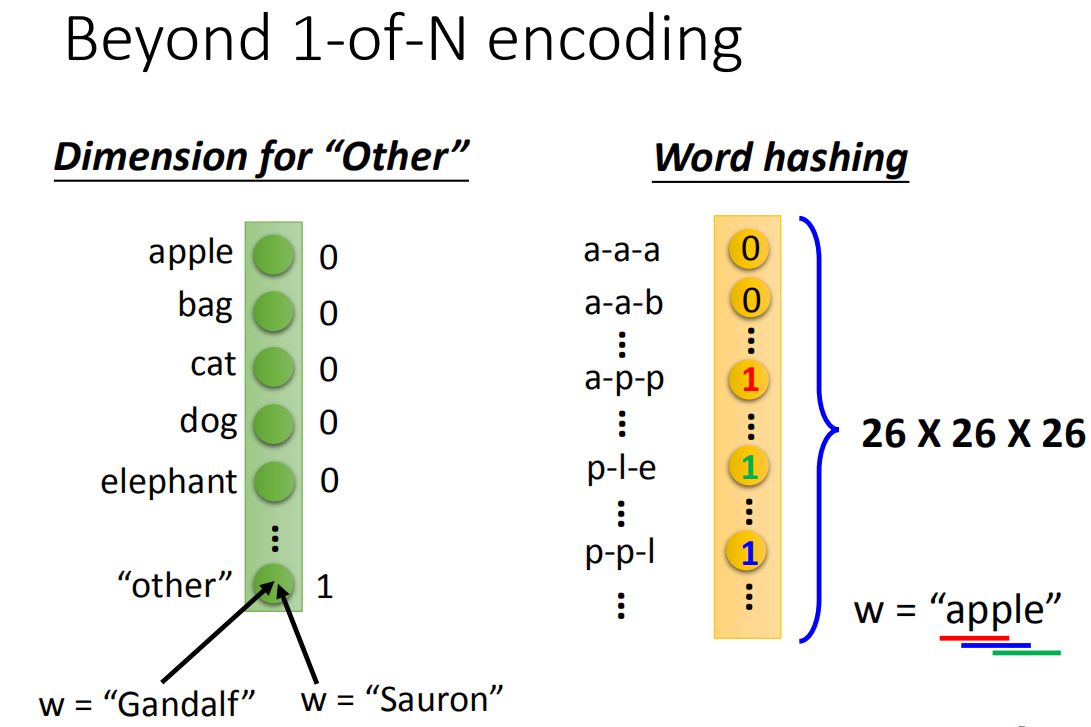
如果只是用1-of-N encoding来描述一个词汇的话你会遇到一些问题,因为有很多词汇你可能都没有见过,所以你需要在1-of-N encoding里面多加dimension,这个dimension代表other。然后所有的词汇,如果它不是在我们词言有的词汇就归类到other里面去(Gandalf,Sauron归类到other里面去)。你可以用每一个词汇的字母来表示它的vector,比如说,你的词汇是apple,apple里面有出现app、ppl、ple,那在这个vector里面对应到app,ple,ppl的dimension就是1,而其他都为0。
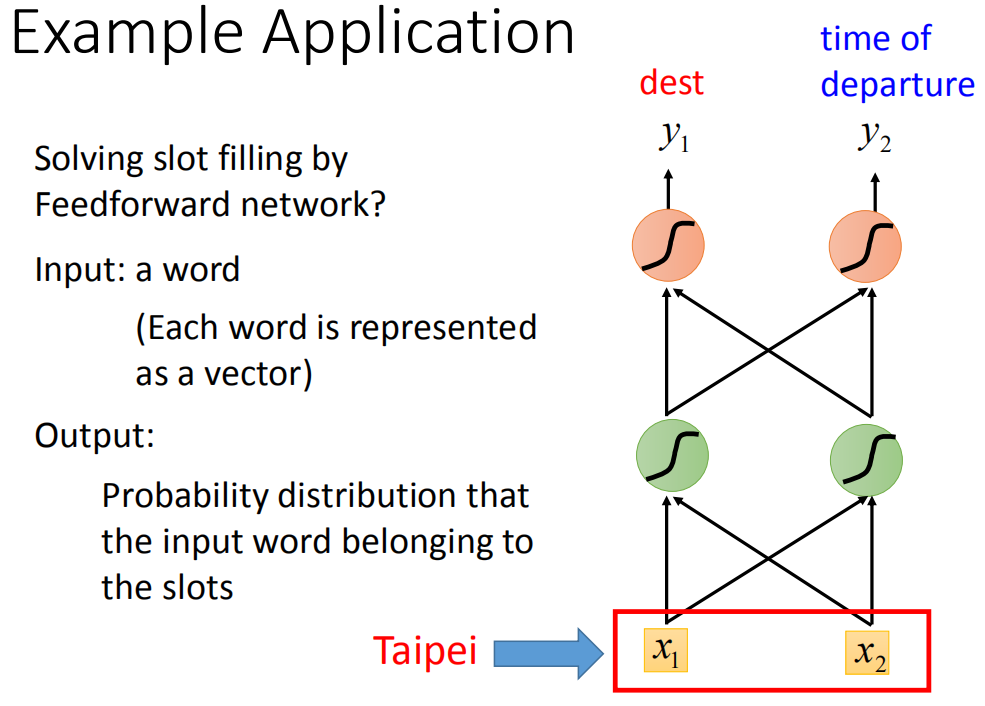
假设把词汇表示为vector,把这个vector丢到feedforward neural network里面去,在这个task里面,你就希望你的output是一个probability distribution。这个probability distribution代表着我们现在input这词汇属于每一个slot的几率,比如Taipei属于destination的几率和Taipei属于time of departure的几率。
但是光只有这个是不够的,feedforward neural network是没有办法解决这个问题。为什么呢,假设现在有一个使用者说:“arrive Taipei on November 2nd”(arrive-other,Taipei-dest, on-other,November-time,2nd-time)。那现在有人说:"leave Taipei on November 2nd",这时候Taipei就变成了“place of departure”,它应该是出发地而不是目的地。但是对于neural network来说,input一样的东西output就应该是一样的东西(input "Taipei",output要么是destination几率最高,要么就是place of departure几率最高),你没有办法一会让出发地的几率最高,一会让它目的地几率最高。这个怎么办呢?这时候就希望我们的neural network是有记忆力的。如果今天我们的neural network是有记忆力的,它记得它看过红色的Taipei之前它就已经看过arrive这个词汇;它记得它看过绿色之前,它就已经看过leave这个词汇,它就可以根据上下文产生不同的output。如果让我们的neural network是有记忆力的话,它就可以解决input不同的词汇,output不同的问题。
但是光只有这个是不够的,feedforward network是没有办法slot这个probability。为什么呢,假设现在有一个使用者说:“arrive Taipei on November 2nd”(arrive-other,Taipei-dest, on-other,November-time,2nd-time)。那现在有人说:"leave Taipei on November 2nd",这时候Taipei就变成了“place of departure”,它应该是出发地而不是目的地。但是对于neural network来说,input一样的东西output就应该是一样的东西(input "Taipei",output要么是destination几率最高,要么就是time of departure几率最高),你没有办法一会让出发地的几率最高,一会让它目的地几率最高。这个肿么办呢?这时候就希望我们的neural network是有记忆力的。如果今天我们的neural network是有记忆力的,它记得它看过红色的Taipei之前它就已经看过arrive这个词汇;它记得它看过绿色之前,它就已经看过leave这个词汇,它就可以根据上下文产生不同的output。如果让我们的neural network是有记忆力的话,它就可以解决input不同的词汇,output不同的问题。

RNN概述
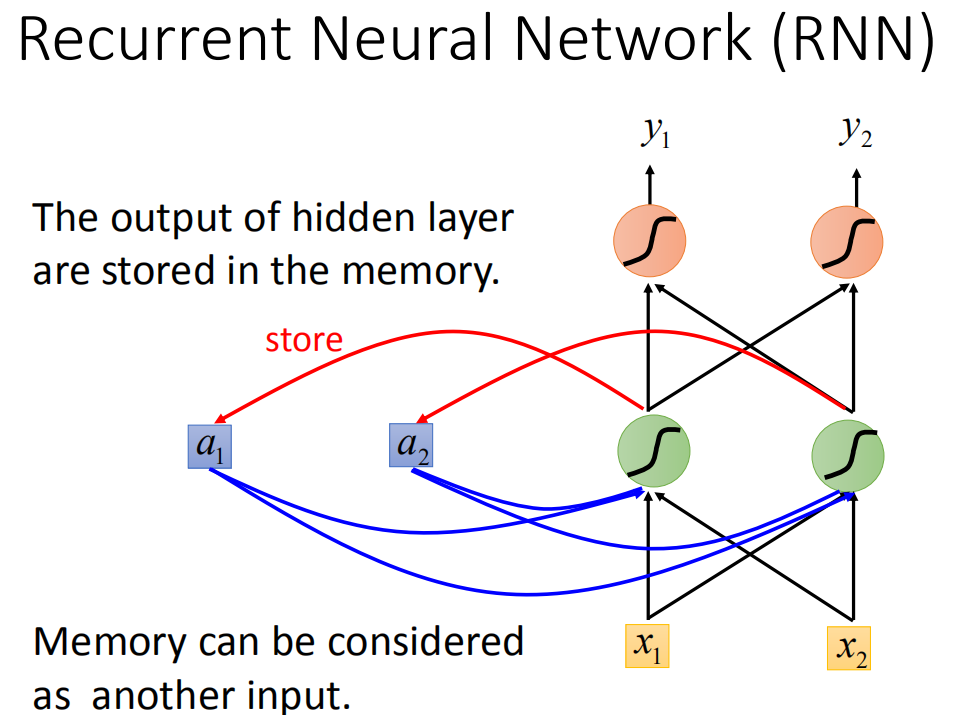
这种有记忆的neural network就叫做Recurrent Neural network(RNN)。在RNN里面,每一次hidden layer的neuron产生output的时候,这个output会被存到memory里去(用蓝色方块表示memory)。那下一次当有input时,这些neuron不只是考虑input
例子
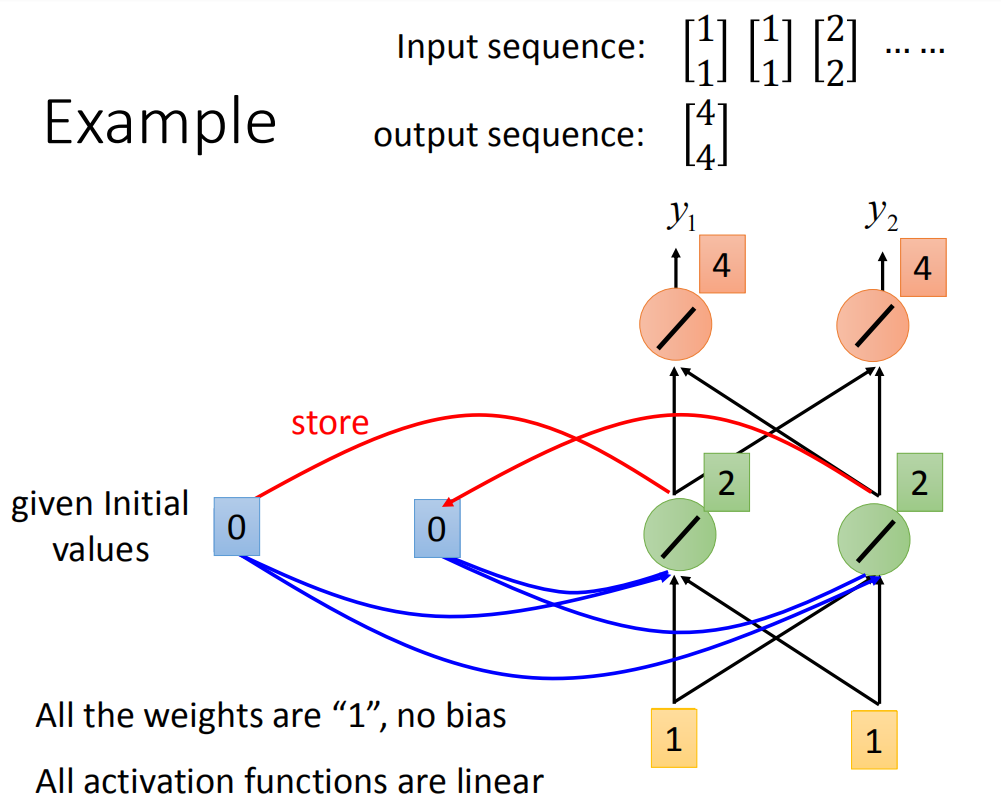
举个例子,假设我们现在图上这个neural network,它所有的weight都是1,所有的neuron没有任何的bias。假设所有的activation function都是linear(这样可以不要让计算太复杂)。现在假设我们的input 是sequence
现在输入第一个
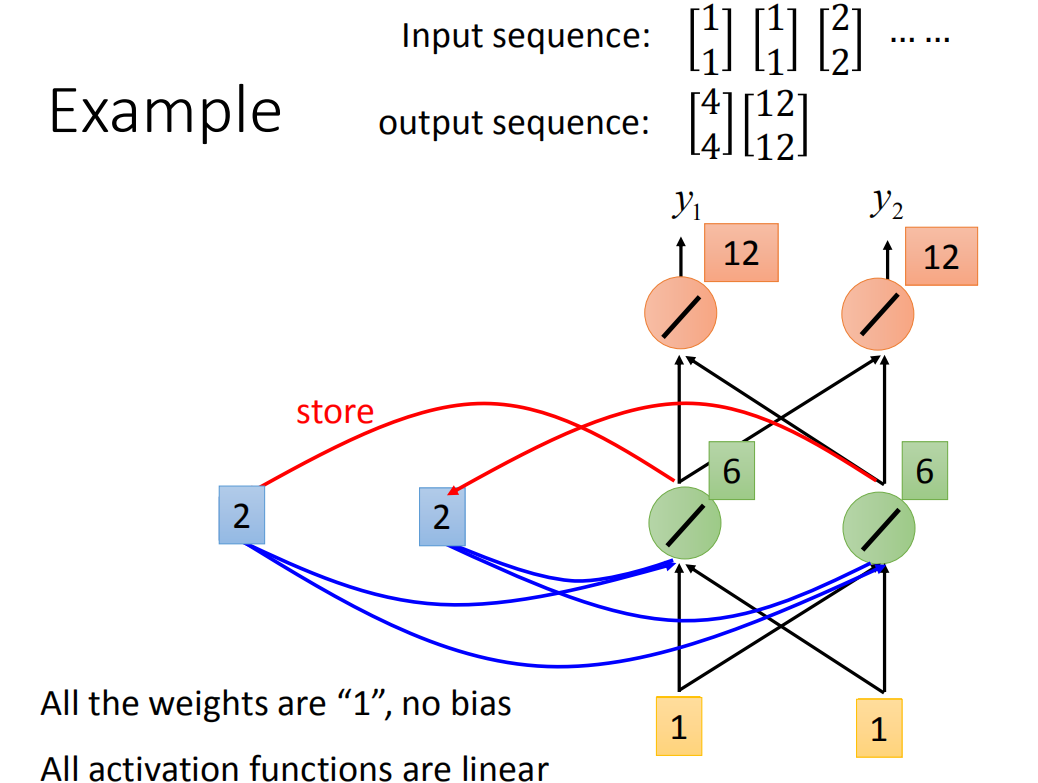
接下来Recurrent Neural Network会将绿色neuron的output存在memory里去,所以memory里面的值被update为2。
接下来再输入
所以对Recurrent Neural Network来说,你就算input一样的东西,它的output是可能不一样了(因为有memory)
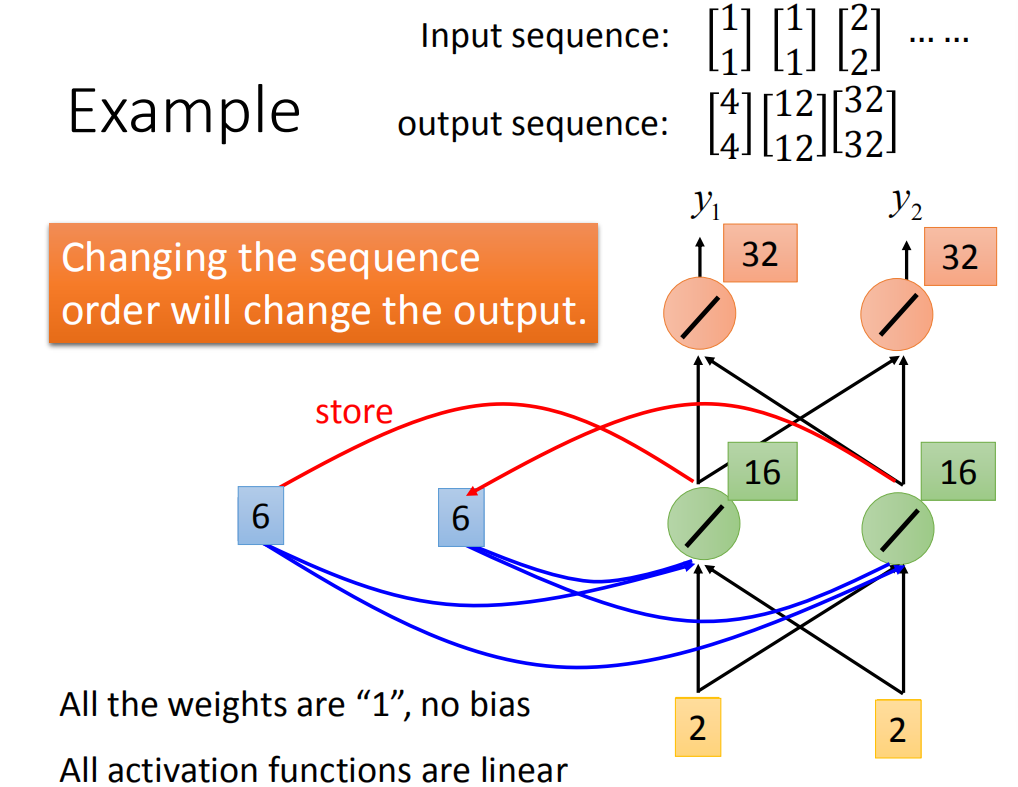
现在
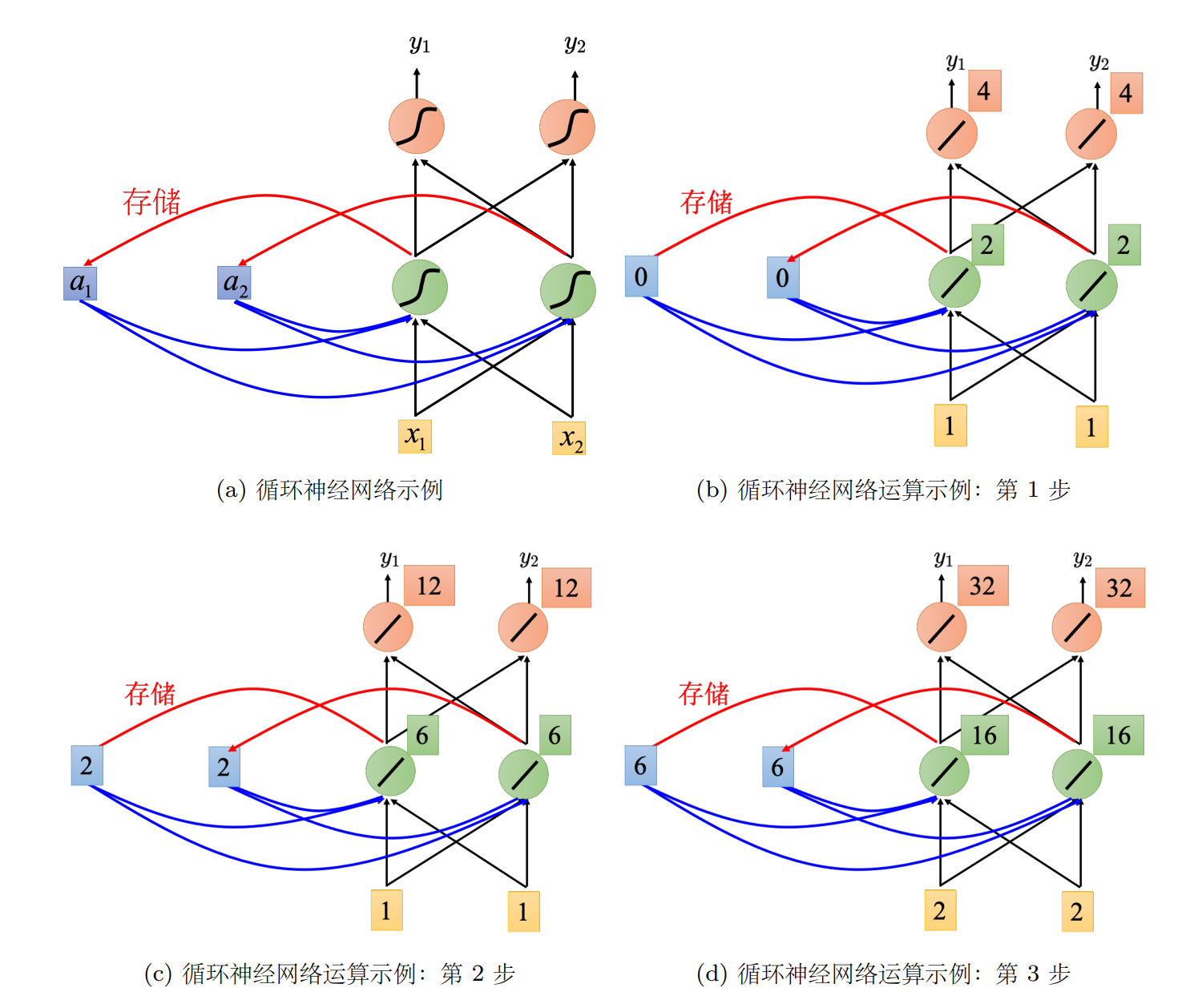
那在做Recurrent Neural Network时,有一件很重要的事情就是这个input sequence调换顺序之后output不同(Recurrent Neural Network里,它会考虑sequence的order)
RNN架构

