 MoE 知识蒸馏
MoE 知识蒸馏
One Student Knows All Experts Know: From Sparse to Dense
One Student Knows All Experts Know: From Sparse to Dense (opens new window)
太长不看版
人类教育系统由多个 Expert 来训练一位 Student。专家混合 (Mixture-of-experts, MoE) 是一种强大的稀疏架构,包括多个 Expert 模型。但是,MoE 的架构容易过拟合,难以部署,对业界其实并不友好。
这个工作受到人类教育的启发,作者提出了一种新的任务**:知识整合** (Knowledge Integration),本文的方法分为2步**:知识聚合 (Knowledge Gathering) 和知识蒸馏 (Knowledge Distillation)**。使用稀疏的教师模型来蒸馏密集的学生模型。学生是一个密集的模型,从不同 Expert 那里获取知识。
为了从不同的预训练 Expert 那里有效地收集知识,本文研究了4种不同的可能的知识收集方法,即 Summation, Averaging, Top-K Knowledge Gathering (Top-KG), 和 Singular Value Decomposition Knowledge Gathering (SVD-KG)。然后再通过知识蒸馏精炼密集的学生模型。
1 背景:稀疏 MoE 模型虽强大却难以部署
回顾一个研究员,一路走来的学习历程,大多数人都是从多个教师 (即 Expert 那里) 学习到不同的知识。受人类教育的启发,这项工作侧重于通过一组 Expert 的知识来训练一个强大的学生模型。
在 MoE 中,每个 Expert 都是整个模型中的一个子神经网络。对于输入的每个子集,只有一个特定的子网络被激活,MoE 的这种稀疏计算的方式使我们能够将模型扩展到万亿参数的规模。
但是,MoE 方法也有问题,比如很容易过拟合。使用 MoE 模型时,我们通常在大型数据集上预训练 MoE,然后在各种下游任务上去做微调。在大多数情况下,这些下游任务才是我们想要解决的目标问题。MoE 的应用存在下面3大问题:
第一,容易过拟合。与 Dense 的模型相比,稀疏模型更多的可训练参数和稀疏的条件计算会引入过拟合,尤其是当数据集的规模不够大的时候。
第二,比较难部署。即使我们成功地训练了一个 MoE 模型,它其实也是很难部署的。对于参数量达到数万亿规模的 MoE 模型,我们就需要在不同设备 (GPU, TPU) 上面部署不同的专家来减小设备上的内存消耗。
第三,MoE 模型硬件不友好,专家并行性代价高昂。对于 GPU 集群,all-to-all 操作太慢,无法扩大 MoE 模型。而且,门控函数包括许多创建 token mask 的操作,选择 top-k Expert 并寻找每个 Expert 的输入 token 的 id。由于 tensor 的稀疏表示,所有这些操作都很浪费。
总之,稀疏 MoE 虽然强大,但是在实践中相对难以使用。密集的模型能力稍差,但是却容易使用,因此,本文希望结合稀疏模型的能力来训练高效又易于使用的密集模型。
