 LSTM
LSTM
其他RNN
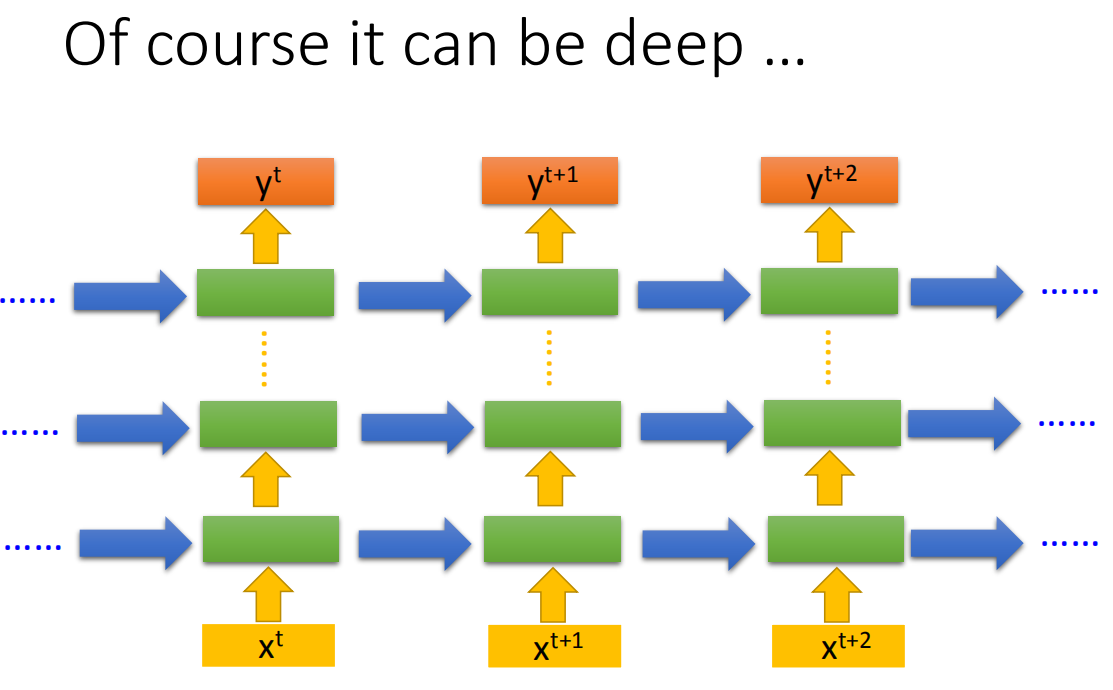
Recurrent Neural Networ的架构是可以任意设计的,比如说,它当然是deep(刚才我们看到的Recurrent Neural Networ它只有一个hidden layer),当然它也可以是deep Recurrent Neural Networ。
比如说,我们把
Elman network &Jordan network
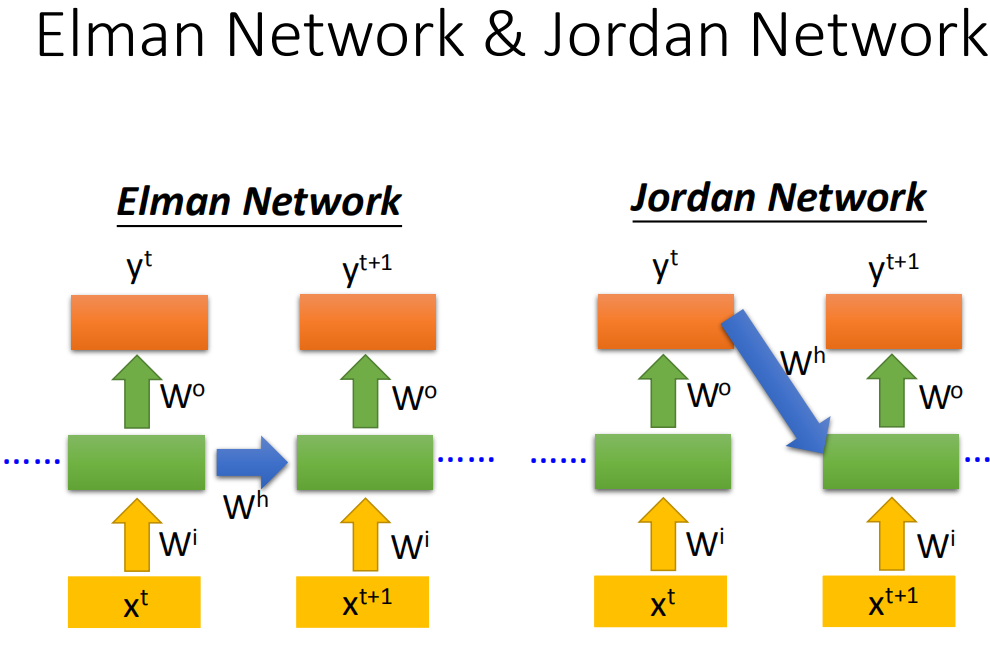
Recurrent Neural Networ会有不同的变形,我们刚才讲的是Elman network。(如果我们今天把hidden layer的值存起来,在下一个时间点在读出来)。还有另外一种叫做Jordan network,Jordan network存的是整个network output的值,它把output值在下一个时间点在读进来(把output存到memory里)。传说Jordan network会得到好的performance。
Elman network是没有target,很难控制说它能学到什么hidden layer information(学到什么放到memory里),但是Jordan network是有target,今天我们比较很清楚我们放在memory里是什么样的东西。
Bidirectional neural network
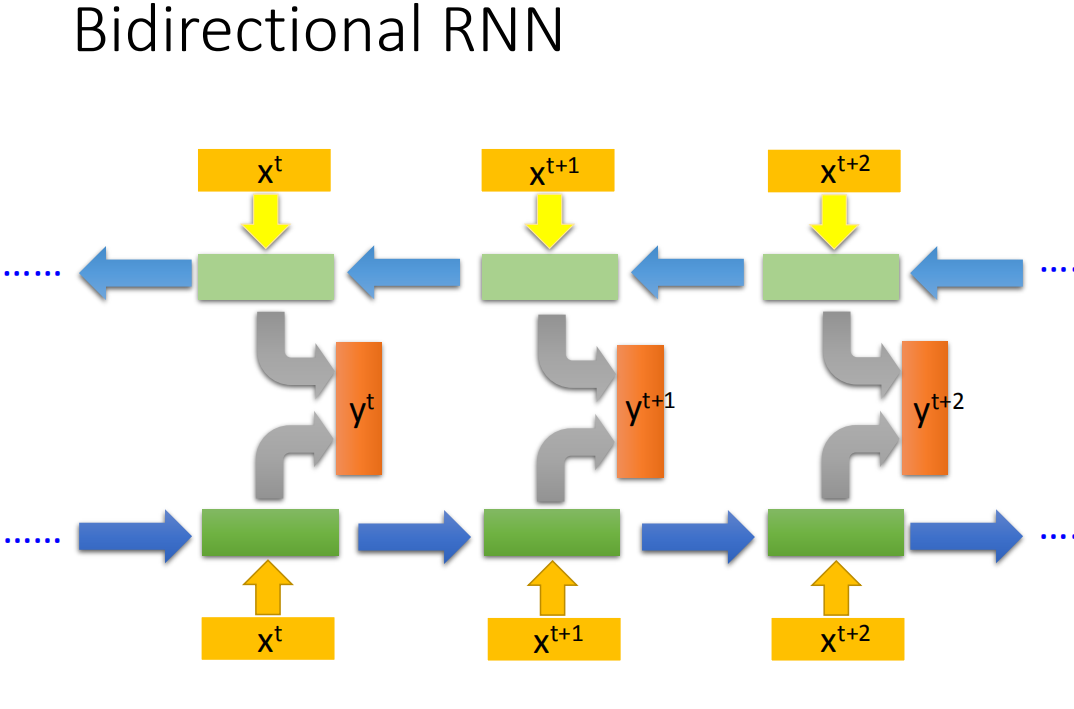
