 Monarch矩阵
Monarch矩阵
文章来源:Monarch矩阵-计算高效的稀疏型矩阵分解 (opens new window)
最佳排版请看原博客:Monarch矩阵:计算高效的稀疏型矩阵分解 - 科学空间|Scientific Spaces (opens new window)
在矩阵压缩这个问题上,我们通常有两个策略可以选择,分别是低秩化和稀疏化。低秩化通过寻找矩阵的低秩近似来减少矩阵尺寸,而稀疏化则是通过减少矩阵中的非零元素来降低矩阵的复杂性。如果说SVD是奔着矩阵的低秩近似去的,那么相应地寻找矩阵稀疏近似的算法又是什么呢?
接下来我们要学习的是论文《Monarch: Expressive Structured Matrices for Efficient and Accurate Training》 (opens new window),它为上述问题给出了一个答案——“Monarch矩阵”,这是一簇能够分解为若干置换矩阵与稀疏矩阵乘积的矩阵,同时具备计算高效且表达能力强的特点,论文还讨论了如何求一般矩阵的Monarch近似,以及利用Monarch矩阵参数化LLM来提高LLM速度等内容。
值得指出的是,该论文的作者也正是著名的Flash Attention的作者Tri Dao,其工作几乎都在致力于改进LLM的性能,这篇Monarch也是个人主页 (opens new window)上特意展示的几篇论文之一,单从这一点看就非常值得学习一番。
SVD回顾
首先我们来简单回顾一下SVD(奇异值分解)。对于矩阵
其中
这里下标就按照Python的切片来执行,所以
特别地,由SVD得到的如上低秩近似,正好是如下优化问题的精确解:
其中
SVD可以展开讨论的内容非常多,甚至写成一本书也不为过,这里就不再继续深入了。最后说一下,SVD的计算复杂度是
Monarch矩阵
低秩分解应用非常广,但它未必总是符合我们的需求,比如可逆方阵的低秩近似必然不可逆,这意味着低秩近似不适合需要求逆的场景。此时另一个选择是稀疏近似,稀疏矩阵通常能够保证秩不退化。
注意稀疏和低秩并无必然联系,比如单位阵就是很稀疏的矩阵,但它可逆(满秩)。寻找矩阵的稀疏近似并不难,比如将绝对值最大的
Monarch矩阵正是为此而生,假设
其中
置换矩阵
置换矩阵
当然这样写大家可能依然觉得迷糊,然事实上用代码实现非常简单:
Px = x.reshape(m, m).transpose().reshape(n)
如下图所示:
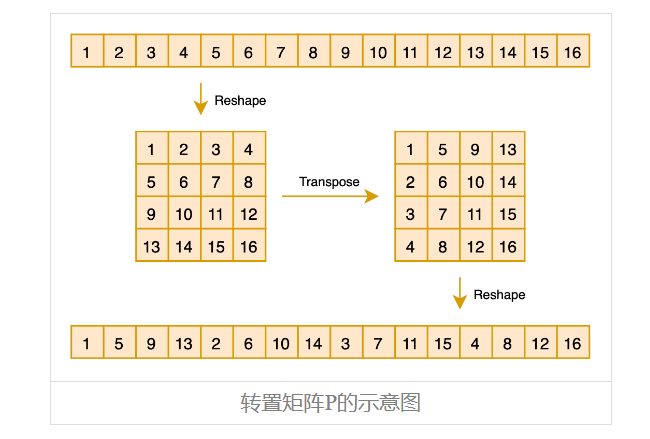