2 MoE 基本介绍
MoE 的基本概念和定义
给定一个具有
式中,
式中,
MoE 的常见目标函数
在训练 MoE 模型时,如果我们不加任何的正则化策略,大多数 token 可能会派到一小部分 Expert 里面,其他的 Expert 只会收到很少很少的 token,这种极不平衡的分配会导致 MoE 模型的效率很低且精度较差。因此,为了实现不同 Expert 的平衡工作负载,通常使用辅助的平衡损失函数:
式中,
其中,
当我们试图优化辅助平衡损失函数时,其实是希望
3 知识整合的问题定义
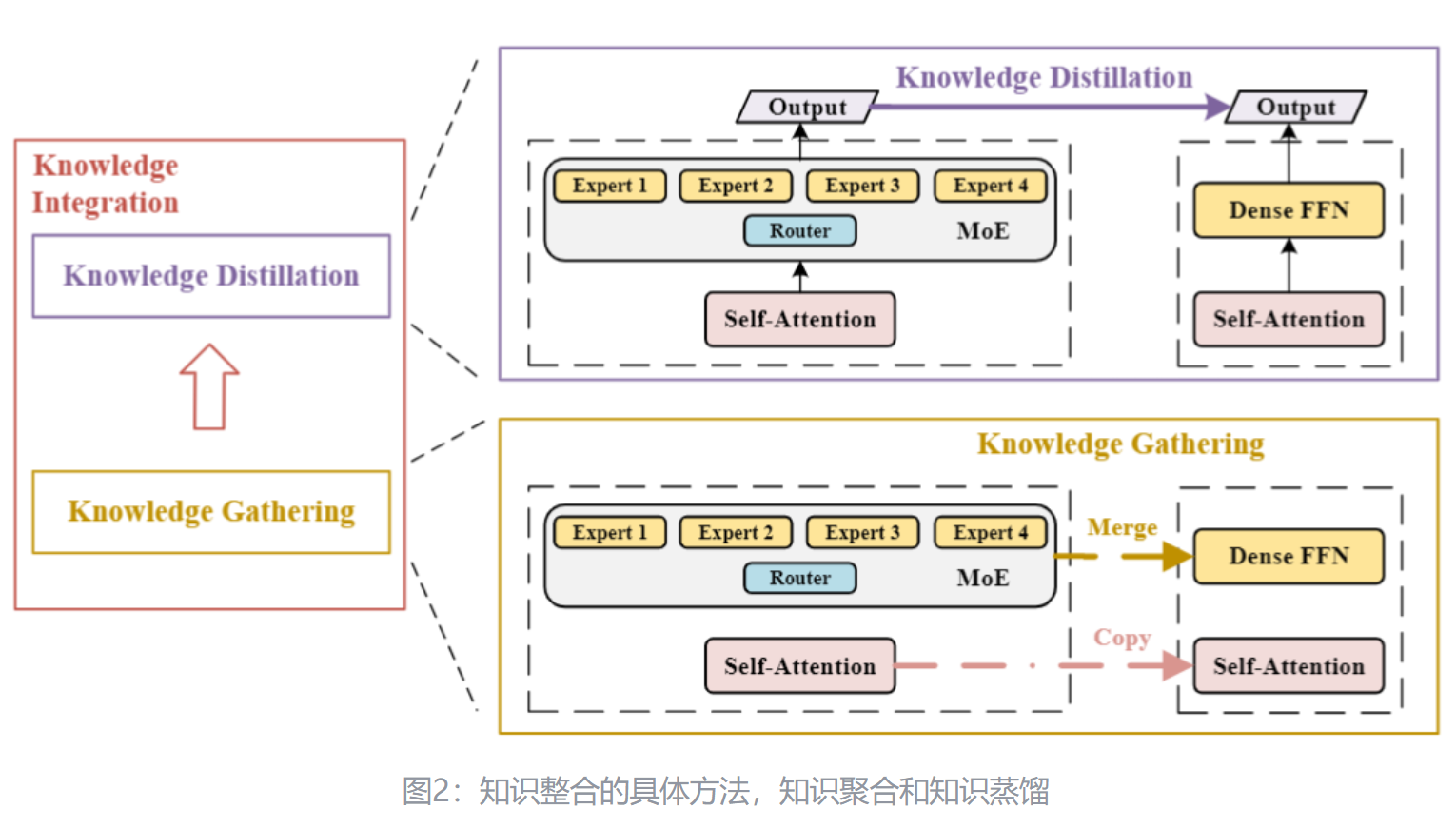
本文的方法知识整合可以分为2步**:知识聚合** (Knowledge Gathering) 和知识蒸馏 (Knowledge Distillation)
对于第1步,给定
式中,
然后目标就是根据
第2个阶段是对密集的学生模型进行微调,以最小化教师输出和学生输出之间的差异。
本文的目标是尽可能地保留 MoE 给密集学生模型带来的帮助。因此,本文搞了个指标来衡量密集的学生模型整合 MoE 对应的知识的能力:
其中,
4 第一阶段:知识整合
如下图2所示是知识整合的具体方法,整体的思路就是2步:知识聚合 (Knowledge Gathering) 和知识蒸馏 (Knowledge Distillation)。
在初始化学生模型的时候,大部分的参数其实是和教师模型重合的,比如 Embedding 层,Attention 层,归一化层。所以对于这些层的参数,学生模型可以直接复制教师模型的。问题的关键在于 MoE 层,MoE 层比单个 FFN 层具有更多的可学习参数,每个 Expert 都是一个有独立参数的 FFN。知识聚合的目的就是合并来自不同 FFN Expert 的知识,并将知识分配给学生模型中的单个 FFN。作者研究了4种不同的知识聚合方法,即:Summation, Averaging, Top-K Knowledge Gathering (Top-KG), 和 Singular Value Decomposition Knowledge Gathering (SVD-KG)。
假设
简单来讲就是把
偏置
采用这种简单的策略是因为可训练参数较少,存储在 bias 中的知识远小于 weight 中的知识。
权重
累加 (Summation):
取均值 (Averaging):
Top-K Knowledge Gathering:
对于第
SVD Knowledge Gathering
矩阵的低秩分解用于把一个非低秩矩阵转化成低秩矩阵,这样的低秩矩阵可以近似整个矩阵的知识,可以通过从多个低秩矩阵重构高阶矩阵。作者在本文中使用 SVD 来提取关键知识并将它们合并:
式中,
然后按照下式得到低秩分解之后的
式中,
5 第二阶段:知识蒸馏
作者进一步对学生模型进行蒸馏,蒸馏损失可以写成:
式中,
最后的损失函数可以写成:
式中,
6 视觉任务实验结果
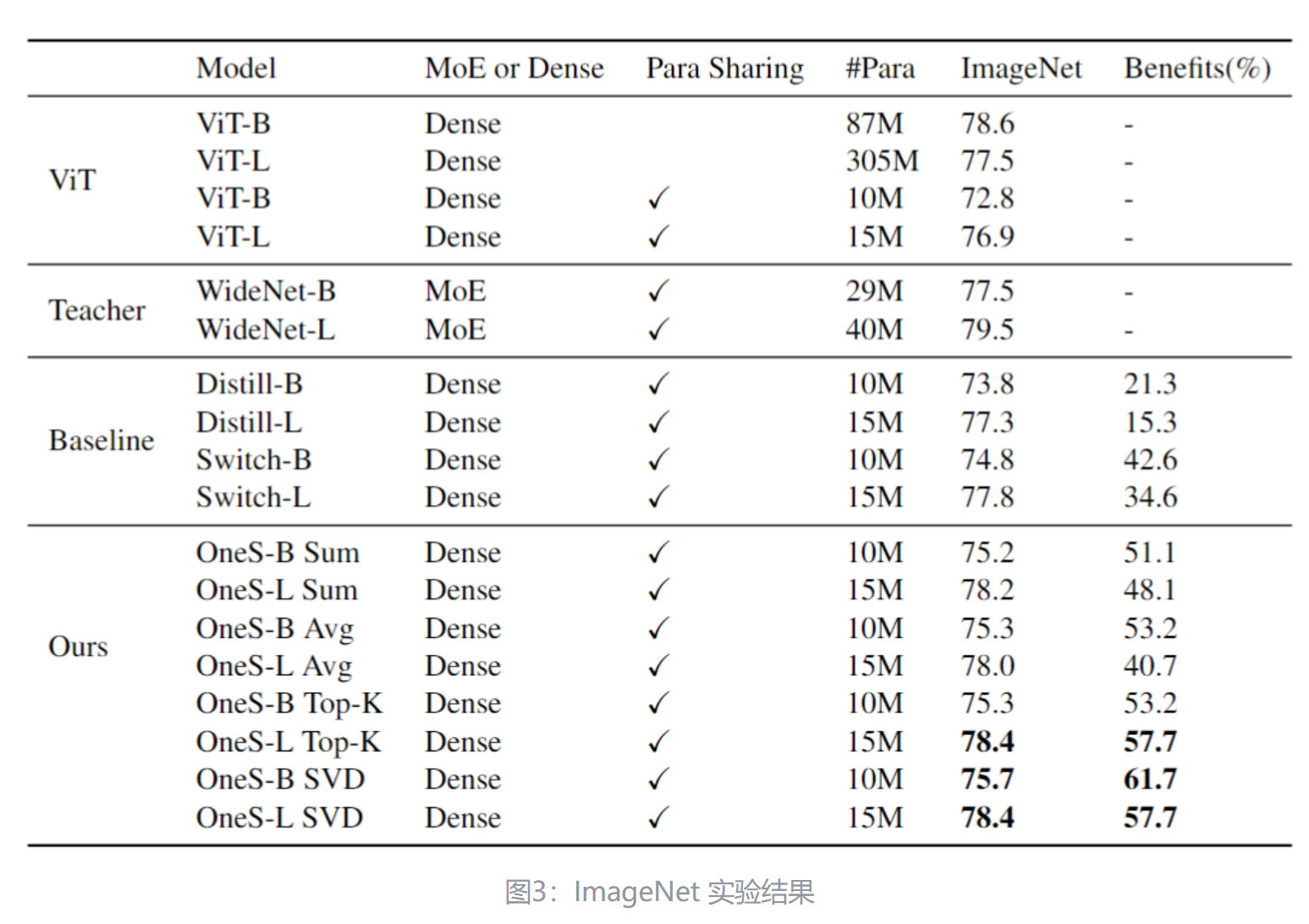