Recurrent Neural Networ还可以是双向,什么意思呢?我们刚才Recurrent Neural Networ你input一个句子的话,它就是从句首一直读到句尾。假设句子里的每一个词汇我们都有
 那我们刚才讲的Recurrent Neural Network其实是Recurrent Neural Network最单的版本
那我们刚才讲的Recurrent Neural Network其实是Recurrent Neural Network最单的版本
LSTM
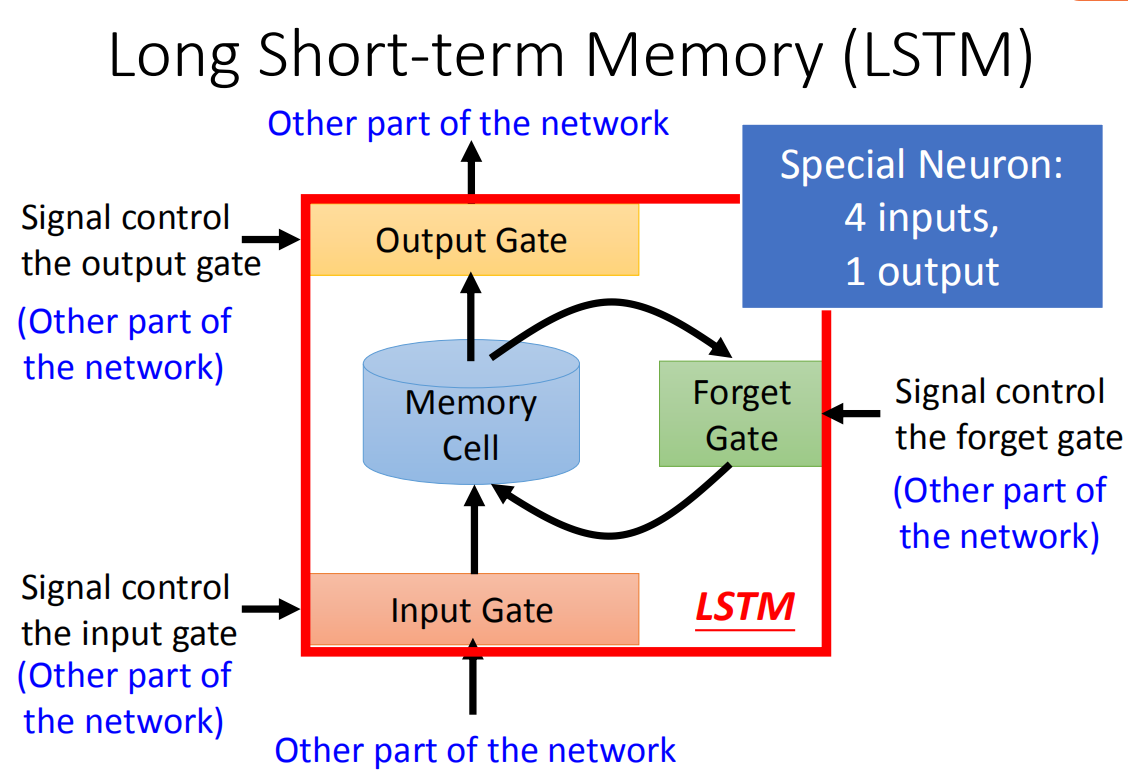
那我们刚才讲的memory是最单纯的,我们可以随时把值存到memory去,也可以把值读出来。但现在最常用的memory称之为Long Short-term Memory(长时间的短期记忆),简写LSTM.这个Long Short-term Memor是比较复杂的。
这个Long Short-term Memor是有三个gate,当外界某个neural的output想要被写到memory cell里面的时候,必须通过一个input Gate,那这个input Gate要被打开的时候,你才能把值写到memory cell里面去,如果把这个关起来的话,就没有办法把值写进去。至于input Gate是打开还是关起来,这个是neural network自己学的(它可以自己学说,它什么时候要把input Gate打开,什么时候要把input Gate关起来)。那么输出的地方也有一个output Gate,这个output Gate会决定说,外界其他的neural可不可以从这个memory里面把值读出来(把output Gate关闭的时候是没有办法把值读出来,output Gate打开的时候,才可以把值读出来)。