今天我们要用Recurrent Neural Network处理slot filling这件事,就像是这样,使用者说:“arrive Taipei on November 2nd”,arrive就变成了一个vector丢到neural network里面去,neural network的hidden layer的output写成
有人看到这里,说这是有三个network,这个不是三个network,这是同一个network在三个不同的时间点被使用了三次。(我这边用同样的weight用同样的颜色表示)
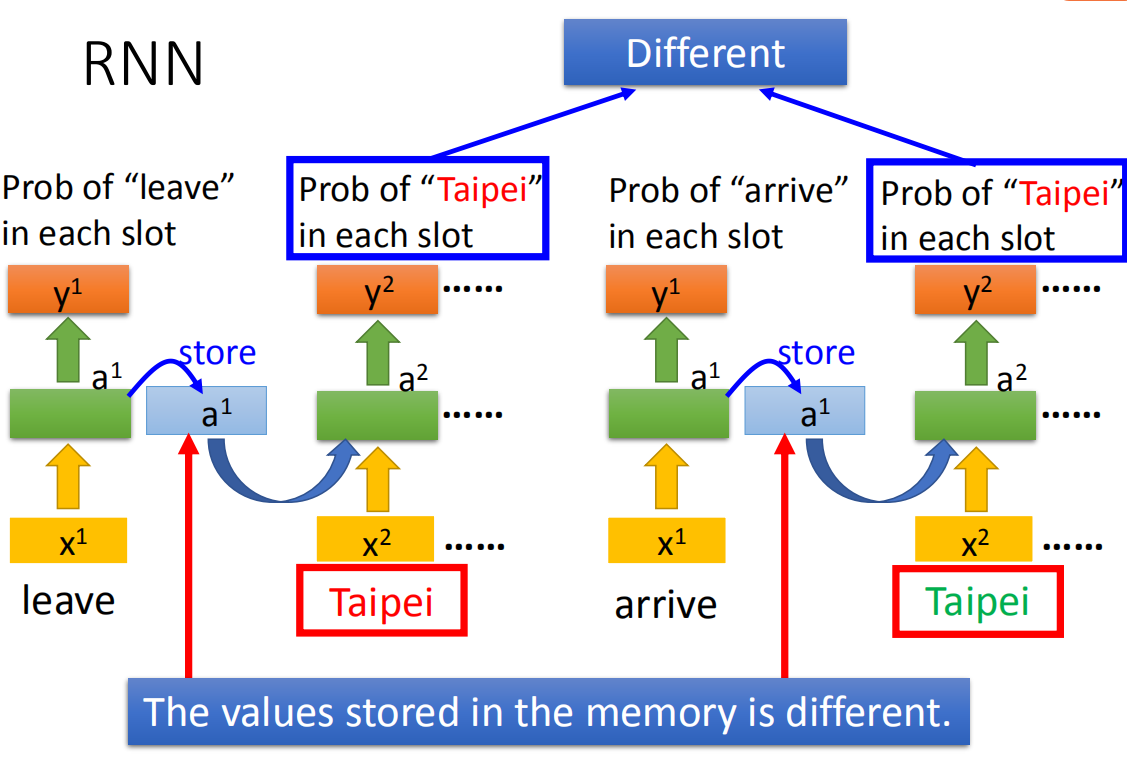
那所以我们有了memory以后,刚才我们讲了输入同一个词汇,我们希望output不同的问题就有可能被解决。比如说,同样是输入“Taipei”这个词汇,但是因为红色“Taipei”前接了“leave”,绿色“Taipei”前接了“arrive”(因为“leave”和“arrive”的vector不一样,所以hidden layer的output会不同),所以存在memory里面的值会不同。现在虽然
RNN怎么学习?
 如果要做learning的话,你要定义一个cost function来evaluate你的model是好还是不好,选一个parameter要让你的loss 最小。那在Recurrent Neural
Network里面,你会怎么定义这个loss呢,下面我们先不写算式,先直接举个例子。
如果要做learning的话,你要定义一个cost function来evaluate你的model是好还是不好,选一个parameter要让你的loss 最小。那在Recurrent Neural
Network里面,你会怎么定义这个loss呢,下面我们先不写算式,先直接举个例子。
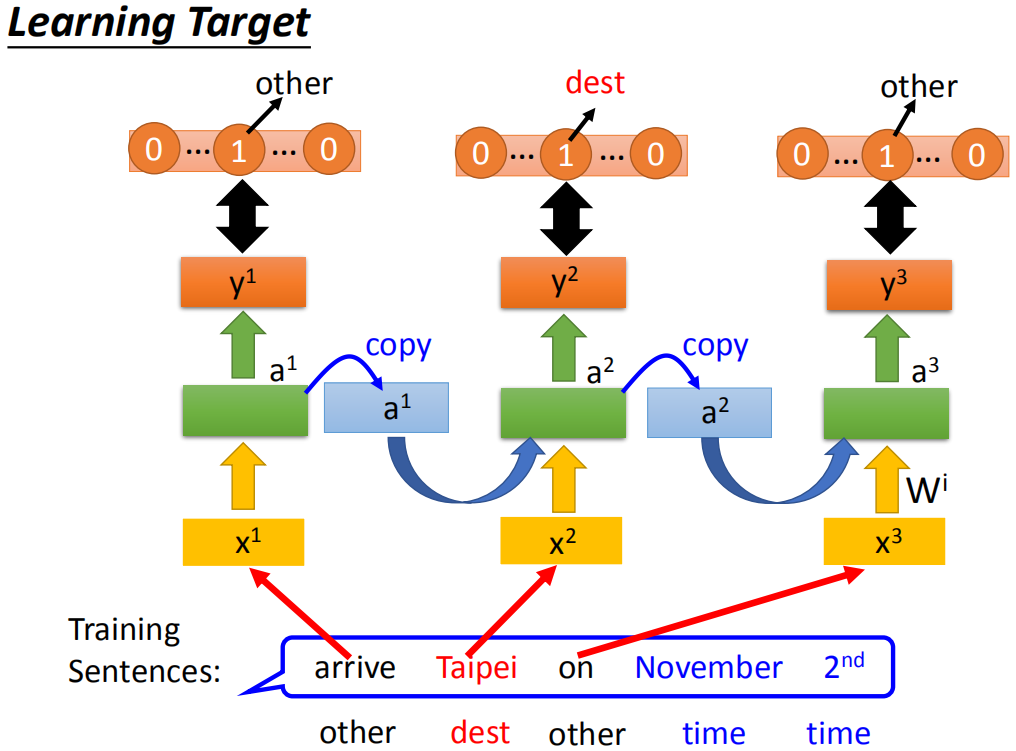
假设我们现在做的事情是slot filling,那你会有train data,那这个train data是说:我给你一些sentence,你要给sentence一些label,告诉machine说第一个word它是属于other slot,“Taipei是”Destination slot,"on"属于other
slot,“November”和“2nd”属于time slot,然后接下来你希望说:你的cost咋样定义呢。那“arrive”丢到Recurrent Neural Network的时候,Recurrent Neural Network会得到一个output
那现在把“Taipei”丢进去之后,因为“Taipei”属于destination slot,就希望说把
那这边注意的事情就是,你在丢
RNN的损失函数output和reference vector的entropy的和就是要最小化的对象。
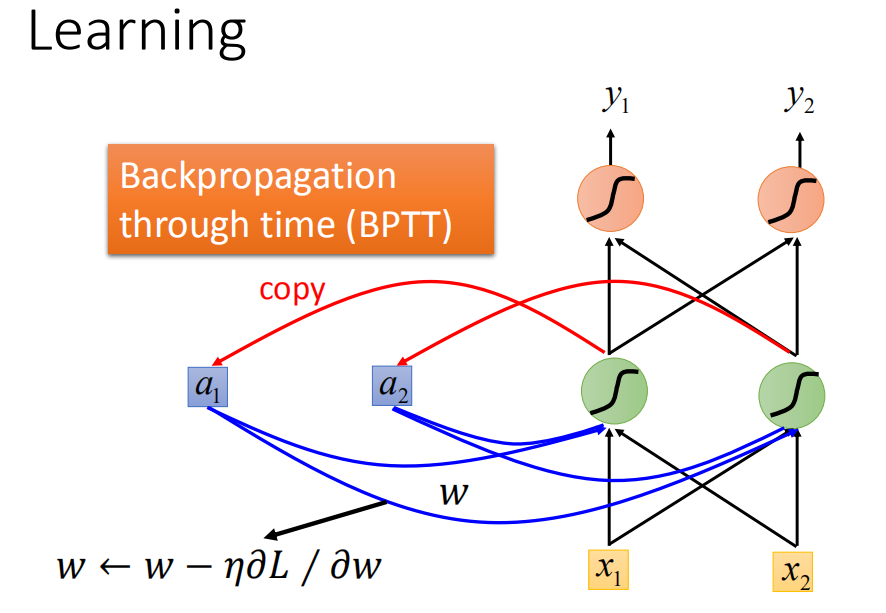 有了这个loss function以后,对于training,也是用梯度下降来做。也就是说我们现在定义出了loss function(L),我要update这个neural network里面的某个参数w,就是计算对w的偏微分,偏微分计算出来以后,就用GD的方法去update里面的参数。在讲feedforward neural network的时候,我们说GD用在feedforward neural network里面你要用一个有效率的算法叫做Backpropagation。那Recurrent Neural Network里面,为了要计算方便,所以也有开发一套算法是Backpropagation的进阶版,叫做BPTT。它跟Backpropagation其实是很类似的,只是Recurrent Neural Network它是在high sequence上运作,所以BPTT它要考虑时间上的information。
有了这个loss function以后,对于training,也是用梯度下降来做。也就是说我们现在定义出了loss function(L),我要update这个neural network里面的某个参数w,就是计算对w的偏微分,偏微分计算出来以后,就用GD的方法去update里面的参数。在讲feedforward neural network的时候,我们说GD用在feedforward neural network里面你要用一个有效率的算法叫做Backpropagation。那Recurrent Neural Network里面,为了要计算方便,所以也有开发一套算法是Backpropagation的进阶版,叫做BPTT。它跟Backpropagation其实是很类似的,只是Recurrent Neural Network它是在high sequence上运作,所以BPTT它要考虑时间上的information。
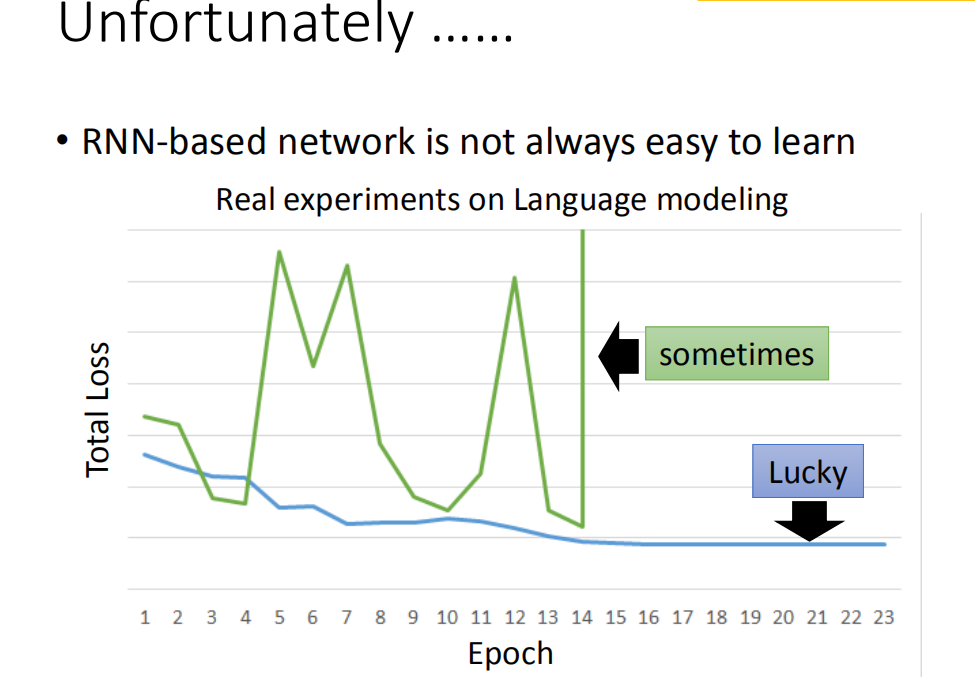 不幸的是,RNN的training是比较困难的。一般而言,你在做training的时候,你会期待,你的learning curve是像蓝色这条线,这边的纵轴是total loss,横轴是epoch的数目,你会希望说:随着epoch的数目越来越多,随着参数不断的update,loss会慢慢的下降最后趋向收敛。但是不幸的是你在训练Recurrent Neural Network的时候,你有时候会看到绿色这条线。如果你是第一次trai Recurrent Neural Network,你看到绿色这条learning curve非常剧烈的抖动,然后抖到某个地方,这时候你会有什么想法,我相信你会:这程序有bug啊。
不幸的是,RNN的training是比较困难的。一般而言,你在做training的时候,你会期待,你的learning curve是像蓝色这条线,这边的纵轴是total loss,横轴是epoch的数目,你会希望说:随着epoch的数目越来越多,随着参数不断的update,loss会慢慢的下降最后趋向收敛。但是不幸的是你在训练Recurrent Neural Network的时候,你有时候会看到绿色这条线。如果你是第一次trai Recurrent Neural Network,你看到绿色这条learning curve非常剧烈的抖动,然后抖到某个地方,这时候你会有什么想法,我相信你会:这程序有bug啊。
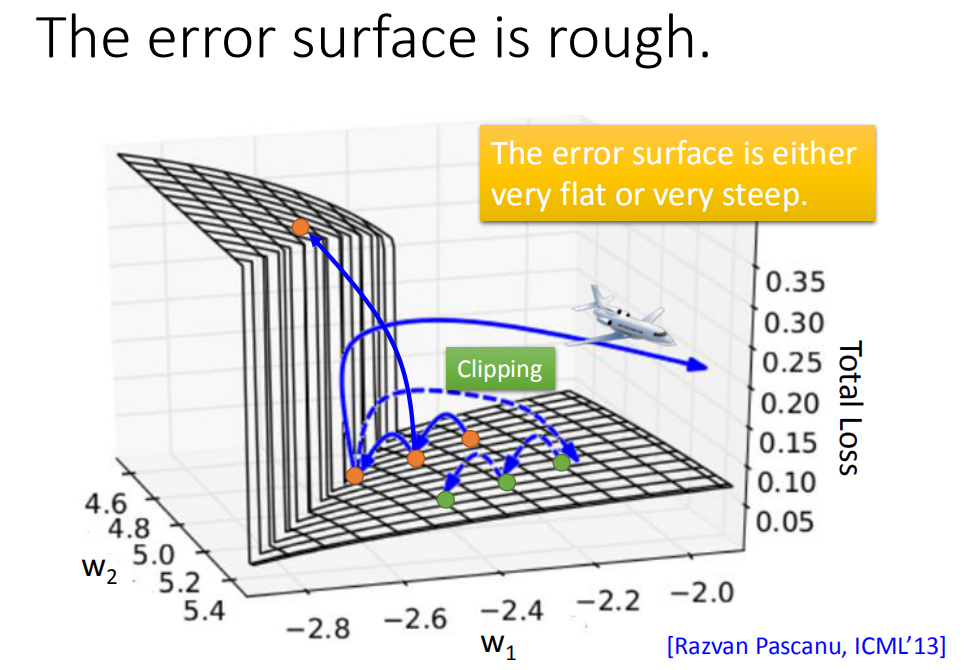 分析了下RNN的性质,他发现说RNN的error surface是total loss的变化是非常陡峭的/崎岖的(error surface有一些地方非常的平坦,一些地方非常的陡峭,就像是悬崖峭壁一样),纵轴是total loss,x和y轴代表是两个参数。这样会造成什么样的问题呢?假设你从橙色的点当做你的初始点,用GD开始调整你的参数(updata你的参数,可能会跳过一个悬崖,这时候你的loss会突然爆长,loss会非常上下剧烈的震荡)。有时候你可能会遇到更惨的状况,就是以正好你一脚踩到这个悬崖上,会发生这样的事情,因为在悬崖上的gradient很大,之前的gradient会很小,所以你措手不及,因为之前gradient很小,所以你可能把learning rate调的比较大。很大的gradient乘上很大的learning rate结果参数就update很多,整个参数就飞出去了。
分析了下RNN的性质,他发现说RNN的error surface是total loss的变化是非常陡峭的/崎岖的(error surface有一些地方非常的平坦,一些地方非常的陡峭,就像是悬崖峭壁一样),纵轴是total loss,x和y轴代表是两个参数。这样会造成什么样的问题呢?假设你从橙色的点当做你的初始点,用GD开始调整你的参数(updata你的参数,可能会跳过一个悬崖,这时候你的loss会突然爆长,loss会非常上下剧烈的震荡)。有时候你可能会遇到更惨的状况,就是以正好你一脚踩到这个悬崖上,会发生这样的事情,因为在悬崖上的gradient很大,之前的gradient会很小,所以你措手不及,因为之前gradient很小,所以你可能把learning rate调的比较大。很大的gradient乘上很大的learning rate结果参数就update很多,整个参数就飞出去了。
用工程的思想来解决,这一招蛮关键的,在很长的一段时间,只有他的code可以把RNN的model给train出来。
这一招就是clipping(当gradient大于某一个threshold的时候,不要让它超过那个threshold),当gradient大于15时,让gradient等于15结束。因为gradient不会太大,所以你要做clipping的时候,就算是踩着这个悬崖上,也不飞出来,会飞到一个比较近的地方,这样你还可以继续做你得RNN的training。
问题:为什么RNN会有这种奇特的特性。有人会说,是不是来自sigmoid function,我们之前讲过Relu activation function的时候,讲过一个问题gradient vanish,这个问题是从sigmoid function来的,RNN会有很平滑的error surface是因为来自于gradient vanish,这问题我是不认同的。等一下来看这个问题是来自sigmoid function,你换成Relu去解决这个问题就不是这个问题了。跟大家讲个秘密,一般在train neural network时,一般很少用Relu来当做activation function。为什么呢?其实你把sigmoid function换成Relu,其实在RNN performance通常是比较差的。所以activation function并不是这里的关键点。
 如果说我们今天讲BPTT,你可能会从式子更直观的看出为什么会有这个问题。那今天我们没有讲BPTT。没有关系,我们有更直观的方法来知道一个gradient的大小。
如果说我们今天讲BPTT,你可能会从式子更直观的看出为什么会有这个问题。那今天我们没有讲BPTT。没有关系,我们有更直观的方法来知道一个gradient的大小。
你把某一个参数做小小的变化,看它对network output的变化有多大,你就可以测出这个参数的gradient的大小。
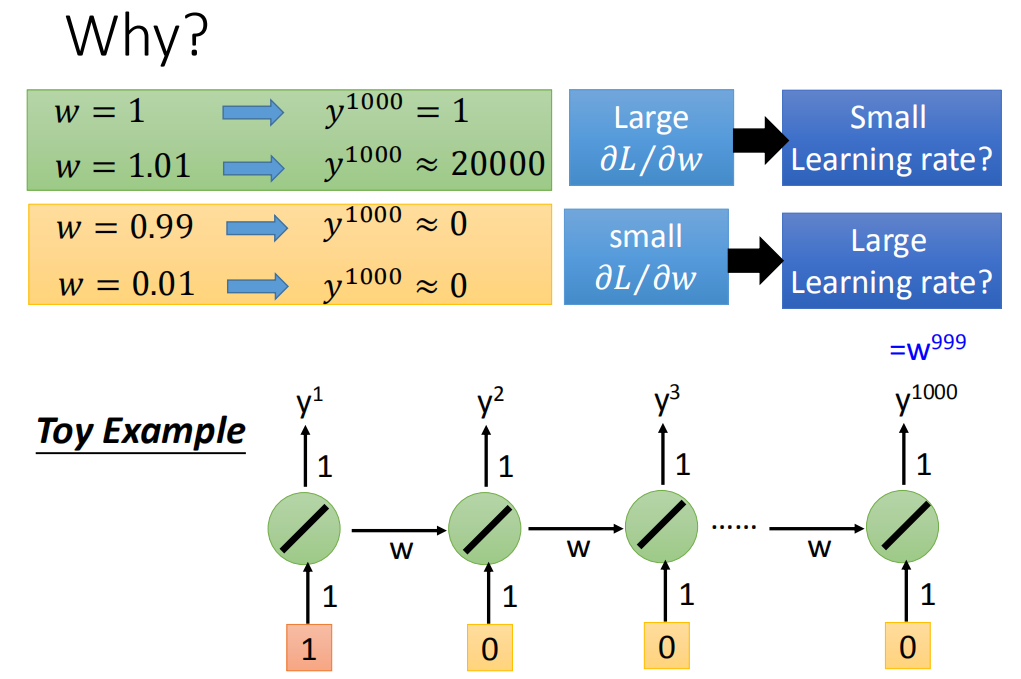
举一个很简单的例子,只有一个neuron,这个neuron是linear。input没有bias,input的weight是1,output的weight也是1,transition的weight是w。也就是说从memory接到neuron的input的weight是w。
现在我假设给neural network的输入是(1,0,0,0),那这个neural network的output会长什么样子呢?比如说,neural network在最后一个时间点(1000个output值是
现在假设w是我们要learn的参数,我们想要知道它的gradient,所以是知道当我们改变w的值时候,对neural的output有多大的影响。现在假设w=1,那现在
所以RNN不好训练的原因不是来自activation function而是来自于它有high sequence同样的weight在不同的时间点被反复的使用。
如何解决RNN梯度消失或者爆炸
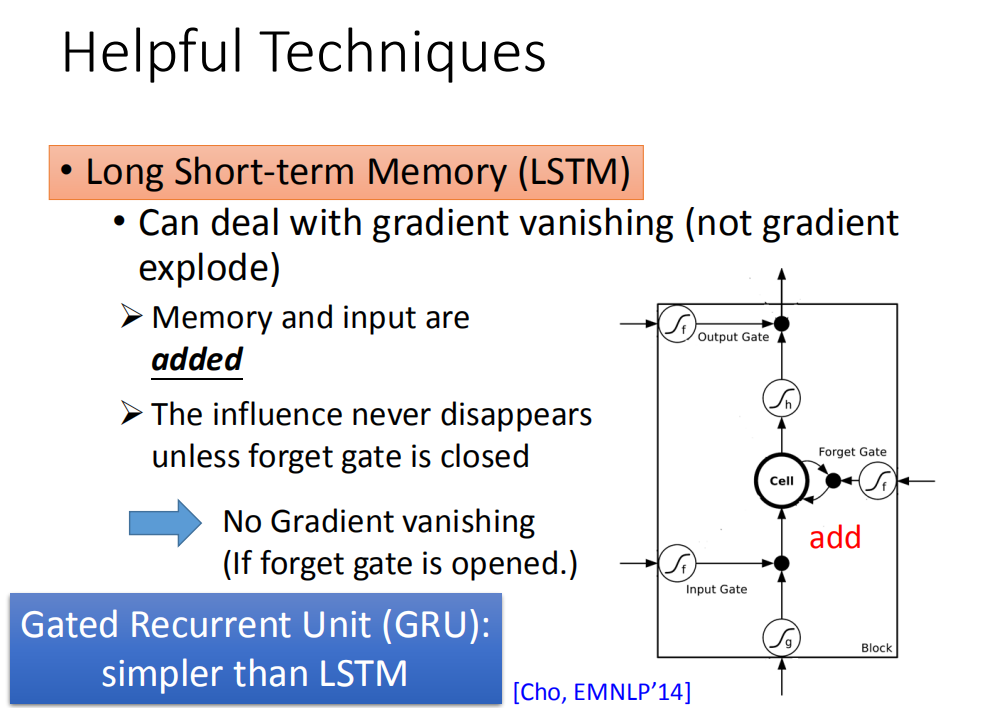 有什么样的技巧可以告诉我们可以解决这个问题呢?其实广泛被使用的技巧就是LSTM,LSTM可以让你的error surface不要那么崎岖。它可以做到的事情是,它会把那些平坦的地方拿掉,解决gradient vanish的问题,不会解决gradient explode的问题。有些地方还是非常的崎岖的(有些地方仍然是变化非常剧烈的,但是不会有特别平坦的地方)。
有什么样的技巧可以告诉我们可以解决这个问题呢?其实广泛被使用的技巧就是LSTM,LSTM可以让你的error surface不要那么崎岖。它可以做到的事情是,它会把那些平坦的地方拿掉,解决gradient vanish的问题,不会解决gradient explode的问题。有些地方还是非常的崎岖的(有些地方仍然是变化非常剧烈的,但是不会有特别平坦的地方)。
如果你要做LSTM时,大部分地方变化的很剧烈,所以当你做LSTM的时候,你可以放心的把你的learning rate设置的小一点,保证在learning rate很小的情况下进行训练。
那为什么LSTM 可以解决梯度消失的问题呢,为什么可以避免gradient特别小呢?
我听说某人在面试某国际大厂的时候被问到这个问题,那这个问题怎么答比较好呢(问题:为什么我们把RNN换成LSTM)。如果你的答案是LSTM比较潮,LSTM比较复杂,这个就太弱了。正在的理由就是LSTM可以handle gradient vanishing的问题。接下里面试官说:为什么LSTM会handle gradient vanishing的问题呢?用这边的式子回答看看,若考试在碰到这样的问题时,你就可以回答了。
RNN跟LSTM在面对memory的时候,它处理的操作其实是不一样的。你想想看,在RNN里面,在每一个时间点,memory里面的值都是会被洗掉,在每一个时间点,neuron的output都要memory里面去,所以在每一个时间点,memory里面的值都是会被覆盖掉。但是在LSTM里面不一样,它是把原来memory里面的值乘上一个值再把input的值加起来放到cell里面。所以它的memory input是相加的。所以今天它和RNN不同的是,如果今天你的weight可以影响到memory里面的值的话,一旦发生影响会永远都存在。不像RNN在每个时间点的值都会被format掉,所以只要这个影响被format掉它就消失了。但是在LSTM里面,一旦对memory造成影响,那影响一直会被留着(除非forget gate要把memory的值洗掉),不然memory一旦有改变,只会把新的东西加进来,不会把原来的值洗掉,所以它不会有gradient vanishing的问题
那你想说们现在有forget gate可能会把memory的值洗掉。其实LSTM的第一个版本其实就是为了解决gradient vanishing的问题,所以它是没有forget gate,forget gate是后来才加上去的。甚至,现在有个传言是:你在训练LSTM的时候,你要给forget gate特别大的bias,你要确保forget gate在多数的情况下都是开启的,只要少数的情况是关闭的
那现在有另外一个版本用gate操控memory cell,叫做Gates Recurrent Unit(GRU),LSTM有三个Gate,而GRU有两个gate,所以GRU需要的参数是比较少的。因为它需要的参数量比较少,所以它在training的时候是比较鲁棒的。如果你今天在train LSTM,你觉得overfitting的情况很严重,你可以试下GRU。GRU的精神就是:旧的不去,新的不来。它会把input gate跟forget gate联动起来,也就是说当input gate打开的时候,forget gate会自动的关闭(format存在memory里面的值),当forget gate没有要format里面的值,input gate就会被关起来。也就是说你要把memory里面的值清掉,才能把新的值放进来。
其他方式
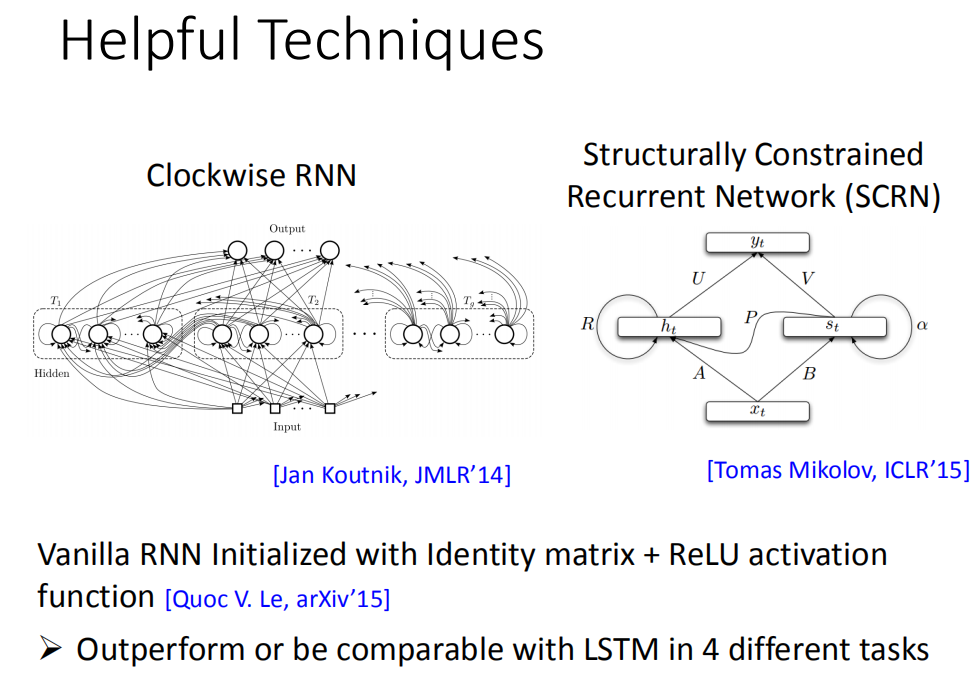 其实还有其他的technique是来handle gradient vanishing的问题。比如说clockwise RNN或者说是Structurally Constrained Recurrent Network (SCRN)等等。
其实还有其他的technique是来handle gradient vanishing的问题。比如说clockwise RNN或者说是Structurally Constrained Recurrent Network (SCRN)等等。
有一个蛮有趣的paper是这样的:一般的RNN用identity matrix(单位矩阵)来initialized transformation weight+ReLU activaton function它可以得到很好的performance。刚才不是说用ReLU的performance会比较呀,如果你说一般train的方法initiaed weight是random,那ReLU跟sigmoid function来比的话,sigmoid performance 会比较好。但是你今天用了identity matrix的话,这时候用ReLU performance会比较好。
RNN其他应用
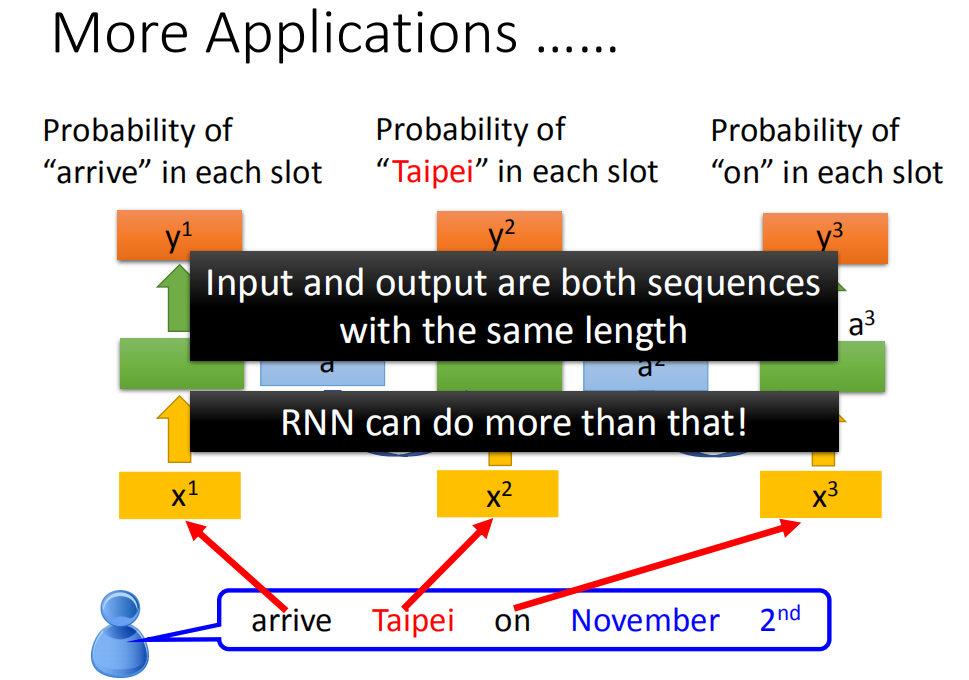 其实RNN有很多的application,前面举得那个solt filling的例子。我们假设input跟output的数目是一样的,也就是说input有几个word,我们就给每一个word slot label。那其实RNN可以做到更复杂的事情
其实RNN有很多的application,前面举得那个solt filling的例子。我们假设input跟output的数目是一样的,也就是说input有几个word,我们就给每一个word slot label。那其实RNN可以做到更复杂的事情
多对一序列
情感识别
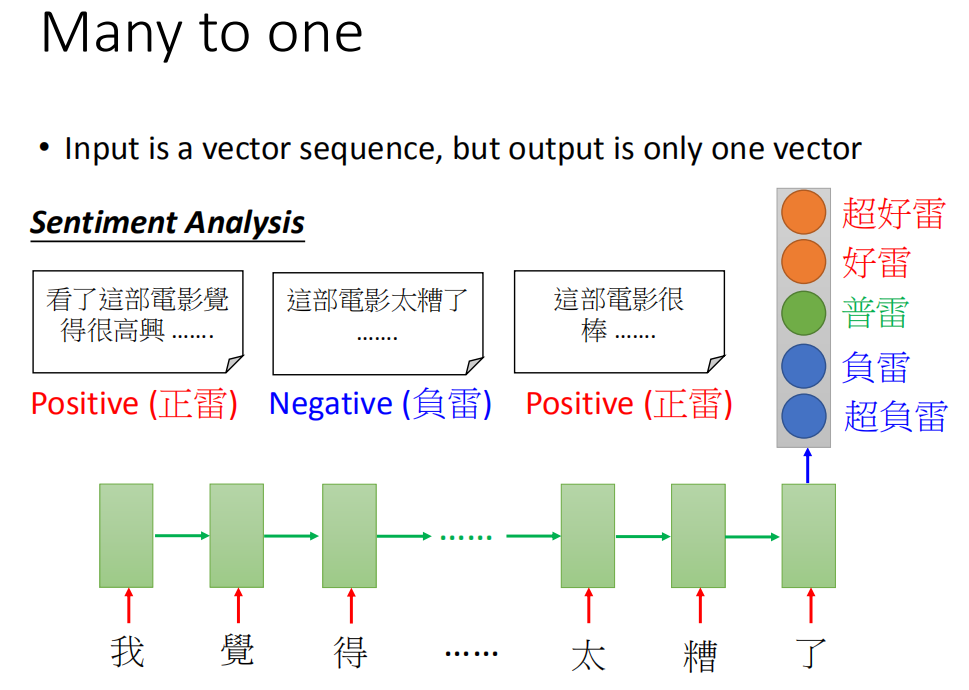 那其实RNN可以做到更复杂的事情,比如说input是一个sequence,output是一个vector,这有什么应用呢。比如说,你可以做sentiment analysis。sentiment analysis现在有很多的应用:
那其实RNN可以做到更复杂的事情,比如说input是一个sequence,output是一个vector,这有什么应用呢。比如说,你可以做sentiment analysis。sentiment analysis现在有很多的应用:
某家公司想要知道,他们的产品在网上的评价是positive 还是negative。他们可能会写一个爬虫,把跟他们产品有关的文章都爬下来。那这一篇一篇的看太累了,所以你可以用一个machine learning 的方法learn一个classifier去说哪些document是正向的,哪些document是负向的。或者在电影上,sentiment analysis所做的事就是给machine 看很多的文章,然后machine要自动的说,哪些文章是正类,哪些文章是负类。怎么样让machine做到这件事情呢?你就是learn一个Recurrent Neural Network,这个input是character sequence,然后Recurrent Neural Network把这个sequence读过一遍。在最后一个时间点,把hidden layer拿出来,在通过几个transform,然后你就可以得到最后的sentiment analysis(这是一个分类的问题,但是因为input是sequence,所以用RNN来处理)
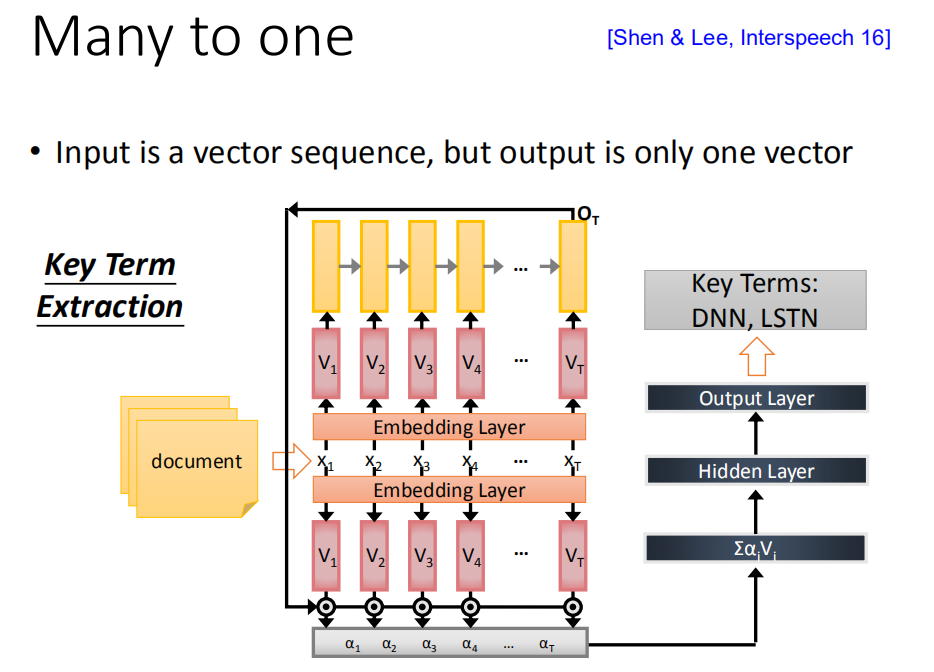 用RNN来作key term extraction。key term extraction意思就是说给machine看一个文章,machine要预测出这篇文章有哪些关键词汇。那如果你今天能够收集到一些training data(一些document,这些document都有label,哪些词汇是对应的,那就可以直接train一个RNN),那这个RNN把document当做input,通过Embedding layer,然后用RNN把这个document读过一次,然后把出现在最后一个时间点的output拿过来做attention,你可以把这样的information抽出来再丢到feedforward neural network得到最后的output
用RNN来作key term extraction。key term extraction意思就是说给machine看一个文章,machine要预测出这篇文章有哪些关键词汇。那如果你今天能够收集到一些training data(一些document,这些document都有label,哪些词汇是对应的,那就可以直接train一个RNN),那这个RNN把document当做input,通过Embedding layer,然后用RNN把这个document读过一次,然后把出现在最后一个时间点的output拿过来做attention,你可以把这样的information抽出来再丢到feedforward neural network得到最后的output
多对多序列
语音识别
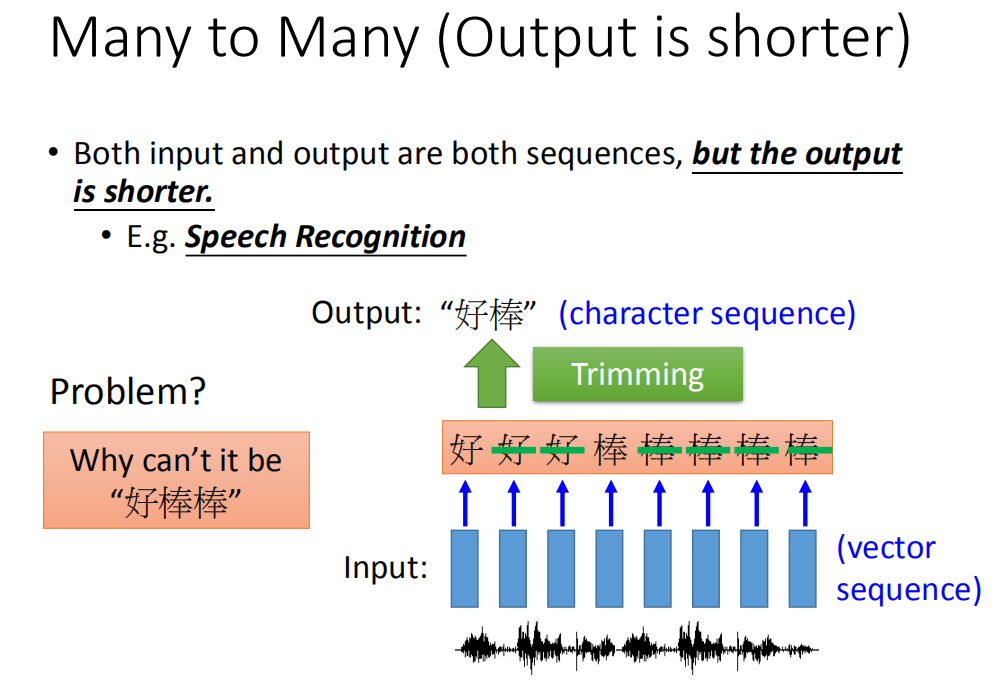 那它也可以是多对多的,比如说当你的input和output都是sequence,但是output sequence比input sequence短的时候,RNN可以处理这个问题。什么样的任务是input sequence长,output sequence短呢。比如说,语音辨识就是这样的任务。在语音辨识这个任务里面input是acoustic sequence(说一句话,这句话就是一段声音讯号)。我们一般处理声音讯号的方式,在这个声音讯号里面,每隔一小段时间,就把它用vector来表示。这个一小段时间是很短的(比如说,0.01秒)。那output sequence是character sequence。
那它也可以是多对多的,比如说当你的input和output都是sequence,但是output sequence比input sequence短的时候,RNN可以处理这个问题。什么样的任务是input sequence长,output sequence短呢。比如说,语音辨识就是这样的任务。在语音辨识这个任务里面input是acoustic sequence(说一句话,这句话就是一段声音讯号)。我们一般处理声音讯号的方式,在这个声音讯号里面,每隔一小段时间,就把它用vector来表示。这个一小段时间是很短的(比如说,0.01秒)。那output sequence是character sequence。
如果你是原来的RNN(slot filling的那个RNN),你把这一串input丢进去,它充其量只能做到说,告诉你每一个vector对应到哪一个character。加入说中文的语音辨识的话,那你的output target理论上就是这个世界上所有可能中文的词汇,常用的可能是八千个,那你RNNclassifier的数目可能就是八千个。虽然很大,但也是没有办法做的。但是充其量只能做到说:每一个vector属于一个character。每一个input对应的时间间隔是很小的(0.01秒),所以通常是好多个vector对应到同一个character。所以你的辨识结果为“好好好棒棒棒棒棒”。你会说:这不是语音辨识的结果呀,有一招叫做“trimming”(把重复的东西拿掉),就变成“好棒”。这这样会有一个严重的问题,因为它没有辨识“好棒棒”。
CTC语音识别
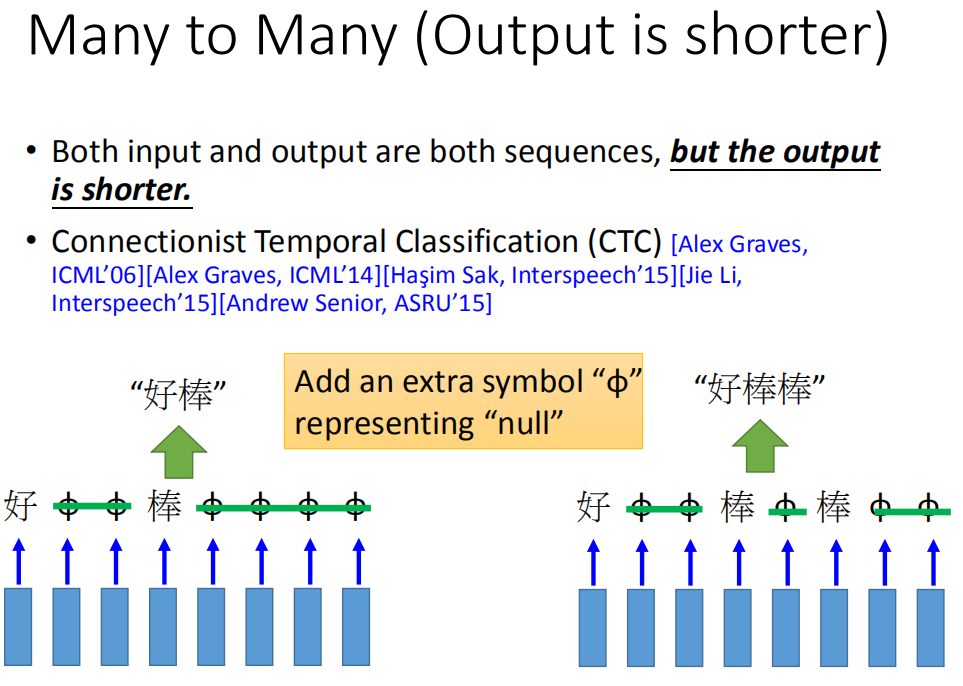 需要把“好棒”跟“好棒棒”分开来,怎么办,我们有一招叫做“CTC”(这招很神妙),它说:我们在output时候,我们不只是output所有中文的character,我们还有output一个符号,叫做"null""(没有任何东西)。所以我今天input一段acoustic feature sequence,它的output是“好 null null 棒 null null null null”,然后我就把“null”的部分拿掉,它就变成“好棒”。如果我们输入另外一个sequence,它的output是“好 null null 棒 null 棒 null null”,然后把“null”拿掉,所以它的output就是“好棒棒”。这样就可以解决叠字的问题了。
需要把“好棒”跟“好棒棒”分开来,怎么办,我们有一招叫做“CTC”(这招很神妙),它说:我们在output时候,我们不只是output所有中文的character,我们还有output一个符号,叫做"null""(没有任何东西)。所以我今天input一段acoustic feature sequence,它的output是“好 null null 棒 null null null null”,然后我就把“null”的部分拿掉,它就变成“好棒”。如果我们输入另外一个sequence,它的output是“好 null null 棒 null 棒 null null”,然后把“null”拿掉,所以它的output就是“好棒棒”。这样就可以解决叠字的问题了。
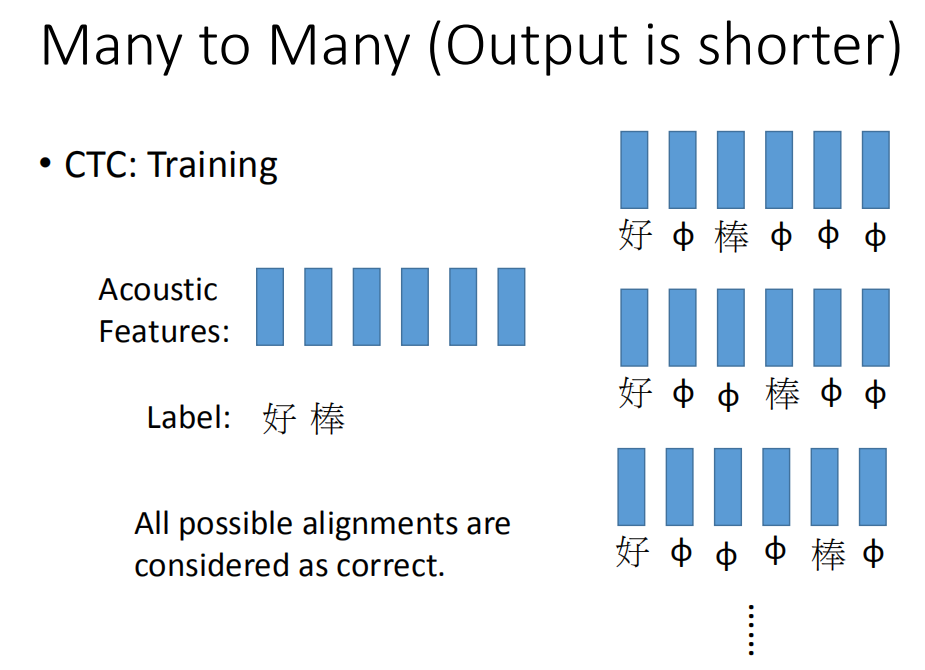 那在训练neuron怎么做呢(CTC怎么做训练呢)。CTC在做training的时候,你手上的train data就会告诉你说,这一串acoustic features对应到这一串character sequence,但它不会告诉你说“好”是对应第几个character 到第几个character。这该怎么办呢,穷举所有可能的alignments。简单来说就是,我们不知道“好”对应到那几个character,“棒”对应到哪几个character。假设我们所有的状况都是可能的。可能第一个是“好 null 棒 null null null”,可能是“好 null null 棒 null null”,也可能是“好 null null null 棒 null”。我们不知道哪个是对的,那假设全部都是对的。在training的时候,全部都当做是正确的,然后一起train。穷举所有的可能,那可能性太多了,有没有巧妙的算法可以解决这个问题呢?那今天我们就不细讲这个问题。
那在训练neuron怎么做呢(CTC怎么做训练呢)。CTC在做training的时候,你手上的train data就会告诉你说,这一串acoustic features对应到这一串character sequence,但它不会告诉你说“好”是对应第几个character 到第几个character。这该怎么办呢,穷举所有可能的alignments。简单来说就是,我们不知道“好”对应到那几个character,“棒”对应到哪几个character。假设我们所有的状况都是可能的。可能第一个是“好 null 棒 null null null”,可能是“好 null null 棒 null null”,也可能是“好 null null null 棒 null”。我们不知道哪个是对的,那假设全部都是对的。在training的时候,全部都当做是正确的,然后一起train。穷举所有的可能,那可能性太多了,有没有巧妙的算法可以解决这个问题呢?那今天我们就不细讲这个问题。
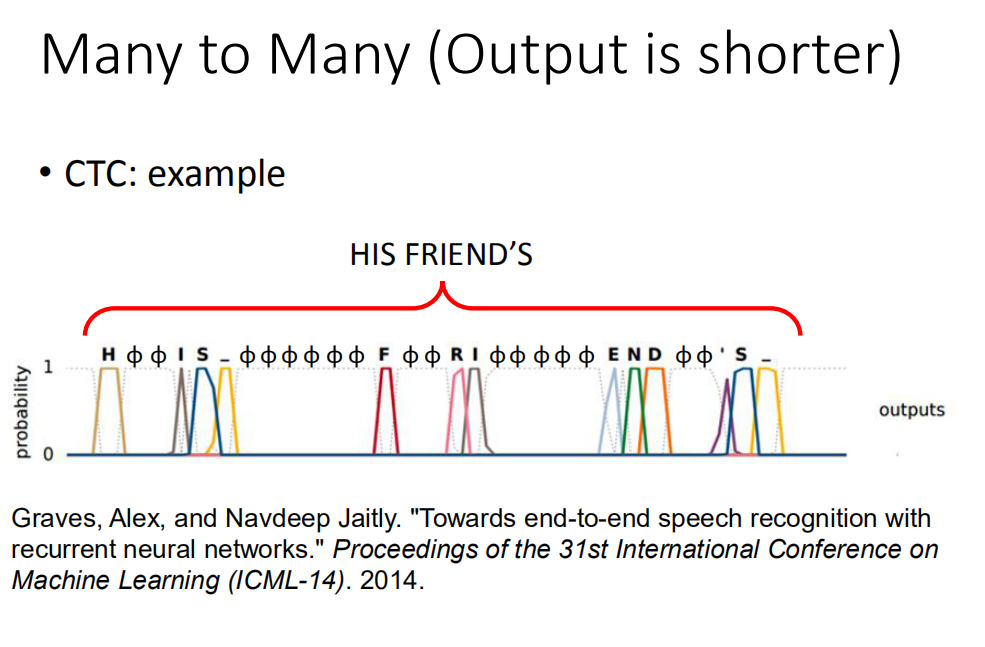 以下是在文献CTC上得到的结果。在做英文辨识的时候,你的RNN output target 就是character(英文的字母+空白)。直接output字母,然后如果字和字之间有boundary,就自动有空白。
以下是在文献CTC上得到的结果。在做英文辨识的时候,你的RNN output target 就是character(英文的字母+空白)。直接output字母,然后如果字和字之间有boundary,就自动有空白。
假设有一个例子,第一个frame是output h,第二个frame是output null,第三个frame是output null,第四个frame是output I等等。如果你看到output是这样子话,那最后把“null”的地方拿掉,那这句话的辨识结果就是“HIS FRIEND'S”。你不需要告诉machine说:"HIS"是一个词汇,“FRIEND's”是一个词汇,machine通过training data会自己学到这件事情。那传说,Google的语音辨识系统已经全面换成CTC来做语音辨识。如果你用CTC来做语音辨识的话,就算是有某一个词汇(比如是:英文中人名,地名)在training data中从来没有出现过,machine也是有机会把它辨识出来。
Sequence to sequence learning
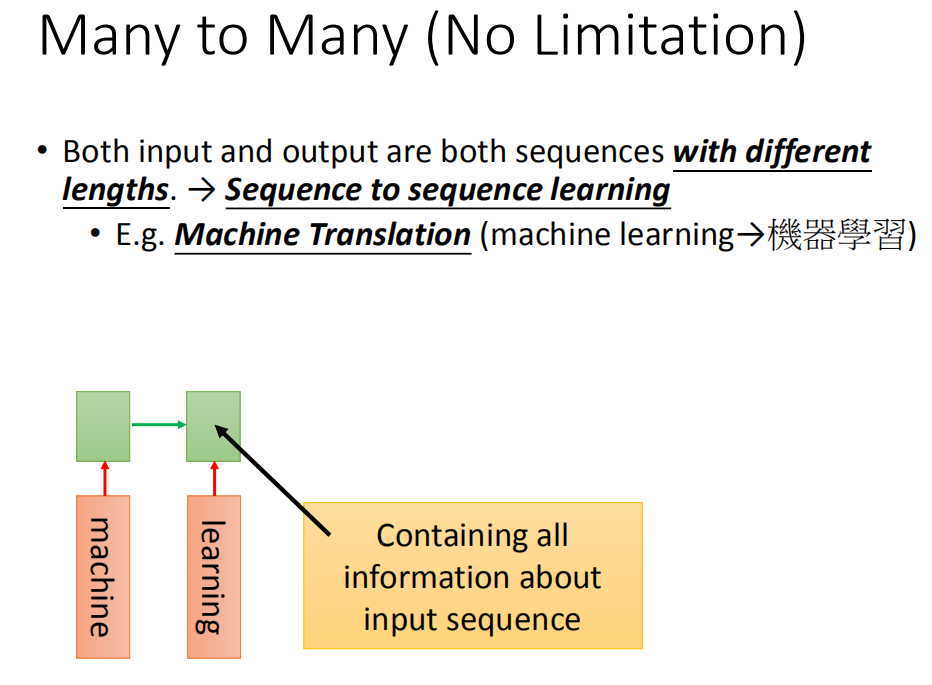 另外一个神奇RNN的应用叫做sequence to sequence learning,在sequence to sequence learning里面,RNN的input跟output都是sequence(但是两者的长度是不一样的)。刚在在CTC时,input比较长,output比较短。在这边我们要考虑的是不确定input跟output谁比较长谁比较短。
另外一个神奇RNN的应用叫做sequence to sequence learning,在sequence to sequence learning里面,RNN的input跟output都是sequence(但是两者的长度是不一样的)。刚在在CTC时,input比较长,output比较短。在这边我们要考虑的是不确定input跟output谁比较长谁比较短。
比如说,我们现在做machine translation,input英文word sequence把它翻译成中文的character sequence。那我们并不知道说,英文跟中文谁比较长谁比较短(有可能是output比较长,output比较短)。所以改怎么办呢?
现在假如说input machine learning ,然后用RNN读过去,然后在最后一个时间点,这个memory里面就存了所有input sequence的information。
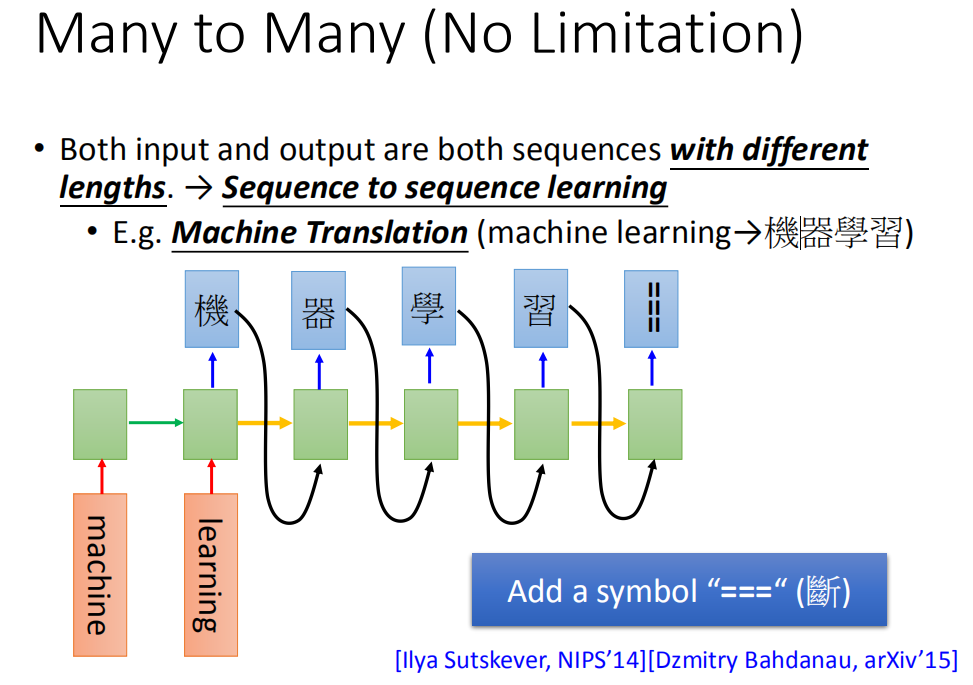 然后接下来,你让machine 吐一个character(机),然后就让它output下一个character,把之前的output出来的character当做input,再把memory里面的值读进来,它就会output “器”。那这个“机”怎么接到这个地方呢,有很多支支节节的技巧,还有很多不同的变形。在下一个时间input “器”,output“学”,然后output“习”,然后一直output下去
然后接下来,你让machine 吐一个character(机),然后就让它output下一个character,把之前的output出来的character当做input,再把memory里面的值读进来,它就会output “器”。那这个“机”怎么接到这个地方呢,有很多支支节节的技巧,还有很多不同的变形。在下一个时间input “器”,output“学”,然后output“习”,然后一直output下去
 这就让我想到推文接龙,有一个人推超,下一个人推人,然后推正,然后后面一直推推,等你推好几个月,都不会停下来。你要怎么让它停下来呢?推出一个“断”,就停下来了。
这就让我想到推文接龙,有一个人推超,下一个人推人,然后推正,然后后面一直推推,等你推好几个月,都不会停下来。你要怎么让它停下来呢?推出一个“断”,就停下来了。
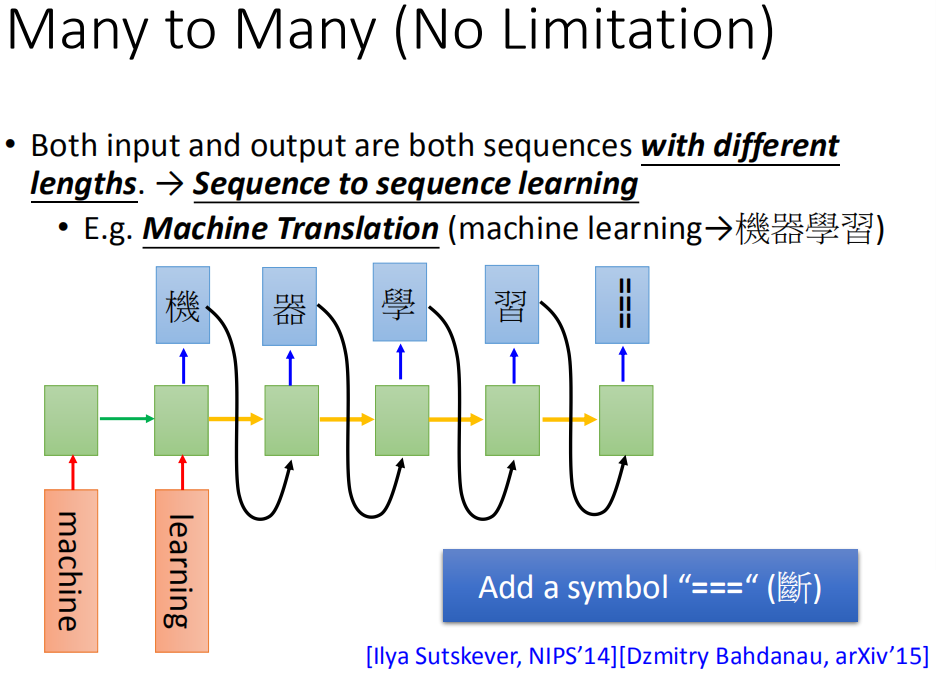 要怎么阻止让它产生词汇呢?你要多加一个symbol “断”,所以现在manchine不只是output说可能character,它还有一个可能output 叫做“断”。所以今天“习”后面是“===”(断)的话,就停下来了。你可能会说这个东西train的起来吗,这是train的起来的。
要怎么阻止让它产生词汇呢?你要多加一个symbol “断”,所以现在manchine不只是output说可能character,它还有一个可能output 叫做“断”。所以今天“习”后面是“===”(断)的话,就停下来了。你可能会说这个东西train的起来吗,这是train的起来的。
 这篇的papre是这样做的,sequence to sequence learning我们原来是input 某种语言的文字翻译成另外一种语言的文字(假设做翻译的话)。那我们有没有可能直接input某种语言的声音讯号,output另外一种语言的文字呢?我们完全不做语音辨识。比如说你要把英文翻译成中文,你就收集一大堆英文的句子,看看它对应的中文翻译。你完全不要做语音辨识,直接把英文的声音讯号丢到这个model里面去,看它能不能output正确的中文。这一招居然是行得通的。假设你今天要把台语转成英文,但是台语的语音辨识系统不好做,因为台语根本就没有standard文字系统,所以这项技术可以成功的话,未来你在训练台语转英文语音辨识系统的时候,你只需要收集台语的声音讯号跟它的英文翻译就可以刻了。你就不需要台语语音辨识的结果,你也不需要知道台语的文字,也可以做这件事。
这篇的papre是这样做的,sequence to sequence learning我们原来是input 某种语言的文字翻译成另外一种语言的文字(假设做翻译的话)。那我们有没有可能直接input某种语言的声音讯号,output另外一种语言的文字呢?我们完全不做语音辨识。比如说你要把英文翻译成中文,你就收集一大堆英文的句子,看看它对应的中文翻译。你完全不要做语音辨识,直接把英文的声音讯号丢到这个model里面去,看它能不能output正确的中文。这一招居然是行得通的。假设你今天要把台语转成英文,但是台语的语音辨识系统不好做,因为台语根本就没有standard文字系统,所以这项技术可以成功的话,未来你在训练台语转英文语音辨识系统的时候,你只需要收集台语的声音讯号跟它的英文翻译就可以刻了。你就不需要台语语音辨识的结果,你也不需要知道台语的文字,也可以做这件事。
Beyond Sequence
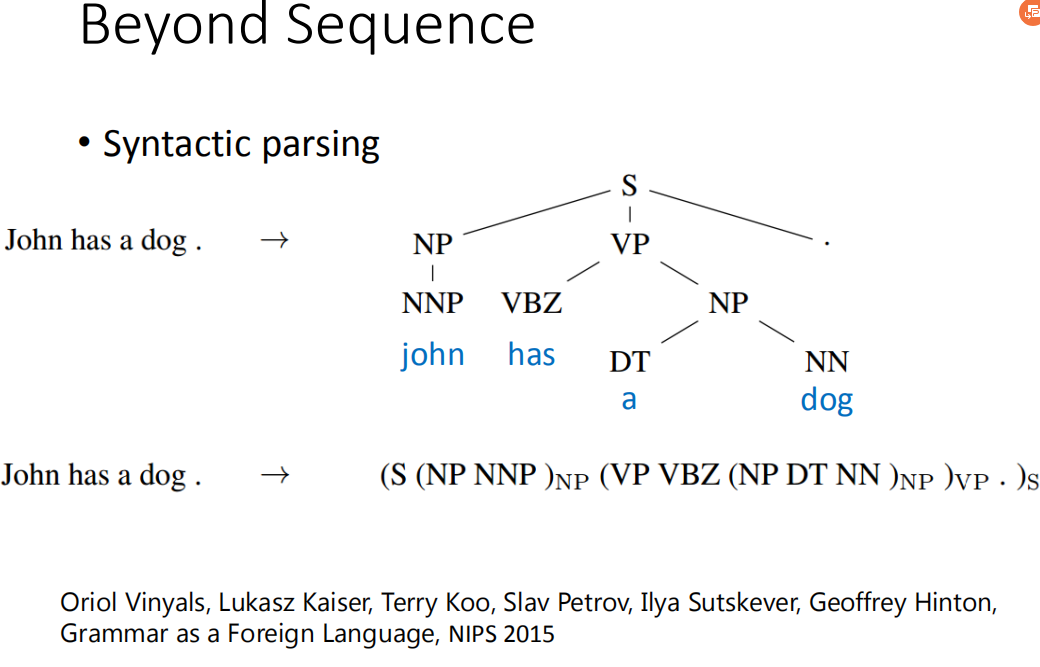 利用sequence to sequence的技术,甚至可以做到Beyond Sequence。这个技术也被用到syntactic parsing。synthetic parsing这个意思就是说,让machine看一个句子,它要得到这个句子的结构树,得到一个树状的结构。怎么让machine得到这样的结构呢?,过去你可能要用structured learning的技术能够解这个问题。但是现在有了 sequence to sequence learning的技术以后,你只要把这个树状图描述成一个sequence(具体看图中 john has a dog)。所以今天是sequence to sequence learning 的话,你就直接learn 一个sequence to sequence model。它的output直接就是syntactic parsing tree。这个是可以train的起来的,非常的surprised
利用sequence to sequence的技术,甚至可以做到Beyond Sequence。这个技术也被用到syntactic parsing。synthetic parsing这个意思就是说,让machine看一个句子,它要得到这个句子的结构树,得到一个树状的结构。怎么让machine得到这样的结构呢?,过去你可能要用structured learning的技术能够解这个问题。但是现在有了 sequence to sequence learning的技术以后,你只要把这个树状图描述成一个sequence(具体看图中 john has a dog)。所以今天是sequence to sequence learning 的话,你就直接learn 一个sequence to sequence model。它的output直接就是syntactic parsing tree。这个是可以train的起来的,非常的surprised
你可能想说machine它今天output的sequence不符合文法结构呢(记得加左括号,忘记加右括号),神奇的地方就是LSTM不会忘记右括号。
Document转成Vector
 那我们要将一个document表示成一个vector的话,往往会用bag-of-word的方法,用这个方法的时候,往往会忽略掉 word order information。举例来说,有一个word sequence是“white blood cells destroying an infection”,另外一个word sequence是:“an infection destroying white blood cells”,这两句话的意思完全是相反的。但是我们用bag-of-word的方法来描述的话,他们的bag-of-word完全是一样的。它们里面有完全一摸一样的六个词汇,因为词汇的order是不一样的,所以他们的意思一个变成positive,一个变成negative,他们的意思是很不一样的。
那我们要将一个document表示成一个vector的话,往往会用bag-of-word的方法,用这个方法的时候,往往会忽略掉 word order information。举例来说,有一个word sequence是“white blood cells destroying an infection”,另外一个word sequence是:“an infection destroying white blood cells”,这两句话的意思完全是相反的。但是我们用bag-of-word的方法来描述的话,他们的bag-of-word完全是一样的。它们里面有完全一摸一样的六个词汇,因为词汇的order是不一样的,所以他们的意思一个变成positive,一个变成negative,他们的意思是很不一样的。
那我们可以用sequence to sequence Auto-encoder这种做法来考虑word sequence order的情况下,把一个document变成一个vector。
Sequence-to-sequence -Text
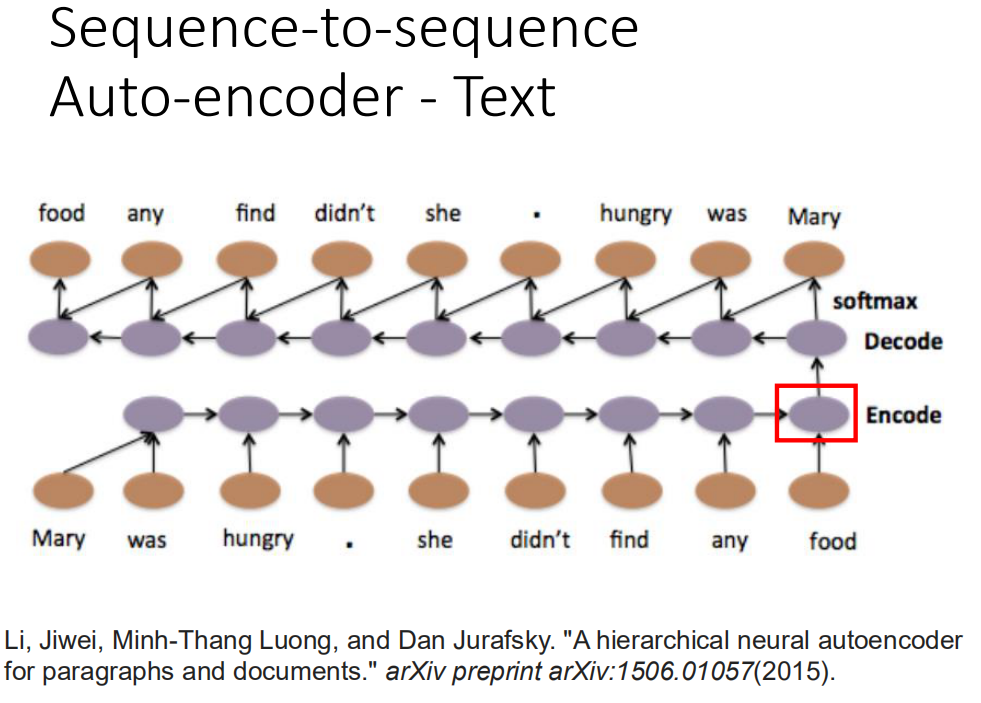 input一个word sequence,通过Recurrent Neural Network变成一个invalid vector,然后把这个invalid vector当做decoder的输入,然后让这个decoder,找回一模一样的句子。如果今天Recurrent Neural Network可以做到这件事情的话,那Encoding这个vector就代表这个input sequence里面重要的information。在trian Sequence-to-sequence Auto-encoder的时候,不需要label data,你只需要收集大量的文章,然后直接train下去就好了。
input一个word sequence,通过Recurrent Neural Network变成一个invalid vector,然后把这个invalid vector当做decoder的输入,然后让这个decoder,找回一模一样的句子。如果今天Recurrent Neural Network可以做到这件事情的话,那Encoding这个vector就代表这个input sequence里面重要的information。在trian Sequence-to-sequence Auto-encoder的时候,不需要label data,你只需要收集大量的文章,然后直接train下去就好了。
Sequence-to-sequence 还有另外一个版本叫skip thought,如果用Sequence-to-sequence的,输入输出都是同一个句子,如果用skip thought的话,输出的目标就会是下一个句子,用sequence-to-sequence得到的结果通常容易表达,如果要得到语义的意思的,那么skip thought会得到比较好的结果。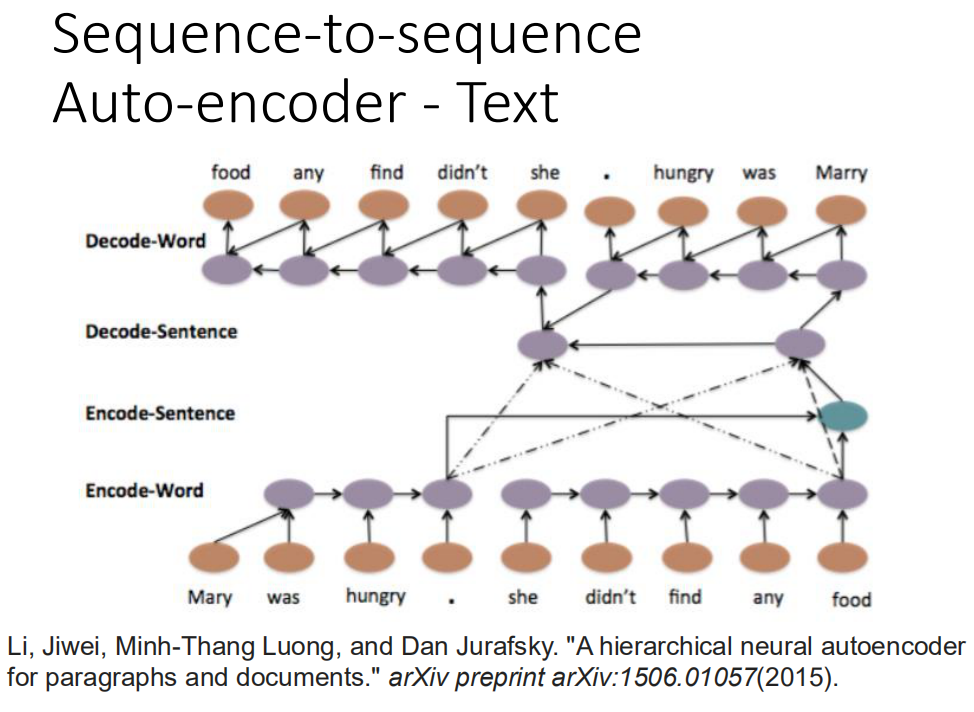 这个结构甚至可以是hierarchical,你可以每一个句子都先得到一个vector(Mary was hungry得到一个vector,she didn't find any food得到一个vector),然后把这些vector加起来,然后变成一个整个 document high label vector,在让这整个vector去产生一串sentence vector,在根据每一个sentence vector再去解回word sequence。这是一个四层的LSTM(从word 变成sentence sequence ,变成document lable,再解回sentence sequence,再解回word sequence)
这个结构甚至可以是hierarchical,你可以每一个句子都先得到一个vector(Mary was hungry得到一个vector,she didn't find any food得到一个vector),然后把这些vector加起来,然后变成一个整个 document high label vector,在让这整个vector去产生一串sentence vector,在根据每一个sentence vector再去解回word sequence。这是一个四层的LSTM(从word 变成sentence sequence ,变成document lable,再解回sentence sequence,再解回word sequence)
Sequence-to-sequence -Speech
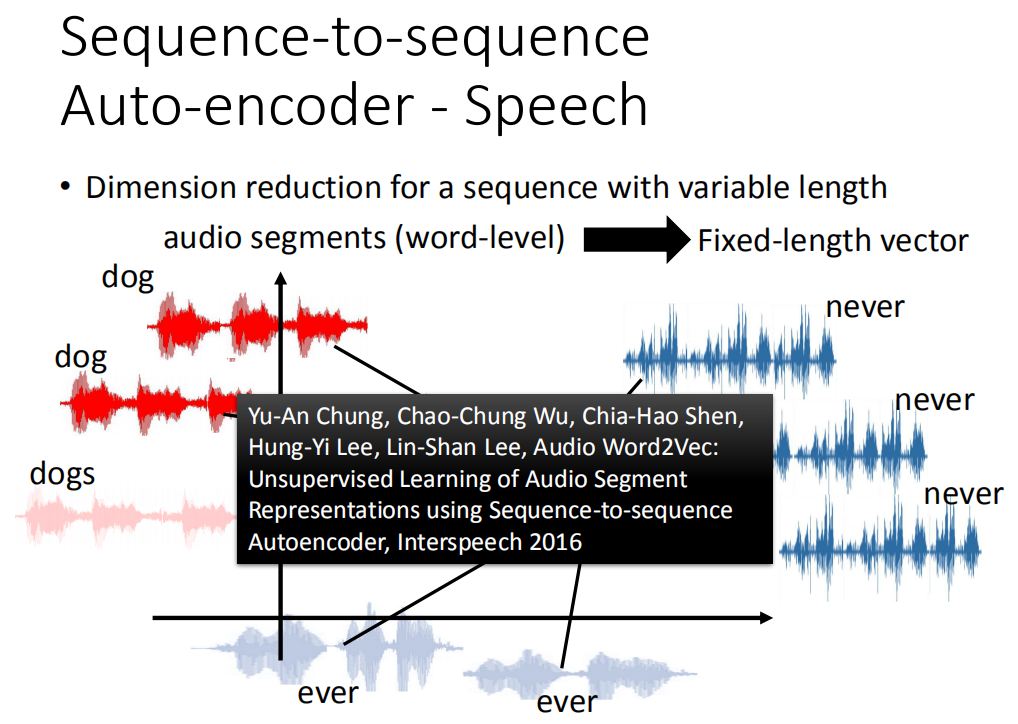 这个也可以用到语音上,在语音上,它可以把一段audio segment变成一个fixed length vector。比如说,左边有一段声音讯号,长长短短都不一样,那你把他们变成vector的话,可能dog跟dogs比较接近,never和ever比较接近。我称之为audio auto vector。一般的auto vector它是把word变成vector,这个是把一段声音讯号变成一个vector。
这个也可以用到语音上,在语音上,它可以把一段audio segment变成一个fixed length vector。比如说,左边有一段声音讯号,长长短短都不一样,那你把他们变成vector的话,可能dog跟dogs比较接近,never和ever比较接近。我称之为audio auto vector。一般的auto vector它是把word变成vector,这个是把一段声音讯号变成一个vector。
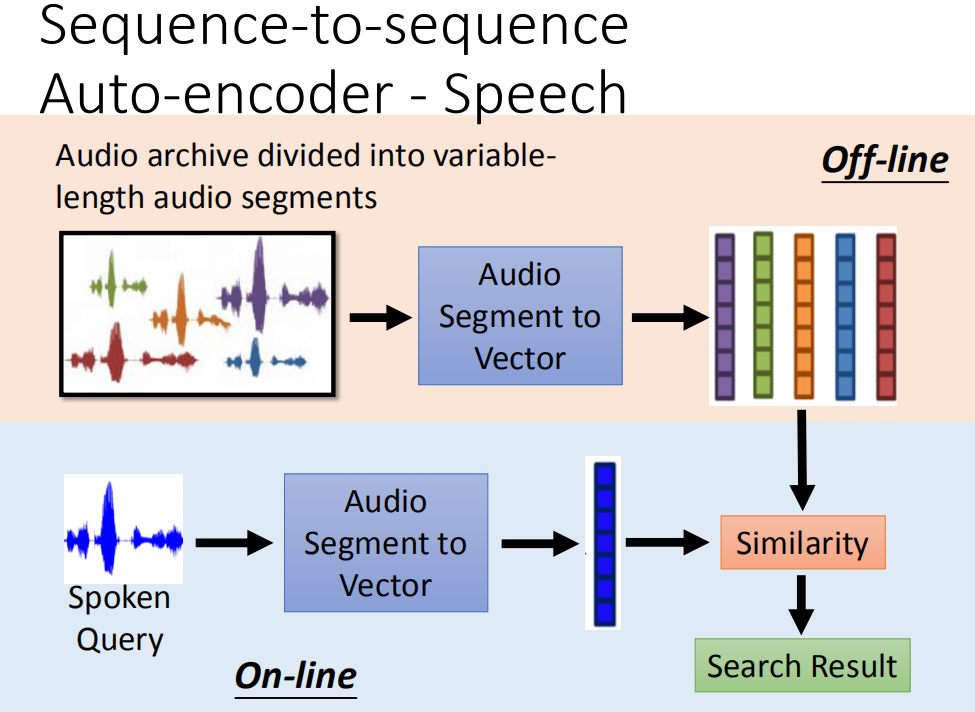 那这个东西有什么用呢?它可以做很多的事。比如说,我们可以拿来做语音的搜寻。什么是语音的搜寻呢?你有一个声音的data base(比如说,上课的录音,然后你说一句话,比如说,你今天要找跟美国白宫有关的东西,你就说美国白宫,不需要做语音辨识,直接比对声音讯号的相似度,machine 就可以从data base里面把提到的部分找出来)
那这个东西有什么用呢?它可以做很多的事。比如说,我们可以拿来做语音的搜寻。什么是语音的搜寻呢?你有一个声音的data base(比如说,上课的录音,然后你说一句话,比如说,你今天要找跟美国白宫有关的东西,你就说美国白宫,不需要做语音辨识,直接比对声音讯号的相似度,machine 就可以从data base里面把提到的部分找出来)
怎么实现呢?你就先把一个audio data base,把这个data base做segmentation切成一段一段的。然后每一个段用刚才讲的audio segment to vector这个技术,把他们通通变成vector。然后现再输入一个spoken query,可以通过audio segment to vector技术也变成vector,接下来计算他们的相似程度。然后就得到搜寻的结果
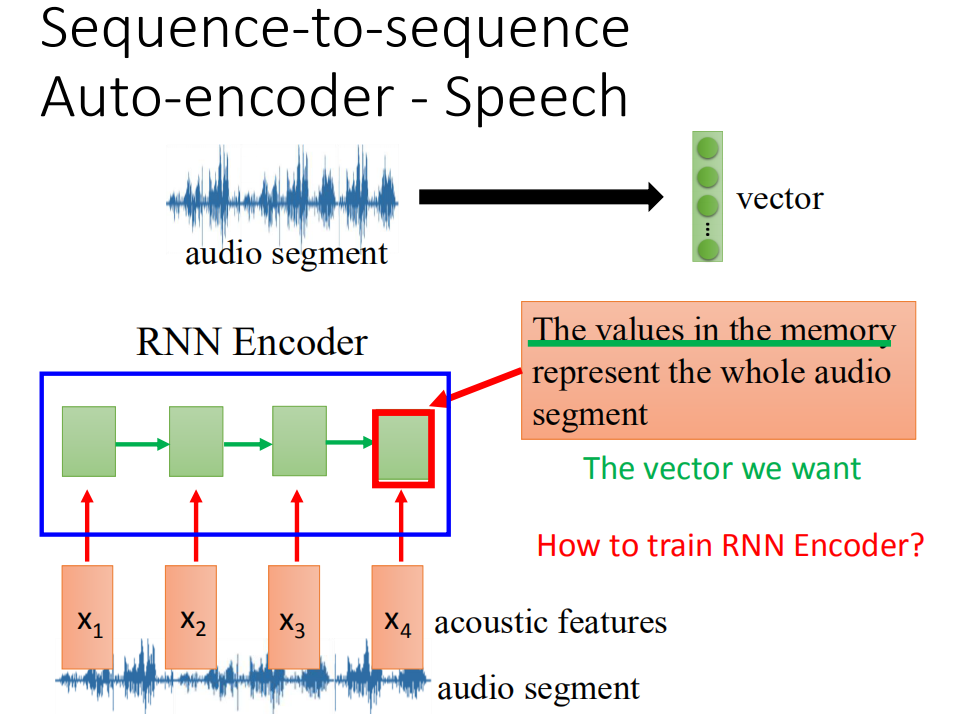 如何把一个audio segment变成一个vector呢?把audio segment抽成acoustic features,然后把它丢到Recurrent neural network里面去,那这个recurrent neural network它的角色就是Encoder,那这个recurrent neural network读过acoustic features之后,最后一个时间点它存在memory里面的值就代表了input声音讯号它的information。它存到memory里面的值是一个vector。这个其实就是我们要拿来表示整段声音讯号的vector。
如何把一个audio segment变成一个vector呢?把audio segment抽成acoustic features,然后把它丢到Recurrent neural network里面去,那这个recurrent neural network它的角色就是Encoder,那这个recurrent neural network读过acoustic features之后,最后一个时间点它存在memory里面的值就代表了input声音讯号它的information。它存到memory里面的值是一个vector。这个其实就是我们要拿来表示整段声音讯号的vector。
但是只要RNN Encoder我没有办法去train,同时你还要train一个RNN Decoder,Decoder的作用就是,它把Encoder得到的值存到memory里面的值,拿进来当做input,然后产生一个acoustic features sequence。然后希望这个
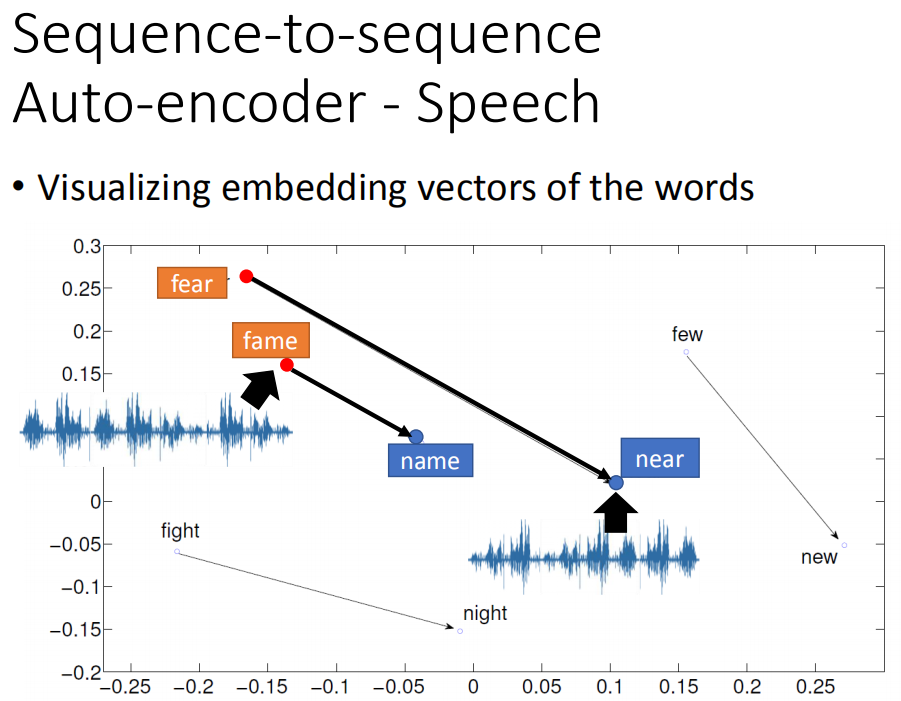 我们在实验上得到一些有趣的结果,图上的每个点其实都是一段声音讯号,你把声音讯号用刚才讲的
Sequence-to-sequence Auto-encoder技术变成平面上一个vector。发现说:fear这个位置在左上角,near的位置在右下角,他们中间这样的关系(fame在左上角,name在右下角)。你会发现说:把fear的开头f换成n,跟fame的开头f换成n,它们的word vector的变化方向是一样的。现在这个技术还没有把语义加进去。
我们在实验上得到一些有趣的结果,图上的每个点其实都是一段声音讯号,你把声音讯号用刚才讲的
Sequence-to-sequence Auto-encoder技术变成平面上一个vector。发现说:fear这个位置在左上角,near的位置在右下角,他们中间这样的关系(fame在左上角,name在右下角)。你会发现说:把fear的开头f换成n,跟fame的开头f换成n,它们的word vector的变化方向是一样的。现在这个技术还没有把语义加进去。
Demo:聊天机器人
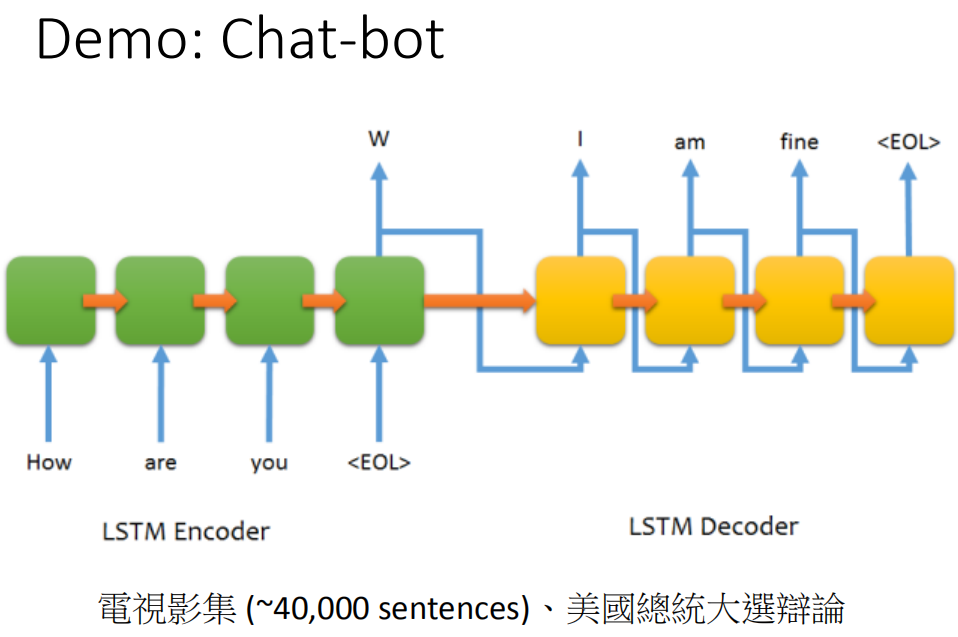 现在有一个demo,这个demo是用Sequence-to-sequence Auto-encoder来训练一个chat-bot(聊天机器人)。怎么用sequence to sequence learning来train chat-bot呢?你就收集很多的对话,比如说电影的台词,在电影中有一个台词是“How are you”,另外一个人接“I am fine”。那就告诉machine说这个sequence to sequence learning当它input是“How are you”的时候,这个model的output就要是“I am fine”。你可以收集到这种data,然后就让machine去 train。这里我们就收集了四万句和美国总统辩论的句子,然后让machine去学这个sequence to sequence这个model。
现在有一个demo,这个demo是用Sequence-to-sequence Auto-encoder来训练一个chat-bot(聊天机器人)。怎么用sequence to sequence learning来train chat-bot呢?你就收集很多的对话,比如说电影的台词,在电影中有一个台词是“How are you”,另外一个人接“I am fine”。那就告诉machine说这个sequence to sequence learning当它input是“How are you”的时候,这个model的output就要是“I am fine”。你可以收集到这种data,然后就让machine去 train。这里我们就收集了四万句和美国总统辩论的句子,然后让machine去学这个sequence to sequence这个model。