如下图3所示是 ImageNet 图像识别任务的实验结果。预训练的数据集使用的是 ImageNet-1K,基线模型选择 WideNet。Benefits 是8式所定义的那样,表示在知识集成之后,Dense 模型保留了多少改进。根据图3可以发现,SVD Knowledge Gathering 的方法的性能最好,因此在接下来的实验中,作者将基于 SVD 的方法设置为默认选择。可以观察到 OneS-L-SVD 在 ImageNet 上实现了 78.4% 的 top-1 准确率,只有 15M 参数。与最强的 Switch-L 相比,本文的模型提高了 0.6%。OneS-L-SVD 实现了与 ViT-B 相当的性能,只有 17% 的可训练参数。这些结果显示了知识整合的有效性。
7 文本任务实验结果
如下图4所示是 NLU 任务实验结果。预训练的数据集使用的是 English Wikipedia 和 BOOKCORPUS,微调时候的评估基准是 General Language Understanding Evaluation (GLUE),以及两个不同的 Stanford Question Answering (SQuAD) 数据集。基线模型选择 ALBERT。
实验结果如下图4所示,可以看到 OneS 方法在所有任务上都优于基线方法 (即 Distill 和 Switch)。在四个任务上,OneS 平均超过 Switch 0.42。在 SQuAD1.1 和 SST-2 等少数任务中,OneS 甚至可以胜过教师 MoE 模型 WideNet。MoE 模型倾向于在小数据集上过拟合。OneS 具有 MoE 的知识,但是结构依然是密集的,因此预训练的优势可以更容易地迁移到下游任务中。
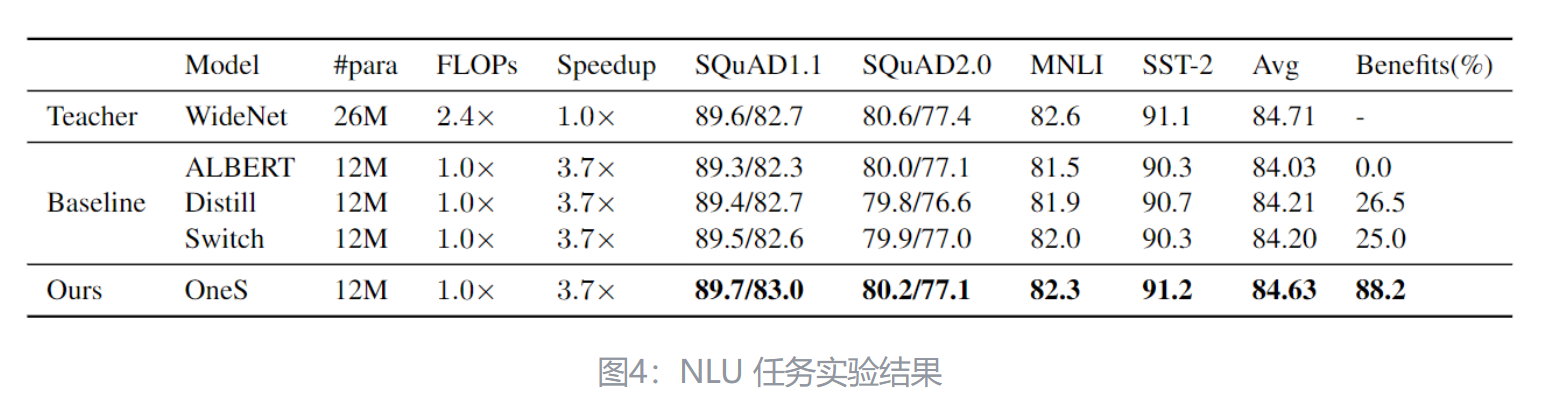
与 MoE 模型相比,OneS 的另一个优点是推理速度。MoE 模型之所以慢的原因是:条件计算带来的门控函数,稀疏 einsum 算子,以上缺点会降低计算的效率。但是,OneS 模型可以实现 3.7 倍的推理速度。OneS 模型高效率的另一个重要原因是密集模型比稀疏 MoE 模型更硬件友好。
8 消融实验结果
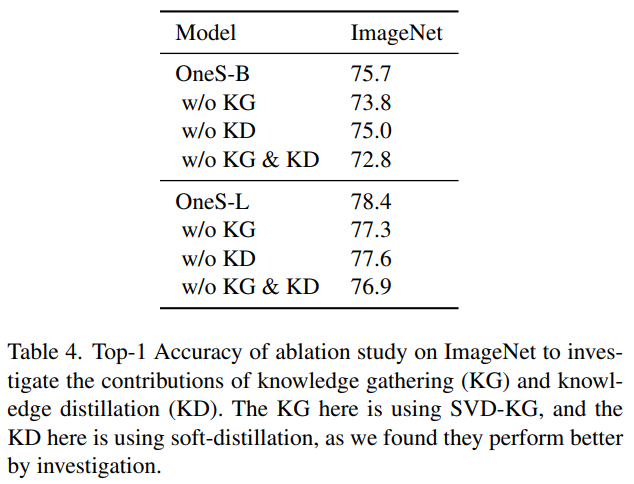
为了进一步验证本文提出的知识聚合和知识蒸馏的有效性,本文进行了如下图所示的消融实验。可以看到,在没有知识聚合的情况下,性能会显著地下降,这表明预训练的稀疏模型中包含的知识对于提高学生模型的性能至关重要。在没有知识蒸馏的情况下,性能会略微下降,说明知识蒸馏有一定帮助,教师可以帮助学生挖掘收集到的知识。对于大模型,去除知识收集和知识蒸馏也会损害性能。
References
Kimi全文翻译 ⬇️
0. 摘要
人类教育系统通过多位专家训练一名学生。专家混合(MoE)是一种强大的稀疏架构,包括多个专家。然而,稀疏 MoE 模型容易过拟合,难以部署,对实践者来说不友好。在这项工作中,受人类教育模型的启发,我们提出了一个新任务,即知识整合,以获得一个与一个稀疏 MoE 一样知识渊博的密集学生模型(OneS)。我们通过提出一个包括知识收集和知识蒸馏的一般训练框架来研究这项任务。具体来说,为了从不同的预训练专家中收集关键知识,我们首先研究了四种不同可能的知识收集方法,即求和、平均、Top-K 知识收集(Top-KG)和本文提出的奇异值分解知识收集(SVD-KG)。