那跟input Gate一样,output Gate什么时候打开什么时候关闭,network是自己学到的。那第三个gate叫做forget Gate,forget Gate决定说:什么时候memory cell要把过去记得的东西忘掉。这个forget Gate什么时候会把存在memory的值忘掉,什么时候会把存在memory里面的值继续保留下来),这也是network自己学到的。
那整个LSTM你可以看成,它有四个input 1个output,这四个input中,一个是想要被存在memory cell的值(但它不一定存的进去)还有操控input Gate的讯号,操控output Gate的讯号,操控forget Gate的讯号,有着四个input但它只会得到一个output
冷知识:这个“-”应该在short-term中间,是长时间的短期记忆。想想我们之前看的Recurrent Neural Network,它的memory在每一个时间点都会被洗掉,只要有新的input进来,每一个时间点都会把memory 洗掉,所以的short-term是非常short的,但如果是Long Short-term Memory,它记得会比较久一点(只要forget Gate不要决定要忘记,它的值就会被存起来)。
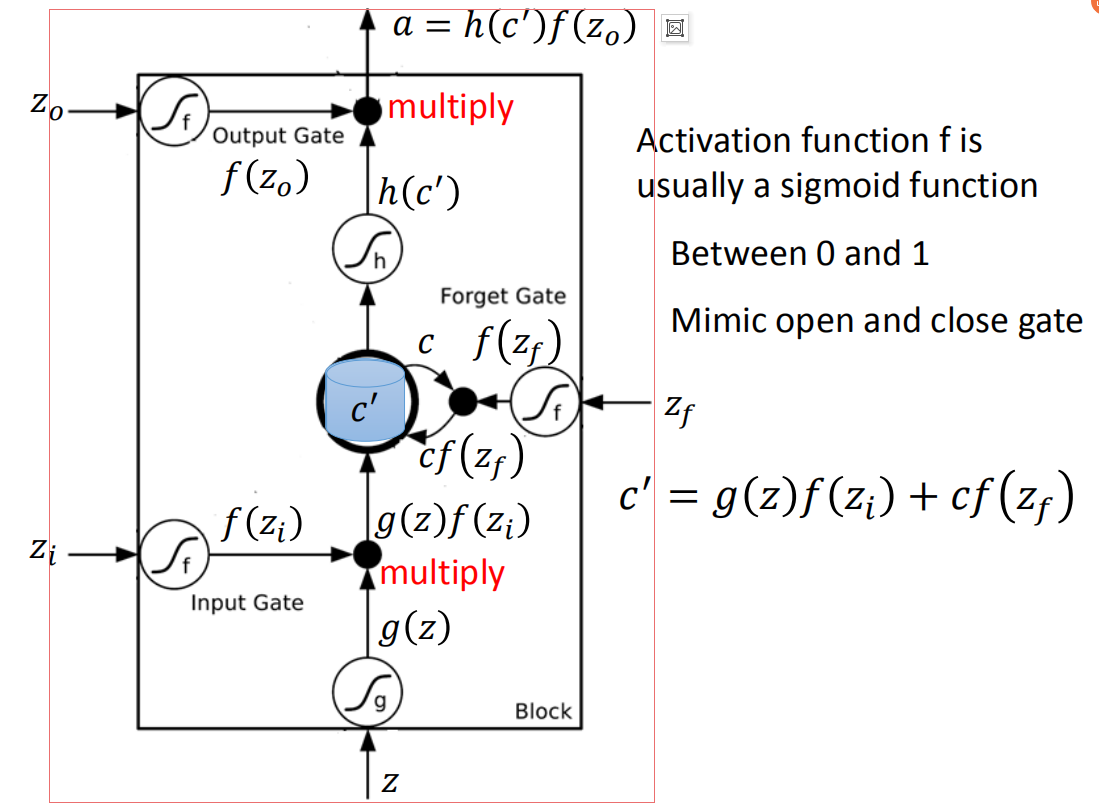 这个memory cell更仔细来看它的formulation,它长的像这样。
这个memory cell更仔细来看它的formulation,它长的像这样。