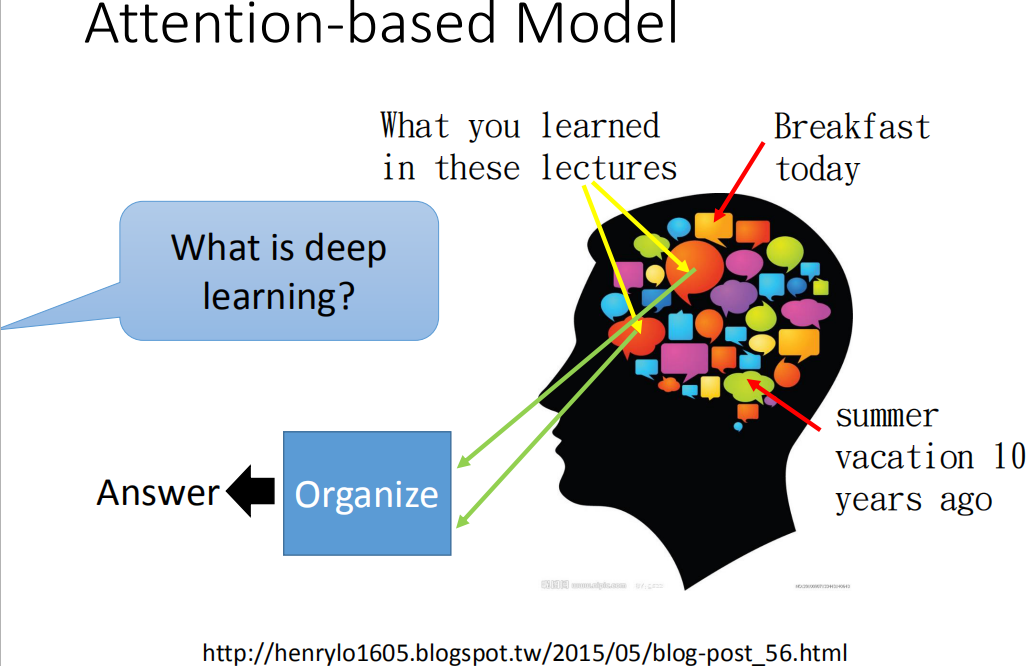 现在除了RNN以外,还有另外一种有用到memory的network,叫做Attention-based Model,这个可以想成是RNN的进阶的版本。
现在除了RNN以外,还有另外一种有用到memory的network,叫做Attention-based Model,这个可以想成是RNN的进阶的版本。
那我们知道说,人的大脑有非常强的记忆力,所以你可以记得非常非常多的东西。比如说,你现在同时记得早餐吃了什么,同时记得10年前夏天发生的事,同时记得在这几门课中学到的东西。那当然有人问你说什么是deep learning的时候,那你的脑中会去提取重要的information,然后再把这些information组织起来,产生答案。但是你的脑中会自动忽略那些无关的事情,比如说,10年前夏天发生的事情等等。
Attension-based Model
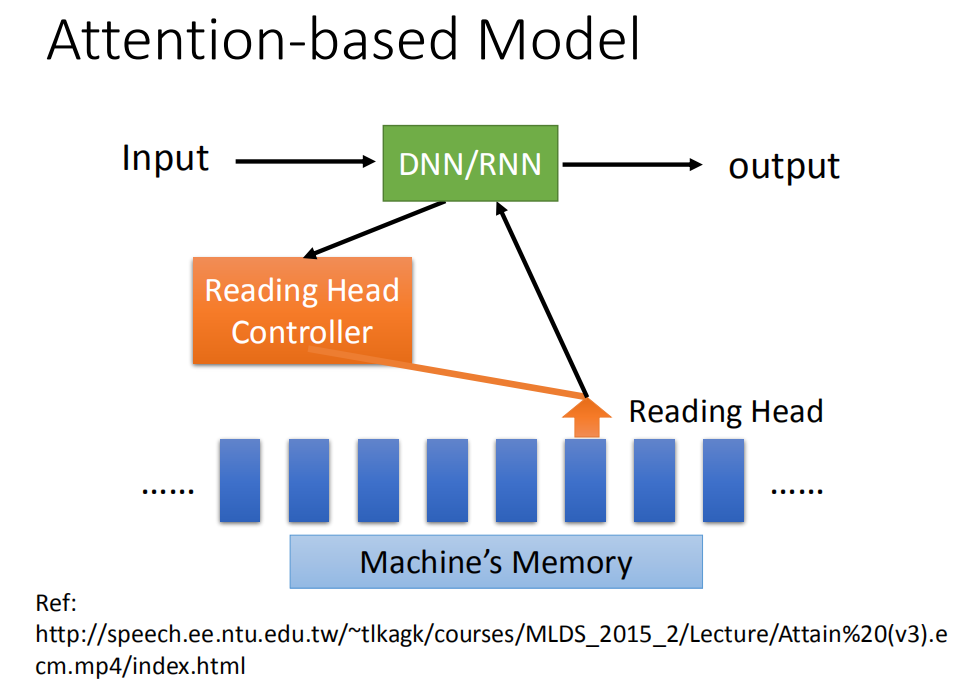 其实machine也可以做到类似的事情,machine也可以有很大的记忆的容量。它可以有很大的data base,在这个data base里面,每一个vector就代表了某种information被存在machine的记忆里面。
其实machine也可以做到类似的事情,machine也可以有很大的记忆的容量。它可以有很大的data base,在这个data base里面,每一个vector就代表了某种information被存在machine的记忆里面。
当你输入一个input的时候,这个input会被丢进一个中央处理器,这个中央处理器可能是一个DNN/RNN,那这个中央处理器会操控一个Reading Head Controller,这个Reading Head Controller会去决定这个reading head放的位置。machine再从这个reading head 的位置去读取information,然后产生最后的output
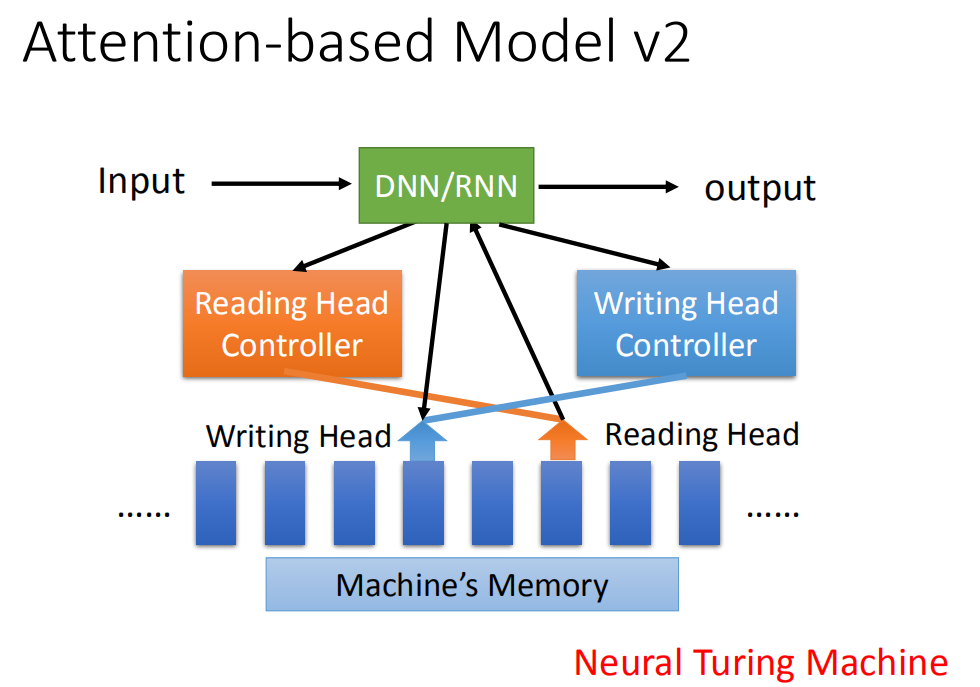 这个model还有一个2.0的版本,它会去操控writing head controller。这个writing head controller会去决定writing head 放的位置。然后machine会去把它的information通过这个writing head写进它的data base里面。所以,它不仅有读的功能,还可以discover出来的东西写入它的memory里面去。这个就是大名鼎鼎的Neural Turing Machine
这个model还有一个2.0的版本,它会去操控writing head controller。这个writing head controller会去决定writing head 放的位置。然后machine会去把它的information通过这个writing head写进它的data base里面。所以,它不仅有读的功能,还可以discover出来的东西写入它的memory里面去。这个就是大名鼎鼎的Neural Turing Machine
阅读理解
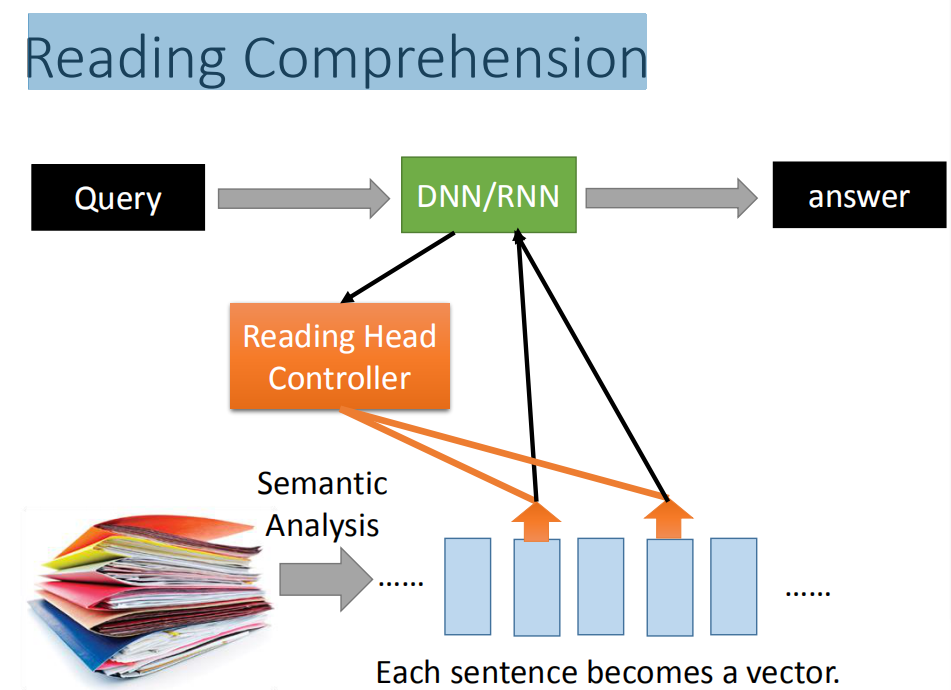 Attention-based Model 常常用在Reading Comprehension里面。所谓的Reading Comprehension就是让machine读一堆document,然后把这些document里面的内容(每一句话)变成一个vector。每一个vector就代表了每一句话的语义。比如你现在想问machine一个问题,然后这个问题被丢进中央处理器里面,那这个中央处理器去控制而来一个reading head controller,去决定说现在在这个data base里面哪些句子是跟中央处理器有关的。假设machine发现这个句子是跟现在的问题是有关的,就把reading head放到这个地方,把information 读到中央处理器中。读取information这个过程可以是重复数次,也就是说machine并不会从一个地方读取information,它先从这里读取information以后,它还可以换一个位置读取information。它把所有读到的information收集起来,最后给你一个最终的答案。
Attention-based Model 常常用在Reading Comprehension里面。所谓的Reading Comprehension就是让machine读一堆document,然后把这些document里面的内容(每一句话)变成一个vector。每一个vector就代表了每一句话的语义。比如你现在想问machine一个问题,然后这个问题被丢进中央处理器里面,那这个中央处理器去控制而来一个reading head controller,去决定说现在在这个data base里面哪些句子是跟中央处理器有关的。假设machine发现这个句子是跟现在的问题是有关的,就把reading head放到这个地方,把information 读到中央处理器中。读取information这个过程可以是重复数次,也就是说machine并不会从一个地方读取information,它先从这里读取information以后,它还可以换一个位置读取information。它把所有读到的information收集起来,最后给你一个最终的答案。