然后,我们通过知识蒸馏来提炼密集学生模型,以抵消收集中的噪声。在 ImageNet 上,我们的 OneS 保留了 61.7% 的 MoE 好处,并以仅有 1500 万参数实现了 78.4% 的 top-1 准确率 ImageNet。在四个自然语言处理数据集上,OneS 获得了 88.2% 的 MoE 好处,并在使用相同架构和训练数据的情况下,以 51.7% 的优势超越了最佳基线。此外,与 MoE 对应物相比,由于计算更少和硬件友好的架构,OneS 可以实现 3.7 倍的推理加速。
1. 引言
回顾我们如何成为研究员,大多数人从多位老师(即专家)那里学习。教育领域的现有工作 [2] 也表明,来自不同学科的专家可以帮助学生深入理解和培养更多的人才。整合专家知识的学生可以快速变得和这些专家一样知识渊博。受这种人类教育模型的启发,这项工作专注于通过收集一组专家的知识来训练一个强大的深度学习模型。深度学习的最新研究提出了专家混合(MoE),这是一个具有多个专家的深度神经网络。
每个专家都是整个模型中的一个子神经网络。MoE 的关键思想是分而治之。MoE 鼓励每个专家从输入的特定子集中学习。对于输入的每个子集,只有一个子网络被激活。这种 MoE 的稀疏计算使我们能够将模型扩展到数万亿参数,同时保持可比的计算成本 [8]。由于其大而稀疏激活的模型容量,MoE 模型功能强大,并取得了有希望的结果。然而,MoE 容易过拟合。我们通常在大型数据集上预训练 MoE,然后对其进行各种下游任务的微调。在大多数情况下,这些下游任务是我们想要解决的目标问题。与密集模型相比,更多的可训练参数和稀疏条件计算在微调期间引入了过拟合 [14, 27],特别是当数据集规模不够大时。此外,即使我们成功训练了 MoE 模型,也很难部署。对于数万亿参数的 MoE,我们需要在不同的设备上部署不同的专家以减少设备上的内存消耗(例如 GPU、TPU)。第三,MoE 模型对硬件不友好。专家并行性在通信上成本高昂。对于 GPU 集群,全对全操作扩展 MoE 模型的速度太慢。此外,门控函数包括许多操作,以创建令牌掩码、选择 top-k 专家,并执行累积和以找到每个令牌的 token-id,然后进行稀疏矩阵乘法 [16]。所有这些操作由于稀疏张量表示而浪费,并且由于许多内核调用而极其缓慢。总之,稀疏 MoE 模型功能强大,但在实践中相对难以使用。密集模型被广泛使用,但与具有可比计算成本的稀疏模型相比较弱。那么,是否可能结合稀疏和密集模型的优势来训练一个既有效又易于使用的模型呢?在这项工作中,受人类教育模型的启发,我们提出了一个新的任务,即知识整合。作为一个通用的训练框架,知识整合包括两个步骤,即知识收集和知识蒸馏。在知识收集中,我们将 MoE 中的每个专家视为人类教育中的专家。学生是一个密集模型,我们需要从所有专家那里收集知识并将其分配给学生。为了从专家那里收集知识,作为第一项专注于此任务的工作,我们研究了四种不同的可能解决方案,即求和、平均、Top-KG 和本文提出的 SVD-KG。对于 Top-KG 和 SVD-KG,我们使用 Top-K 选择或 SVD 从预训练的 MoE 的不同专家中提取关键知识,然后,我们初始化前馈网络(FFN)层以近似 MoE。为了进一步提炼模型,我们使用知识蒸馏 [9] 来微调学生。请注意,在知识蒸馏阶段,我们使用整个 MoE 模型来教导学生密集模型。最终的学生模型与标准密集模型的架构相同,但它将涵盖 MoE 的许多专家和更多的可训练参数。上述框架与人类教育模型非常匹配,一名学生整合了多位专家的知识,以便学生可以快速学习。我们的贡献总结如下:
- 我们提出了一个新的任务,即知识整合。目标是结合稀疏 MoE 模型的有效性和密集模型的可用性。据我们所知,这是第一项专注于从预训练的 MoE 模型中学习密集模型的工作。
- 我们提出了分两步解决知识整合的方法,即知识收集和知识蒸馏。为了收集,我们首先研究了四种不同可能的知识收集方法,即求和、平均、Top-KG 和本文提出的 SVD-KG。Top-KG 和 SVD-KG 是提取和合并预训练 MoE 专家的关键知识的新方法。
- 我们在不同领域评估了我们的通用训练框架,即计算机视觉和自然语言处理。在 ImageNet 上,与基线相比,我们的 OneS 保留了 23.1% 的 MoE 好处。在自然语言处理基准测试中,我们仅使用 46% 的参数就实现了 88.2% 的 MoE 好处,并在使用几乎相同的架构和训练数据的情况下超越了基线(例如 Distill、Switch)。此外,由于硬件友好的模型架构,OneS 可以实现比 MoE 对应物快 3.7 倍的推理加速。
2. 预备知识
2.1. 专家混合
专家混合是一个典型的条件计算模型。在这项工作中,我们使用一个预训练的 MoE 模型作为教师,一个密集模型作为学生来模仿人类教育模型。因此,我们首先简要回顾 MoE。
给定一个具有
其中
其中
其中
其中
其中
2.2. 问题公式化
我们提出的工作有两个阶段:(1)从 MoE 中收集知识;(2)知识蒸馏以进一步提炼新的密集模型(即学生)。对于第一阶段,给定
其中
其中
其中分数可以是评估模型的任何指标。例如,对于图像分类,分数是准确率。这里的
3. 方法
3.1. 从 MoE 中收集知识
我们首先制定我们的 KG 任务。给定一个具有
其中
我们采用这种简单的策略,因为存储在偏置中的知识远少于权重中的知识,因为可训练的参数更少。我们通过实验在附录 E 中验证了这一假设。在复制完美匹配层的权重和平均 MoE 层的偏置之后,我们通过稀疏 MoE 初始化密集学生模型的权重。作为第一项专注于此任务的工作,我们研究了四种方法来收集知识,即求和、平均、Top-KG 和 SVD-KG。前两种是最直接的方法。我们还提出了两种新方法,Top-KG 和 SVD-KG,从预训练的 MoE 的不同专家中提取关键知识。
3.1.1 求和与平均
对于 MoE 中的权重,我们首先考虑两种简单的方法。第一种是求和:
第二个是平均:
尽管这两种收集方法很简单,作为第一项专注于此任务的工作,我们研究它们为从 MoE 模型中收集知识铺平了道路。
3.2. Top-K 知识收集
我们还提出了两种新的方法来收集知识。对于权重,在 MoE 中,一个过度参数化的模型,拥有更多的可训练参数,覆盖所有知识在狭窄的密集模型中是具有挑战性的。因此,我们必须从每个专家中提取关键知识,然后将它们合并到一个小型的密集模型中。然后,问题来了,我们如何从每个可训练矩阵(即权重)中提取关键知识?我们首先提出 Top-K 知识收集来提取每个专家的子矩阵。对于第