底下这个是外界传入cell的input,还有input gate,forget gate,output gate。现在我们假设要被存到cell的input叫做z,操控input gate的信号叫做
假设要输入的部分为z,那三个gate分别是由
那接下来,把
接下来把存到memory里面的值c乘以
LSTM举例
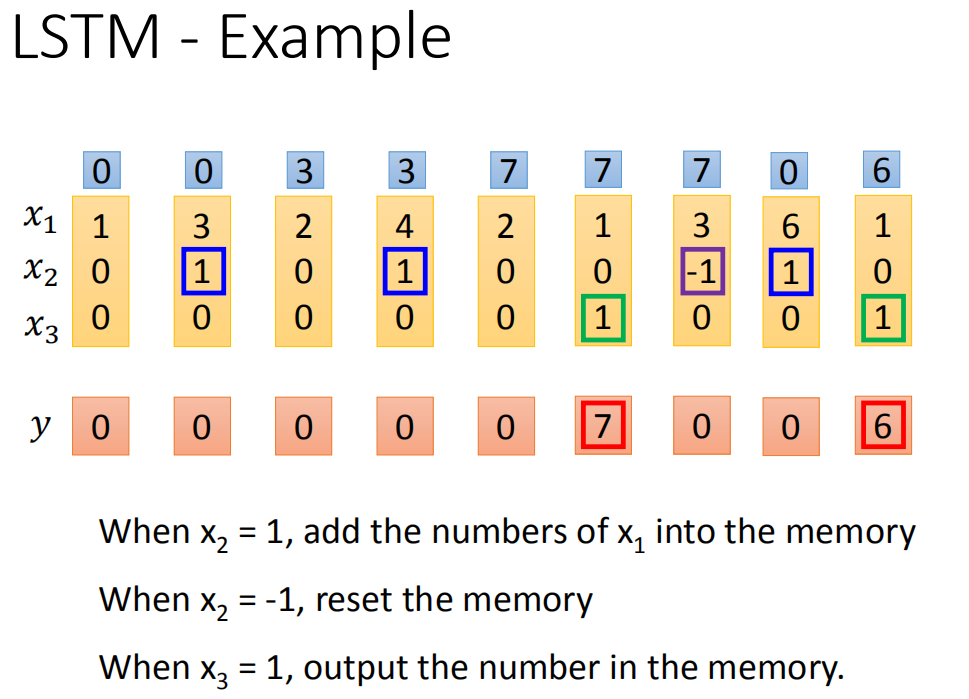 LSTM例子:我们的network里面只有一个LSTM的cell,那我们的input都是三维的vector,output都是一维的output。那这三维的vector跟output还有memory的关系是这样的。假设第二个dimension
LSTM例子:我们的network里面只有一个LSTM的cell,那我们的input都是三维的vector,output都是一维的output。那这三维的vector跟output还有memory的关系是这样的。假设第二个dimension
假设我们原来存到memory里面的值是0,当第二个dimension
LSTM运算举例
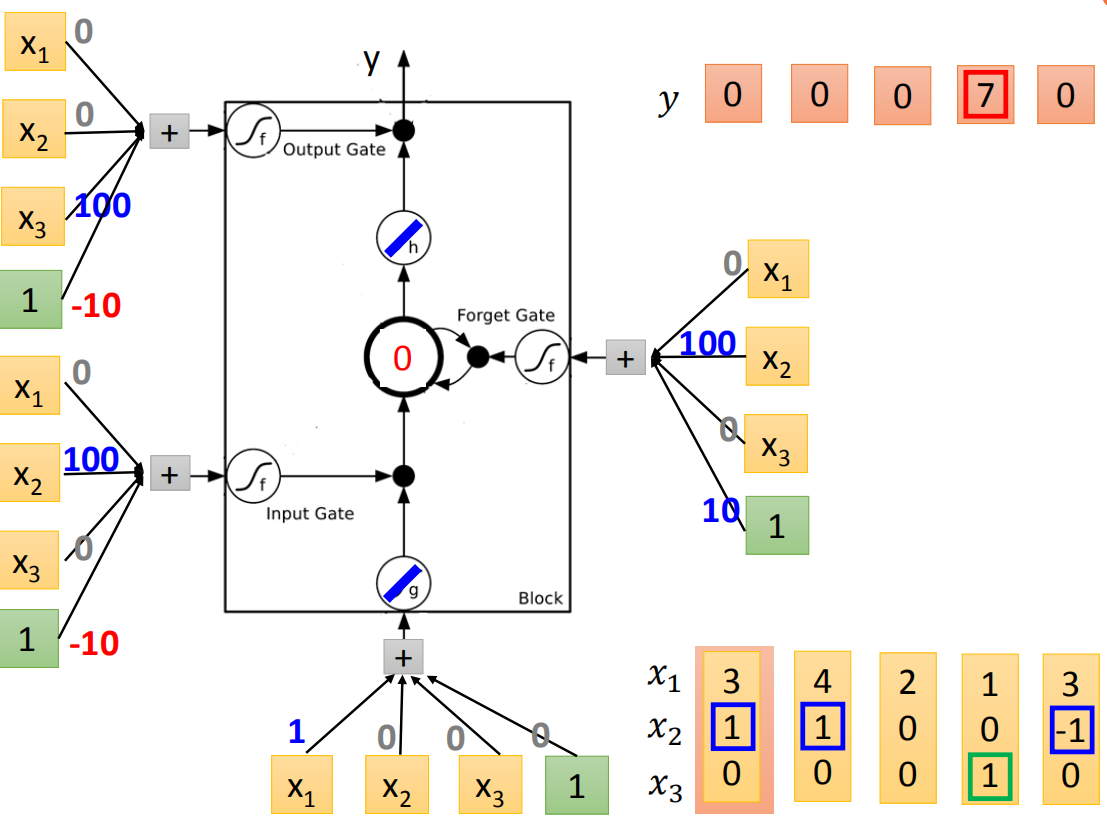 那我们就做一下实际的运算,这个是一个memory cell。这四个input scalar是这样来的:input的三维vector乘以linear transform以后所得到的结果(
那我们就做一下实际的运算,这个是一个memory cell。这四个input scalar是这样来的:input的三维vector乘以linear transform以后所得到的结果(
在实际运算之前,我们先根据它的input,参数分析下可能会得到的结果。底下这个外界传入的cell,