上图是在baby corpus上的结果,baby corpus是一个Q&A的一个简单的测试。我们需要做的事就是读过这五个句子,然后说:what color is Grey?,得到正确的答案,yes。那你可以从machine attention的位置(也就是reading head 的位置)看出machine的思路。图中蓝色代表了machine reading head 的位置,Hop1,Hop2,Hop3代表的是时间,在第一个时间点,machine先把它的reading head放在“greg is a frog”,把这个information提取出来。接下来提取“brian is a frog” information ,再提取“brian is yellow”information。最后它得到结论说:greg 的颜色是yellow。这些事情是machine自动learn出来的。也就是machine attention在哪个位置,这些通过neural network学到该怎么做,并不是去写程序,你要先看这个句子,在看这个句子。这是machine自动去决定的。
Visual Question Answering
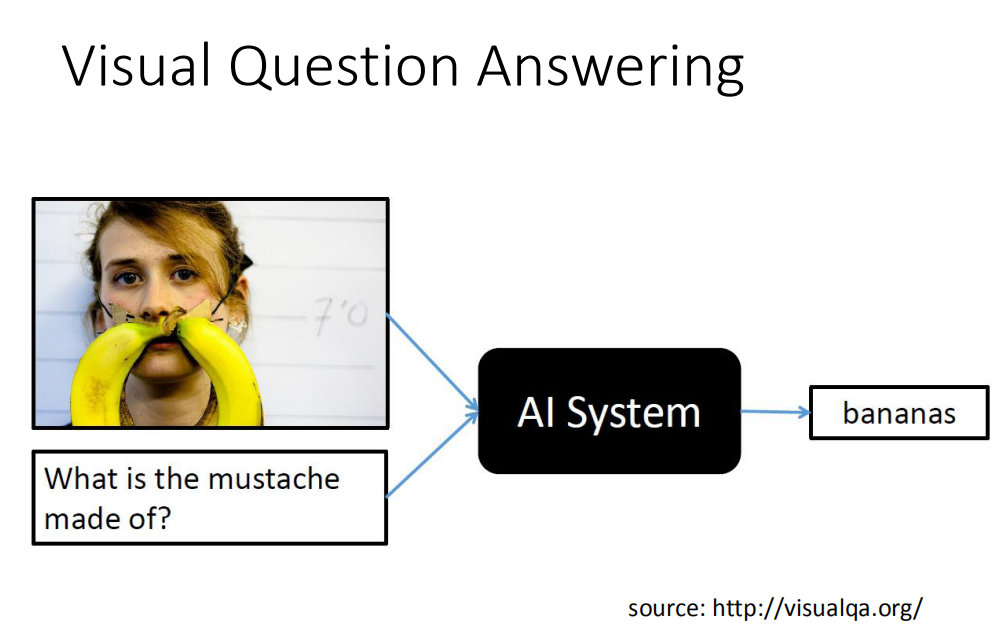 也可以做Visual Question Answering,让machine看一张图,问它这是什么,如果它可以正确回答说:这是香蕉,这就非常厉害了。
也可以做Visual Question Answering,让machine看一张图,问它这是什么,如果它可以正确回答说:这是香蕉,这就非常厉害了。
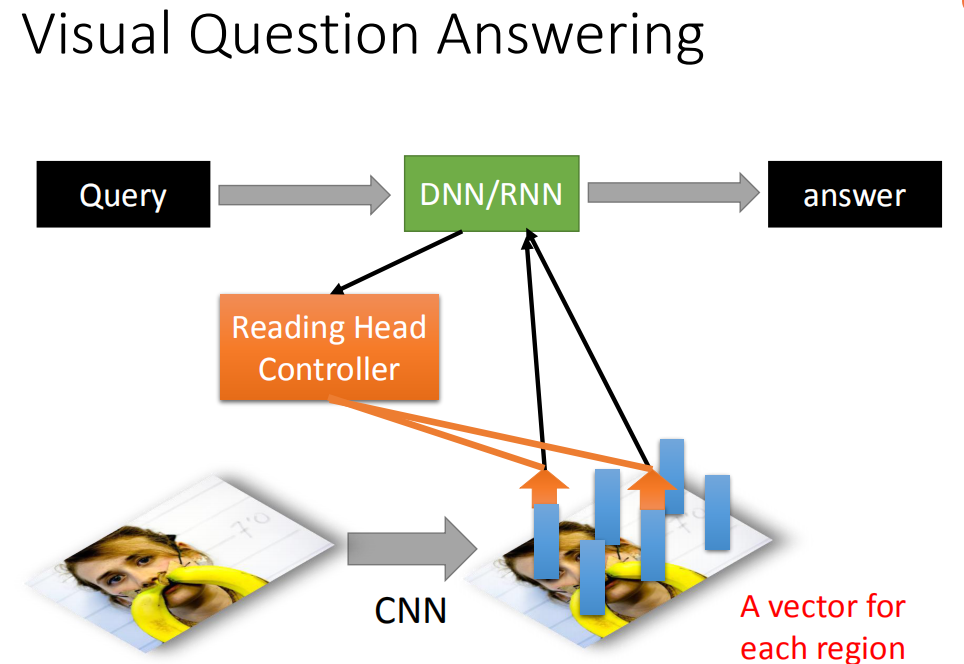 这个Visual Question Answering该怎么做呢?先让machine看一张图,然后通过CNN你可以把这张图的一小块region用一小块的vector来表示。接下里,输入一个query,这个query被丢到中央处理器中,这个中央处理器去操控这个reading head controller,这个reading head controller决定读取的位置(是跟现在输入的问题是有关系的,这个读取的process可能要好几个步骤,machine会分好几次把information读到中央处理器,最后得到答案。
这个Visual Question Answering该怎么做呢?先让machine看一张图,然后通过CNN你可以把这张图的一小块region用一小块的vector来表示。接下里,输入一个query,这个query被丢到中央处理器中,这个中央处理器去操控这个reading head controller,这个reading head controller决定读取的位置(是跟现在输入的问题是有关系的,这个读取的process可能要好几个步骤,machine会分好几次把information读到中央处理器,最后得到答案。
Speech Question Answering
 那可以做语音的Question Answering 。比如说:在语音处理实验上我们让machine做TOEFL Listening Comprehension Test 。让machine听一段声音,然后问它问题,从四个选项里面,machine选择出正确的选项。那machine做的事情是跟人类考生做的事情是一模一样的。
那可以做语音的Question Answering 。比如说:在语音处理实验上我们让machine做TOEFL Listening Comprehension Test 。让machine听一段声音,然后问它问题,从四个选项里面,machine选择出正确的选项。那machine做的事情是跟人类考生做的事情是一模一样的。
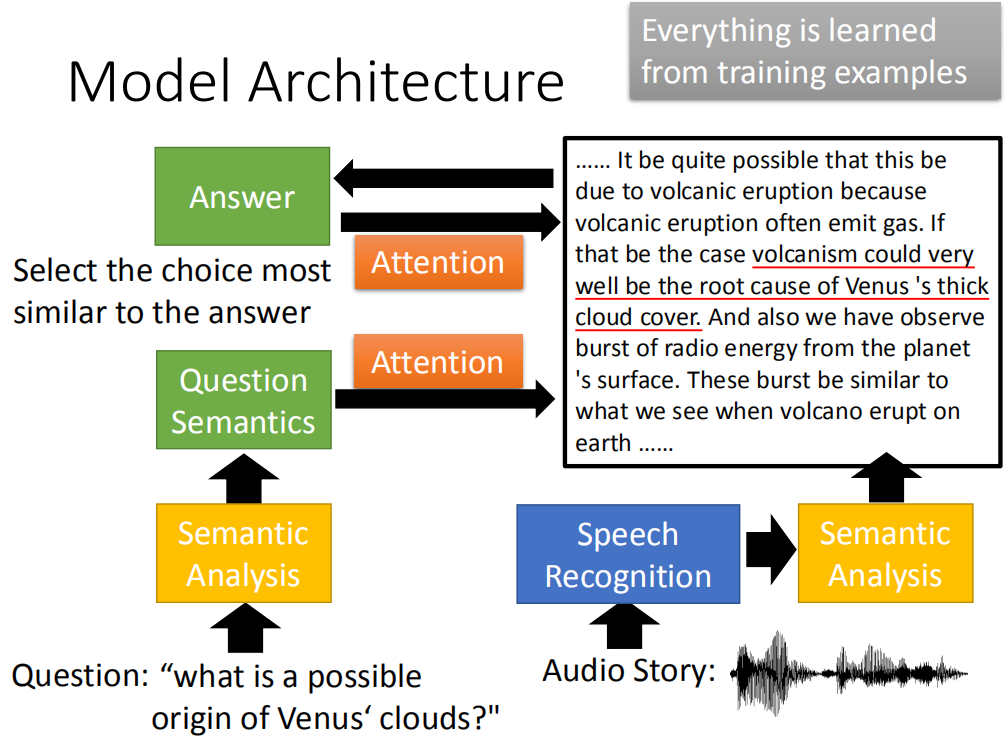 那用的Model Architecture跟我们刚才看到的其实大同小异。你让machine先读一个question,然后把question做语义的分析得到question的语义,声音的部分是让语音辨识先转成文字,在把这些文字做语音的分析,得到这段文字的语义。那machine了解question的语义然后就可以做attention,决定在audio story里面哪些部分是回答问题有关的。这就像画重点一样,machine画的重点就是答案,它也可以回头去修正它产生的答案。经过几个process以后,machine最后得到的答案跟其他几个选项计算相似度,然后看哪一个想项的相似度最高,它就选那一个选项。那整个test就是一个大的neural network。除了语音辨识以外question semantic部分和audio semantic部分都是neural network,所以他们就可以训练的。
那用的Model Architecture跟我们刚才看到的其实大同小异。你让machine先读一个question,然后把question做语义的分析得到question的语义,声音的部分是让语音辨识先转成文字,在把这些文字做语音的分析,得到这段文字的语义。那machine了解question的语义然后就可以做attention,决定在audio story里面哪些部分是回答问题有关的。这就像画重点一样,machine画的重点就是答案,它也可以回头去修正它产生的答案。经过几个process以后,machine最后得到的答案跟其他几个选项计算相似度,然后看哪一个想项的相似度最高,它就选那一个选项。那整个test就是一个大的neural network。除了语音辨识以外question semantic部分和audio semantic部分都是neural network,所以他们就可以训练的。
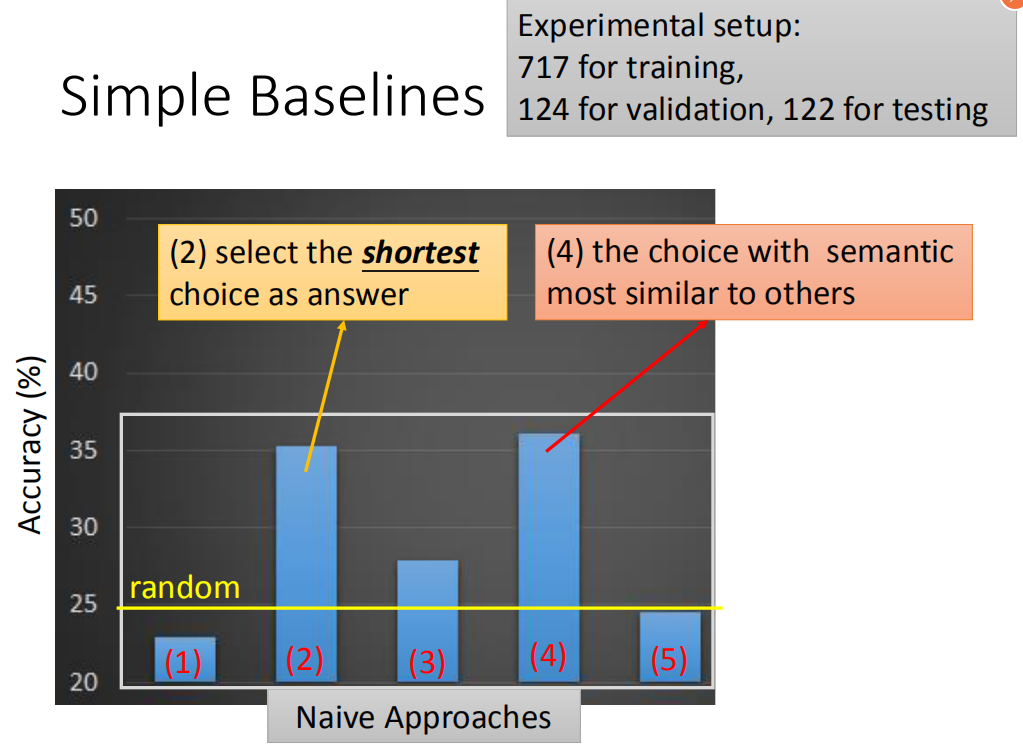 这些是一些实验结果,这个实验结果是:random 正确率是25 percent。有两个方法要比25 percent要强的。
这些是一些实验结果,这个实验结果是:random 正确率是25 percent。有两个方法要比25 percent要强的。
这五个方法都是naive的方法,也就是完全不管文章的内容,直接看问题跟选项就猜答案。我们发现说,如果你选最短的那个选项,你就会得到35 percent的正确率。如果分析四个选项的semantic,用sequence-to-sequence autoencoder,去把一个选项的semantic找出来,然后再去看某个选项和另外三个选项的相似度,如果比较高的话,那就把该选项选出来。和人的直觉是相反的,直觉应该是选一个语义和另外三个语义是不像的,但是别人已经计算到会这么做的了,所以用了计中计,如果要选和其他选项语义比较相似的答案,反而比随便选得到正确答案的概率要高,如果选最不像的那个选项,得到的答案就会接近随机,都是设计好的。
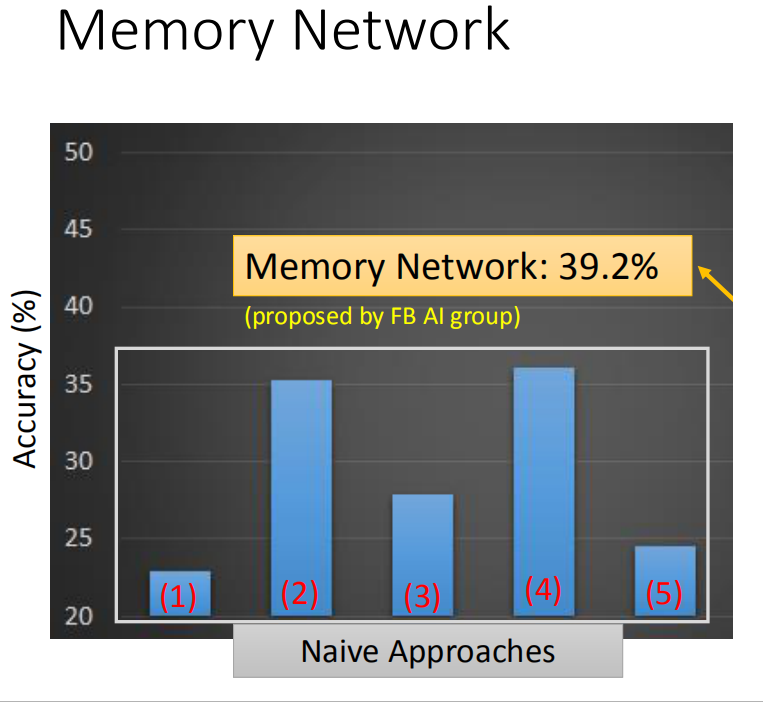
另外还可以用memory network可以得到39.2 %正确率,如果用我们刚才讲的那个model的话,可以做到48.8%正确率。
RNN 和Structured learning关系
 使用deep learning跟structure learning的技术有什么不同呢?首先假如我们用的是unidirectional RNN/LSTM,当你在 decision的时候,你只看了sentence的一半,而你是用structure learning的话,比如用Viterbi algrithm你考虑的是整个句子。从这个结果来看,也许HMM,SVM等还是占到一些优势的。但是这个优势并不是很明显,因为RNN和LSTM他们可以做Bidirectional ,所以他们也可以考虑一整个句子的information
使用deep learning跟structure learning的技术有什么不同呢?首先假如我们用的是unidirectional RNN/LSTM,当你在 decision的时候,你只看了sentence的一半,而你是用structure learning的话,比如用Viterbi algrithm你考虑的是整个句子。从这个结果来看,也许HMM,SVM等还是占到一些优势的。但是这个优势并不是很明显,因为RNN和LSTM他们可以做Bidirectional ,所以他们也可以考虑一整个句子的information
在HMM/SVM里面,你可以explicitly的考虑label之间的关系
举例说,如果做inference的时候,再用Viterbi algrithm求解的时候(假设每个label出现的时候都要出现五次)这个算法可以轻松做到,因为可以修改机器在选择分数最高的时候,排除掉不符合constraint的那些结果,但是如果是LSTM/RNN,直接下一个constraint进去是比较难的,因为没办法让RNN连续吐出某个label五次才是正确的。所以在这点上,structured learning似乎是有点优势的。如果是RNN/LSTM,你的cost function跟你实际上要考虑的error往往是没有关系的,当你做RNN/LSTM的时候,考虑的cost是每一个时间点的cross entropy(每一个时间的RNN的output cross entropy),它跟你的error不见得是直接相关的。但是你用structure learning的话,structure learning 的cost会影响你的error,从这个角度来看,structured learning也是有一些优势的。最重要的是,RNN/LSTM可以是deep,HMMM,SVM等它们其实也可以是deep,但是它们要想拿来做deep learning 是比较困难的。在我们上一堂课讲的内容里面。它们都是linear,因为他们定义的evaluation函数是线性的。如果不是线性的话也会很麻烦,因为只有是线性的我们才能套用上节课讲的那些方法来做inference。
最后总结来看,RNN/LSTM在deep这件事的表现其实会比较好,同时这件事也很重要,如果只是线性的模型,function space就这么大,可以直接最小化一个错误的上界,但是这样没什么,因为所有的结果都是坏的,所以相比之下,deep learning占到很大的优势。
Integerated Together
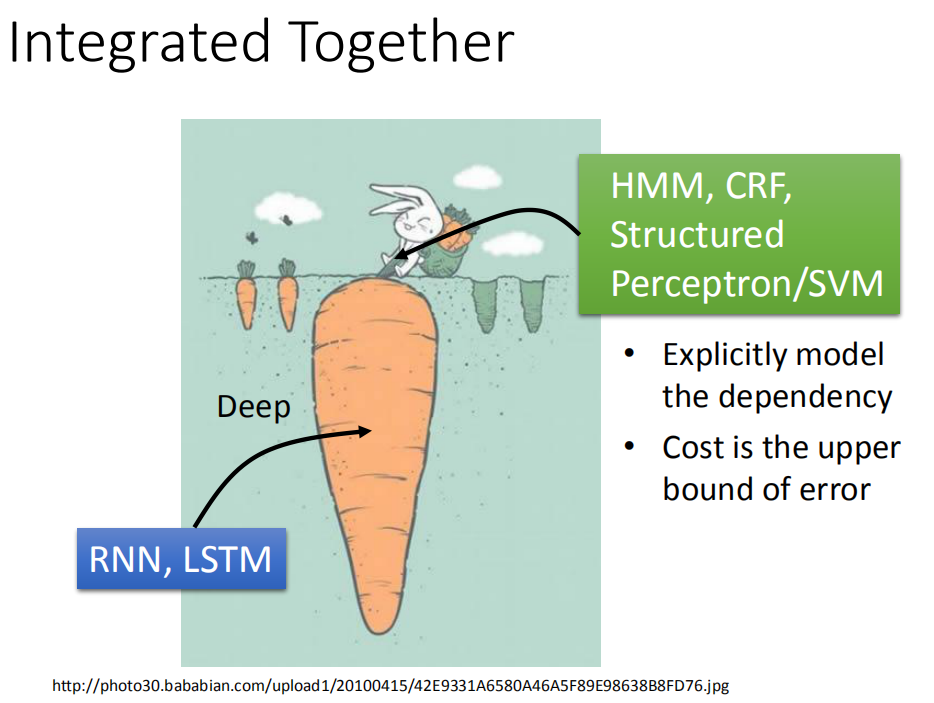 deep learning和structured learning结合起来。input features 先通过RNN/LSTM,然后RNN/LSTM的output再做为HMM/svm的input。用RNN/LSTM的output来定义HMM/structured SVM的evaluation function,如此就可以同时享有deep learning的好处,也可以有structure learning的好处。
deep learning和structured learning结合起来。input features 先通过RNN/LSTM,然后RNN/LSTM的output再做为HMM/svm的input。用RNN/LSTM的output来定义HMM/structured SVM的evaluation function,如此就可以同时享有deep learning的好处,也可以有structure learning的好处。
 在语音上,我们常常把deep learning 和structure learning 合起来(CNN/LSTM/DNN + HMM),所以做语音的时候一般HMM都还在,这样得到的结果往往是最好的。
在语音上,我们常常把deep learning 和structure learning 合起来(CNN/LSTM/DNN + HMM),所以做语音的时候一般HMM都还在,这样得到的结果往往是最好的。
这个系统工作流程:
在HMM里面,必须要去计算
其中
其实加上HMM在语音辨识里很有帮助,就算是用RNN,但是在辨识的时候,常常会遇到问题,假设我们是一个frame,用RNN来问这个frame属于哪个form,往往会产生奇怪的结果,比如说一个frame往往是蔓延好多个frame,比如理论是是看到第一个frame是A,第二个frame是A,第三个是A,第四个是A,然后BBB,但是如果用RNN做的时候,RNN每个产生的label都是独立的,所以可能会在前面若无其事的改成B,然后又是A,RNN很容易出现这个现象。HMM则可以把这种情况修复。因为RNN在训练的时候是分来考虑的,假如不同的错误对语音辨识结果影响很大,结果就会不好。所以加上HMM会很有帮助。
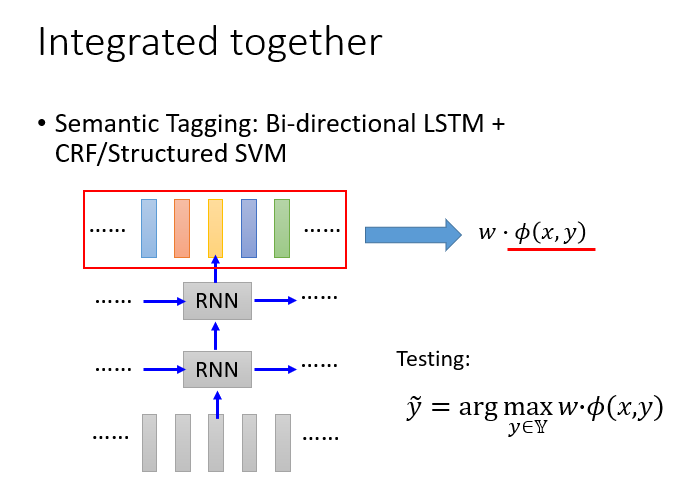
先用Bi-directional LSTM做feature,然后把这些feature拿来在做CRF或者Structured SVM,然后学习一个权重w,这个
Structure learning practical?
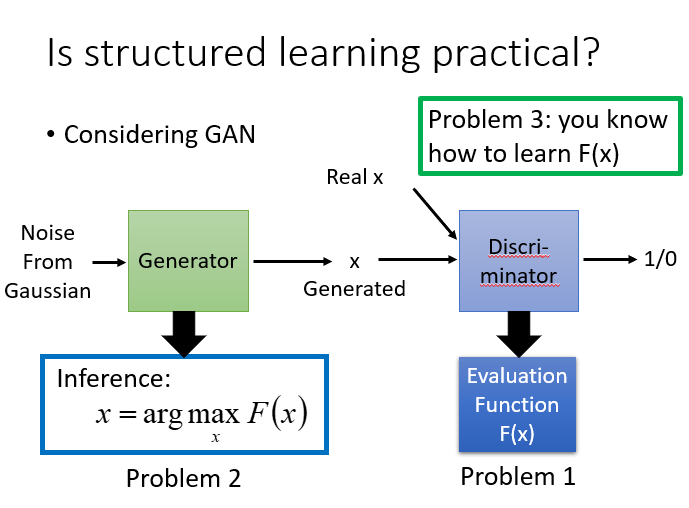
有人说structured learning是否现实?
structured learning需要解三个问题,其中input的问题往往很困难,因为要穷举所有的y让其最大,解一个optimization的问题,其实大部分状况都没有好的解决办法,只有少数有,其他都是不好的状况。所有有人说structured learning应用并不广泛,但是未来未必是这样的。
其实GAN就是一种structured learning,可以把discriminator看做是evaluation function(也就是problem 1)最后要解一个inference的问题,我们要穷举我们未知的东西,看看哪个可以让我们的evaluation function最大。这步往往比较困难,因为x的可能性太多了。但其实这个可以就是generator,我们可以想成generator就是用所给的noise,输出一个update,它输出的这个高斯模型,就是让discriminator分辨不出的高斯模型,如果discriminator就是evaluation function的话,那output的值就是让evaluation function的值很大的那个对应值,所以这个generator就是在解这个问题,其实generator的输出就是argmax的输出,可以把generator当做在解inference这个问题,然后就直接求problem 3。structured learning过程和GAN模型generator不断产生让discriminator最大的那个值,然后再去训练discriminator不断识别真实值,然后更新值的过程是异曲同工的。
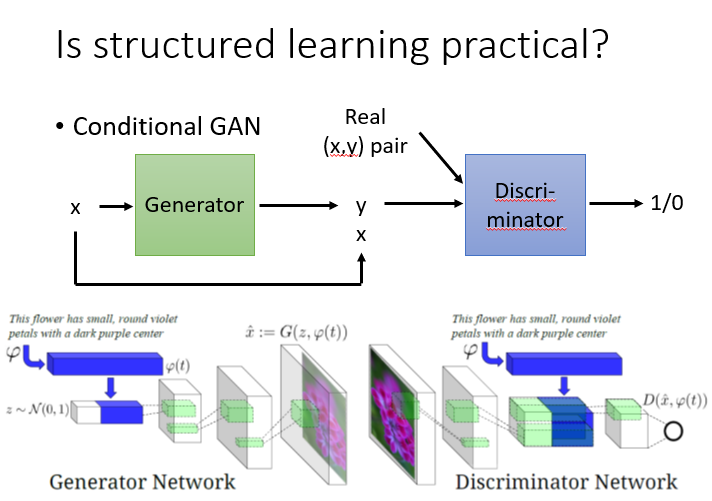
GAN也可以是conditional的GAN,现在的任务是给定x,找出最有可能的y,想象成语音辨识,x是声音讯号,y是辨识出来的文字,如果是用conditional的概念,generator输入一个x,就会output一个y,discriminator是去检查y的pair是不是对的,如果给他一个真正的x,y的pair,会得到一个比较高的分数,给一个generator输出的一个y配上输入的x,所产生的一个假的pair,就会给他一个比较低的分数。训练的过程就和原来的GAN就是一样的,这个已经成功运用在文字产生图片这个task上面。这个task的input就是一句话,output就是一张图,generator做的事就是输入一句话,然后产生一张图片,而discriminator要做的事就是给他一张图片,要他判断这个x,y的pair是不是真的,如果把 discriminator换成evaluation function,把generator换成解inference的problem,其实conditional GAN和structured learning就是可以类比,或者说GAN就是训练structured learning的一种方法。
 很多人都有类似的想法,比如GAN可以和Energy—based模型一起做。这里给出一些Reference。
很多人都有类似的想法,比如GAN可以和Energy—based模型一起做。这里给出一些Reference。
[TOC]
Sequence Models
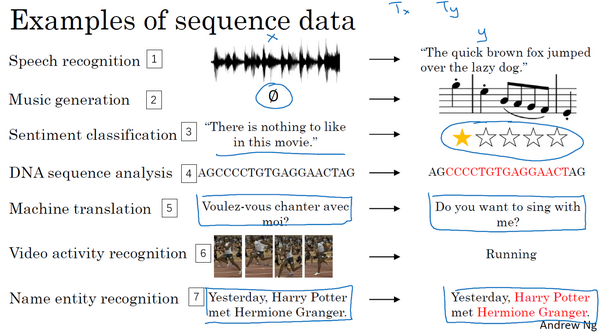
在本课程中你将学会序列模型,它是深度学习中最令人激动的内容之一。循环神经网络(RNN)之类的模型在语音识别、自然语言处理和其他领域中引起变革。在本节课中,你将学会如何自行创建这些模型。我们先看一些例子,这些例子都有效使用了序列模型。
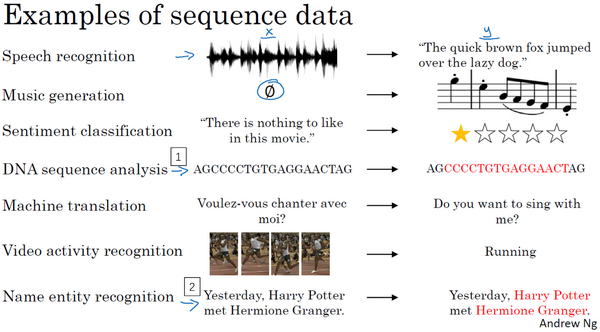
在进行语音识别时,给定了一个输入音频片段
音乐生成问题是使用序列数据的另一个例子,在这个例子中,只有输出数据
在处理情感分类时,输入数据
系列模型在DNA序列分析中也十分有用,你的DNA可以用A、C、G、T四个字母来表示。所以给定一段DNA序列,你能够标记出哪部分是匹配某种蛋白质的吗?
在机器翻译过程中,你会得到这样的输入句:“Voulez-vou chante avecmoi?”(法语:要和我一起唱么?),然后要求你输出另一种语言的翻译结果。
在进行视频行为识别时,你可能会得到一系列视频帧,然后要求你识别其中的行为。
在进行命名实体识别时,可能会给定一个句子要你识别出句中的人名。
所以这些问题都可以被称作使用标签数据
Notation
比如说你想要建立一个序列模型,它的输入语句是这样的:“Harry Potter and Herminoe Granger invented a new spell.”,(这些人名都是出自于J.K.Rowling笔下的系列小说Harry Potter)。假如你想要建立一个能够自动识别句中人名位置的序列模型,那么这就是一个命名实体识别问题,这常用于搜索引擎,比如说索引过去24小时内所有新闻报道提及的人名,用这种方式就能够恰当地进行索引。命名实体识别系统可以用来查找不同类型的文本中的人名、公司名、时间、地点、国家名和货币名等等。