3.2.1 SVD 知识收集
我们研究了另一种从专家中提取关键知识的新方法。低秩压缩 [3] 在捕获关键知识方面显示出了有希望的结果,它被用来将非低秩矩阵转换为权重矩阵的秩 -k 分解。这样的低秩矩阵可以近似整个矩阵的知识。基于此,我们可以更容易地通过从多个低秩矩阵重构高秩矩阵来合并低秩矩阵。请注意,在这项工作中,获得秩 -k 分解并不是我们的目标。相反,秩 -k 分解只是我们分解和合并的中间步骤。在这项工作中,我们提出使用 SVD 来提取关键知识并将它们合并以初始化另一个密集矩阵:
其中
其中
然后我们可以得到
3.3. 知识蒸馏
为了从噪声中挖掘知识,我们采用软知识蒸馏 [9] 来微调密集学生。软蒸馏最小化教师和学生输出之间的 Kullback-Leibler 散度。相应的蒸馏损失可以写成:
其中
3.4. 优化
我们的最终损失函数很简单:
其中
4. 实验
4.1. 计算机视觉
实验设置
为了评估我们的通用训练框架,我们在计算机视觉和自然语言处理两个不同领域进行实验。对于视觉,我们选择了两个广泛使用的图像分类基准,ILSVRC-2012 ImageNet[5] 和 Cifar10[10],作为评估我们框架的平台。我们在此工作中使用的 ILSVRC-2012 ImageNet 数据集有 1k 个类别和 130 万张图像。为了简洁起见,我们在以下实验中将其称为 ImageNet。基线作为我们第一项专注于从预训练的 MoE 整合知识的工作中,据我们所知,只有两个现有的强大基线是 Meta AI MoE[1] 提出的知识蒸馏框架和 Switch Transformer[8]。第一个简单地随机初始化学生密集模型。第二个工作用非专家权重初始化密集模型。也就是说,他们简单地复制可以完美匹配的层到密集模型中。对于不能匹配的权重(即专家),他们跳过从 MoE 的初始化,而是从零开始训练这些层。在我们的工作中,为了简洁起见,我们将这两种方法分别称为 Distill 和 Switch。我们还报告了在相同设置下的 Vision Transformer (ViT) 的结果,以比较参数效率。教师在我们的训练框架中,我们需要一个 MoE 模型来初始化我们的密集学生模型(即知识收集)和执行知识蒸馏。在这项工作中,我们应用了预训练的 WideNet[27] 作为平台。WideNet 是一个基于 MoE 的变换器,只有一个可训练的变换器块。这个变换器块使用 MoE 而不是 FFN 层来学习局部表示。本文的主要焦点是验证预训练的 MoE 中的知识能否在密集学生中保留,因此我们使用 WideNet 作为我们的教师模型,以更直接的方式验证我们方法的有效性。超参数为了公平比较,我们遵循教师模型中使用的数据增强:Inception 风格的预处理,Mixup[30],RandAugment[4] 和标签平滑 [23, 29]。我们使用 LAMB[28] 优化器。批量大小和学习率分别设置为 4096 和 0.004。对于教师模型,所有 WideNet[27] 的设置都与他们论文中报告的相同。请注意,我们在 OneS 的知识蒸馏阶段冻结了教师模型(即 WideNet)的所有可训练权重。对于蒸馏超参数,我们设置