之前做CV的读者可能会觉得这个操作有点熟悉,它其实就是ShuffleNet (opens new window)中的“Shuffle”操作,这样对向量先reshape然后transpose最后再reshape回来的组合运算,起到一种“伪Shuffle”的效果,它也可以视为
分块对角
说完
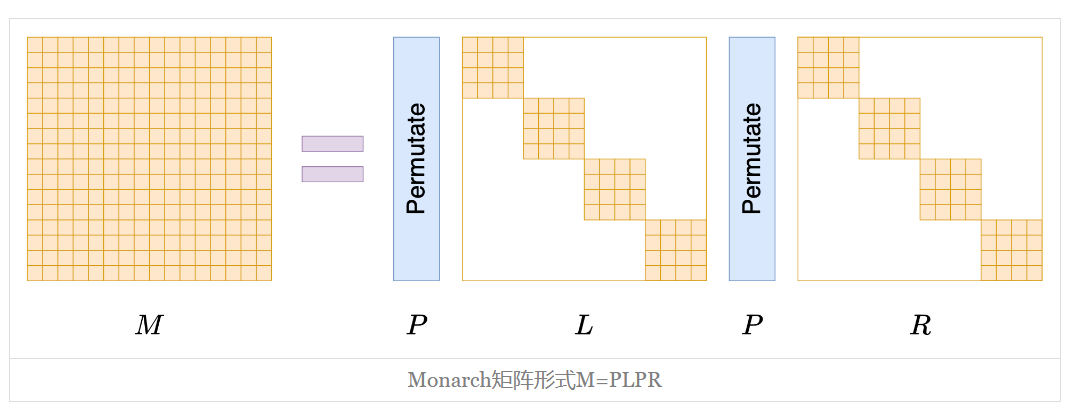
当
效率简析
那么Monarch矩阵能否达到这个目的呢?换句话说Monarch矩阵能否达到前面说的“实用”标准?表达能力方面我们后面再谈,我们先看计算高效方面。
比如“矩阵-向量”乘法,标准的复杂度是
再比如求逆,我们考虑
所以结论就是,由于
Monarch分解
确认Monarch矩阵的有效性后,接下来应用方面的一个关键问题就是:给定任意的
非常幸运的是,这个问题有一个复杂度不超过
高维数组
理解这个算法的关键一步,是将Monarch相关的矩阵、向量都转化为更高维数组的形式。具体来说,Monarch矩阵
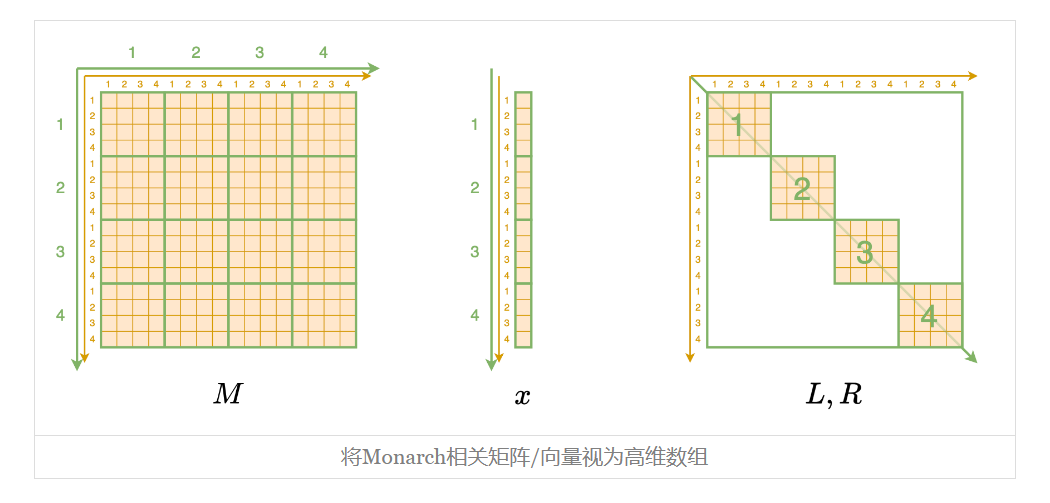
虽然说起来挺费劲的,但事实上代码就一行
M.reshape(m, m, m, m)
同理,x.reshape(m, m)。剩下的
新恒等式
接下来,我们将推出
最后就是
从这个等式可以看出,当我们固定一对
参考实现
笔者简单用Numpy写的参考实现如下:
import numpy as np
def monarch_factorize(A):
M = A.reshape(m, m, m, m).transpose(1, 2, 0, 3)
U, S, V = np.linalg.svd(M)
L = (U[:, :, :, 0] * S[:, :, :1]**0.5).transpose(0, 2, 1)
R = (V[:, :, 0] * S[..., :1]**0.5).transpose(1, 0, 2)
return L, R
def convert_3D_to_2D(LR):
X = np.zeros((m, m, m, m))
for i in range(m):
X[i, i] += LR[i]
return X.transpose(0, 2, 1, 3).reshape(n, n)
m = 8
n = m**2
A = np.where(np.random.rand(n, n) > 0.8, np.random.randn(n, n), 0)
L, R = monarch_factorize(A)
L = convert_3D_to_2D(L)
R = convert_3D_to_2D(R)