现在给定这样的输入数据
更简单的那种输出形式:
这个输入数据是9个单词组成的序列,所以最终我们会有9个特征集和来表示这9个单词,并按序列中的位置进行索引,
输出数据也是一样,我们还是用
你应该记得我们之前用的符号,我们用
所以在这个例子中,
既然我们这个例子是NLP,也就是自然语言处理,这是我们初次涉足自然语言处理,一件我们需要事先决定的事是怎样表示一个序列里单独的单词,你会怎样表示像Harry这样的单词,
接下来我们讨论一下怎样表示一个句子里单个的词。想要表示一个句子里的单词,第一件事是做一张词表,有时也称为词典,意思是列一列你的表示方法中用到的单词。这个词表(下图所示)中的第一个词是a,也就是说词典中的第一个单词是a,第二个单词是Aaron,然后更下面一些是单词and,再后面你会找到Harry,然后找到Potter,这样一直到最后,词典里最后一个单词可能是Zulu。
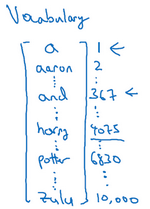
因此a是第一个单词,Aaron是第二个单词,在这个词典里,and出现在367这个位置上,Harry是在4075这个位置,Potter在6830,词典里的最后一个单词Zulu可能是第10,000个单词。所以在这个例子中我用了10,000个单词大小的词典,这对现代自然语言处理应用来说太小了。对于商业应用来说,或者对于一般规模的商业应用来说30,000到50,000词大小的词典比较常见,但是100,000词的也不是没有,而且有些大型互联网公司会用百万词,甚至更大的词典。许多商业应用用的词典可能是30,000词,也可能是50,000词。不过我将用10,000词大小的词典做说明,因为这是一个很好用的整数。
如果你选定了10,000词的词典,构建这个词典的一个方法是遍历你的训练集,并且找到前10,000个常用词,你也可以去浏览一些网络词典,它能告诉你英语里最常用的10,000个单词,接下来你可以用one-hot表示法来表示词典里的每个单词。
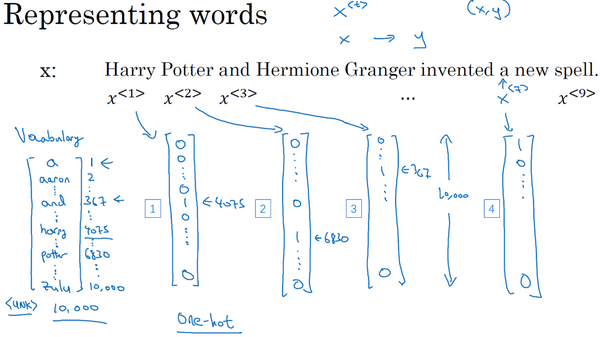
举个例子,在这里
同样
and在词典里排第367,所以
因为a是字典第一个单词,
所以这种表示方法中,
那么还剩下最后一件事,我们将在之后的视频讨论,如果你遇到了一个不在你词表中的单词,答案就是创建一个新的标记,也就是一个叫做Unknow Word的伪造单词,用<UNK>作为标记,来表示不在词表中的单词,我们之后会讨论更多有关这个的内容。
Recurrent Neural Network Model
可以尝试的方法之一是使用标准神经网络,在我们之前的例子中,我们有9个输入单词。想象一下,把这9个输入单词,可能是9个one-hot向量,然后将它们输入到一个标准神经网络中,经过一些隐藏层,最终会输出9个值为0或1的项,它表明每个输入单词是否是人名的一部分。
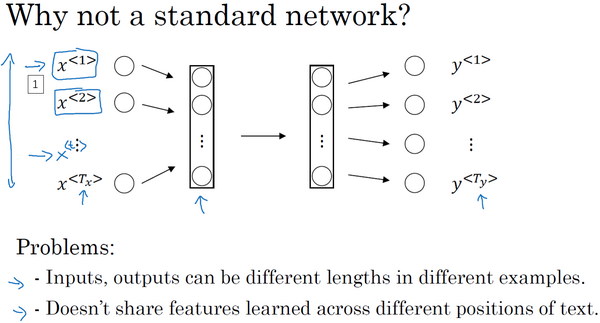
但结果表明这个方法并不好,主要有两个问题,
一、是输入和输出数据在不同例子中可以有不同的长度,不是所有的例子都有着同样输入长度
二、一个像这样单纯的神经网络结构,它并不共享从文本的不同位置上学到的特征。具体来说,如果神经网络已经学习到了在位置1出现的Harry可能是人名的一部分,那么如果Harry出现在其他位置,比如
之前我们提到过这些(上图编号1所示的
那么什么是循环神经网络呢?我们先建立一个(下图编号1所示)。如果你以从左到右的顺序读这个句子,第一个单词就是,假如说是
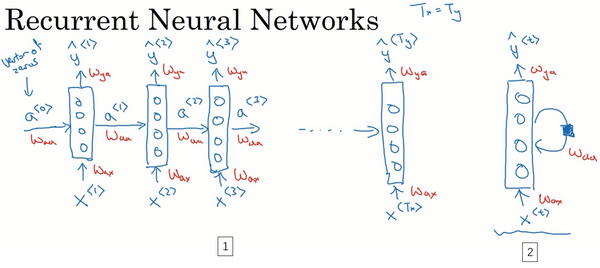
要开始整个流程,在零时刻需要构造一个激活值
在一些研究论文中或是一些书中你会看到这类神经网络,用这样的图形来表示(上图编号2所示),在每一个时间步中,你输入
循环神经网络是从左向右扫描数据,同时每个时间步的参数也是共享的,所以下页幻灯片中我们会详细讲述它的一套参数,我们用
在这个循环神经网络中,它的意思是在预测
所以这样特定的神经网络结构的一个限制是它在某一时刻的预测仅使用了从序列之前的输入信息并没有使用序列中后部分的信息,我们会在之后的双向循环神经网络(BRNN)的视频中处理这个问题。但对于现在,这个更简单的单向神经网络结构就够我们来解释关键概念了,之后只要在此基础上作出修改就能同时使用序列中前面和后面的信息来预测
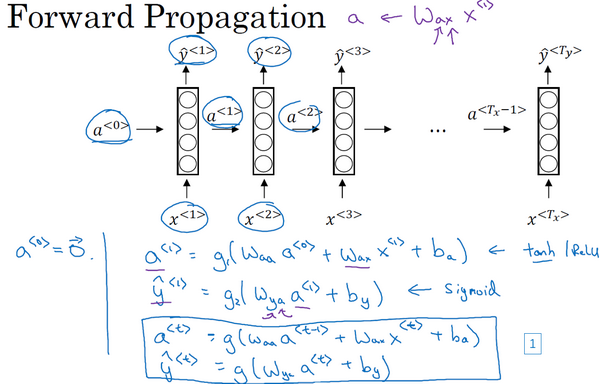
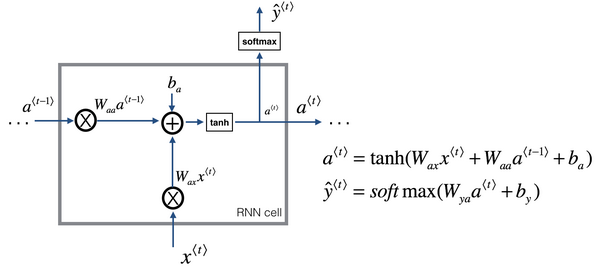
这里是一张清理后的神经网络示意图,和我之前提及的一样,一般开始先输入
我将用这样的符号约定来表示这些矩阵下标,举个例子
循环神经网络用的激活函数经常是tanh,不过有时候也会用ReLU,但是tanh是更通常的选择,我们有其他方法来避免梯度消失问题,我们将在之后进行讲述。选用哪个激活函数是取决于你的输出
更一般的情况下,在
所以这些等式定义了神经网络的前向传播,你可以从零向量
现在为了帮我们建立更复杂的神经网络,我实际要将这个符号简化一下,我在下一张幻灯片里复制了这两个等式(上图编号1所示的两个等式)。