4.1.1 ImageNet 上的结果
我们在表 1 中报告了 ImageNet 上的 top-1 准确率和 MoE 好处。在这张表中,正如我们在方程 8 中定义的,MoE 好处意味着在知识整合后,密集模型保留了多少改进。首先,在研究了四种不同的 KG 方法后,基于 SVD 的整合方法表现最佳。因此,我们将基于 SVD 的方法设置为以下实验中的默认选择。基于 Top-K 的整合方法在大规模上与基于 SVD 的方法表现相当,但在基础级别上略差。我们建议的原因是大型模型具有更大的容量,对稀疏列丢弃更加鲁棒。此外,我们观察到 OneS-L-SVD 仅用 1500 万参数就在 ImageNet 上实现了 78.4% 的 top-1 准确率。与最强的 Switch-L 相比,我们的模型提高了 0.6 个百分点。与教师模型相比,OneS-L-SVD 以一半的参数超越了 WideNet-B 0.9%。最终,OneS-L-SVD 以仅 17% 的可训练参数实现了与 ViT-B 相当的性能。更重要的是,在 [27] 中,没有 MoE,WideNet-L 只能达到 76.9% 的 top-1 准确率。我们的 OneS 具有完全相同的架构,但我们可以实现 78.4% 的准确率。也就是说,我们的 OneS-L-SVD 保留了 61.7% 的改进(即 MoE 好处)。此外,我们的 OneS-B-SVD 实现了 57.7% 的 MoE 好处,超过了最强的基线(即 Switch)23.1 个百分点。这些结果表明了知识整合的有效性。
4.1.2 Cifar10 上的结果
我们进一步在 Cifar10 上微调了我们的密集学生模型 OneS。如表 2 所示,我们的 OneS-L 仍然优于我们的基线,Switch-B 和 Switch-L,分别提高了 0.3% 和 0.6%。OneS-L 甚至可以用 0.33×的可训练参数达到与 WideNet-B 相当的性能。OneS-B 也因为知识收集而优于 Switch-B。总之,Cifar10 上的结果表明,ImageNet 上的预训练改进可以传播到下游任务。
4.2. 自然语言处理
实验设置
与计算机视觉任务上的实验类似,我们仍然在自然语言处理上有两阶段的训练。不同之处在于,按照现有工作 [6, 11, 27],我们关注下游任务的性能而不是预训练。数据集我们使用英文维基百科 [6] 和 BOOKCORPUS[33] 作为我们的预训练语料库。对于微调,我们在通用语言理解评估(GLUE)基准 [26] 上评估我们的工作,以及斯坦福问答(SQuAD)数据集 [17, 18] 的两个不同版本。对于 GLUE 实验,我们报告了 5 次运行的中位数,遵循现有工作 [11, 27]。基线与计算机视觉实验类似,我们仍然选择 Distill 和 Switch 作为我们的直接基线,尽管我们的工作是第一项专注于此任务。学生模型在这里与 ALBERT 的架构相同,除了个别层归一化 [27]。因此,另一个基线是 ALBERT。我们期望我们的 OneS 能在几乎相同的架构、相当数量的参数和相同的预训练数据集的情况下超越 ALBERT。超参数在初始化后,我们通过掩蔽语言建模损失、句子顺序预测损失和软知识蒸馏损失的线性组合进一步训练 OneS。按照 [20],我们只将掩蔽语言建模损失的 logits 输入到