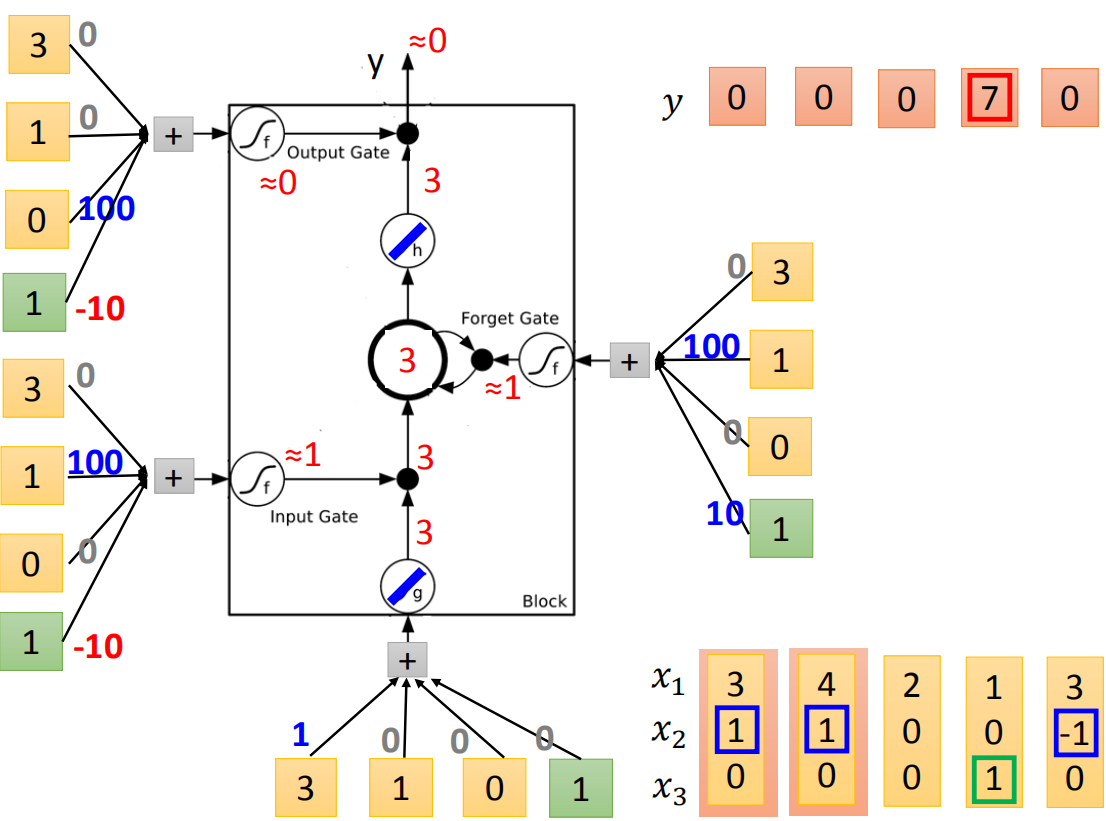 接下来,我们实际的input一下看看。我们假设g和h都是linear(因为这样计算会比较方便)。假设存到memory里面的初始值是0,我们input第一个vector(3,1,0),input这边3*1=3,这边输入的是的值为3。input gate这边(
接下来,我们实际的input一下看看。我们假设g和h都是linear(因为这样计算会比较方便)。假设存到memory里面的初始值是0,我们input第一个vector(3,1,0),input这边3*1=3,这边输入的是的值为3。input gate这边(
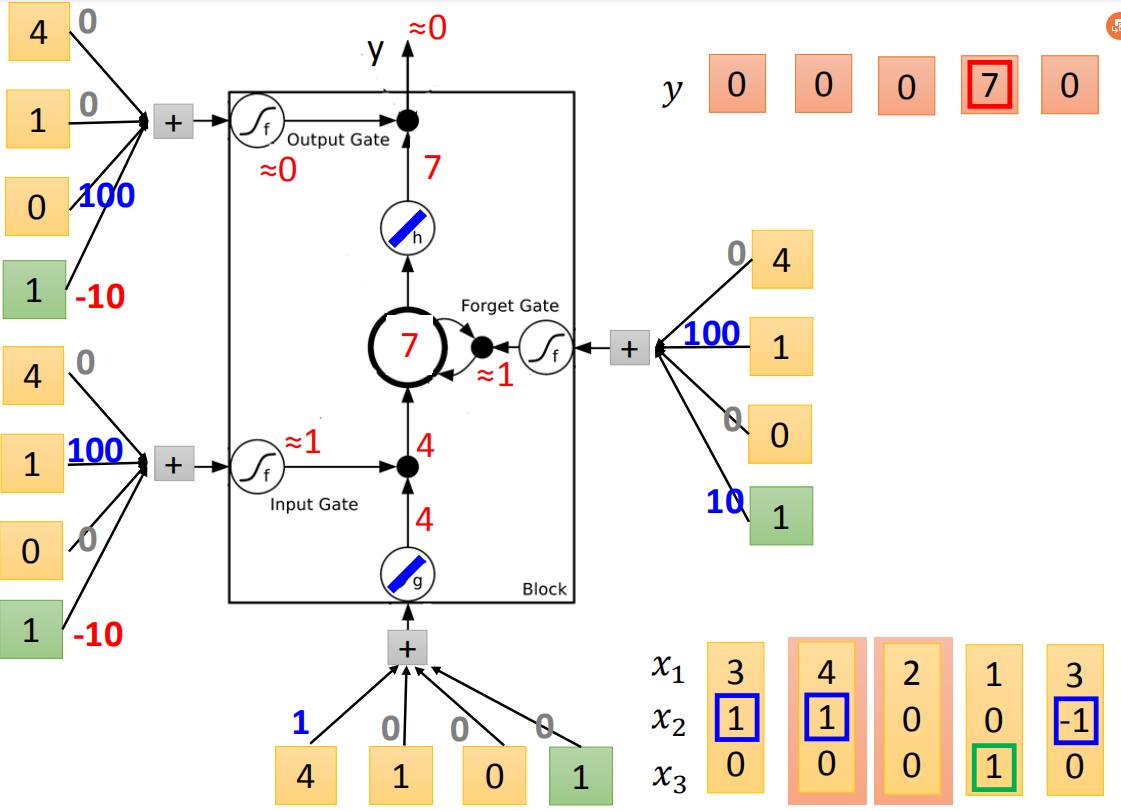 接下来input(4,1,0),传入input的值为4,input gate会被打开,forget gate也会被打开,所以memory里面存的值等于7(3+4=7),output gate仍然会被关闭的,所以7没有办法被输出,所以整个memory的输出为0。
接下来input(4,1,0),传入input的值为4,input gate会被打开,forget gate也会被打开,所以memory里面存的值等于7(3+4=7),output gate仍然会被关闭的,所以7没有办法被输出,所以整个memory的输出为0。
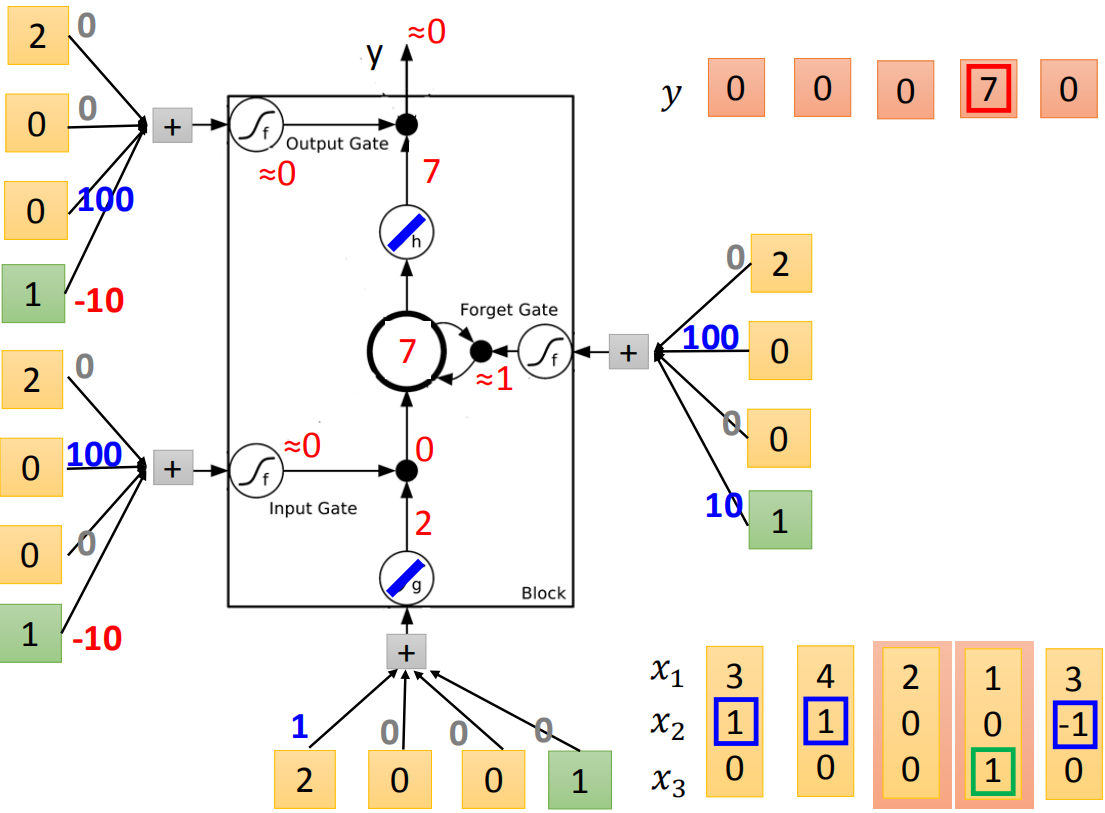
接下来input(2,0,0),传入input的值为2,input gate关闭(