接下来为了简化这些符号,我要将这部分(
用这个符号(
同样对于这个例子(
RNN前向传播示意图:
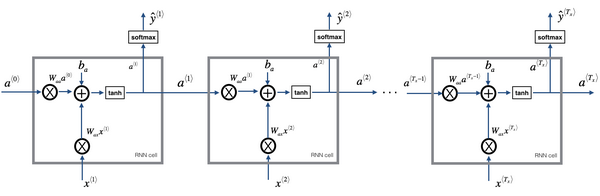
好就这么多,你现在知道了基本的循环神经网络,下节课我们会一起来讨论反向传播,以及你如何能够用RNN进行学习。
Backpropagation through time
之前我们已经学过了循环神经网络的基础结构,在本节视频中我们将来了解反向传播是怎样在循环神经网络中运行的。和之前一样,当你在编程框架中实现循环神经网络时,编程框架通常会自动处理反向传播。但我认为,在循环神经网络中,对反向传播的运行有一个粗略的认识还是非常有用的,让我们来一探究竟。
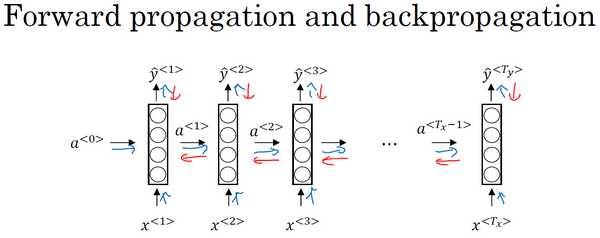
在之前你已经见过对于前向传播(上图蓝色箭头所指方向)怎样在神经网络中从左到右地计算这些激活项,直到输出所有地预测结果。而对于反向传播,我想你已经猜到了,反向传播地计算方向(上图红色箭头所指方向)与前向传播基本上是相反的。
我们来分析一下前向传播的计算,现在你有一个输入序列,
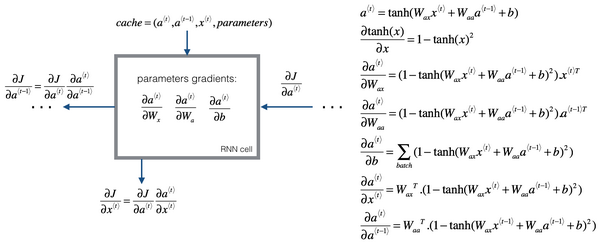
为了真正计算出
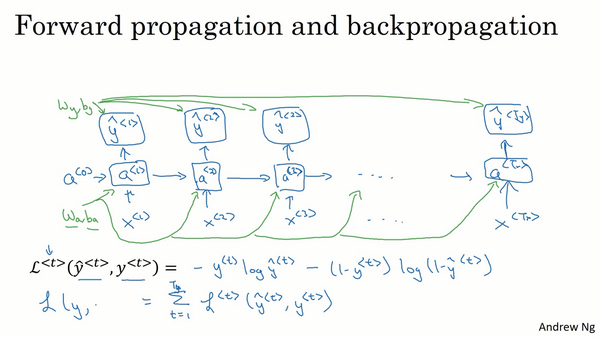
然后为了计算反向传播,你还需要一个损失函数。我们先定义一个元素损失函数(上图编号1所示)
它对应的是序列中一个具体的词,如果它是某个人的名字,那么
现在我们来定义整个序列的损失函数,将
在这个计算图中,通过
这就是完整的计算图,在之前的例子中,你已经见过反向传播,所以你应该能够想得到反向传播算法需要在相反的方向上进行计算和传递信息,最终你做的就是把前向传播的箭头都反过来,在这之后你就可以计算出所有合适的量,然后你就可以通过导数相关的参数,用梯度下降法来更新参数。
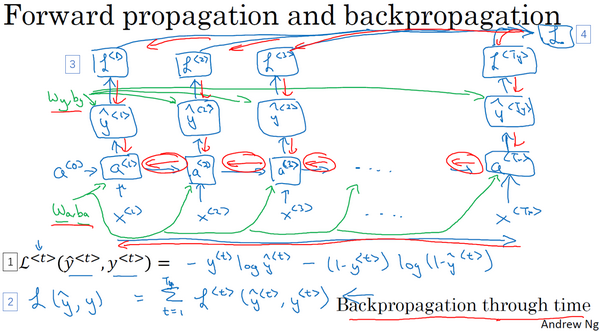
在这个反向传播的过程中,最重要的信息传递或者说最重要的递归运算就是这个从右到左的运算,这也就是为什么这个算法有一个很别致的名字,叫做**“通过(穿越)时间反向传播**(backpropagation through time)”。取这个名字的原因是对于前向传播,你需要从左到右进行计算,在这个过程中,时刻
RNN反向传播示意图:
希望你大致了解了前向和反向传播是如何在RNN中工作的,到目前为止,你只见到了RNN中一个主要的例子,其中输入序列的长度和输出序列的长度是一样的。在下节课将展示更多的RNN架构,这将让你能够处理一些更广泛的应用。
Different types of RNNs
现在你已经了解了一种RNN结构,它的输入量
你应该还记得这周第一个视频中的那个幻灯片,那里有很多例子输入
比如音乐生成这个例子,
还有一些情况,输入长度和输出长度不同,他们都是序列但长度不同,比如机器翻译,一个法语句子和一个英语句子不同数量的单词却能表达同一个意思。
所以我们应该修改基本的RNN结构来处理这些问题,这个视频的内容参考了Andrej Karpathy的博客,一篇叫做《循环神经网络的非理性效果》(“The Unreasonable Effectiveness of Recurrent Neural Networks”)的文章,我们看一些例子。
你已经见过
现在我们看另外一个例子,假如说,你想处理情感分类问题(下图编号2所示),这里