PL = L.reshape(m, m, n).transpose(1, 0, 2).reshape(n, n)
PR = R.reshape(m, m, n).transpose(1, 0, 2).reshape(n, n)
U, S, V = np.linalg.svd(A)
print('Monarch error:', np.square(A - PL.dot(PR)).mean())
print('Low-Rank error:', np.square(A - (U[:, :m] * S[:m]).dot(V[:m])).mean())
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
笔者简单对比了一下SVD求出的秩-
Monarch推广
到目前为止,我们约定所讨论的矩阵都是
非平方阶
为此,我们先引入一些记号。假设Px = x.reshape(m, m).transpose().reshape(n),现在我们一般化为Px = x.reshape(n // b, b).transpose().reshape(n),记为
有了这些记号,我们可以定义一般的Monarch矩阵(原论文的附录):
示意图如下:
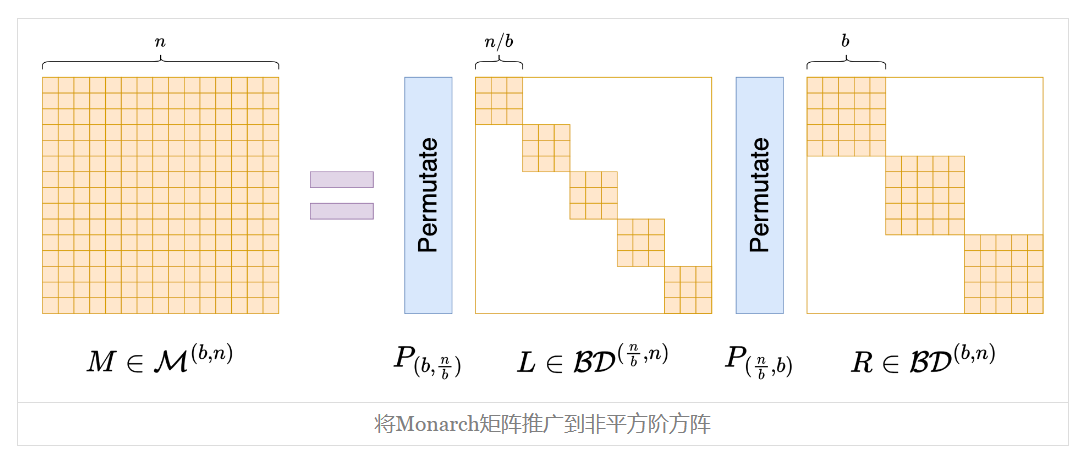
前面所定义的Monarch矩阵,在这里可以简单记为
只要形式
可能读者会困惑,为什么要区分
如果我们不在意这些理论细节,只希望构造一个带有稀疏特性的矩阵参数化方式,那么就可以更灵活地对Monarch矩阵进行推广了,比如
其中
甚至,你可以结合低秩分解的形式,推广到非方阵的块矩阵,如下图:
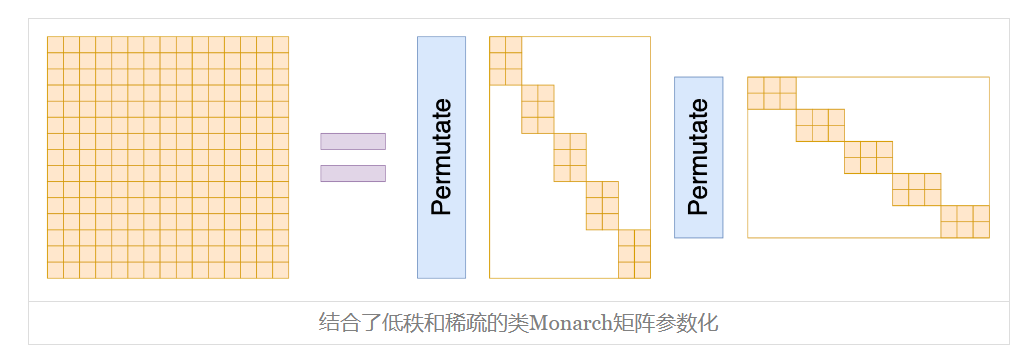
基于这个类比,我们还可以进一步将Monarch矩阵的概念推广到非方阵。总之,如果只是需要一种类似Monarch矩阵的稀疏化结构矩阵,而不在意理论细节,那么结果就仅限于我们的想象力了。
应用例子
目前看来,Monarch矩阵最大的特点就是对矩阵乘法比较友好,所以最大的用途无非就是替换全连接层的参数矩阵,从而提高全连接层的效率,这也是原论文实验部分的主要内容。
我们又可以将其分为“事前处理”和“事后处理”两类:“事前处理”就是在训练模型之前就将全连接层的参数矩阵改为Monarch矩阵,这样训练和推理都能提速,训练出来的模型也最贴合Monarch矩阵;“事后处理”就是已经有一个训练好的模型,此时我们可以用Monarch分解给全连接层的参数矩阵找一个Monarch近似,然后替换掉原来的矩阵,必要时再简单微调一下,以此提高原始模型的微调效率或推理效率。