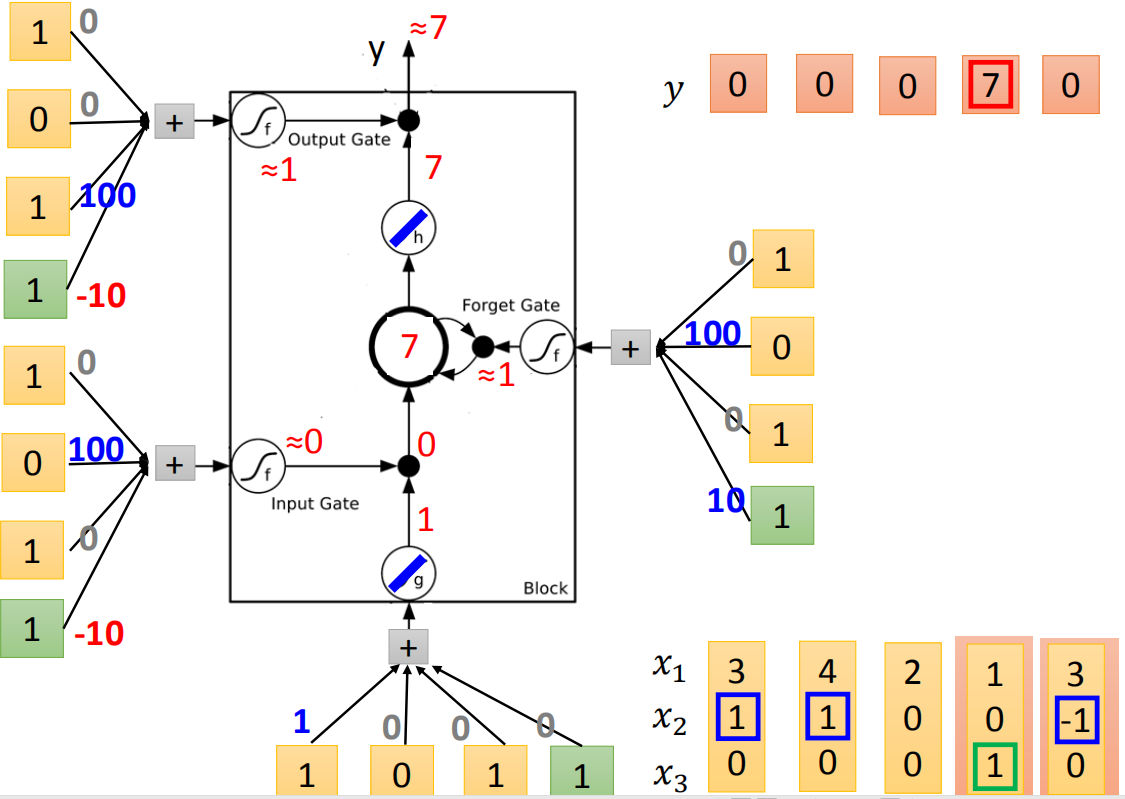 接下来input(1,0,1),传入input的值为1,input gate是关闭的,forget gate是打开的,memory里面存的值不变,output gate被打开,整个output为7(memory里面存的7会被读取出来)
接下来input(1,0,1),传入input的值为1,input gate是关闭的,forget gate是打开的,memory里面存的值不变,output gate被打开,整个output为7(memory里面存的7会被读取出来)
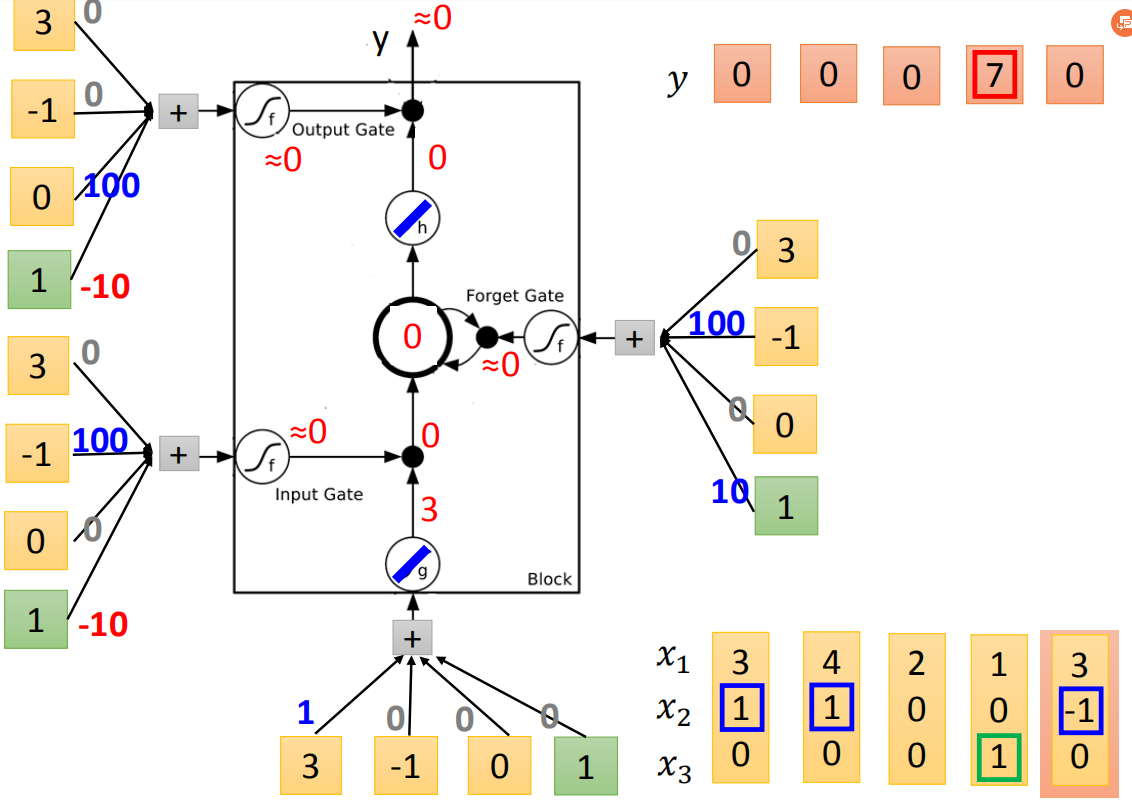 最后input(3,-1,0),传入input的值为3,input gate 关闭,forget gate关闭,memory里面的值会被洗掉变为0,output gate关闭,所以整个output为0。
最后input(3,-1,0),传入input的值为3,input gate 关闭,forget gate关闭,memory里面的值会被洗掉变为0,output gate关闭,所以整个output为0。
LSTM原理
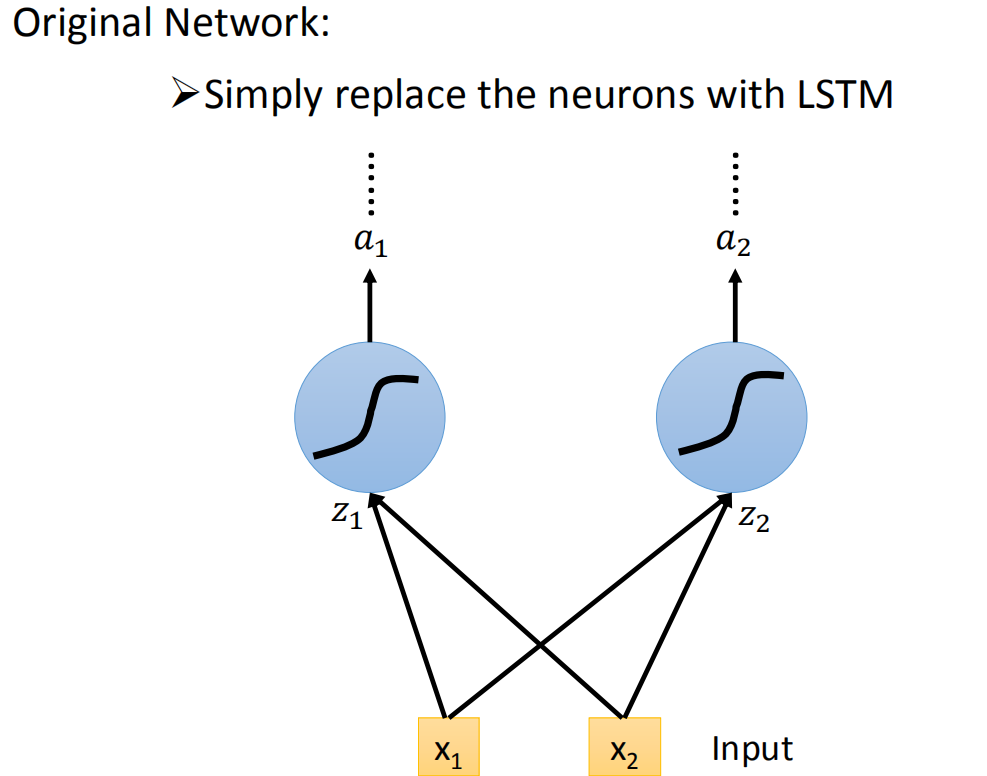 你可能会想这个跟我们的neural network有什么样的关系呢。你可以这样想,在我们原来的neural network里面,我们会有很多的neural,我们会把input乘以不同的weight当做不同neural的输入,每一个neural都是一个function,输入一个值然后输出一个值。但是如果是LSTM的话,其实你只要把LSTM那么memory的cell想成是一个neuron就好了。