4.2.1 NLU 基准上的结果
预训练后,我们在没有蒸馏损失的情况下微调我们的 OneS。这种设置与现有的语言模型蒸馏工作不同。原因是,我们的目标之一是获得一个易于使用的模型,而不需要专家路由。如果我们仍然有 MoE 教师,下游微调仍然需要复杂的硬件和软件协同设计。下游自然语言理解任务的结果如表 3 所示。总的来说,我们可以观察到 OneS 在所有任务上超越了 ALBERT 和基线(即 Distill 和 Switch),实现了 88.2% 的 MoE 好处。例如,在四项任务上,OneS 平均超过 Switch 0.42 个百分点。此外,我们在 Switch 和 Distill 上分别实现了 53.2% 和 51.7% 的 MoE 好处。在一些任务上,例如 SQuAD1.1 和 SST-2,OneS 甚至超越了教师 MoE 模型 WideNet。我们建议 MoE 模型倾向于在小数据集上过拟合。OneS 拥有 MoE 的知识,但结构密集,因此预训练的好处可以更容易地传播到下游任务。与 MoE 模型相比,OneS 的另一个优势是推理速度。MoE 之所以如此缓慢,是因为 MoE 模型由于条件计算而具有门控函数和稀疏 einsum 操作符,这会降低计算效率。然而,我们的模型可以实现 3.7 倍的推理加速。请注意,WideNet 仅在 MoE 层使用 2.4 倍 FLOPs。对于其他层,WideNet 与 OneS 或 ALBERT 具有相同的计算成本,因此全局 FLOPs 小于 OneS 的 2.4 倍。因此,OneS 能够实现如此高效率的一个原因是计算更少,另一个重要原因是,密集模型比稀疏 MoE 模型更受硬件欢迎。
4.3. 消融研究
我们在这工作中进行了四组消融研究。第一组是调查知识收集和知识蒸馏的贡献。如表 4 所示,没有知识收集,性能显著下降,表明预训练稀疏模型中包含的知识对提高学生模型的性能至关重要。对于没有 KD 的模型,在这次实验中,我们采用方程 18 中的
5. 结论和未来工作
在这篇论文中,受人类教育模型的启发,我们提出了知识整合,一个新的任务,以结合 MoE 模型的有效性和密集模型的可用性。作为第一项专注于此任务的工作,我们的解决方案是分两步整合知识(即知识收集和知识蒸馏)。知识收集侧重于从预训练的 MoE 收集知识以初始化密集学生模型。知识蒸馏是进一步提炼密集模型。实验表明,我们的 OneS 在计算机视觉和自然语言处理任务上取得了出色的有效性和效率。值得注意的是,我们的 OneS 甚至可以在 0.42× FLOPs 每 MoE 或 FFN 层,3.7 倍推理加速和 46% 可训练参数的情况下保留 88.2% 的好处。未来,我们计划探索更先进的知识收集和蒸馏方法,以更好地将 MoE 的知识整合到密集学生中。此外,尽管大多数最近的基于 MoE 的变换器对不同专家使用相同的架构,但研究从具有不同架构的专家那里收集知识的方法是有价值的。最后,我们期望将我们的方法适应于像 GLaM[7] 这样的非常大的 MoE 模型。