为了完整性,还要补充一个“一对一”(one-to-one)的结构(上图编号3所示),这个可能没有那么重要,这就是一个小型的标准的神经网络,输入
除了“多对一”的结构,也可以有“一对多”(one-to-many)的结构。对于一个“一对多”神经网络结构的例子就是音乐生成(上图编号1所示),事实上,你会在这个课后编程练习中去实现这样的模型,你的目标是使用一个神经网络输出一些音符。对应于一段音乐,输入
这样这个神经网络的结构,首先是你的输入
我们已经讨论了“多对多”、“多对一”、“一对一”和“一对多”的结构,对于“多对多”的结构还有一个有趣的例子值得详细说一下,就是输入和输出长度不同的情况。你刚才看过的多对多的例子,它的输入长度和输出长度是完全一样的。而对于像机器翻译这样的应用,输入句子的单词的数量,比如说一个法语的句子,和输出句子的单词数量,比如翻译成英语,这两个句子的长度可能不同,所以还需要一个新的网络结构,一个不同的神经网络(上图编号2所示)。首先读入这个句子,读入这个输入,比如你要将法语翻译成英语,读完之后,这个网络就会输出翻译结果。有了这种结构
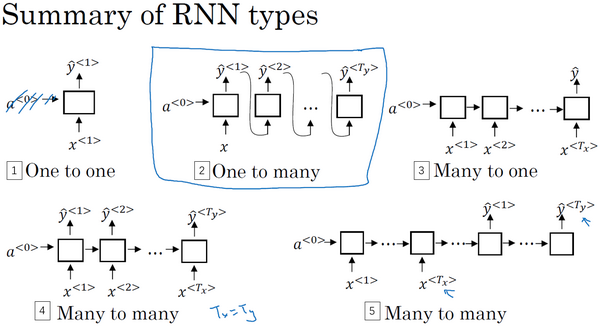
这就是一个“多对多”结构的例子,到这周结束的时候,你就能对这些各种各样结构的基本构件有一个很好的理解。严格来说,还有一种结构,我们会在第四周涉及到,就是“注意力”(attention based)结构,但是根据我们现在画的这些图不好理解这个模型。
总结一下这些各种各样的RNN结构,这(上图编号1所示)是“一对一”的结构,当去掉
现在,你已经了解了大部分基本的模块,这些就是差不多所有的神经网络了,除了序列生成,有些细节的问题我们会在下节课讲解。
我希望你从本视频中了解到用这些RNN的基本模块,把它们组合在一起就可以构建各种各样的模型。但是正如我前面提到的,序列生成还有一些不一样的地方,在这周的练习里,你也会实现它,你需要构建一个语言模型,结果好的话会得到一些有趣的序列或者有意思的文本。下节课深入探讨序列生成。
Language model and sequence generation
在自然语言处理中,构建语言模型是最基础的也是最重要的工作之一,并且能用RNN很好地实现。在本视频中,你将学习用RNN构建一个语言模型,在本周结束的时候,还会有一个很有趣的编程练习,你能在练习中构建一个语言模型,并用它来生成莎士比亚文风的文本或其他类型文本。
所以什么是语言模型呢?比如你在做一个语音识别系统,你听到一个句子,“the apple and pear(pair) salad was delicious.”,所以我究竟说了什么?我说的是 “the apple and pair salad”,还是“the apple and pear salad”?(pear和pair是近音词)。你可能觉得我说的应该更像第二种,事实上,这就是一个好的语音识别系统要帮助输出的东西,即使这两句话听起来是如此相似。而让语音识别系统去选择第二个句子的方法就是使用一个语言模型,他能计算出这两句话各自的可能性。
举个例子,一个语音识别模型可能算出第一句话的概率是
所以语言模型所做的就是,它会告诉你某个特定的句子它出现的概率是多少,根据我所说的这个概率,假设你随机拿起一张报纸,打开任意邮件,或者任意网页或者听某人说下一句话,并且这个人是你的朋友,这个你即将从世界上的某个地方得到的句子会是某个特定句子的概率是多少,例如“the apple and pear salad”。它是两种系统的基本组成部分,一个刚才所说的语音识别系统,还有机器翻译系统,它要能正确输出最接近的句子。而语言模型做的最基本工作就是输入一个句子,准确地说是一个文本序列,
那么如何建立一个语言模型呢?为了使用RNN建立出这样的模型,你首先需要一个训练集,包含一个很大的英文文本语料库(corpus)或者其它的语言,你想用于构建模型的语言的语料库。语料库是自然语言处理的一个专有名词,意思就是很长的或者说数量众多的英文句子组成的文本。

假如说,你在训练集中得到这么一句话,“Cats average 15 hours of sleep a day.”(猫一天睡15小时),你要做的第一件事就是将这个句子标记化,意思就是像之前视频中一样,建立一个字典,然后将每个单词都转换成对应的one-hot向量,也就是字典中的索引。可能还有一件事就是你要定义句子的结尾,一般的做法就是增加一个额外的标记,叫做EOS(上图编号1所示),它表示句子的结尾,这样能够帮助你搞清楚一个句子什么时候结束,我们之后会详细讨论这个。EOS标记可以被附加到训练集中每一个句子的结尾,如果你想要你的模型能够准确识别句子结尾的话。在本周的练习中我们不需要使用这个EOS标记,不过在某些应用中你可能会用到它,不过稍后就能见到它的用处。于是在本例中我们,如果你加了EOS标记,这句话就会有9个输入,有
现在还有一个问题如果你的训练集中有一些词并不在你的字典里,比如说你的字典有10,000个词,10,000个最常用的英语单词。现在这个句,“The Egyptian Mau is a bread of cat.”其中有一个词Mau,它可能并不是预先的那10,000个最常用的单词,在这种情况下,你可以把Mau替换成一个叫做UNK的代表未知词的标志,我们只针对UNK建立概率模型,而不是针对这个具体的词Mau。
完成标识化的过程后,这意味着输入的句子都映射到了各个标志上,或者说字典中的各个词上。下一步我们要构建一个RNN来构建这些序列的概率模型。在下一张幻灯片中会看到的一件事就是最后你会将
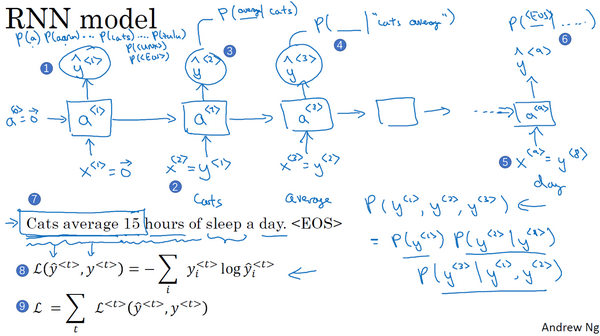
现在我们来建立RNN模型,我们继续使用“Cats average 15 hours of sleep a day.”这个句子来作为我们的运行样例,我将会画出一个RNN结构。在第0个时间步,你要计算激活项
然后RNN进入下个时间步,在下一时间步中,仍然使用激活项
然后再进行RNN的下个时间步,现在要计算
一直到最后,没猜错的话,你会停在第9个时间步,然后把
所以RNN中的每一步都会考虑前面得到的单词,比如给它前3个单词(上图编号7所示),让它给出下个词的分布,这就是RNN如何学习从左往右地每次预测一个词。
接下来为了训练这个网络,我们要定义代价函数。于是,在某个时间步
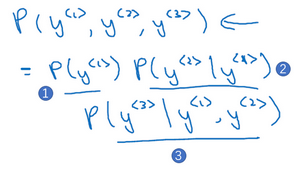
如果你用很大的训练集来训练这个RNN,你就可以通过开头一系列单词像是Cars average 15或者Cars average 15 hours of来预测之后单词的概率。现在有一个新句子,它是
Sampling novel sequences
在你训练一个序列模型之后,要想了解到这个模型学到了什么,一种非正式的方法就是进行一次新序列采样,来看看到底应该怎么做。
记住一个序列模型模拟了任意特定单词序列的概率,我们要做的就是对这些概率分布进行采样来生成一个新的单词序列。下图编号1所示的网络已经被上方所展示的结构训练过了,而为了进行采样(下图编号2所示的网络),你要做一些截然不同的事情。
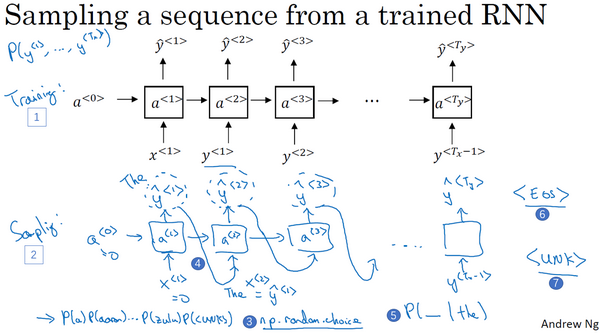
第一步要做的就是对你想要模型生成的第一个词进行采样,于是你输入np.random.choice(上图编号3所示),来根据向量中这些概率的分布进行采样,这样就能对第一个词进行采样了。
然后继续下一个时间步,记住第二个时间步需要
然后再到下一个时间步,无论你得到什么样的用one-hot码表示的选择结果,都把它传递到下一个时间步,然后对第三个词进行采样。不管得到什么都把它传递下去,一直这样直到最后一个时间步。
那么你要怎样知道一个句子结束了呢?方法之一就是,如果代表句子结尾的标识在你的字典中,你可以一直进行采样直到得到EOS标识(上图编号6所示),这代表着已经抵达结尾,可以停止采样了。另一种情况是,如果你的字典中没有这个词,你可以决定从20个或100个或其他个单词进行采样,然后一直将采样进行下去直到达到所设定的时间步。不过这种过程有时候会产生一些未知标识(上图编号7所示),如果你要确保你的算法不会输出这种标识,你能做的一件事就是拒绝采样过程中产生任何未知的标识,一旦出现就继续在剩下的词中进行重采样,直到得到一个不是未知标识的词。如果你不介意有未知标识产生的话,你也可以完全不管它们。
这就是你如何从你的RNN语言模型中生成一个随机选择的句子。直到现在我们所建立的是基于词汇的RNN模型,意思就是字典中的词都是英语单词(下图编号1所示)。
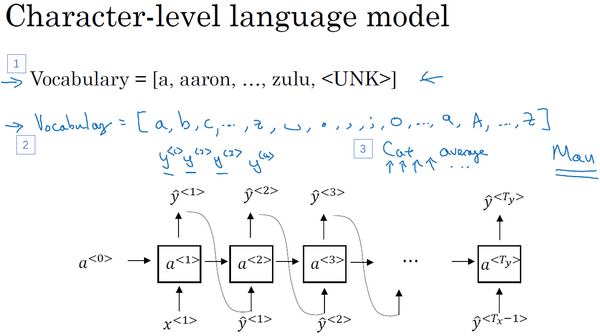
根据你实际的应用,你还可以构建一个基于字符的RNN结构,在这种情况下,你的字典仅包含从a到z的字母,可能还会有空格符,如果你需要的话,还可以有数字0到9,如果你想区分字母大小写,你可以再加上大写的字母,你还可以实际地看一看训练集中可能会出现的字符,然后用这些字符组成你的字典(上图编号2所示)。
如果你建立一个基于字符的语言模型,比起基于词汇的语言模型,你的序列
使用基于字符的语言模型有有点也有缺点,优点就是你不必担心会出现未知的标识,例如基于字符的语言模型会将Mau这样的序列也视为可能性非零的序列。而对于基于词汇的语言模型,如果Mau不在字典中,你只能把它当作未知标识UNK。不过基于字符的语言模型一个主要缺点就是你最后会得到太多太长的序列,大多数英语句子只有10到20个的单词,但却可能包含很多很多字符。所以基于字符的语言模型在捕捉句子中的依赖关系也就是句子较前部分如何影响较后部分不如基于词汇的语言模型那样可以捕捉长范围的关系,并且基于字符的语言模型训练起来计算成本比较高昂。所以我见到的自然语言处理的趋势就是,绝大多数都是使用基于词汇的语言模型,但随着计算机性能越来越高,会有更多的应用。在一些特殊情况下,会开始使用基于字符的模型。但是这确实需要更昂贵的计算力来训练,所以现在并没有得到广泛地使用,除了一些比较专门需要处理大量未知的文本或者未知词汇的应用,还有一些要面对很多专有词汇的应用。
在现有的方法下,现在你可以构建一个RNN结构,看一看英文文本的语料库,然后建立一个基于词汇的或者基于字符的语言模型,然后从训练的语言模型中进行采样。