你可能会想这个跟我们的neural network有什么样的关系呢。你可以这样想,在我们原来的neural network里面,我们会有很多的neural,我们会把input乘以不同的weight当做不同neural的输入,每一个neural都是一个function,输入一个值然后输出一个值。但是如果是LSTM的话,其实你只要把LSTM那么memory的cell想成是一个neuron就好了。
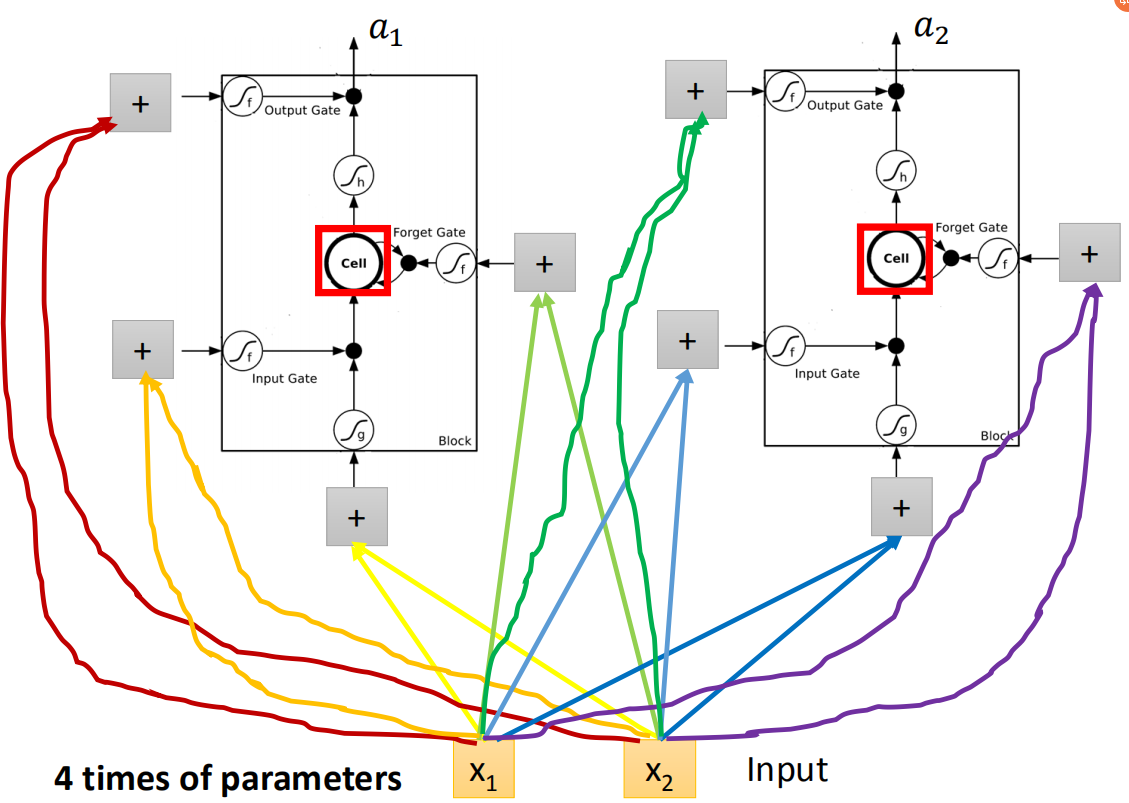
所以我们今天要用一个LSTM的neuron,你做的事情其实就是原来简单的neuron换成LSTM。现在的input(
LSTM因为需要四个input,而且四个input都是不一样,原来的一个neuron就只有一个input和output,所以LSTM需要的参数量(假设你现在用的neural的数目跟LSTM是一样的)是一般neural network的四倍。这个跟Recurrent Neural Network 的关系是什么,这个看起来好像不一样,所以我们要画另外一张图来表示。
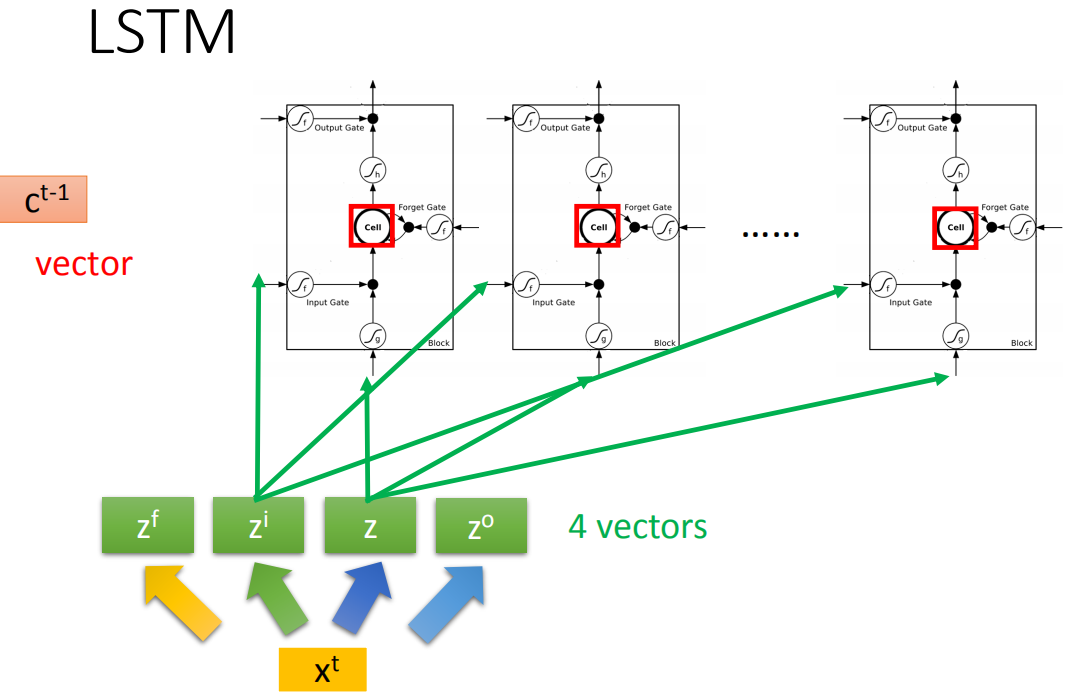
假设我们现在有一整排的neuron(LSTM),这些LSTM里面的memory都存了一个值,把所有的值接起来就变成了vector,写为
这个
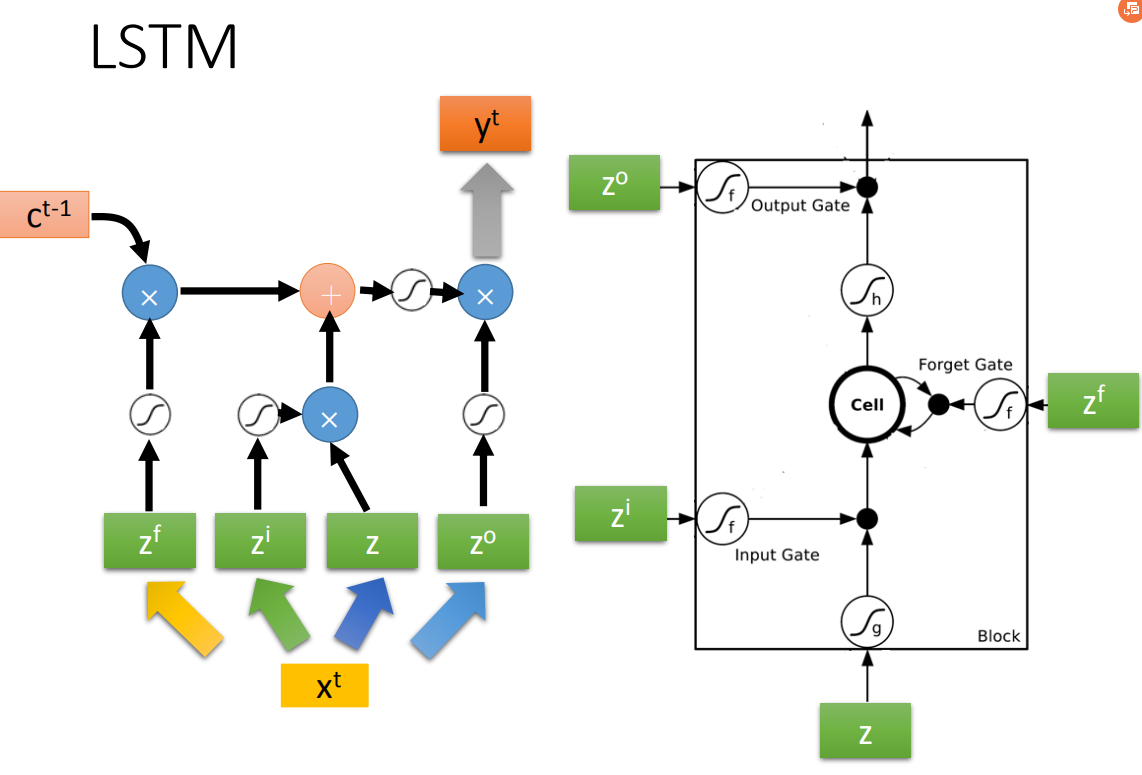 一个memory cell就长这样,现在input分别就是
一个memory cell就长这样,现在input分别就是
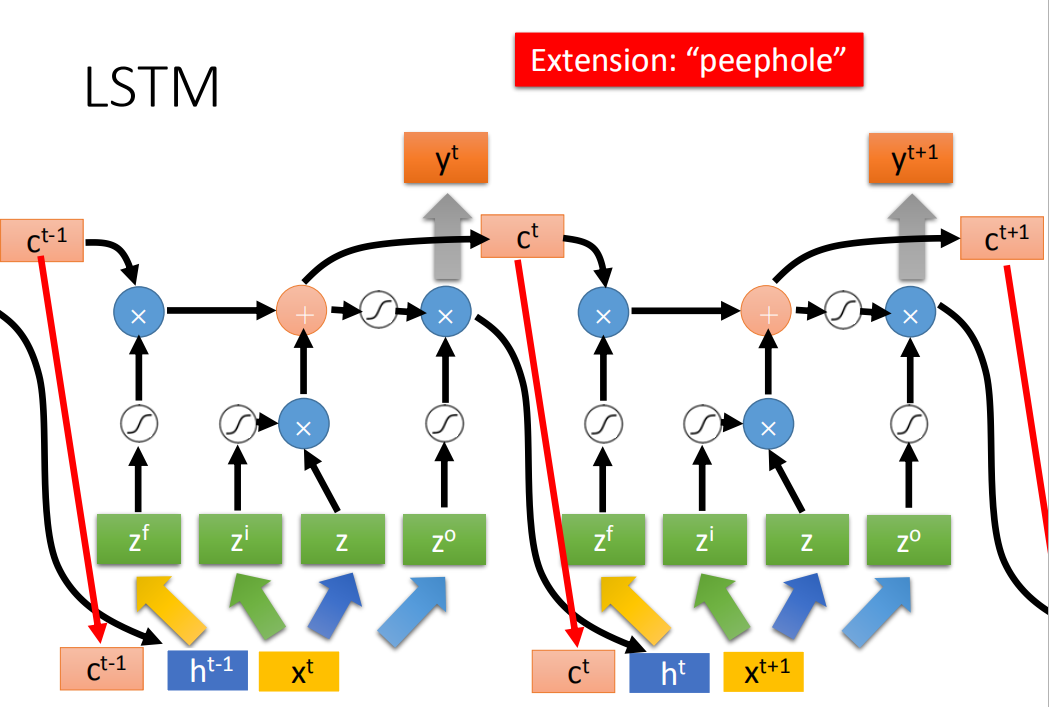 之前那个相加以后的结果就是memory里面存放的值
之前那个相加以后的结果就是memory里面存放的值