除了替换全连接层外,《Monarch Mixer: A Simple Sub-Quadratic GEMM-Based Architecture》 (opens new window)还讨论了更极端的做法——作为一个Token-Mixer模块直接替换Attention层。不过就笔者看来,Monarch-Mixer并不算太优雅,因为它跟MLP-Mixer (opens new window)一样,都是用一个可学的矩阵替换掉Attention矩阵,只不过在Monarch-Mixer这里换成了Monarch矩阵。这样的模式学到的是静态的注意力,个人对其普适性是存疑的。
最后,对如今的LLM来说,Monarch矩阵还可以用来构建参数高效的微调方案(Parameter-Efficient Fine-Tuning,PEFT)。我们知道,LoRA是从低秩分解出发设计的,既然低秩和稀疏是两条平行的路线,那么作为稀疏的代表作Monarch矩阵不应该也可以用来构建一种PEFT方案?Google了一下,还真有这样做的,论文名是《MoRe Fine-Tuning with 10x Fewer Parameters》 (opens new window),还很新鲜,是ICML2024的Workshop之一。
蝶之帝王
最后再简单说说Monarch矩阵的拟合能力。“Monarch”意为“帝王”、“君主”,取自“Monarch Butterfly(帝王蝴蝶)”一词,之所以这样命名,是因为它对标的是更早的“utterfly矩阵 (opens new window)”。
什么是Butterfly矩阵?这个说起来还真有点费劲。Butterfly矩阵是一系列(
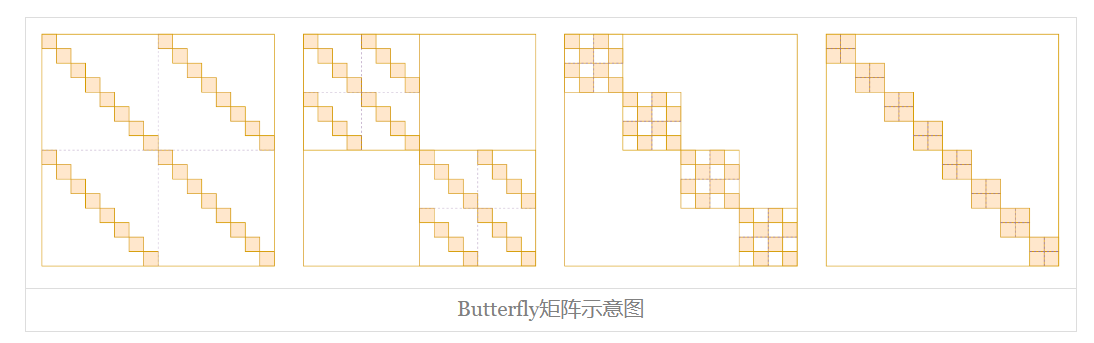
准确的Butterfly矩阵定义大家自行看论文就好,这里不详细展开。Butterfly这个名字来源于作者觉得每个Butterfly因子的形状像Butterfly(蝴蝶),当然像不像大家见仁见智,反正作者觉得像。从字面上来看,“Monarch Butterfly”比“Butterfly”更高级(毕竟是“帝王”),这暗示着Monarch矩阵比Butterfly矩阵更强。确实如此,Monarch论文附录证明了,不管
我们也可以从“矩阵-向量”乘法复杂度来直观感知Monarch矩阵表达能力。我们知道,一个
文章小结
本文介绍了Monarch矩阵,这是Tri Dao前两年提出的一簇能够分解为转置矩阵与稀疏矩阵乘积的矩阵,具备计算高效的特点(众所周知,Tri Dao是高性能的代名词),可以用来为全连接层提速、构建参数高效的微调方式等。