这里有一些样本,它们是从一个语言模型中采样得到的,准确来说是基于字符的语言模型,你可以在编程练习中自己实现这样的模型。如果模型是用新闻文章训练的,它就会生成左边这样的文本,这有点像一篇不太合乎语法的新闻文本,不过听起来,这句“Concussion epidemic”,to be examined,确实有点像新闻报道。用莎士比亚的文章训练后生成了右边这篇东西,听起来很像是莎士比亚写的东西:
“The mortal moon hath her eclipse in love.
And subject of this thou art another this fold.
When besser be my love to me see sabl's.
For whose are ruse of mine eyes heaves.”
这些就是基础的RNN结构和如何去建立一个语言模型并使用它,对于训练出的语言模型进行采样。在之后的视频中,我想探讨在训练RNN时一些更加深入的挑战以及如何适应这些挑战,特别是梯度消失问题来建立更加强大的RNN模型。下节课,我们将谈到梯度消失并且会开始谈到GRU,也就是门控循环单元和LSTM长期记忆网络模型。
Vanishing gradients with RNNs
你已经了解了RNN时如何工作的了,并且知道如何应用到具体问题上,比如命名实体识别,比如语言模型,你也看到了怎么把反向传播用于RNN。其实,基本的RNN算法还有一个很大的问题,就是梯度消失的问题。这节课我们会讨论,在下几节课我们会讨论一些方法用来解决这个问题。
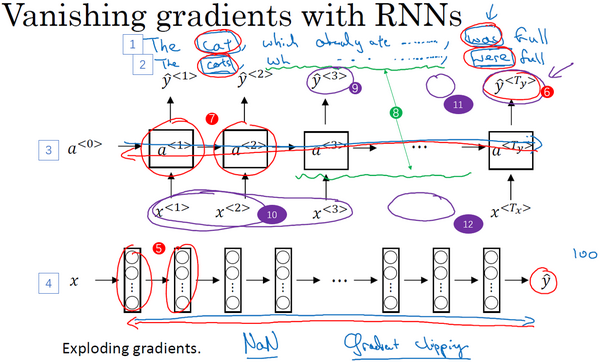
你已经知道了RNN的样子,现在我们举个语言模型的例子,假如看到这个句子(上图编号1所示),“The cat, which already ate ……, was full.”,前后应该保持一致,因为cat是单数,所以应该用was。“The cats, which ate ……, were full.”(上图编号2所示),cats是复数,所以用were。这个例子中的句子有长期的依赖,最前面的单词对句子后面的单词有影响。但是我们目前见到的基本的RNN模型(上图编号3所示的网络模型),不擅长捕获这种长期依赖效应,解释一下为什么。
你应该还记得之前讨论的训练很深的网络,我们讨论了梯度消失的问题。比如说一个很深很深的网络(上图编号4所示),100层,甚至更深,对这个网络从左到右做前向传播然后再反向传播。我们知道如果这是个很深的神经网络,从输出
对于有同样问题的RNN,首先从左到右前向传播,然后反向传播。但是反向传播会很困难,因为同样的梯度消失的问题,后面层的输出误差(上图编号6所示)很难影响前面层(上图编号7所示的层)的计算。这就意味着,实际上很难让一个神经网络能够意识到它要记住看到的是单数名词还是复数名词,然后在序列后面生成依赖单复数形式的was或者were。而且在英语里面,这中间的内容(上图编号8所示)可以任意长,对吧?所以你需要长时间记住单词是单数还是复数,这样后面的句子才能用到这些信息。也正是这个原因,所以基本的RNN模型会有很多局部影响,意味着这个输出

尽管我们一直在讨论梯度消失问题,但是,你应该记得我们在讲很深的神经网络时,我们也提到了梯度爆炸,我们在反向传播的时候,随着层数的增多,梯度不仅可能指数型的下降,也可能指数型的上升。事实上梯度消失在训练RNN时是首要的问题,尽管梯度爆炸也是会出现,但是梯度爆炸很明显,因为指数级大的梯度会让你的参数变得极其大,以至于你的网络参数崩溃。所以梯度爆炸很容易发现,因为参数会大到崩溃,你会看到很多NaN,或者不是数字的情况,这意味着你的网络计算出现了数值溢出。如果你发现了梯度爆炸的问题,一个解决方法就是用梯度修剪。梯度修剪的意思就是观察你的梯度向量,如果它大于某个阈值,缩放梯度向量,保证它不会太大,这就是通过一些最大值来修剪的方法。所以如果你遇到了梯度爆炸,如果导数值很大,或者出现了NaN,就用梯度修剪,这是相对比较鲁棒的,这是梯度爆炸的解决方法。然而梯度消失更难解决,这也是我们下几节视频的主题。
总结一下,在前面的课程,我们了解了训练很深的神经网络时,随着层数的增加,导数有可能指数型的下降或者指数型的增加,我们可能会遇到梯度消失或者梯度爆炸的问题。加入一个RNN处理1,000个时间序列的数据集或者10,000个时间序列的数据集,这就是一个1,000层或者10,000层的神经网络,这样的网络就会遇到上述类型的问题。梯度爆炸基本上用梯度修剪就可以应对,但梯度消失比较棘手。我们下节会介绍GRU,门控循环单元网络,这个网络可以有效地解决梯度消失的问题,并且能够使你的神经网络捕获更长的长期依赖,我们去下个视频一探究竟吧。
Gated Recurrent Unit(GRU)
你已经了解了基础的RNN模型的运行机制,在本节视频中你将会学习门控循环单元,它改变了RNN的隐藏层,使其可以更好地捕捉深层连接,并改善了梯度消失问题,让我们看一看。
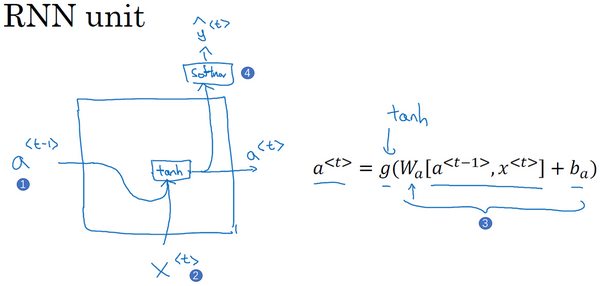
你已经见过了这个公式,

许多GRU的想法都来分别自于Yu Young Chang, Kagawa,Gaza Hera, Chang Hung Chu和Jose Banjo的两篇论文。我再引用上个视频中你已经见过的这个句子,“The cat, which already ate……, was full.”,你需要记得猫是单数的,为了确保你已经理解了为什么这里是was而不是were,“The cat was full.”或者是“The cats were full”。当我们从左到右读这个句子,GRU单元将会有个新的变量称为
所以这些等式表示了GRU单元的计算,在每个时间步,我们将用一个候选值重写记忆细胞,即

重点来了,在GRU中真正重要的思想是我们有一个门,我先把这个门叫做
然后GRU的关键部分就是上图编号3所示的等式,我们刚才写出来的用

所以我们接下来要给GRU用的式子就是
让我再画个图来(下图所示)解释一下GRU单元,顺便说一下,当你在看网络上的博客或者教科书或者教程之类的,这些图对于解释GRU和我们稍后会讲的LSTM是相当流行的,我个人感觉式子在图片中比较容易理解,那么即使看不懂图片也没关系,我就画画,万一能帮得上忙就最好了。
GRU单元输入
再用一个不同的参数集,通过sigmoid激活函数算出
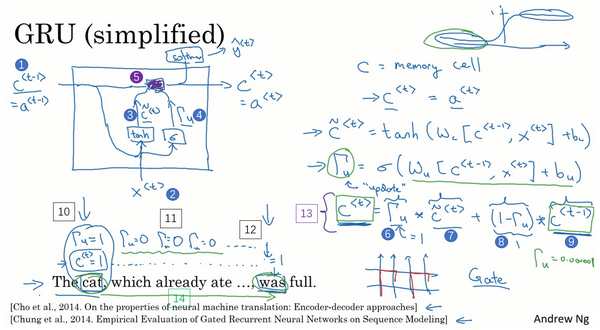
这就是GRU单元或者说是一个简化过的GRU单元,它的优点就是通过门决定,当你从左(上图编号10所示)到右扫描一个句子的时候,这个时机是要更新某个记忆细胞,还是不更新,不更新(上图编号11所示,中间
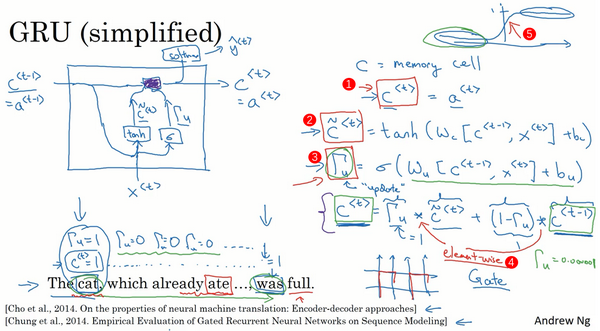
现在我想说下一些实现的细节,在这个我写下的式子中
当然在实际应用中
你现在已经理解GRU最重要的思想了,幻灯片中展示的实际上只是简化过的GRU单元,现在来描述一下完整的GRU单元。
对于完整的GRU单元我要做的一个改变就是在我们计算的第一个式子中给记忆细胞的新候选值加上一个新的项,我要添加一个门

正如你所见,有很多方法可以来设计这些类型的神经网络,然后我们为什么有
还有在符号上的一点,我尝试去定义固定的符号让这些概念容易理解,如果你看学术文章的话,你有的时候会看到有些人使用另一种符号
所以这就是GRU,即门控循环单元,这是RNN的其中之一。这个结构可以更好捕捉非常长范围的依赖,让RNN更加有效。然后我简单提一下其他常用的神经网络,比较经典的是这个叫做LSTM,即长短时记忆网络,我们在下节视频中讲解。
(Chung J, Gulcehre C, Cho K H, et al. Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling[J]. Eprint Arxiv, 2014.
Cho K, Merrienboer B V, Bahdanau D, et al. On the Properties of Neural Machine Translation: Encoder-Decoder Approaches[J]. Computer Science, 2014.)
1.10 长短期记忆(LSTM(long short term memory)unit)
在上一个视频中你已经学了GRU(门控循环单元)。它能够让你可以在序列中学习非常深的连接。其他类型的单元也可以让你做到这个,比如LSTM即长短时记忆网络,甚至比GRU更加有效,让我们看看。
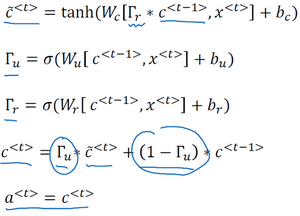
这里是上个视频中的式子,对于GRU我们有
还有两个门:
更新门
相关门
LSTM是一个比GRU更加强大和通用的版本,这多亏了 Sepp Hochreiter和 Jurgen Schmidhuber,感谢那篇开创性的论文,它在序列模型上有着巨大影响。我感觉这篇论文是挺难读懂的,虽然我认为这篇论文在深度学习社群有着重大的影响,它深入讨论了梯度消失的理论,我感觉大部分的人学到LSTM的细节是在其他的地方,而不是这篇论文。

这就是LSTM主要的式子(上图编号2所示),我们继续回到记忆细胞c上面来,使用
我们像以前那样有一个更新门
然后这里(上图编号7所示)用遗忘门(the forget gate),我们叫它
然后我们有一个新的输出门,
于是记忆细胞的更新值
所以这给了记忆细胞选择权去维持旧的值
然后这个表示更新门(
遗忘门(
最后
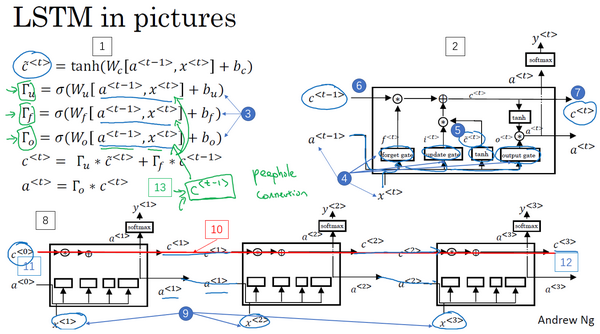
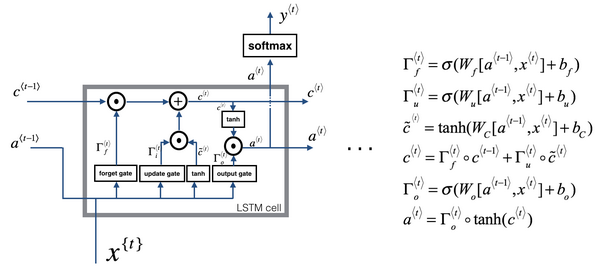
再提一下,这些式子就是控制LSTM行为的主要的式子了(上图编号1所示)。像之前一样用图片稍微解释一下,先让我把图画在这里(上图编号2所示)。如果图片过于复杂,别担心,我个人感觉式子比图片好理解,但是我画图只是因为它比较直观。这个右上角的图的灵感来自于Chris Ola的一篇博客,标题是《理解LSTM网络》(Understanding LSTM Network),这里的这张图跟他博客上的图是很相似的,但关键的不同可能是这里的这张图用了
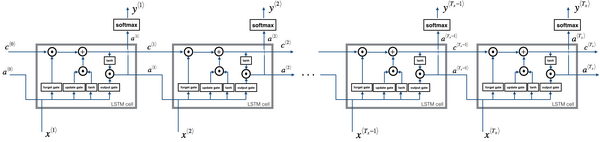
这里其中一个元素很有意思,如你在这一堆图(上图编号8所示的一系列图片)中看到的,这是其中一个,再把他们连起来,就是把它们按时间次序连起来,这里(上图编号9所示)输入
这就是LSTM,你可能会想到这里和一般使用的版本会有些不同,最常用的版本可能是门值不仅取决于
如你所见LSTM主要的区别在于一个技术上的细节,比如这(上图编号13所示)有一个100维的向量,你有一个100维的隐藏的记忆细胞单元,然后比如第50个
LSTM前向传播图:
LSTM反向传播计算:
门求偏导:
**参数求偏导 **:
$ dW_f = d\Gamma_f^{\langle t \rangle} * \begin{pmatrix} a_{prev} \ x_t\end{pmatrix}^T \tag{5}
为了计算
最后,计算隐藏状态、记忆状态和输入的偏导数:
$ da_{prev} = W_f^T*d\Gamma_f^{\langle t \rangle} + W_u^T * d\Gamma_u^{\langle t \rangle}+ W_c^T * d\tilde c^{\langle t \rangle} + W_o^T * d\Gamma_o^{\langle t \rangle} \tag{9}$
$ dc_{prev} = dc_{next}\Gamma_f^{\langle t \rangle} + \Gamma_o^{\langle t \rangle} * (1- \tanh(c_{next})^2)*\Gamma_f^{\langle t \rangle}da_{next} \tag{10}
这就是LSTM,我们什么时候应该用GRU?什么时候用LSTM?这里没有统一的准则。而且即使我先讲解了GRU,在深度学习的历史上,LSTM也是更早出现的,而GRU是最近才发明出来的,它可能源于Pavia在更加复杂的LSTM模型中做出的简化。研究者们在很多不同问题上尝试了这两种模型,看看在不同的问题不同的算法中哪个模型更好,所以这不是个学术和高深的算法,我才想要把这两个模型展示给你。
GRU的优点是这是个更加简单的模型,所以更容易创建一个更大的网络,而且它只有两个门,在计算性上也运行得更快,然后它可以扩大模型的规模。
但是LSTM更加强大和灵活,因为它有三个门而不是两个。如果你想选一个使用,我认为LSTM在历史进程上是个更优先的选择,所以如果你必须选一个,我感觉今天大部分的人还是会把LSTM作为默认的选择来尝试。虽然我认为最近几年GRU获得了很多支持,而且我感觉越来越多的团队也正在使用GRU,因为它更加简单,而且还效果还不错,它更容易适应规模更加大的问题。
所以这就是LSTM,无论是GRU还是LSTM,你都可以用它们来构建捕获更加深层连接的神经网络。
(Hochreiter S, Schmidhuber J. Long Short-Term Memory[J]. Neural Computation, 1997, 9(8):1735-1780.)
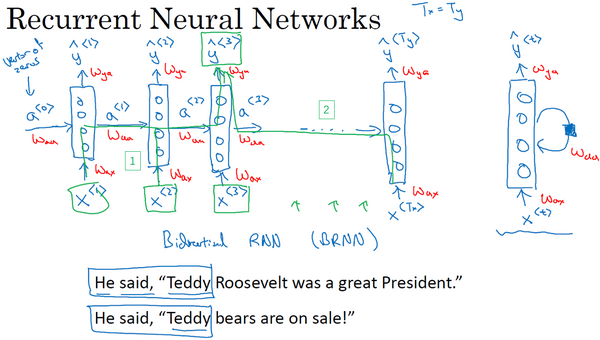
1.11 双向循环神经网络(Bidirectional RNN)
现在,你已经了解了大部分RNN模型的关键的构件,还有两个方法可以让你构建更好的模型,其中之一就是双向RNN模型,这个模型可以让你在序列的某点处不仅可以获取之前的信息,还可以获取未来的信息,我们会在这个视频里讲解。第二个就是深层的RNN,我们会在下个视频里见到,现在先从双向RNN开始吧。
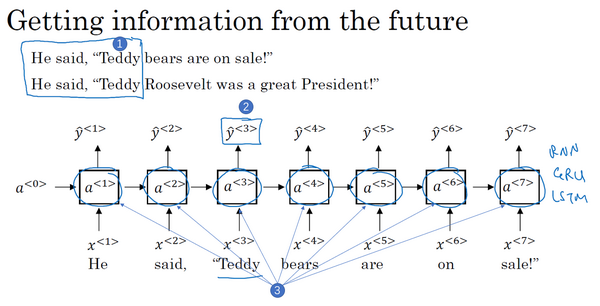
为了了解双向RNN的动机,我们先看一下之前在命名实体识别中已经见过多次的神经网络。这个网络有一个问题,在判断第三个词Teddy(上图编号1所示)是不是人名的一部分时,光看句子前面部分是不够的,为了判断
那么一个双向的RNN是如何解决这个问题的?下面解释双向RNN的工作原理。为了简单,我们用四个输入或者说一个只有4个单词的句子,这样输入只有4个,
到目前为止,我还没做什么,仅仅是把前面幻灯片里的RNN画在了这里,只是在这些地方画上了箭头。我之所以在这些地方画上了箭头是因为我们想要增加一个反向循环层,这里有个
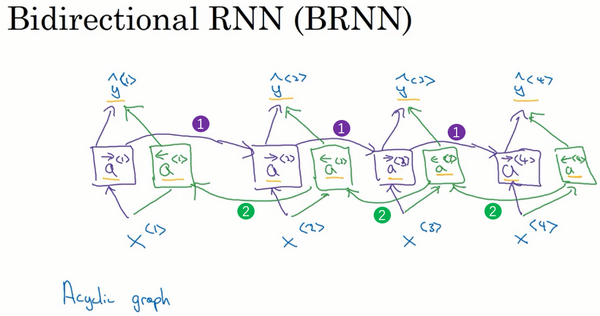
同样,我们把网络这样向上连接,这个
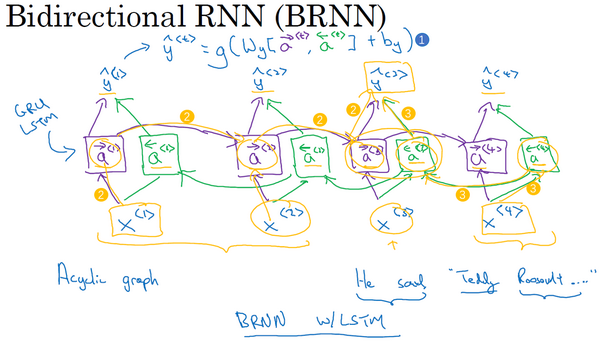
举个例子,为了预测结果,你的网络会有如
这就是双向循环神经网络,并且这些基本单元不仅仅是标准RNN单元,也可以是GRU单元或者LSTM单元。事实上,很多的NLP问题,对于大量有自然语言处理问题的文本,有LSTM单元的双向RNN模型是用的最多的。所以如果有NLP问题,并且文本句子都是完整的,首先需要标定这些句子,一个有LSTM单元的双向RNN模型,有前向和反向过程是一个不错的首选。
以上就是双向RNN的内容,这个改进的方法不仅能用于基本的RNN结构,也能用于GRU和LSTM。通过这些改变,你就可以用一个用RNN或GRU或LSTM构建的模型,并且能够预测任意位置,即使在句子的中间,因为模型能够考虑整个句子的信息。这个双向RNN网络模型的缺点就是你需要完整的数据的序列,你才能预测任意位置。比如说你要构建一个语音识别系统,那么双向RNN模型需要你考虑整个语音表达,但是如果直接用这个去实现的话,你需要等待这个人说完,然后获取整个语音表达才能处理这段语音,并进一步做语音识别。对于实际的语音识别的应用通常会有更加复杂的模块,而不是仅仅用我们见过的标准的双向RNN模型。但是对于很多自然语言处理的应用,如果你总是可以获取整个句子,这个标准的双向RNN算法实际上很高效。
好的,这就是双向RNN,下一个视频,也是这周的最后一个,我们会讨论如何用这些概念,标准的RNN,LSTM单元,GRU单元,还有双向的版本,构建更深的网络。
1.12 深层循环神经网络(Deep RNNs)
目前你学到的不同RNN的版本,每一个都可以独当一面。但是要学习非常复杂的函数,通常我们会把RNN的多个层堆叠在一起构建更深的模型。这节视频里我们会学到如何构建这些更深的RNN。
一个标准的神经网络,首先是输入
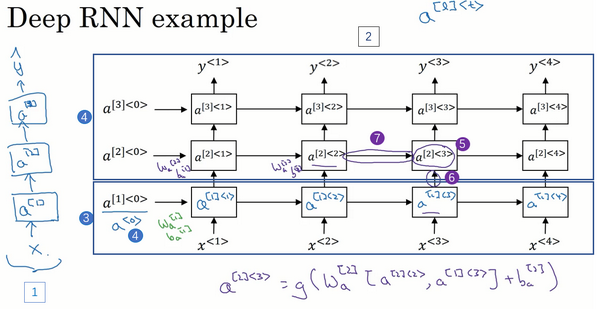
这是我们一直见到的标准的RNN(上图编号3所示方框内的RNN),只是我把这里的符号稍微改了一下,不再用原来的
我们看个具体的例子,看看这个值(
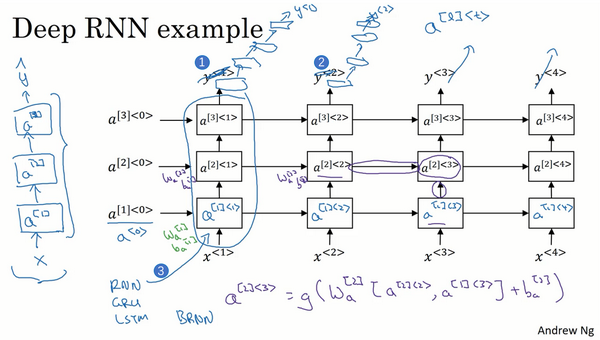
对于像左边这样标准的神经网络,你可能见过很深的网络,甚至于100层深,而对于RNN来说,有三层就已经不少了。由于时间的维度,RNN网络会变得相当大,即使只有很少的几层,很少会看到这种网络堆叠到100层。但有一种会容易见到,就是在每一个上面堆叠循环层,把这里的输出去掉(上图编号1所示),然后换成一些深的层,这些层并不水平连接,只是一个深层的网络,然后用来预测
这就是深层RNN的内容,从基本的RNN网络,基本的循环单元到GRU,LSTM,再到双向RNN,还有深层版的模型。这节课后,你已经可以构建很不错的学习序列的模型了。