你可能认为说这很复杂了,但是这不是LSTM的最终形态,真正的LSTM,会把上一个时间的输出接进来,当做下一个时间的input,也就说下一个时间点操控这些gate的值不是只看那个时间点的input
 LSTM通常不会只有一层,若有五六层的话。大概是这个样子。每一个第一次看这个的人,反映都会很难受。现在还是 quite standard now,当有一个人说我用RNN做了什么,你不要去问他为什么不用LSTM,因为他其实就是用了LSTM。现在当你说,你在做RNN的时候,其实你指的就用LSTM。Keras支持三种RNN:‘’LSTM‘’,“GRU”,"SimpleRNN"
LSTM通常不会只有一层,若有五六层的话。大概是这个样子。每一个第一次看这个的人,反映都会很难受。现在还是 quite standard now,当有一个人说我用RNN做了什么,你不要去问他为什么不用LSTM,因为他其实就是用了LSTM。现在当你说,你在做RNN的时候,其实你指的就用LSTM。Keras支持三种RNN:‘’LSTM‘’,“GRU”,"SimpleRNN"
GRU
GRU是LSTM稍微简化的版本,它只有两个gate,虽然少了一个gate,但是performance跟LSTM差不多(少了1/3的参数,也是比较不容易overfitting)。如果你要用这堂课最开始讲的那种RNN,你要说是simple RNN才行。
GRU是LSTM稍微简化的版本,它只有两个gate,虽然少了一个gate,但是performance跟LSTM差不多(少了1/3的参数,也是比较不容易overfitting)。如果你要用这堂课最开始讲的那种RNN,你要说是simple RNN才行。